Anstatt nur den aktuellen Zustand der Daten in einer Domäne zu speichern, verwenden Sie einen nur zum Anfügen vorgesehenen Speicher, um die vollständige Serie von Aktionen aufzuzeichnen, die mit diesen Daten ausgeführt wurden. Der Speicher fungiert als Aufzeichnungssystem und kann zum Materialisieren der Domänenobjekte verwendet werden. Dadurch lassen sich Tasks in komplexen Domänen vereinfachen, da Datenmodell und Geschäftsdomäne nicht mehr synchronisiert werden müssen. Gleichzeitig steigen Leistung, Skalierbarkeit und Reaktionsfähigkeit. Das Muster kann auch Konsistenz für Transaktionsdaten bieten und vollständige Überwachungspfade und -verläufe verwalten, die kompensierende Maßnahmen ermöglichen können.
Kontext und Problem
Die meisten Anwendungen basieren auf Daten. Der typische Ansatz besteht darin, dass die Anwendung den aktuellen Zustand der Daten verwaltet, indem sie die Daten aktualisiert, wenn Benutzer damit arbeiten. Im herkömmlichen CRUD-Modell (Create, Read, Update, Delete – Erstellen, Lesen, Aktualisieren, Löschen) sieht ein typischer Datenprozess folgendermaßen aus: Der Prozess liest Daten aus dem Speicher, nimmt einige Änderungen daran vor und aktualisiert den Zustand der Daten mit neuen Werten – häufig mithilfe von Transaktionen, die die Daten sperren.
Der CRUD-Ansatz weist einige Einschränkungen auf:
CRUD-Systeme führen Aktualisierungsvorgänge direkt für einen Datenspeicher aus. Dies kann aufgrund des erforderlichen Verarbeitungsaufwands die Leistung und Reaktionsfähigkeit verringern und die Skalierbarkeit einschränken.
In einer kollaborativen Domäne mit vielen gleichzeitigen Benutzern sind Datenaktualisierungskonflikte wahrscheinlicher, da die Aktualisierungsvorgänge in einem einzigen Datenelement stattfinden.
Sofern kein weiterer Überwachungsmechanismus vorhanden ist, der die Details jedes Vorgangs in einem separaten Protokoll aufzeichnet, ist der Verlauf nicht mehr nachvollziehbar.
Lösung
Das Ereignissourcingmuster definiert eine Vorgehensweise zur Verarbeitung von Daten, die auf einer Ereignissequenz basiert. Jedes Ereignis wird in einem nur zum Anfügen vorgesehenen Speicher aufgezeichnet. Der Anwendungscode sendet eine Reihe von Ereignissen, die zwingend jede Aktion beschreiben, die für die Daten im Ereignisspeicher ausgeführt wurde, in dem die Daten dauerhaft gespeichert sind. Jedes Ereignis stellt eine Reihe von Änderungen der Daten dar (z.B. AddedItemToOrder).
Die Ereignisse werden in einem Ereignisspeicher dauerhaft gespeichert, der als Aufzeichnungssystem (die maßgebliche Datenquelle) für den aktuellen Zustand der Daten fungiert. Der Ereignisspeicher veröffentlicht diese Ereignisse in der Regel, sodass Consumer benachrichtigt werden und die Ereignisse bei Bedarf verarbeiten können. Consumer könnten z.B. Tasks initiieren, die die Vorgänge in den Ereignissen auf andere Systeme anwenden, oder eine andere verknüpfte Aktion ausführen, die zum Abschließen des Vorgangs erforderlich ist. Beachten Sie, dass der Anwendungscode, der die Ereignisse generiert, von den Systemen abgekoppelt ist, die die Ereignisse abonnieren.
Typische Anwendungen der vom Ereignisspeicher veröffentlichten Ereignisse sind die Verwaltung materialisierter Sichten von Entitäten, wenn Aktionen in der Anwendung diese ändern, und die Integration in externe Systeme. Ein System kann z.B. eine materialisierte Sicht aller Kundenaufträge verwalten, die zum Auffüllen von Teilen der Benutzeroberfläche verwendet wird. Die Anwendung fügt neue Aufträge hinzu, fügt Artikel zu einem Auftrag hinzu oder entfernt sie und fügt Versandinformationen hinzu. Ereignisse, die diese Änderungen beschreiben, können verarbeitet und für die Aktualisierung der Materialisierten Sicht verwendet werden.
Anwendungen können den Ereignisverlauf zu jeder Zeit lesen. Anschließend können Sie ihn verwenden, um den aktuellen Status einer Entität zu materialisieren, indem Sie alle Ereignisse, die sich auf diese Entität beziehen, wiedergeben und verwenden. Dies kann bei Bedarf erfolgen, um bei der Verarbeitung einer Anforderung ein Domänenobjekt zu materialisieren. Alternativ kann der Vorgang durch einen geplanten Task ausgelöst werden, sodass der Zustand der Entität als materialisierte Sicht gespeichert werden kann, um die Darstellungsschicht zu unterstützen.
Die Abbildung zeigt eine Übersicht über das Muster, einschließlich einiger Optionen für die Verwendung des Ereignisstroms: Erstellen einer materialisierten Sicht, Integrieren von Ereignissen in externe Anwendungen und Systeme und die Wiedergabe von Ereignissen, um Projektionen des aktuellen Zustands bestimmter Entitäten zu erstellen.
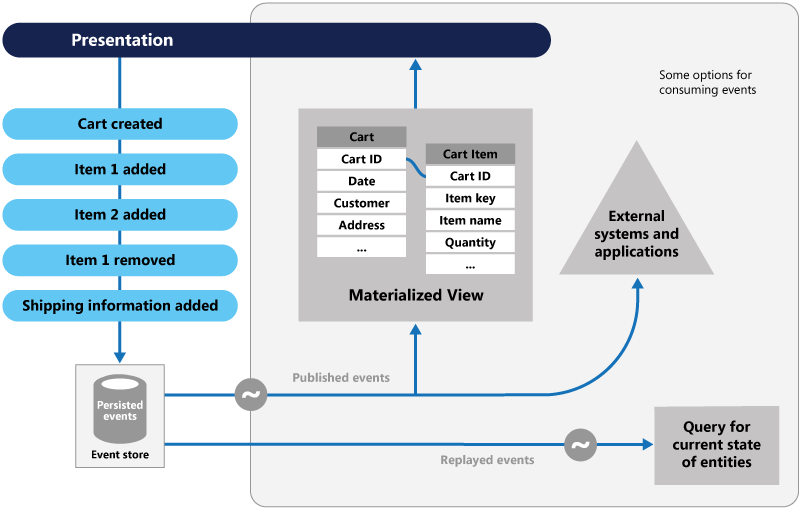
Das Ereignissourcingmuster bietet folgende Vorteile:
Ereignisse sind unveränderlich und können mit einem Nur-Anfügen-Vorgang gespeichert werden. Benutzeroberflächenelemente, Workflows oder Prozesse, die ein Ereignis auslösen, können weiterhin ausgeführt werden, und Tasks, die die Ereignisse verarbeiten, können im Hintergrund ausgeführt werden. In Verbindung mit der Tatsache, dass bei der Verarbeitung von Transaktionen keine Konflikte auftreten, kann dieser Vorgang die Leistung und Skalierbarkeit von Anwendungen erheblich verbessern, insbesondere für die Darstellungsschicht oder die Benutzeroberfläche.
Ereignisse sind einfache Objekte, die eine bestimmte durchgeführte Aktion sowie alle zugehörigen Daten beschreiben, die zum Beschreiben der durch das Ereignis repräsentierten Aktion erforderlich sind. Ereignisse aktualisieren einen Datenspeicher nicht direkt. Sie werden nur aufgezeichnet, um zur richtigen Zeit verarbeitet zu werden. Die Nutzung von Ereignissen kann die Implementierung und Verwaltung vereinfachen.
Ereignisse haben in der Regel eine Bedeutung für einen Domänenexperten, während die objektrelationale Unverträglichkeit (Object-Relational Impedance Mismatch) dazu führen kann, dass komplexe Datenbanktabellen schwer zu verstehen sind. Tabellen sind künstliche Konstrukte, die den aktuellen Zustand des Systems repräsentieren, nicht die aufgetretenen Ereignisse.
Ereignissourcing kann verhindern, dass gleichzeitige Updates Konflikte verursachen, weil Objekte nicht direkt im Datenspeicher aktualisiert werden müssen. Das Domänenmodell muss jedoch weiterhin so entworfen werden, dass es sich selbst vor Anforderungen schützen kann, die zu einem inkonsistenten Zustand führen könnten.
Die Nur-Anfügen-Speicherung von Ereignissen erzeugt ein Überwachungsprotokoll, mit dem Handlungen in Bezug auf einen Datenspeicher überwacht werden können. Somit kann der aktuelle Status in Form von materialisierten Sichten oder Projektionen erneut generiert werden, indem die Ereignisse zu einem beliebigen Zeitpunkt erneut wiedergegeben werden. Dies unterstützt zudem die Prüfung und das Debuggen des Systems. Da ausgleichende Ereignisse zum Abbrechen von Änderungen verwendet werden müssen, entsteht zudem ein Protokoll der zurückgenommenen Änderungen. Diese Funktion wäre nicht gegeben, wenn das Modell den aktuellen Zustand speichern würde. Die Liste der Ereignisse kann auch verwendet werden, um die Anwendungsleistung zu analysieren und Trends im Benutzerverhalten zu erkennen. Sie kann zudem verwendet werden, um andere nützliche Geschäftsinformationen zu erhalten.
Der Ereignisspeicher löst Ereignisse aus, Tasks führen Vorgänge als Reaktion auf diese Ereignisse aus. Diese Abkopplung der Tasks von den Ereignissen sorgt für Flexibilität und Erweiterbarkeit. Tasks kennen den Ereignistyp und die Ereignisdaten, aber nicht den Vorgang, der das Ereignis ausgelöst hat. Darüber hinaus kann jedes Ereignis von mehreren Tasks verarbeitet werden. Dies ermöglicht eine einfache Integration in andere Dienste und Systeme, die nur auf neue vom Ereignisspeicher ausgelöste Ereignisse lauschen. Die Ereignisse beim Ereignissourcing sind jedoch zuweilen sehr spezifisch, und es ist möglicherweise erforderlich, stattdessen spezielle Integrationsereignisse zu generieren.
Das Ereignissourcing wird häufig mit dem CQRS-Muster kombiniert, indem als Reaktion auf die Ereignisse Datenverwaltungstasks ausgeführt und aus den gespeicherten Ereignissen Sichten materialisiert werden.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei der Entscheidung, wie dieses Muster implementiert werden soll:
Das System ist nur dann letztlich konsistent, wenn durch Wiedergabe von Ereignissen materialisierte Sichten erstellt oder Projektionen generiert werden. Es gibt eine gewisse Verzögerung zwischen dem Hinzufügen von Ereignissen zum Ereignisspeicher durch eine Anwendung nach der Verarbeitung einer Anforderung, dem Veröffentlichen der Ereignisse und dem Verarbeiten der Ereignisse durch die Consumer. Während dieses Zeitraums können neue Ereignisse im Ereignisspeicher eingegangen sein, die weitere Änderungen an Entitäten beschreiben. Das System sollte so konzipiert sein, dass in diesen Szenarien eine eventuelle Konsistenz berücksichtigt wird.
Hinweis
Weitere Informationen zur letztlichen Konsistenz finden Sie unter Data Consistency Primer (Grundlagen der Datenkonsistenz).
Der Ereignisspeicher ist die dauerhafte Informationsquelle, daher sollten Ereignisdaten niemals aktualisiert werden. Die einzige Möglichkeit, eine Entität zu aktualisieren, um eine Änderung rückgängig zu machen, besteht darin, dem Ereignisspeicher ein kompensierendes Ereignis hinzuzufügen. Wenn das Format (nicht die Daten) der dauerhaft gespeicherten Ereignisse geändert werden muss – möglicherweise während einer Migration –, kann es schwierig sein, vorhandene Ereignisse im Speicher mit der neuen Version zu kombinieren. Möglicherweise müssen alle Ereignisse durchlaufen werden, die Änderungen vornehmen, sodass die Ereignisse mit dem neuen Format konform sind. Eventuell müssen auch neue Ereignisse hinzugefügt werden, die das neue Format verwenden. Ziehen Sie in Betracht, einen Versionsstempel für jede Version des Ereignisschemas zu verwenden, um sowohl das alte als auch das neue Ereignisformat beizubehalten.
Möglicherweise speichern Anwendungen mit mehreren Threads und mehrere Instanzen von Anwendungen Ereignisse im Ereignisspeicher. Die Konsistenz der Ereignisse im Ereignisspeicher ist von entscheidender Bedeutung, ebenso wie die Reihenfolge der Ereignisse, die eine bestimmte Entität betreffen (die Reihenfolge, in der Änderungen auf eine Entität angewendet werden, wirkt sich auf den aktuellen Zustand aus). Durch Hinzufügen eines Zeitstempels zu jedem Ereignis lassen sich Probleme verhindern. Eine weitere häufige Vorgehensweise besteht darin, jedes Ereignis, das aus einer Anforderung resultiert, mit einem inkrementellen Bezeichner zu kommentieren. Wenn zwei Aktionen versuchen, gleichzeitig Ereignisse für die gleiche Entität hinzuzufügen, kann der Ereignisspeicher ein Ereignis ablehnen, das mit einem vorhandenen Entitätsbezeichner und einem vorhandenen Ereignisbezeichner übereinstimmt.
Es gibt keine Standardmethode oder vorhandene Mechanismen wie beispielsweise SQL-Abfragen, um Informationen aus Ereignissen auszulesen. Die einzigen Daten, die extrahiert werden können, sind Ereignisströme. Hierbei wird ein Ereignisbezeichner als Kriterium verwendet. Die Ereignis-ID lässt sich in der Regel einzelnen Entitäten zuordnen. Der aktuelle Zustand einer Entität kann nur bestimmt werden, indem alle Ereignisse, die sich auf sie beziehen, im Vergleich zum ursprünglichen Zustand der Entität wiedergegeben werden.
Die Länge der einzelnen Ereignisströme wirkt sich auf die Verwaltung und Aktualisierung des Systems aus. Wenn die Ströme umfangreich sind, kann es sinnvoll sein, in bestimmten Intervallen – z.B. nach einer bestimmten Anzahl von Ereignissen – Momentaufnahmen zu erstellen. Der aktuelle Zustand der Entität kann aus der Momentaufnahme abgerufen werden, indem alle Ereignisse wiedergegeben werden, die nach diesem Zeitpunkt aufgetreten sind. Weitere Informationen zum Erstellen von Momentaufnahmen von Daten finden Sie unter Primäre und untergeordnete Momentaufnahmereplikation.
Auch wenn das Ereignissourcing das Risiko von Aktualisierungskonflikten bei den Daten minimiert, muss die Anwendung dennoch weiterhin in der Lage sein, Inkonsistenzen zu bewältigen, die aus der letztlichen Konsistenz und dem Fehlen von Transaktionen entstehen. So kann beispielsweise ein Ereignis, das eine Verringerung des Bestands anzeigt, im Datenspeicher ankommen, während eine Bestellung für den betreffenden Artikel eintrifft. In dieser Situation müssen die beiden Vorgänge in Einklang gebracht werden. Entweder muss der Kunde darauf hingewiesen oder eine Nachbestellung erstellt werden.
Weil eine Ereignisveröffentlichung als at least once (mindestens einmal) festgelegt sein könnte, müssen Consumer der Ereignisse idempotent sein. Sie dürfen das in einem Ereignis beschriebene Update nicht erneut anwenden, wenn das Ereignis mehr als einmal verarbeitet wird. Mehrere Instanzen eines Consumers können gleichzeitig die Eigenschaften einer Entität aggregieren und verwalten, z. B. die Gesamtzahl der Aufträge. Wenn ein Auftrag eingeht, muss nur einer davon den aggregierten Wert inkrementell erhöhen. Dies ist zwar kein entscheidendes Merkmal des Ereignissourcings, spiegelt jedoch die übliche Implementierungsentscheidung wider.
Der ausgewählte Ereignisspeicher muss die von Ihrer Anwendung generierte Ereignislast unterstützen.
Seien Sie vorsichtig bei Szenarien, in denen die Verarbeitung eines Ereignisses die Erzeugung eines oder mehrerer neuer Ereignisse nach sich zieht, da dies zu einer Endlosschleife führen kann.
Verwendung dieses Musters
Verwenden Sie dieses Muster in folgenden Szenarien:
Sie möchten eine Absicht, einen Zweck oder einen Grund in den Daten erfassen. Änderungen an einer Kundenentität können z. B. als Reihe von bestimmten Ereignistypen erfasst werden, wie etwa Umgezogen, Konto gekündigt oder Verstorben.
Es ist von entscheidender Bedeutung, Aktualisierungskonflikte bei Daten zu minimieren oder vollständig zu vermeiden.
Sie möchten auftretende Ereignisse aufzeichnen und wiedergeben, um den Zustand eines Systems wiederherzustellen, Änderungen rückgängig zu machen oder ein Verlaufs- und Überwachungsprotokoll zu pflegen. Wenn beispielsweise ein Task mehrere Schritte umfasst, müssen Sie möglicherweise Aktionen ausführen, um Updates rückgängig zu machen, und dann einige Schritte wiedergeben, um die Daten wieder in einen konsistenten Zustand zu versetzen.
Wenn Sie Ereignisse verwenden. Dies ist eine natürliche Betriebsfunktion der Anwendung und erfordert wenig zusätzlichen Aufwand bei Entwicklung und Implementierung.
Sie müssen den Prozess der Eingabe oder Aktualisierung von Daten von den Tasks abkoppeln, die zum Anwenden dieser Aktionen erforderlich sind. Diese Änderung kann dazu dienen, die Leistung der Benutzeroberfläche zu verbessern oder Ereignisse auf andere Listener zu verteilen, die eine Aktion ausführen, wenn die Ereignisse auftreten. Sie können z. B. ein Lohnabrechnungssystem mit einer Kostenübermittlungswebsite integrieren. Die als Antwort auf Datenaktualisierungen auf der Website vom Ereignisspeicher aufgerufenen Ereignisse würden dann sowohl von der Website als auch vom Lohnabrechnungssystem verwendet.
Wenn Sie mehr Flexibilität benötigen, um das Format der materialisierten Modelle und Entitätsdaten ändern zu können, wenn sich die Anforderungen ändern oder wenn Sie das Muster mit CQRS verwenden, müssen Sie ein Lesemodell oder die Ansichten anpassen, die die Daten verfügbar machen.
Wenn Sie das Muster mit CQRS verwenden und die letztliche Konsistenz während der Aktualisierung eines Lesemodells annehmbar ist oder die Leistungsbeeinträchtigung durch das Aktivieren von Entitäten und Daten aus einem Ereignisstrom annehmbar ist.
Dieses Muster ist in den folgenden Situationen eventuell nicht nützlich:
Kleine oder einfache Domänen, Systeme ohne oder mit nur geringfügiger Geschäftslogik oder Systeme ohne Domäne, die naturgemäß gut mit herkömmlichen CRUD-Datenverwaltungsmechanismen funktionieren.
Systeme, in denen Konsistenz und Echtzeitupdates der Datensichten erforderlich sind.
Systeme, in den Überwachungspfade, Verlaufsinformationen und Funktionen zum Ausführen von Rollbacks und Wiedergeben von Aktionen nicht erforderlich sind.
Systeme, bei denen nur in geringem Maß Aktualisierungskonflikte bei den zugrunde liegenden Daten auftreten. Dies können z.B. Systeme sein, die Daten eher hinzufügen als aktualisieren.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Event Sourcing-Pattern im Design seines Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Säulen des Azure Well-Architected Framework behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Durch die Erfassung des Änderungsverlaufs in komplexen Geschäftsprozessen kann die Zustandsnachbildung erleichtert werden, wenn Sie Zustandsspeicher wiederherstellen müssen. - RE:06 Datenpartitionierung - RE:09 Notfallwiederherstellung |
| Die Leistungseffizienz hilft Ihrer Workload, Anforderungen effizient durch Optimierungen in Skalierung, Daten und Code zu erfüllen. | Dieses Muster kann in der Regel in Kombination mit CQRS, einem geeigneten Domänendesign und strategischen Momentaufnahmen die Workload-Leistung aufgrund der unteilbaren Vorgänge, die ausschließlich Anfügungen zulassen, und der Vermeidung von Datenbanksperren für Schreib- und Lesevorgänge verbessern. - PE:08 Datenleistung |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Ein Konferenzverwaltungssystem muss die Anzahl der abgeschlossenen Buchungen für eine Konferenz nachvollziehen können. So kann es prüfen, ob noch Sitzplätze vorhanden sind, wenn ein potenzieller Teilnehmer versucht, eine Buchung abzugeben. Das System kann die Gesamtanzahl von Buchungen für eine Konferenz auf mindestens zwei Arten speichern:
Das System kann die Informationen zur Gesamtanzahl von Buchungen als separate Entität in einer Datenbank speichern, die Buchungsinformationen enthält. Wenn Buchungen vorgenommen oder storniert werden, kann das System diese Zahl entsprechend erhöhen oder reduzieren. Dieser Ansatz ist in der Theorie sehr einfach, kann aber zu Skalierbarkeitsproblemen führen, wenn eine große Anzahl von Teilnehmern innerhalb kurzer Zeit versucht, Plätze zu buchen. Dies kann beispielsweise am letzten Tag des möglichen Buchungszeitraums der Fall sein.
Das System kann Informationen zu Buchungen und Stornierungen in Form von Ereignissen in einem Ereignisspeicher speichern. So kann das System die Anzahl der verfügbaren Plätze durch Wiedergabe dieser Ereignisse berechnen. Dieser Ansatz ist aufgrund der Unveränderlichkeit von Ereignissen besser skalierbar. Das System muss nur Daten aus dem Ereignisspeicher lesen oder an den Ereignisspeicher anfügen können. Ereignisinformationen zu Buchungen und Stornierungen werden niemals geändert.
Das folgende Diagramm veranschaulicht, wie das Platzreservierungs-Subsystem des Konferenzverwaltungssystems mithilfe des Ereignissourcingmusters implementiert werden könnte.
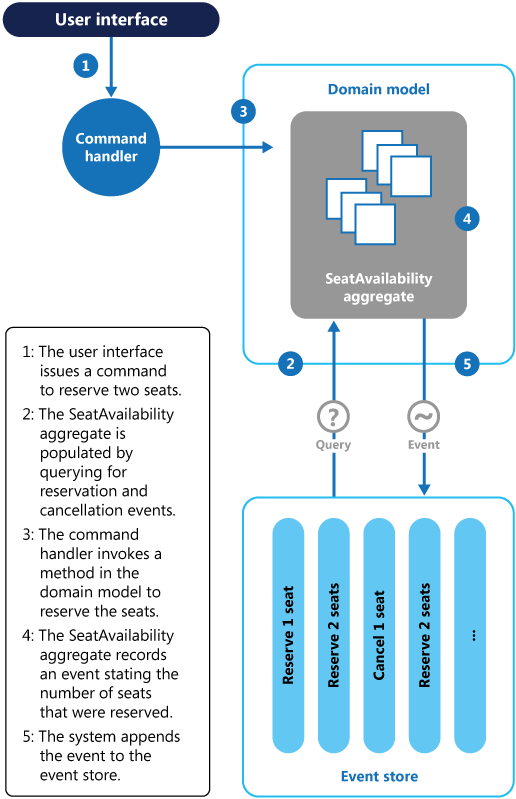
Die Aktionssequenz für die Reservierung von zwei Plätzen lautet folgendermaßen:
Die Benutzeroberfläche gibt einen Befehl aus, um Plätze für zwei Teilnehmer zu reservieren. Der Befehl wird von einem separaten Befehlshandler verarbeitet. Dies ist ein Stück Logik, das von der Benutzeroberfläche abgekoppelt ist und für die Verarbeitung von Anforderungen zuständig ist, die als Befehle übermittelt werden.
Es wird ein Aggregat mit Informationen zu allen Reservierungen für die Konferenz erstellt, indem die Ereignisse abgefragt werden, die Buchungen und Stornierungen beschreiben. Dieses Aggregat wird als
SeatAvailabilitybezeichnet und ist in einem Domänenmodell enthalten, das Methoden zum Abfragen und Ändern der Daten im Aggregat verfügbar macht.Ziehen Sie ggf. folgende Optimierungen in Betracht: Verwenden von Momentaufnahmen (damit Sie nicht die gesamte Liste der Ereignisse abfragen und wiedergeben müssen, um den aktuellen Zustand des Aggregats zu erhalten) und Zwischenspeichern einer Kopie des Aggregats im Arbeitsspeicher.
Der Befehlshandler ruft eine Methode auf, die vom Domänenmodell verfügbar gemacht wurde, um die Reservierungen vorzunehmen.
Das
SeatAvailability-Aggregat zeichnet ein Ereignis auf, das die Anzahl von reservierten Plätzen enthält. Wenn das Aggregat das nächste Mal Ereignisse anwendet, werden alle Reservierungen verwendet, um zu berechnen, wie viele Plätze verbleiben.Das System fügt das neue Ereignis an die Liste der Ereignisse im Ereignisspeicher an.
Wenn ein Benutzer einen Platz storniert, ist das Verfahren ähnlich – mit einer Ausnahme: Der Befehlshandler gibt einen Befehl aus, der ein Stornierungsereignis generiert und dieses an den Ereignisspeicher anfügt.
Ein Ereignisspeicher bietet nicht nur mehr Raum für Skalierbarkeit, sondern auch einen vollständigen Verlauf bzw. Überwachungspfad der Buchungen und Stornierungen für eine Konferenz. Die Ereignisse im Ereignisspeicher stellen den korrekten Datensatz dar. Es ist nicht notwendig, Aggregate auf andere Weise dauerhaft zu speichern, weil das System ganz einfach die Ereignisse wiedergeben und den Zustand auf einen beliebigen Zeitpunkt wiederherstellen kann.
Weitere Information zu diesem Beispiel finden Sie unter Introducing Event Sourcing (Einführung in das Ereignissourcing).
Nächste Schritte
Data Consistency Primer (Grundlagen der Datenkonsistenz). Wenn Sie das Ereignissourcing mit einem separaten Lesespeicher oder materialisierten Sichten verwenden, sind die gelesenen Daten nicht sofort konsistent. Stattdessen werden die Daten nur letztlich konsistent sein. Dieser Artikel bietet eine Übersicht über die Probleme bei der Gewährleistung von Konsistenz bei verteilten Daten.
Data Partitioning Guidance (Leitfaden zur Datenpartitionierung). Bei der Verwendung von Ereignissourcing werden Daten häufig partitioniert, um die Skalierbarkeit zu verbessern, Konflikte zu reduzieren und die Leistung zu optimieren. Dieser Artikel beschreibt, wie Daten auf getrennte Partitionen aufgeteilt werden, und erläutert mögliche Probleme.
Blog von Martin Fowler:
Zugehörige Ressourcen
Die folgenden Muster und Anweisungen können für die Implementierung dieses Musters ebenfalls relevant sein:
CQRS-Muster (Command and Query Responsibility Segregation). Der Schreibspeicher, der die permanente Informationsquelle für eine CQRS-Implementierung bereitstellt, basiert oft auf einer Implementierung des Ereignissourcingmusters. Das Muster beschreibt, wie mithilfe separater Schnittstellen die Vorgänge, die Daten in einer Anwendung lesen, von den Vorgängen getrennt werden, die Daten aktualisieren.
Muster „Materialisierte Sichten“: Der Datenspeicher, der in einem auf Ereignissourcing basierenden System verwendet wird, eignet sich in der Regel nicht gut für effiziente Abfragen. Ein häufiger Ansatz besteht darin, in regelmäßigen Abständen oder bei Änderung von Daten vorab aufgefüllte Sichten der Daten zu generieren.
Muster „Kompensierende Transaktion“: Die vorhandenen Daten in einem Ereignissourcing-Speicher werden nicht aktualisiert. Stattdessen werden neue Einträge hinzugefügt, die den Status der Entitäten auf die neuen Werte übertragen. Um eine Änderung rückgängig zu machen, werden ausgleichende Einträge verwendet, da es nicht möglich ist, die vorherige Änderung rückgängig zu machen. Dieses Muster beschreibt, wie die Ergebnisse eines vorherigen Vorgangs rückgängig gemacht werden können.