Udforsk løsningsarkitekturen
Lad os revidere arkitekturen for maskinel indlæring (MLOps) for at forstå formålet med det, vi forsøger at opnå.
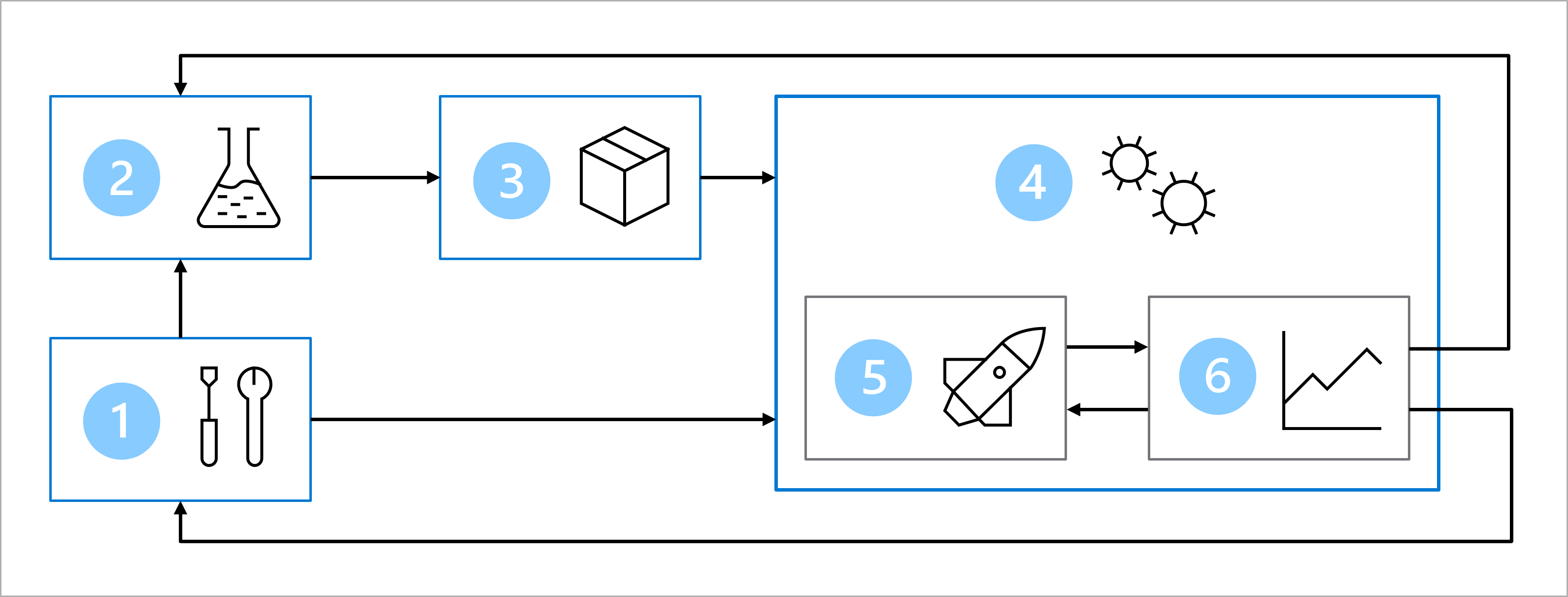
Forestil dig, at du sammen med datavidenskabs- og softwareudviklingsteamet er blevet enige om følgende arkitektur for at oplære, teste og udrulle diabetesklassificeringsmodellen:
Seddel
Diagrammet er en forenklet repræsentation af en MLOps-arkitektur. Hvis du vil have vist en mere detaljeret arkitektur, skal du udforske de forskellige use cases i MLOps (v2)-løsningsaccelerator.
Arkitekturen omfatter:
- installation: Opret alle nødvendige Azure-ressourcer til løsningen.
- Modeludvikling (indre løkke): Udforsk og behandl dataene for at oplære og evaluere modellen.
- Kontinuerlig integration: Pak og registrer modellen.
- modelinstallation (ydre løkke): Udrul modellen.
- Kontinuerlig udrulning: Test modellen, og hæv til produktionsmiljøet.
- Overvågning: Overvåg modellens og slutpunktsydeevnen.
Datavidenskabsteamet er ansvarlig for modeludvikling. Softwareudviklingsteamet er ansvarlig for at integrere den udrullede model med den webapp, der bruges af praktiserende læger til at vurdere, om en patient har diabetes. Du er ansvarlig for at tage modellen fra modeludvikling til modelinstallation.
Du forventer, at datavidenskabsteamet konstant foreslår ændringer af de scripts, der bruges til at oplære modellen. Når der er en ændring i træningsscriptet, skal du oplære modellen igen og geninstallere modellen til det eksisterende slutpunkt.
Du vil tillade, at datavidenskabsteamet eksperimenterer uden at røre koden klar til produktion. Du vil også sikre dig, at enhver ny eller opdateret kode automatisk gennemgår aftalte kvalitetskontroller. Når du har bekræftet koden for at oplære modellen, skal du bruge det opdaterede træningsscript til at oplære en ny model og udrulle den.
Hvis du vil holde styr på ændringerne og bekræfte din kode, før du opdaterer produktionskoden, er det nødvendigt at arbejde med forgreninger. Du har aftalt med datavidenskabsteamet, at hver gang de vil foretage en ændring, opretter de en funktionsgren til at oprette en kopi af koden og foretage deres ændringer af kopien.
Alle dataforskere kan oprette en funktionsgren og arbejde derinde. Når koden er opdateret, og koden skal være den nye produktionskode, skal vedkommende oprette en pullanmodning. I pullanmodningen vil det være synligt for andre, hvad de foreslåede ændringer er, hvilket giver andre mulighed for at gennemse og diskutere ændringerne.
Når der oprettes en pullanmodning, skal du automatisk kontrollere, om koden fungerer, og om kvaliteten af koden er op til organisationens standarder. Når koden har bestået kvalitetskontrollen, skal dataforskeren for kundeemnet gennemse ændringerne og godkende opdateringerne, før pullanmodningen kan flettes, og koden i hovedgrenen kan opdateres i overensstemmelse hermed.
Vigtigt!
Ingen må nogensinde pushændringer af hovedgrenen. Hvis du vil beskytte din kode, især produktionskoden, skal du gennemtvinge, at hovedforgreningen kun kan opdateres via pullanmodninger, der skal godkendes.