Evaluer forskellige typer klynger
Oplæring af en klyngemodel
Der er flere algoritmer, du kan bruge til klyngedannelse. En af de mest anvendte algoritmer er K-Means- klyngedannelse, der i sin enkleste form består af følgende trin:
- Funktionsværdierne vektoriseres for at definere n-dimensionelle koordinater (hvor n er antallet af funktioner). I eksemplet med blomsten har vi to funktioner: antallet af kronblade og antallet af blade. Funktionsvektoren har derfor to koordinater, som vi kan bruge til konceptuelt at afbilde datapunkterne i todimensionelt rum.
- Du bestemmer, hvor mange klynger du vil bruge til at gruppere blomsterne . Kald denne værdi k. Hvis du f.eks. vil oprette tre klynger, skal du bruge en k værdi på 3. Derefter afbildes k punkter ved tilfældige koordinater. Disse punkter bliver midtpunkterne for hver klynge, så de kaldes centroider.
- Hvert datapunkt (i dette tilfælde en blomst) tildeles den nærmeste centroid.
- Hver centroid flyttes til midten af de datapunkter, der er tildelt den, baseret på middelafstanden mellem punkterne.
- Når centroiden er flyttet, kan datapunkterne nu være tættere på et andet centroid, så datapunkterne omfordeles til klynger baseret på den nye nærmeste centroid.
- Trinnene til omfordeling af centroider og klynger gentages, indtil klyngerne bliver stabile, eller et forudbestemt maksimalt antal gentagelser nås.
Følgende animation viser denne proces:

Hierarkisk klyngedannelse
Hierarkisk klyngeoprettelse er en anden type klyngealgoritme, hvor klynger selv tilhører større grupper, som tilhører endnu større grupper osv. Resultatet er, at datapunkter kan være klynger i forskellig grad af præcision: med et stort antal meget små og præcise grupper eller et lille antal større grupper.
Hvis vi f.eks. anvender klyngedannelse på betydningen af ord, kan vi få en gruppe, der indeholder adjektiver, der er specifikke for følelser ("vred", "glad" osv.). Denne gruppe tilhører en gruppe, der indeholder alle menneskelige adjektiver ('glad', 'flot', 'ung'), som tilhører en endnu højere gruppe, der indeholder alle adjektiver ('glad', 'grøn', 'smuk', 'hård', ' osv.).
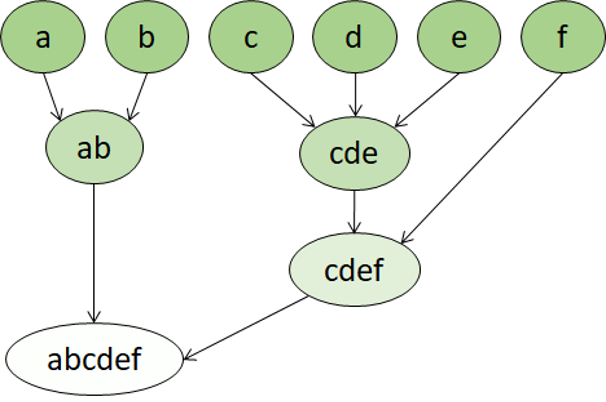
Hierarkisk klyngedannelse er nyttig til ikke kun at opdele data i grupper, men også til at forstå relationerne mellem disse grupper. En stor fordel ved hierarkisk klyngeoprettelse er, at det ikke kræver, at antallet af klynger defineres på forhånd. Og det kan nogle gange give mere fortolkelige resultater end ikke-hierarkiske tilgange. De største ulemper er, at det kan tage længere tid at beregne disse metoder end enklere metoder, og nogle gange er de ikke egnede til store datasæt.