Hvad er regression?
Regression fungerer ved at oprette en relation mellem variabler i de data, der repræsenterer egenskaber – også kaldet de funktioner– for det, der observeres, og den variabel, vi forsøger at forudsige – kendt som -mærkaten.
Husk vores firma lejer cykler og ønsker at forudsige det forventede antal huslejer på en given dag. I dette tilfælde omfatter funktioner ting som ugedagen, måneden osv., mens etiketten er antallet af cykeludlejninger.
For at oplære modellen starter vi med et dataeksempel, der indeholder funktionerne, samt kendte værdier for mærkaten. Så i dette tilfælde har vi brug for historiske data, der indeholder datoer, vejrforhold og antallet af cykellejer.
Derefter opdeler vi dette dataeksempel i to undersæt:
- En oplæring datasæt, som vi anvender en algoritme på, som bestemmer en funktion, der indkapsler relationen mellem funktionsværdierne og de kendte mærkatværdier.
- En validering eller test datasæt, som vi kan bruge til at evaluere modellen ved hjælp af den til at generere forudsigelser for etiketten og sammenligne dem med de faktiske kendte mærkatværdier.
Brugen af historiske data med kendte mærkatværdier til at oplære en model gør regression til et eksempel på overvåget maskinel indlæring.
Et simpelt eksempel
Lad os tage et simpelt eksempel for at se, hvordan oplærings- og evalueringsprocessen fungerer i princippet. Lad os antage, at vi forenkler scenariet, så vi bruger en enkelt funktion – gennemsnitlig daglig temperatur – til at forudsige etiketten for leje af cykler.
Vi starter med nogle data, der indeholder kendte værdier for den gennemsnitlige daglige temperaturfunktion og cykellejemærket.
| Temperatur | Udlejning |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
| 82 | 156 |
| 54 | 114 |
| 62 | 129 |
Nu vi tilfældigt vælge fem af disse observationer og bruge dem til at oplære en regressionsmodel. Når vi taler om "oplæring af en model", mener vi at finde en funktion (en matematisk ligning, lad os kalde den f), der kan bruge temperaturfunktionen (som vi kalder x) til at beregne antallet af huslejer (som vi kalder y). Vi skal med andre ord definere følgende funktion: f(x) = y.
Vores træningsdatasæt ser sådan ud:
| x | y |
|---|---|
| 56 | 115 |
| 61 | 126 |
| 67 | 137 |
| 72 | 140 |
| 76 | 152 |
Lad os starte med at afbilde træningsværdierne for x og y i et diagram:
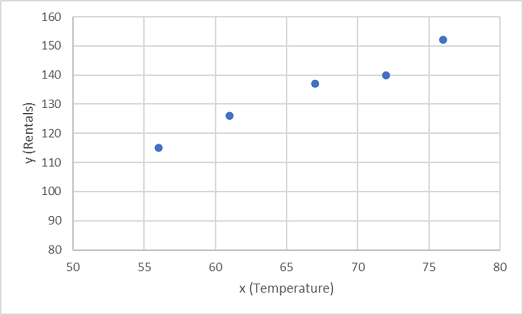
Nu skal vi tilpasse disse værdier til en funktion, hvilket giver mulighed for tilfældig variation. Du kan sikkert se, at de afbildede punkter udgør en næsten lige diagonal linje. Der er med andre ord en synlig lineær relation mellem x og y, så vi er nødt til at finde en lineær funktion, der passer bedst til dataeksemplet. Der er forskellige algoritmer, vi kan bruge til at bestemme denne funktion, som i sidste ende vil finde en lige linje med minimal samlet varians fra de afbildede punkter; Som dette:
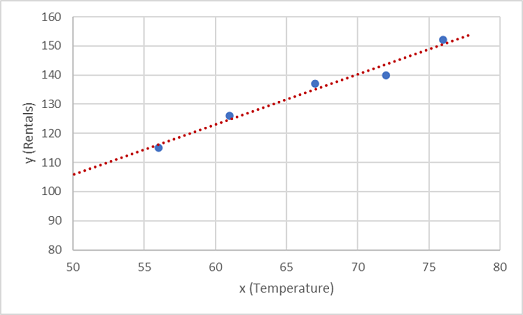
Linjen repræsenterer en lineær funktion, der kan bruges sammen med en hvilken som helst værdi af x til at anvende den hældning af linjen og dens opfange (hvor linjen krydser y-aksen, når x er 0) for at beregne y. Hvis vi i dette tilfælde udvidede linjen til venstre, ville vi opdage, at når x er 0, er y ca. 20, og linjens hældning er sådan, at for hver enhed af x du bevæger dig langs til højre, stiger y med ca. 1,7. Vi kan derfor beregne vores f funktion som 20 + 1,7x.
Nu, hvor vi har defineret vores forudsigende funktion, kan vi bruge den til at forudsige mærkater for de valideringsdata, vi har holdt tilbage, og sammenligne de forudsagte værdier (som vi typisk angiver med symbolet ŷeller "y-hat") med de faktiske kendte y værdier.
| x | y | ŷ |
|---|---|---|
| 82 | 156 | 159.4 |
| 54 | 114 | 111.8 |
| 62 | 129 | 125.4 |
Lad os se, hvordan værdierne y og ŷ sammenlignes i en afbildning:
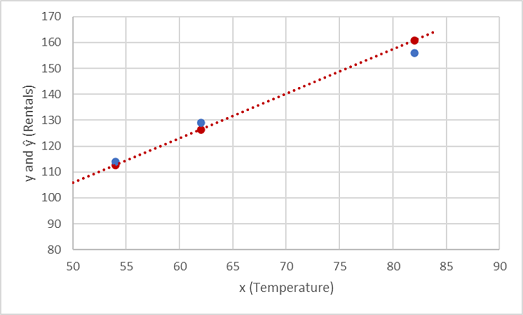
De afbildede punkter på funktionslinjen er de forudsagte ŷ værdier, der beregnes af funktionen, og de andre afbildede punkter er de faktiske y værdier.
Der er forskellige måder, hvorpå vi kan måle variansen mellem de forudsagte og faktiske værdier, og vi kan bruge disse målepunkter til at evaluere, hvor godt modellen forudsiger.
Seddel
Machine learning er baseret på statistikker og matematik, og det er vigtigt at være opmærksom på specifikke begreber, som statistikere og matematikere (og derfor dataspecialister) bruger. Du kan tænke på forskellen mellem en forudsagt etiketværdi og den faktiske mærkatværdi som en måling af fejl. I praksis er de "faktiske" værdier dog baseret på stikprøveobservationer (som selv kan være underlagt en vilkårlig varians). For at gøre det klart, at vi sammenligner en forudsagt værdi (ŷ) med en observeret værdi (y) henviser vi til forskellen mellem dem som resterne. Vi kan opsummere resterne for alle valideringsdataforudsigelser for at beregne den samlede tab i modellen som en måling af dens forudsigende ydeevne.
En af de mest almindelige måder at måle tabet på er ved at firkante de enkelte restprodukter, lægge kvadraterne sammen og beregne middelværdien. Ved at sætte resterne til grund baseres beregningen på absolutte værdier (idet man ignorerer, om forskellen er negativ eller positiv) og giver større vægt til større forskelle. Denne metrikværdi kaldes Middelværdi kvadreret fejl.
For vores valideringsdata ser beregningen sådan ud:
| y | ŷ | y - ŷ | (y - ŷ)2 |
|---|---|---|---|
| 156 | 159.4 | -3.4 | 11.56 |
| 114 | 111.8 | 2.2 | 4.84 |
| 129 | 125.4 | 3.6 | 12.96 |
| Sum | ∑ | 29.36 | |
| Betyde | x̄ | 9.79 |
Derfor er tabet for vores model baseret på MSE-metrikværdien 9,79.
Er det noget godt? Det er svært at se, fordi MSE-værdien ikke udtrykkes i en meningsfuld måleenhed. Vi ved, at jo lavere værdien er, jo mindre tab er der i modellen, og derfor er det bedre at forudsige. Det gør det til en nyttig metrikværdi at sammenligne to modeller og finde den, der fungerer bedst.
Nogle gange er det mere nyttigt at udtrykke tabet i den samme måleenhed som selve den forudsagte mærkatværdi. i dette tilfælde antallet af huslejer. Det er muligt at gøre dette ved at beregne kvadratroden af MSE, hvilket giver en metrikværdi, der er kendt, ikke overraskende, som Root Mean Squared Error (RMSE).
√9,79 = 3,13
Så vores model's RMSE angiver, at tabet er lidt over 3, som du kan fortolke løst som betyder, at forkerte forudsigelser i gennemsnit er forkerte med omkring tre huslejer.
Der er mange andre målepunkter, der kan bruges til at måle tab i en regression. R-2 (R-kvadreret) (også kaldet bestemmelseskoefficient) er korrelationen mellem x og y kvadreret. Dette giver en værdi mellem 0 og 1, der måler den afvigelsesmængde, der kan forklares af modellen. Jo tættere denne værdi er på 1, jo bedre forudsiger modellen generelt.