Dybe neurale netværksbegreber
Før vi udforsker, hvordan du oplærer en DNN-model (Deep Neural Network) for maskinel indlæring, skal vi overveje, hvad vi forsøger at opnå. Maskinel indlæring drejer sig om at forudsige en mærkat baseret på nogle funktioner af en bestemt observation. En model til maskinel indlæring er en funktion, der beregner y (etiketten) fra x (funktionerne): f(x)=y.
Et simpelt klassificeringseksempel
Lad os f.eks. antage, at din observation består af nogle målinger af en pingvin.

Målingerne er specifikt:
- Længden af pingvinens regning.
- Dybden af pingvinens regning.
- Længden af pingvinens flipper.
- Pingvinens vægt.
I dette tilfælde er funktionerne (x) en vektor på fire værdier eller matematisk x=[x1,x2,x3,x4].
Lad os antage, at den etiket, vi forsøger at forudsige (y) er arten af pingvinen, og at der er tre mulige arter, det kunne være:
- Adelie
- Gentoo
- Chinstrap
Dette er et eksempel på en klassificering problem, hvor modellen til maskinel indlæring skal forudsige den mest sandsynlige klasse, som observationen tilhører. En klassificeringsmodel opnår dette ved at forudsige en etiket, der består af sandsynligheden for hver klasse. Med andre ord er y en vektor med tre sandsynlighedsværdier. én for hver af de mulige klasser: y=[P(0),P(1),P(2)].
Du oplærer modellen til maskinel indlæring ved hjælp af observationer, som du allerede kender den sande mærkat for. Du kan f.eks. have følgende funktionsmålinger for en Adelie- model:
x=[37.3, 16.8, 19.2, 30.0]
Du ved allerede, at dette er et eksempel på en Adelie (klasse 0), så en perfekt klassificeringsfunktion skal resultere i en etiket, der angiver en 100% sandsynlighed for klasse 0 og en 0% sandsynlighed for klasser 1 og 2:
y=[1, 0, 0]
En dyb neural netværksmodel
Så hvordan skal vi bruge deep learning til at bygge en klassificeringsmodel til pingvinklassificeringsmodellen? Lad os se på et eksempel:
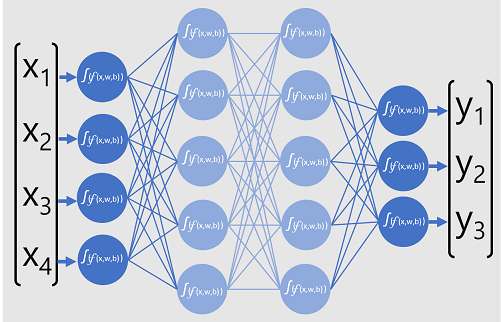
Den dybe neurale netværksmodel for klassificeringen består af flere lag af kunstige neuroner. I dette tilfælde er der fire lag:
- Et input lag med en neuron for hver forventet inputværdi (x).
- To såkaldte skjulte lag, der hver indeholder fem neuroner.
- Et output lag, der indeholder tre neuroner – én for hver klassesandsynlighed (y) værdi, der skal forudsiges af modellen.
På grund af netværkets lagdelte arkitektur kaldes denne type model nogle gange for en flerlags perceptron. Bemærk derudover, at alle neuroner i input og skjulte lag er forbundet med alle neuroner i de efterfølgende lag - dette er et eksempel på et fuldt forbundet netværk.
Når du opretter en model som denne, skal du definere et inputlag, der understøtter det antal funktioner, din model skal behandle, og et outputlag, der afspejler det antal output, du forventer, at den vil producere. Du kan beslutte, hvor mange skjulte lag du vil inkludere, og hvor mange neuroner der er i hver af dem; men du har ingen kontrol over input- og outputværdierne for disse lag – disse bestemmes af modeltræningsprocessen.
Oplæring af et dybt neuralt netværk
Oplæringsprocessen for et dybt neuralt netværk består af flere gentagelser, der kaldes epoker. I den første epoke starter du med at tildele tilfældige initialiseringsværdier for vægt (w) og bias b værdier. Derefter er processen som følger:
- Funktioner til dataobservationer med kendte mærkatværdier sendes til inputlaget. Disse observationer er generelt grupperet i batches (ofte kaldet minipartier).
- Neuronerne anvender derefter deres funktion, og hvis de aktiveres, overføres resultatet til det næste lag, indtil outputlaget giver en forudsigelse.
- Forudsigelsen sammenlignes med den faktiske kendte værdi, og mængden af varians mellem de forudsagte og sande værdier (som vi kalder tab) beregnes.
- Baseret på resultaterne beregnes reviderede værdier for vægt- og biasværdier for at reducere tabet, og disse justeringer er backpropagated til neuronerne i netværkslagene.
- Den næste epoke gentager batch træning fremad pass med den reviderede vægt og bias værdier, forhåbentlig forbedre nøjagtigheden af modellen (ved at reducere tabet).
Seddel
Behandling af træningsfunktionerne som et batch forbedrer effektiviteten af træningsprocessen ved at behandle flere observationer samtidig som en matrix af funktioner med vektorer af vægte og bias. Lineære algebraiske funktioner, der fungerer sammen med matrixer og vektorer, er også en del af 3D-grafikbehandling, og derfor giver computere med GPU'er (Graphic Processing Units) markant bedre ydeevne i forbindelse med detaljeret læringsmodeltræning end kun computere med cpu (Central Processing Unit).
Et nærmere kig på tabsfunktioner og backpropagation
I den tidligere beskrivelse af den dybe læringsproces blev det nævnt, at tabet fra modellen beregnes og bruges til at justere vægt- og biasværdierne. Hvordan fungerer det præcist?
Beregner tab
Lad os antage, at et af de eksempler, der sendes gennem oplæringsprocessen, indeholder funktioner i en Adelie prøve (klasse 0). Det korrekte output fra netværket er [1, 0, 0]. Antag nu, at det output, der produceres af netværket, er [0.4, 0.3, 0.3]. Ved at sammenligne disse kan vi beregne en absolut varians for hvert element (med andre ord, hvor langt hver forudsagt værdi er væk fra, hvad den skal være) som [0,6, 0,3, 0,3].
Da vi faktisk beskæftiger os med flere observationer, aggregerer vi typisk variansen , f.eks. ved at sætte de individuelle variansværdier og beregne middelværdien, så vi ender med en enkelt gennemsnitlig tabsværdi, f.eks. 0,18.
Optimizers
Her er den smarte del. Tabet beregnes ved hjælp af en funktion, der fungerer på resultaterne fra det sidste lag af netværket, som også er en funktion. Det sidste lag af netværket fungerer på output fra de tidligere lag, som også er funktioner. Så i realiteten er hele modellen fra inputlaget helt frem til tabsberegningen blot én stor indlejret funktion. Funktioner har et par virkelig nyttige egenskaber, herunder:
- Du kan konceptualisere en funktion som en afbildet linje, der sammenligner outputtet med hver af dens variabler.
- Du kan bruge differentialkalkulus til at beregne funktionens afledte når som helst med hensyn til dens variabler.
Lad os tage den første af disse funktioner. Vi kan afbilde linjen for funktionen for at få vist, hvordan en individuel vægtværdi sammenlignes med tab, og markere det punkt på linjen, hvor den aktuelle vægtværdi svarer til den aktuelle tabsværdi.
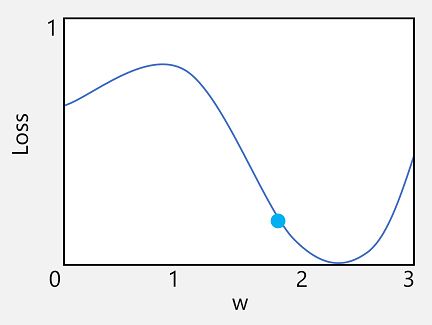
Lad os nu anvende den anden egenskab ved en funktion. Resultatet af en funktion for et givet punkt angiver, om hældningen (eller graduering) af funktionsoutputtet (i dette tilfælde tab) er stigende eller faldende i forhold til en funktionsvariabel (i dette tilfælde vægtværdien). Et positivt derivat angiver, at funktionen er stigende, og et negativt afledt middel angiver, at den er faldende. I dette tilfælde har funktionen en nedadgående graduering på det afbildede punkt for den aktuelle vægtværdi. Med andre ord vil en forøgelse af vægten have den virkning, at tabet mindskes.
Vi bruger en optimizer til at anvende det samme trick for alle vægt- og biasvariabler i modellen og bestemme, i hvilken retning vi skal justere dem (op eller ned) for at reducere den samlede mængde tab i modellen. Der er flere almindeligt anvendte optimeringsalgoritmer, herunder stokastisk gradueringsafstamning (SGD), ADADELTA (Adaptive Learning Rate), Adam (Adaptive MomentumEstimat)og andre; som alle er designet til at finde ud af, hvordan man justerer vægte og bias for at minimere tab.
Læringsfrekvens
Nu er det indlysende næste spørgsmål er, hvor meget skal optimering justere vægte og bias værdier? Hvis du ser på plottet for vores vægtværdi, kan du se, at øge vægten med et lille beløb vil følge funktionslinjen ned (reducere tabet), men hvis vi øger det med for meget, begynder funktionslinjen at gå op igen, så vi faktisk kan øge tabet; og efter den næste epoke, kan vi finde vi nødt til at reducere vægten.
Størrelsen af justeringen styres af en parameter, som du angiver for oplæring, der kaldes læringsfrekvens. En lav læringsfrekvens resulterer i små justeringer (så det kan tage flere epoker at minimere tabet), mens en høj læringsrate resulterer i store justeringer (så du kan gå glip af minimumet).