Udforsk løsningsarkitekturen
Lad os gennemgå den arkitektur, du har besluttet dig for machine learning-handlinger (MLOps) arbejdsproces for at forstå, hvor og hvornår vi skal bekræfte koden.
Seddel
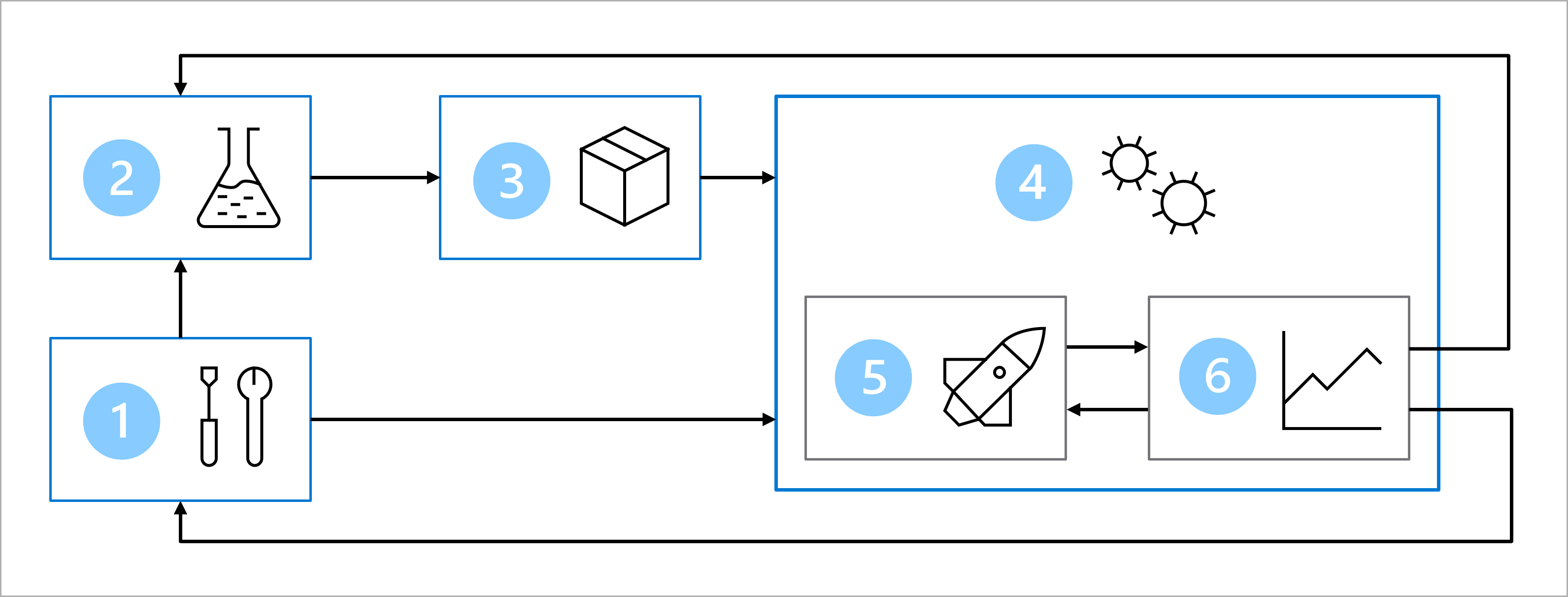
Diagrammet er en forenklet repræsentation af en MLOps-arkitektur. Hvis du vil have vist en mere detaljeret arkitektur, skal du udforske de forskellige use cases i MLOps (v2)-løsningsaccelerator.
MlOps-arkitekturens primære mål er at skabe en robust og reproducerbar løsning. For at opnå dette omfatter arkitekturen:
- installation: Opret alle nødvendige Azure-ressourcer til løsningen.
- Modeludvikling (indre løkke): Udforsk og behandl dataene for at oplære og evaluere modellen.
- Kontinuerlig integration: Pak og registrer modellen.
- modelinstallation (ydre løkke): Udrul modellen.
- Kontinuerlig udrulning: Test modellen, og hæv til produktionsmiljøet.
- Overvågning: Overvåg modellens og slutpunktsydeevnen.
Hvis du vil flytte en model fra udvikling til udrulning, skal du have løbende integration. Under løbende integration skal du pakke og registrere modellen. Før du pakker en model, skal du dog bekræfte den kode, der bruges til at oplære modellen.
Sammen med datavidenskabsteamet har du accepteret at bruge trunkbaseret udvikling. Ikke alene beskytter forgreninger produktionskoden, den giver dig også mulighed for automatisk at bekræfte eventuelle foreslåede ændringer, før du fletter den med produktionskoden.
Lad os udforske arbejdsprocessen for en dataforsker:
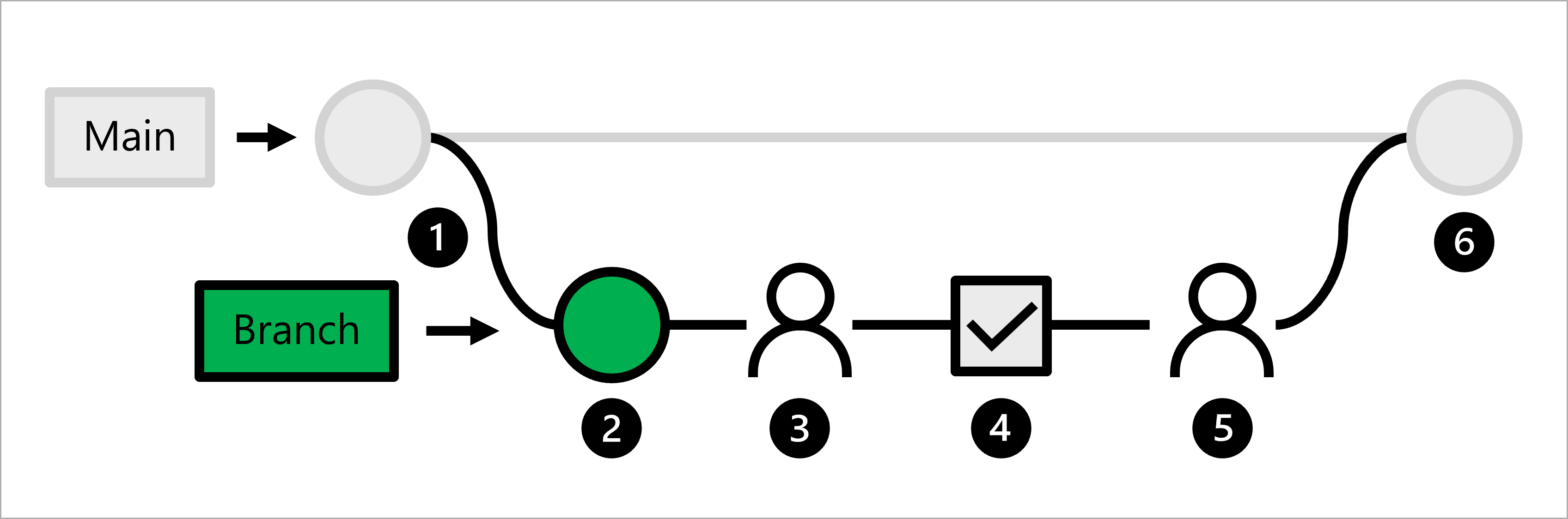
- Produktionskoden hostes i forgreningen .
- En dataforsker opretter en funktionsgren til modeludvikling.
- Dataforskeren opretter en pullanmodning til at foreslå at sende ændringer til hovedgrenen.
- Når der oprettes en pullanmodning, udløses en GitHub-handlingsarbejdsproces for at bekræfte koden.
- Når koden passerer linting og enhedstest, skal den ledende dataforsker godkende de foreslåede ændringer.
- Når dataforskeren for kundeemnet har godkendt ændringerne, er pullanmodningen flettet, og hovedgrenen opdateres tilsvarende.
Som maskinlæringstekniker skal du oprette en GitHub-handlingsarbejdsproces, der bekræfter koden ved at køre en linter- og enhedstest, hver gang der oprettes en pullanmodning.