Visualiser data
En af de mest intuitive måder at analysere resultaterne af dataforespørgsler på er ved at visualisere dem som diagrammer. Notesbøger i Azure Databricks indeholder diagramfunktioner i brugergrænsefladen, og når denne funktionalitet ikke giver det, du har brug for, kan du bruge et af de mange Python-grafikbiblioteker til at oprette og få vist datavisualiseringer i notesbogen.
Brug af indbyggede notesbogdiagrammer
Når du får vist en dataramme eller kører en SQL-forespørgsel i en Spark-notesbog i Azure Databricks, vises resultaterne under kodecellen. Resultaterne gengives som standard som en tabel, men du kan også få vist resultaterne som en visualisering og tilpasse, hvordan diagrammet viser dataene, som vist her:
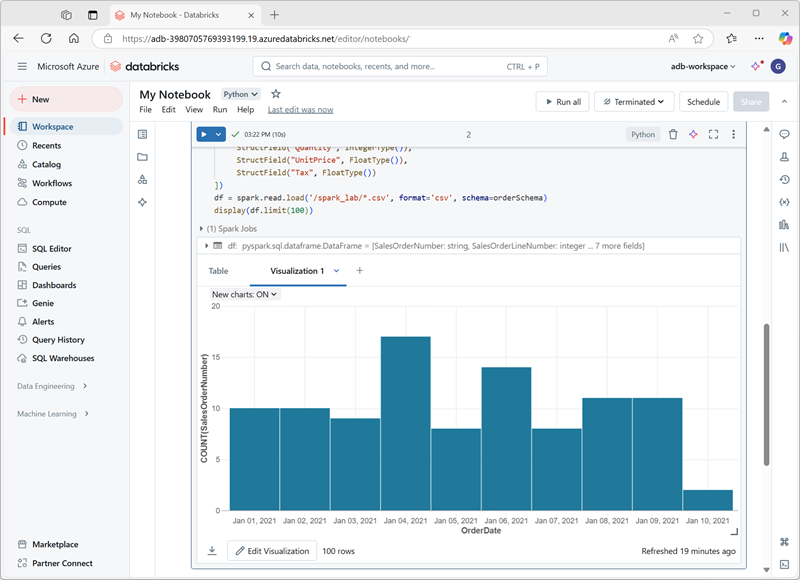
Visualiseringstyper
Det er de forskellige typer visualiseringer, du kan lave i Databricks, som hver især er gode til bestemte typer dataindsigt. Hovedpunkter:
Søjlediagrammer / Kurvediagrammer / Områdediagrammer: til at vise tendenser over tid, kategoriske sammenligninger eller begge dele. Nyttigt for at se, hvordan målinger udvikler sig.
Cirkeldiagrammer: god til at vise proportionale dele af en helhed (men ikke til tidsserier).
Histogram: for at se fordelingen af numeriske data (hvordan værdier spredes, grupperes).
Heatmap: nyttigt til visualisering af to kategoriske akser og farvelægning med en numerisk værdi, hjælper med at se mønstre på tværs af grupper.
Punkt-/boblediagrammer: viser forholdet mellem to (eller flere) numeriske variabler; bobler gør det muligt at bruge størrelse eller farve som en tredje dimension.
Box plot: for at sammenligne fordelinger (spredning, kvartiler, outliers) på tværs af kategorier.
Kombinationsdiagram: blanding af linjer og søjler i det samme diagram, nyttigt, hvor du vil sammenligne forskellige målinger med forskellige skalaer.
Pivottabel: Giver dig mulighed for at omforme og aggregere data i tabelform (f.eks. SQL PIVOT/GROUP BY), hvilket er nyttigt til analyser på tværs af tabulatorer.
Særlige typer: kohorteanalyse (sporing af grupper over tid), tællervisning (fremhævning af en enkelt oversigtsmetrik, måske mod mål), tragt, kortvisualiseringer (koroplet, markør), ordsky osv. Disse er mere specialiserede.
Den indbyggede visualiseringsfunktionalitet i notesbøger er nyttig, når du hurtigt vil opsummere dataene visuelt. Når du vil have mere kontrol over, hvordan dataene formateres, eller hvis du vil have vist værdier, som du allerede har samlet i en forespørgsel, bør du overveje at bruge en grafikpakke til at oprette dine egne visualiseringer.
Brug af grafikpakker i kode
Der er mange grafikpakker, som du kan bruge til at oprette datavisualiseringer i kode. Python understøtter især et stort udvalg af pakker. de fleste af dem bygget på basen Matplotlib bibliotek. Outputtet fra et grafikbibliotek kan gengives i en notesbog, hvilket gør det nemt at kombinere kode til indfødning og manipulere data med indbyggede datavisualiseringer og markdown-celler for at angive kommentarer.
Du kan f.eks. bruge følgende PySpark-kode til at aggregere data fra de hypotetiske produktdata, der tidligere blev udforsket i dette modul, og bruge Matplotlib til at oprette et diagram ud fra de aggregerede data.
from matplotlib import pyplot as plt
# Get the data as a Pandas dataframe
data = spark.sql("SELECT Category, COUNT(ProductID) AS ProductCount \
FROM products \
GROUP BY Category \
ORDER BY Category").toPandas()
# Clear the plot area
plt.clf()
# Create a Figure
fig = plt.figure(figsize=(12,8))
# Create a bar plot of product counts by category
plt.bar(x=data['Category'], height=data['ProductCount'], color='orange')
# Customize the chart
plt.title('Product Counts by Category')
plt.xlabel('Category')
plt.ylabel('Products')
plt.grid(color='#95a5a6', linestyle='--', linewidth=2, axis='y', alpha=0.7)
plt.xticks(rotation=70)
# Show the plot area
plt.show()
Matplotlib-biblioteket kræver, at data er i en Pandas-dataramme i stedet for en Spark-dataramme, så toPandas-metoden bruges til at konvertere den. Koden opretter derefter et tal med en angivet størrelse og afbilder et liggende søjlediagram med en brugerdefineret egenskabskonfiguration, før det resulterende afbildning vises.
Det diagram, der er oprettet af koden, ligner følgende billede:
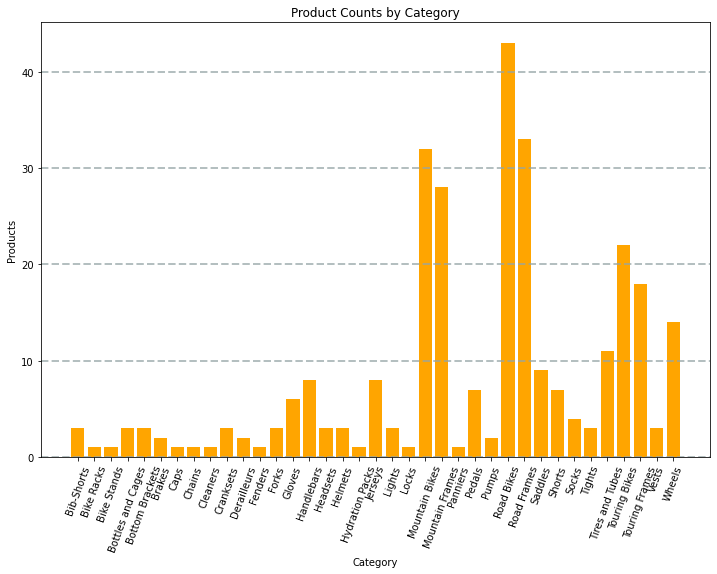
Du kan bruge matplotlib-biblioteket til at oprette mange diagramtyper. eller hvis du foretrækker det, kan du bruge andre biblioteker, f.eks . Seaborn , til at oprette meget tilpassede diagrammer.
Seddel
Matplotlib- og Seaborn-bibliotekerne er muligvis allerede installeret på Databricks-klynger, afhængigt af Databricks Runtime for klyngen. Hvis ikke, eller hvis du vil bruge et andet bibliotek, der ikke allerede er installeret, kan du føje det til klyngen. Du kan finde flere oplysninger i Klyngebiblioteker i dokumentationen til Azure Databricks.