Evaluer klassificeringsmodeller
Oplæringsnøjagtigheden af en klassificeringsmodel er meget mindre vigtig end, hvor godt denne model fungerer, når der gives nye, usete data. Vi oplærer trods alt modeller, så de kan bruges på nye data, som vi finder i den virkelige verden. Så når vi har oplært en klassificeringsmodel, evaluerer vi, hvordan den fungerer på et sæt nye, usete data.
I de tidligere enheder oprettede vi en model, der kunne forudsige, om en patient havde diabetes eller ej baseret på deres blodsukkerniveau. Når vi nu anvendes på nogle data, der ikke var en del af oplæringssættet, får vi følgende forudsigelser.
| x | y | ŷ |
|---|---|---|
| 83 | 0 | 0 |
| 119 | 1 | 1 |
| 104 | 1 | 0 |
| 105 | 0 | 1 |
| 86 | 0 | 0 |
| 109 | 1 | 1 |
Husk, at x refererer til blodglukoseniveauet, y refererer til, om de faktisk er diabetiker, og ŷ refererer til modellens forudsigelse om, hvorvidt de er diabetiker eller ej.
Bare beregning af, hvor mange forudsigelser var korrekte, er nogle gange vildledende eller for forenklet for os at forstå den slags fejl, det vil gøre i den virkelige verden. Hvis du vil have mere detaljerede oplysninger, kan vi tabulere resultaterne i en struktur, der kaldes en forvirringsmatrix, f.eks.:
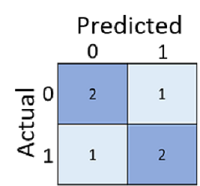
Forvirringsmatrixen viser det samlede antal tilfælde, hvor:
- Modellen forudsagde 0, og den faktiske etiket er 0 (sande negative, øverst til venstre)
- Modellen forudsagde 1, og den faktiske etiket er 1 (sande positivenederst til højre)
- Modellen forudsagde 0, og den faktiske etiket er 1 (falske negativernederst til venstre)
- Modellen forudsagde 1, og den faktiske etiket er 0 (falske positiver, øverst til højre)
Cellerne i en forvirringsmatrix er ofte skyggelagt, så højere værdier har en dybere skygge. Det gør det nemmere at se en stærk diagonal tendens fra øverste venstre til nederste højre hjørne, hvor de celler, hvor den forudsagte værdi og den faktiske værdi er den samme, fremhæves.
Ud fra disse kerneværdier kan du beregne en række andre målepunkter, der kan hjælpe dig med at evaluere modellens ydeevne. For eksempel:
- nøjagtighed: (TP+TN)/(TP+TN+FP+FN) – ud af alle forudsigelserne, hvor mange var korrekte?
- Recall: TP/(TP+FN) – for alle de tilfælde, hvor er positive, hvor mange identificerede modellen?
- Precision: TP/(TP+FP) – af alle de tilfælde, som modellen forudsagde var positive, hvor mange der faktisk er positive?