Indførelsen
Klyngedannelse er processen til gruppering af objekter med lignende objekter. På billedet nedenfor har vi f.eks. en samling af 2D-koordinater, der er grupperet i tre kategorier – øverst til venstre (gul), bund (rød) og øverst til højre (blå).
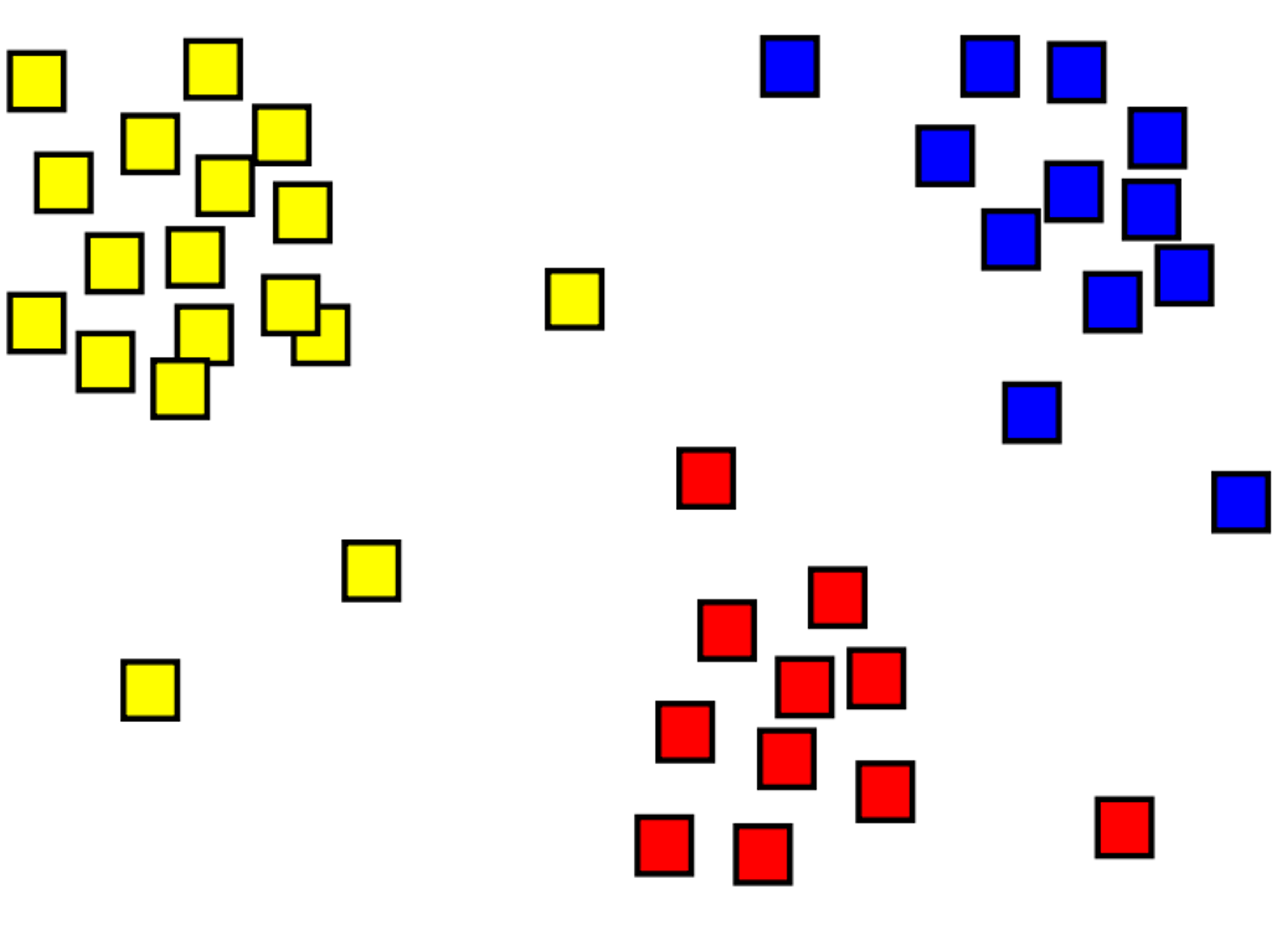
En stor forskel mellem klynge- og klassificeringsmodeller er, at klyngedannelse er en ikke-overvåget metode, hvor oplæring udføres uden mærkater. Klyngemodeller identificerer eksempler, der har en lignende samling af funktioner. På det foregående billede grupperes eksempler, der befinder sig på en lignende placering, sammen.
Klynger er almindelige og nyttige til at udforske nye data, hvor mønstre mellem datapunkter, f.eks. kategorier på højt niveau, endnu ikke er kendt. Det bruges i mange felter, der automatisk skal mærke komplekse data, herunder analyse af sociale netværk, hjerneforbindelse, spamfiltrering osv.