Konvolutionelle neurale netværk
Selvom du kan bruge deep learning-modeller til enhver form for maskinel indlæring, er de især nyttige til håndtering af data, der består af store matrixer af numeriske værdier – f.eks. billeder. Modeller til maskinel indlæring, der arbejder med billeder, er grundlaget for et område, kunstig intelligens kaldet computer vision, og deep learning teknikker har været ansvarlig for at køre fantastiske fremskridt på dette område i de seneste år.
Kernen i deep learning succes på dette område er en slags model kaldet en convolutional neurale netværk, eller CNN. Et CNN fungerer typisk ved at udtrække funktioner fra billeder og derefter overføre disse funktioner til et fuldt forbundet neuralt netværk for at generere en forudsigelse. Funktionsudtrækningslagene i netværket har den virkning, at antallet af funktioner reduceres fra den potentielt enorme matrix af individuelle pixelværdier til et mindre funktionssæt, der understøtter etiketforudsigelse.
Lag i et CNN
CNN'er består af flere lag, der hver især udfører en bestemt opgave med at udtrække funktioner eller forudsige mærkater.
Lag til konvolution
En af de vigtigste lagtyper er et convolutional lag, der udtrækker vigtige funktioner i billeder. Et konvolutionelt lag fungerer ved at anvende et filter på billeder. Filteret defineres af en kerne-, der består af en matrix med vægtværdier.
Et 3x3-filter kan f.eks. defineres på følgende måde:
1 -1 1
-1 0 -1
1 -1 1
Et billede er også blot en matrix med pixelværdier. Hvis du vil anvende filteret, skal du "overlejre" det på et billede og beregne en vægtet sum af de tilsvarende billedpixelværdier under filterkernen. Resultatet tildeles derefter til midtercellen for en tilsvarende 3x3-programrettelse i en ny matrix med værdier, der har samme størrelse som billedet. Lad os f.eks. antage, at et billede på 6 x 6 har følgende pixelværdier:
255 255 255 255 255 255
255 255 100 255 255 255
255 100 100 100 255 255
100 100 100 100 100 255
255 255 255 255 255 255
255 255 255 255 255 255
Hvis du anvender filteret på 3x3-programrettelsen øverst til venstre på billedet, fungerer det på følgende måde:
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 255 100 x -1 0 -1 = (255 x -1)+(255 x 0)+(100 x -1) + = 155
255 100 100 1 -1 1 (255 x1 )+(100 x -1)+(100 x 1)
Resultatet tildeles den tilsvarende pixelværdi i den nye matrix på følgende måde:
? ? ? ? ? ?
? 155 ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Nu flyttes filteret (convolved), typisk ved hjælp af et trin størrelse på 1 (så du bevæger dig langs en pixel til højre), og værdien for den næste pixel beregnes
255 255 255 1 -1 1 (255 x 1)+(255 x -1)+(255 x 1) +
255 100 255 x -1 0 -1 = (255 x -1)+(100 x 0)+(255 x -1) + = -155
100 100 100 1 -1 1 (100 x1 )+(100 x -1)+(100 x 1)
Så nu kan vi udfylde den næste værdi i den nye matrix.
? ? ? ? ? ?
? 155 -155 ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
? ? ? ? ? ?
Processen gentages, indtil vi har anvendt filteret på tværs af alle 3x3-programrettelser i billedet for at oprette en ny matrix med værdier som denne:
? ? ? ? ? ?
? 155 -155 155 -155 ?
? -155 310 -155 155 ?
? 310 155 310 0 ?
? -155 -155 -155 0 ?
? ? ? ? ? ?
På grund af filterkernens størrelse kan vi ikke beregne værdier for pixel ved kanten. Så vi anvender typisk bare en indre margen værdi (ofte 0):
0 0 0 0 0 0
0 155 -155 155 -155 0
0 -155 310 -155 155 0
0 310 155 310 0 0
0 -155 -155 -155 0 0
0 0 0 0 0 0
Resultatet af konvolutionen overføres typisk til en aktiveringsfunktion, som ofte er en rektificeret lineær enhed(ReLU) funktion, der sikrer, at negative værdier er indstillet til 0:
0 0 0 0 0 0
0 155 0 155 0 0
0 0 310 0 155 0
0 310 155 310 0 0
0 0 0 0 0 0
0 0 0 0 0 0
Den resulterende matrix er et funktionskort af funktionsværdier, der kan bruges til at oplære en model til maskinel indlæring.
Bemærk: Værdierne i funktionsoversigten kan være større end maksimumværdien for en pixel (255), så hvis du vil visualisere funktionsoversigten som et billede, skal du normalisere funktionsværdierne mellem 0 og 255.
Processen for konvolution vises i animationen nedenfor.

- Et billede overføres til det konvolutionelle lag. I dette tilfælde er billedet en simpel geometrisk form.
- Billedet består af en matrix af pixel med værdier mellem 0 og 255 (for farvebilleder er dette normalt en 3-dimensionel matrix med værdier for røde, grønne og blå kanaler).
- En filterkerne initialiseres generelt med tilfældige vægte (i dette eksempel har vi valgt værdier for at fremhæve den effekt, som et filter kan have på pixelværdier, men i et rigtigt CNN vil de oprindelige vægte typisk blive genereret ud fra en tilfældig Gaussisk fordeling). Dette filter bruges til at udtrække en funktionsoversigt fra billeddataene.
- Filteret samles på tværs af billedet og beregner funktionsværdier ved at anvende en sum af vægterne ganget med deres tilsvarende pixelværdier på hver position. Der anvendes en relu-aktiveringsfunktion (Rectified Linear Unit) for at sikre, at negative værdier er angivet til 0.
- Efter opløsningen indeholder funktionsoversigten de udtrukne funktionsværdier, som ofte lægger vægt på billedets vigtige visuelle attributter. I dette tilfælde fremhæver funktionskortet kanterne og hjørnerne af trekanten på billedet.
Et konvolutionelt lag anvender typisk flere filterkerner. Hvert filter opretter et andet funktionskort, og alle funktionskort overføres til det næste lag af netværket.
Gruppering af lag
Når du har udtrukket funktionsværdier fra billeder, bruges gruppering af (eller nedsampling) lag til at reducere antallet af funktionsværdier, samtidig med at de vigtigste skelnende funktioner, der er blevet udtrukket, bevares.
En af de mest almindelige former for gruppering er maksimale gruppering, hvor der anvendes et filter på billedet, og kun den maksimale pixelværdi i filterområdet bevares. Så hvis du f.eks. anvender en 2x2-puljekerne på følgende programrettelse af et billede, vil resultatet 155.
0 0
0 155
Bemærk, at effekten af 2x2-grupperingsfilteret er at reducere antallet af værdier fra 4 til 1.
Som med convolutionale lag fungerer gruppering af lag ved at anvende filteret på tværs af hele funktionsoversigten. Animationen nedenfor viser et eksempel på maksimal gruppering for et billedkort.

- Funktionsoversigten, der er udtrukket af et filter i et konvolutionelt lag, indeholder en matrix af funktionsværdier.
- En grupperingskerne bruges til at reducere antallet af funktionsværdier. I dette tilfælde er kernestørrelsen 2x2, så den producerer en matrix med fjerdedel af antallet af funktionsværdier.
- Samlekernen samles på tværs af funktionsoversigten og bevarer kun den højeste pixelværdi på hver position.
Slipper lag
En af de vanskeligste udfordringer i et CNN er at undgå overfitting, hvor den resulterende model klarer sig godt med oplæringsdataene, men ikke generaliserer sig godt til nye data, som den ikke blev oplært i. En teknik, du kan bruge til at afhjælpe overfitting, er at inkludere lag, hvor træningsprocessen tilfældigt eliminerer (eller "dråber") funktionskort. Dette kan virke kontraintuitivt, men det er en effektiv måde at sikre, at modellen ikke lærer at være overafhængig af træningsbillederne.
Andre teknikker, du kan bruge til at afhjælpe overfitting, omfatter tilfældigt spejling, spejling eller skævvridning af træningsbillederne for at generere data, der varierer mellem trænings epoker.
Flade lag
Når du har brugt konvolutionelle lag og gruppering af lag til at udtrække de vigtigste funktioner i billederne, er de resulterende funktionskort flerdimensionelle matrixer af pixelværdier. Et fladt lag bruges til at fladgør funktionsoversigterne til en vektor af værdier, der kan bruges som input til et fuldt forbundet lag.
Fuldt forbundne lag
Normalt slutter et CNN med et fuldt forbundet netværk, hvor funktionsværdierne overføres til et inputlag via et eller flere skjulte lag, og genererer forudsagte værdier i et outputlag.
En grundlæggende CNN-arkitektur kan se ud som følger:
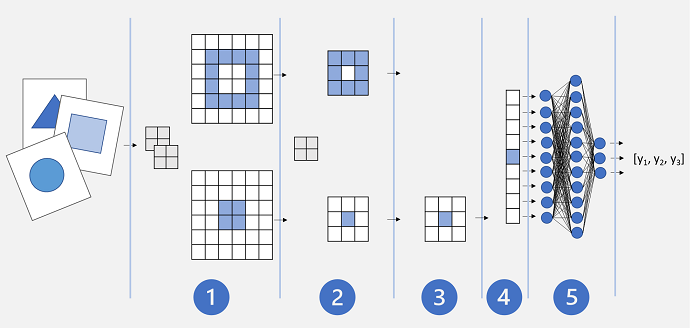
- Billeder føres ind i et konvolutionelt lag. I dette tilfælde er der to filtre, så hvert billede producerer to funktionskort.
- Funktionskortene overføres til et grupperingslag, hvor en 2x2-puljekerne reducerer størrelsen af funktionskortene.
- Et faldende lag falder tilfældigt på nogle af funktionsoversigterne for at forhindre overfitting.
- Et fladt lag tager de resterende matrixer med funktionskort og fladgør dem til en vektor.
- Vektorelementerne føres ind i et fuldt tilsluttet netværk, hvilket genererer forudsigelserne. I dette tilfælde er netværket en klassificeringsmodel, der forudsiger sandsynligheder for tre mulige billedklasser (trekant, firkantet og cirkel).
Oplæring af en CNN-model
Som med ethvert dybt neuralt netværk oplæres et CNN ved at overføre batches af træningsdata gennem det over flere epoker og justere vægte og biasværdier baseret på det tab, der beregnes for hver epoke. I tilfælde af CNN omfatter backpropagation af justerede vægte filterkernevægte, der anvendes i konvolutionelle lag, samt vægte, der anvendes i fuldt forbundne lag.