Herstellen einer Verbindung zwischen Azure Data Factory und Microsoft Purview
In diesem Dokument werden die Schritte erläutert, die zum Verbinden eines Azure Data Factory-Kontos mit einem Microsoft Purview-Konto erforderlich sind, um die Datenherkunft nachzuverfolgen und Datenquellen zu erfassen. In dem Dokument werden auch die Details des Aktivitätsabdeckungsbereichs und der unterstützten Herkunftsmuster erläutert.
Wenn Sie eine verbindung zwischen einem Azure Data Factory und Microsoft Purview herstellen, werden bei jeder Ausführung einer unterstützten Azure Data Factory Aktivität Metadaten zu den Quelldaten der Aktivität, ausgabedaten und der Aktivität automatisch im Microsoft Purview Data Map erfasst.
Wenn eine Datenquelle bereits gescannt wurde und in der Datenzuordnung vorhanden ist, fügt der Erfassungsprozess die Herkunftsinformationen aus Azure Data Factory dieser vorhandenen Quelle hinzu. Wenn die Quelle oder Ausgabe nicht in der Data Map vorhanden ist und von Azure Data Factory Herkunft unterstützt wird, fügt Microsoft Purview automatisch metadaten aus Azure Data Factory der Data Map unter der Stammsammlung hinzu.
Dies kann eine hervorragende Möglichkeit sein, Ihren Datenbestand zu überwachen, wenn Benutzer Informationen mithilfe von Azure Data Factory verschieben und transformieren.
Anzeigen vorhandener Data Factory-Verbindungen
Mehrere Azure Data Factorys können eine Verbindung mit einem einzelnen Microsoft Purview herstellen, um Datenherkunftsinformationen per Push zu übertragen. Mit dem aktuellen Grenzwert können Sie über das Microsoft Purview Management Center bis zu 10 Data Factory-Konten gleichzeitig verbinden. Gehen Sie wie folgt vor, um die Liste der Data Factory-Konten anzuzeigen, die mit Ihrem Microsoft Purview-Konto verbunden sind:
Wählen Sie im linken Navigationsbereich Verwaltung aus.
Wählen Sie unter Herkunftsverbindungen die Option Data Factory aus.
Die Data Factory-Verbindungsliste wird angezeigt.

Beachten Sie die verschiedenen Werte für Verbindungsstatus:
- Verbunden: Die Data Factory ist mit dem Microsoft Purview-Konto verbunden.
- Getrennt: Data Factory hat Zugriff auf den Katalog, ist aber mit einem anderen Katalog verbunden. Daher wird die Datenherkunft nicht automatisch an den Katalog gemeldet.
- Unbekannt: Der aktuelle Benutzer hat keinen Zugriff auf Data Factory, sodass die Verbindung status unbekannt ist.

Hinweis
Zum Anzeigen der Data Factory-Verbindungen muss Ihnen die folgende Rolle zugewiesen werden. Die Rollenvererbung aus einer Verwaltungsgruppe wird nicht unterstützt. Rolle "Sammlungsadministratoren" für die Stammsammlung.
Erstellen einer neuen Data Factory-Verbindung
Hinweis
Zum Hinzufügen oder Entfernen der Data Factory-Verbindungen muss Ihnen die folgende Rolle zugewiesen werden. Die Rollenvererbung aus einer Verwaltungsgruppe wird nicht unterstützt. Rolle "Sammlungsadministratoren" für die Stammsammlung.
Außerdem müssen die Benutzer als "Besitzer" oder "Mitwirkender" der Data Factory verwendet werden.
Für Ihre Data Factory muss eine vom System zugewiesene verwaltete Identität aktiviert sein.
Führen Sie die folgenden Schritte aus, um eine vorhandene Data Factory mit Ihrem Microsoft Purview-Konto zu verbinden. Sie können Data Factory auch über ADF mit dem Microsoft Purview-Konto verbinden.
Wählen Sie im linken Navigationsbereich Verwaltung aus.
Wählen Sie unter Herkunftsverbindungen die Option Data Factory aus.
Wählen Sie auf der Seite Data Factory-Verbindungdie Option Neu aus.
Wählen Sie In der Liste Ihr Data Factory-Konto und dann OK aus. Sie können auch nach dem Abonnementnamen filtern, um Ihre Liste einzuschränken.
Einige Data Factory-Instanzen sind möglicherweise deaktiviert, wenn die Data Factory bereits mit dem aktuellen Microsoft Purview-Konto verbunden ist oder die Data Factory keine verwaltete Identität hat.
Wenn eine der ausgewählten Data Factorys bereits mit einem anderen Microsoft Purview-Konto verbunden ist, wird eine Warnmeldung angezeigt. Wenn Sie OK auswählen, wird die Data Factory-Verbindung mit dem anderen Microsoft Purview-Konto getrennt. Es sind keine weiteren Bestätigungen erforderlich.
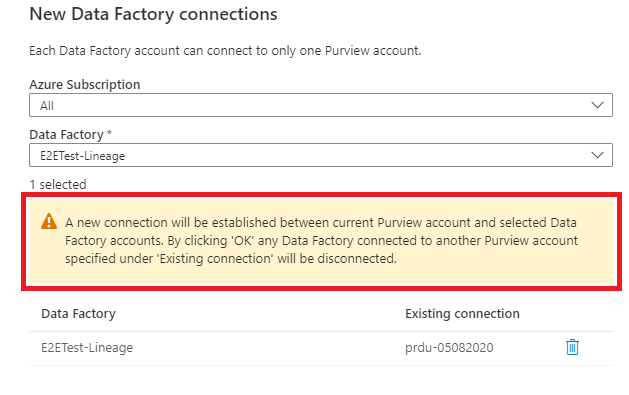
Hinweis
Wir unterstützen das Gleichzeitige Hinzufügen von bis zu 10 Azure Data Factory Konten. Wenn Sie mehr als 10 Data Factory-Konten hinzufügen möchten, tun Sie dies in mehreren Batches.
Funktionsweise der Authentifizierung
Die verwaltete Identität von Data Factory wird verwendet, um Datenherkunfts-Pushvorgänge von Data Factory an Microsoft Purview zu authentifizieren. Wenn Sie Ihre Data Factory mit Microsoft Purview auf der Benutzeroberfläche verbinden, wird die Rollenzuweisung automatisch hinzugefügt.
Weisen Sie der verwalteten Identität der Data Factory die Rolle Datenkurator für die Microsoft Purview-Stammsammlung zu. Weitere Informationen finden Sie unter Zugriffssteuerung in Microsoft Purview und Hinzufügen von Rollen und Einschränken des Zugriffs über Sammlungen.
Entfernen von Data Factory-Verbindungen
Gehen Sie wie folgt vor, um eine Data Factory-Verbindung zu entfernen:
Wählen Sie auf der Seite Data Factory-Verbindung die Schaltfläche Entfernen neben einer oder mehreren Data Factory-Verbindungen aus.
Wählen Sie im Popup die Option Bestätigen aus, um die ausgewählten Data Factory-Verbindungen zu löschen.


Überwachen der Data Factory-Links
Im Microsoft Purview-Governanceportal können Sie die Data Factory-Links überwachen.
Unterstützte Azure Data Factory-Aktivitäten
Microsoft Purview erfasst die Laufzeitherkunft aus den folgenden Azure Data Factory Aktivitäten:
Wichtig
Microsoft Purview löscht die Herkunft, wenn die Quelle oder das Ziel ein nicht unterstütztes Datenspeichersystem verwendet.
Die Integration zwischen Data Factory und Microsoft Purview unterstützt nur eine Teilmenge der Von Data Factory unterstützten Datensysteme, wie in den folgenden Abschnitten beschrieben.
Copy-Aktivität Support
| Datenspeicher | Unterstützt |
|---|---|
| Azure Blob Storage | Ja |
| Azure Cognitive Search | Ja |
| Azure Cosmos DB for NoSQL * | Ja |
| Azure Cosmos DB for MongoDB * | Ja |
| Azure Data Explorer * | Ja |
| Azure Data Lake Storage Gen1 | Ja |
| Azure Data Lake Storage Gen2 | Ja |
| Azure Database for MariaDB * | Ja |
| Azure Database for MySQL * | Ja |
| Azure Database for PostgreSQL * | Ja |
| Azure Files | Ja |
| Azure SQL-Datenbank * | Ja |
| Azure SQL Managed Instance * | Ja |
| Azure Synapse Analytics * | Ja |
| Dedizierter Azure SQL-Pool (früher SQL DW) * | Ja |
| Azure Table Storage | Ja |
| Amazon S3 | Ja |
| Bienenkorb* | Ja |
| Orakel* | Ja |
| SAP-Tabelle (beim Herstellen einer Verbindung mit SAP ECC oder SAP S/4HANA) | Ja |
| SQL Server * | Ja |
| Teradata * | Ja |
* Microsoft Purview unterstützt derzeit keine Abfrage oder gespeicherte Prozedur für Die Herkunft oder Überprüfung. Die Herkunft ist nur auf Tabellen- und Sichtquellen beschränkt.
Wenn Sie selbstgehostete Integration Runtime verwenden, beachten Sie die Minimale Version mit Herkunftsunterstützung für:
- Beliebiger Anwendungsfall: Version 5.9.7885.3 oder höher
- Kopieren von Daten aus Oracle: Version 5.10 oder höher
- Kopieren von Daten in Azure Synapse Analytics per COPY-Befehl oder PolyBase: Version 5.10 oder höher
Einschränkungen bei der Herkunft der Kopieraktivität
Wenn Sie die folgenden Features der Kopieraktivität verwenden, wird die Herkunft derzeit noch nicht unterstützt:
- Kopieren Sie Daten mithilfe des Binärformats in Azure Data Lake Storage Gen1.
- Komprimierungseinstellung für Binärdateien, durch Trennzeichen getrennte Text-, Excel-, JSON- und XML-Dateien.
- Quellpartitionsoptionen für Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, SQL Server und SAP Table.
- Kopieren Sie Daten in eine dateibasierte Senke mit der Einstellung max. Zeilen pro Datei.
- Die Herkunft auf Spaltenebene wird derzeit von der Kopieraktivität nicht unterstützt, wenn die Quelle/Senke eine Ressourcengruppe ist.
Zusätzlich zur Herkunft wird das Datenassetschema (auf der Registerkarte Asset –> Schema) für die folgenden Connectors gemeldet:
- CSV- und Parquet-Dateien in Azure Blob, Azure Files, ADLS Gen1, ADLS Gen2 und Amazon S3
- Azure Data Explorer, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, SQL Server, Teradata
Datenfluss Support
| Datenspeicher | Unterstützt |
|---|---|
| Azure Blob Storage | Ja |
| Azure Cosmos DB for NoSQL * | Ja |
| Azure Data Lake Storage Gen1 | Ja |
| Azure Data Lake Storage Gen2 | Ja |
| Azure Database for MySQL * | Ja |
| Azure Database for PostgreSQL * | Ja |
| Azure SQL-Datenbank * | Ja |
| Azure SQL Managed Instance * | Ja |
| Azure Synapse Analytics * | Ja |
| Dedizierter Azure SQL-Pool (früher SQL DW) * | Ja |
* Microsoft Purview unterstützt derzeit keine Abfrage oder gespeicherte Prozedur für Die Herkunft oder Überprüfung. Die Herkunft ist nur auf Tabellen- und Sichtquellen beschränkt.
Einschränkungen der Datenflussherkunft
- Die Datenflussherkunft kann ressourcensatz auf Ordnerebene generieren, ohne dass die beteiligten Dateien sichtbar sind.
- Die Herkunft auf Spaltenebene wird derzeit nicht unterstützt, wenn die Quelle/Senke eine Ressourcengruppe ist.
- Für die Herkunft der Datenflussaktivität unterstützt Microsoft Purview nur die Anzeige der beteiligten Quelle und Senke. Die detaillierte Datenherkunft für die Datenflusstransformation wird noch nicht unterstützt.
- Die Herkunft wird nicht unterstützt, wenn Flowlets Teil des Dataflows sind.
- Derzeit unterstützt Purview keine Herkunftsberichterstellung für Synapse-Tabellen (LakeHouse DB/Workspace DB)
SSIS-Paketunterstützung ausführen
Weitere Informationen finden Sie unter Unterstützte Datenspeicher.
Zugriff auf ein gesichertes Microsoft Purview-Konto
Wenn Ihr Microsoft Purview-Konto durch eine Firewall geschützt ist, erfahren Sie, wie Data Factory über private Microsoft Purview-Endpunkte auf ein gesichertes Microsoft Purview-Konto zugreifen kann.
Übertragen der Data Factory-Herkunft in Microsoft Purview
Eine umfassende exemplarische Vorgehensweise finden Sie im Tutorial: Pushen von Data Factory-Herkunftsdaten an Microsoft Purview.
Unterstützte Herkunftsmuster
Es gibt mehrere Muster der Herkunft, die Microsoft Purview unterstützt. Die generierten Datenherkunftsdaten basieren auf dem Typ der Quelle und Senke, die in den Data Factory-Aktivitäten verwendet werden. Obwohl Data Factory mehr als 80 Quellen und Senken unterstützt, unterstützt Microsoft Purview nur eine Teilmenge, wie unter Unterstützte Azure Data Factory Aktivitäten aufgeführt.
Informationen zum Konfigurieren von Data Factory zum Senden von Datenherkunftsinformationen finden Sie unter Erste Schritte mit der Herkunft.
Einige andere Möglichkeiten zum Auffinden von Informationen in der Herkunftsansicht umfassen Folgendes:
- Zeigen Sie auf der Registerkarte Herkunft auf Shapes, um zusätzliche Informationen zum Medienobjekt in der QuickInfo anzuzeigen.
- Wählen Sie den Knoten oder Edge aus, um den Objekttyp anzuzeigen, zu dem er gehört, oder um Ressourcen zu wechseln.
- Spalten eines Datasets werden auf der linken Seite der Registerkarte Herkunft angezeigt. Weitere Informationen zur Herkunft auf Spaltenebene finden Sie unter Datasetspaltenherkunft.
Datenherkunft für 1:1-Vorgänge
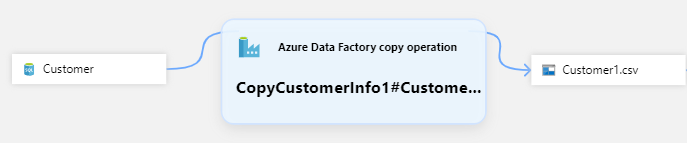
Das häufigste Muster zum Erfassen der Datenherkunft ist das Verschieben von Daten aus einem einzelnen Eingabedataset in ein einzelnes Ausgabedataset mit einem Prozess dazwischen.
Ein Beispiel für dieses Muster wäre folgendes:
- 1 Quelle/Eingabe: Kunde (SQL-Tabelle)
- 1 Senke/Ausgabe: Customer1.csv (Azure-Blob)
- 1 Prozess: CopyCustomerInfo1#Customer1.csv (Data Factory Copy-Aktivität)
Datenverschiebung mit 1:1-Herkunfts- und Wildcardunterstützung
Ein weiteres gängiges Szenario zum Erfassen der Herkunft ist die Verwendung eines Wildcards zum Kopieren von Dateien aus einem einzelnen Eingabedataset in ein einzelnes Ausgabedataset. Der Wildcard ermöglicht es der Kopieraktivität, mehrere Dateien zum Kopieren mithilfe eines gemeinsamen Teils des Dateinamens abzugleichen. Microsoft Purview erfasst die Herkunft auf Dateiebene für jede einzelne Datei, die von der entsprechenden Kopieraktivität kopiert wurde.
Ein Beispiel für dieses Muster wäre folgendes:
- Quelle/Eingabe: CustomerCall*.csv (ADLS Gen2-Pfad)
- Senke/Ausgabe: CustomerCall*.csv (Azure-Blobdatei)
- 1 Prozess: CopyGen2ToBlob#CustomerCall.csv (Data Factory Copy-Aktivität)

Datenverschiebung mit n:1-Herkunft
Sie können Datenfluss Aktivitäten verwenden, um Datenvorgänge wie Zusammenführung, Verknüpfung usw. auszuführen. Zum Erstellen eines Zieldatasets können mehrere Quelldatasets verwendet werden. In diesem Beispiel erfasst Microsoft Purview die Herkunft einzelner Eingabedateien auf Dateiebene in einer SQL-Tabelle, die Teil einer Datenfluss-Aktivität ist.
Ein Beispiel für dieses Muster wäre folgendes:
- 2 Quellen/Eingaben: Customer.csv, Sales.parquet (ADLS Gen2-Pfad)
- 1 Senke/Ausgabe: Unternehmensdaten (Azure SQL Tabelle)
- 1 Prozess: DataFlowBlobsToSQL (Data Factory Datenfluss-Aktivität)

Herkunft für Ressourcensätze
Ein Ressourcensatz ist ein logisches Objekt im Katalog, das viele Partitionsdateien im zugrunde liegenden Speicher darstellt. Weitere Informationen finden Sie unter Grundlegendes zu Ressourcensätzen. Wenn Microsoft Purview die Herkunft aus dem Azure Data Factory erfasst, wendet es die Regeln an, um die einzelnen Partitionsdateien zu normalisieren und ein einzelnes logisches Objekt zu erstellen.
Im folgenden Beispiel wird eine Azure Data Lake Gen2-Ressourcengruppe aus einem Azure-Blob erstellt:
- 1 Quelle/Eingabe: Employee_management.csv (Azure-Blob)
- 1 Senke/Ausgabe: Employee_management.csv (Azure Data Lake Gen 2)
- 1 Prozess: CopyBlobToAdlsGen2_RS (Data Factory-Copy-Aktivität)

Nächste Schritte
Tutorial: Pushen von Data Factory-Datenherkunftsdaten an Microsoft Purview