Entwickeln einer Kubernetes-Anwendung für Azure SQL-Datenbank
Gilt für:![]() Azure SQL-Datenbank
Azure SQL-Datenbank
In diesem Lernprogramm erfahren Sie, wie Sie eine moderne Anwendung mit Python, Docker Containers, Kubernetes und Azure SQL-Datenbank entwickeln.
Moderne Anwendungsentwicklung hat mehrere Herausforderungen. Von der Auswahl eines „Stapels“ von Front-End bis hin zur Datenspeicherung und -verarbeitung aus mehreren konkurrierenden Standards, und durch die Gewährleistung der höchsten Sicherheits- und Leistungsniveaus müssen Entwickler sicherstellen, dass die Anwendungsskala skaliert und gut funktioniert und auf mehreren Plattformen unterstützt werden kann. Für diese letzte Anforderung ist das Bündeln der Anwendung in Containertechnologien wie Docker und die Bereitstellung mehrerer Container auf der Kubernetes-Plattform jetzt in der Anwendungsentwicklung unerlässlich.
In diesem Beispiel untersuchen wir die Verwendung von Python, Docker-Containern und Kubernetes – alle auf der Microsoft Azure-Plattform ausgeführt. Die Verwendung von Kubernetes bedeutet, dass Sie auch die Flexibilität haben, lokale Umgebungen oder sogar andere Clouds für eine nahtlose und konsistente Bereitstellung Ihrer Anwendung zu verwenden und Multicloud-Bereitstellungen für noch höhere Resilienz zu ermöglichen. Außerdem verwenden wir Microsoft Azure SQL-Datenbank für eine dienstbasierte, skalierbare, hochgradig robuste und sichere Umgebung für die Datenspeicherung und -verarbeitung. In vielen Fällen verwenden andere Anwendungen häufig bereits Microsoft Azure SQL-Datenbank, und diese Beispielanwendung kann verwendet werden, um diese Daten weiter zu verwenden und anzureichern.
Dieses Beispiel ist relativ umfassend im Bereich, verwendet jedoch die einfachste Anwendung, Datenbank und Bereitstellung, um den Prozess zu veranschaulichen. Sie können dieses Beispiel wesentlich robuster anpassen, auch wenn Sie die neuesten Technologien für die zurückgegebenen Daten verwenden. Es ist ein nützliches Lerntool, um ein Muster für andere Anwendungen zu erstellen.
Verwenden von Python, Docker-Containern, Kubernetes und der AdventureWorksLT-Beispieldatenbank in einem praktischen Beispiel
Das Unternehmen AdventureWorks (fiktiv) verwendet eine Datenbank, in der Daten über Vertrieb und Marketing, Produkte, Kunden und Fertigung gespeichert werden. Sie enthält auch Ansichten und gespeicherte Prozeduren, die Informationen zu den Produkten verknüpfen, z. B. Produktname, Kategorie, Preis und eine kurze Beschreibung.
Das AdventureWorks-Entwicklungsteam möchte ein Proof-of-Concept (PoC) erstellen, das Daten aus einer Ansicht in der AdventureWorksLT-Datenbank zurückgibt und sie als REST-API verfügbar macht. Mit diesem PoC erstellt das Entwicklungsteam eine skalierbarere und Multicloud-fähige Anwendung für das Vertriebsteam. Sie haben die Microsoft Azure-Plattform für alle Aspekte der Bereitstellung ausgewählt. Das PoC verwendet die folgenden Elemente:
- Eine Python-Anwendung, die das Flask-Paket für die monitorlose Webbereitstellung verwendet.
- Docker-Container für Code- und Umgebungsisolation, die in einer privaten Registrierung gespeichert sind, damit das gesamte Unternehmen die Anwendungscontainer in zukünftigen Projekten wiederverwenden kann, was Zeit und Geld spart.
- Kubernetes für eine einfache Bereitstellung und Skalierung und um die Plattformsperre zu vermeiden.
- Microsoft Azure SQL-Datenbank für die Auswahl von Größe, Leistung, Skalierung, Automanagement und Sicherung, zusätzlich zur relationalen Datenspeicherung und -verarbeitung auf höchster Sicherheitsstufe.
In diesem Artikel erläutern wir den Prozess zum Erstellen des gesamten PoC-Projekts. Die allgemeinen Schritte zum Erstellen der Anwendung sind:
- Festlegen von Voraussetzungen
- Erstellen der Anwendung
- Erstellen eines Docker-Containers zur Bereitstellung und Testen der Anwendung
- Erstellen einer Azure Container Service (ACS)-Registrierung und Laden des Containers in die ACS-Registrierung
- Erstellen der Azure Kubernetes Service-Umgebung (AKS)
- Bereitstellen des Anwendungscontainers aus der ACS-Registrierung in AKS
- Testen der Anwendung
- Bereinigen
Voraussetzungen
In diesem Artikel gibt es mehrere Werte, die Sie ersetzen sollten. Stellen Sie sicher, dass Sie diese Werte für jeden Schritt konsistent ersetzen. Es könnte eine gute Idee sein, einen Text-Editor zu öffnen und diese Werte dort abzulegen, um die richtigen Werte festzulegen, während Sie das PoC-Projekt durcharbeiten:
ReplaceWith_AzureSubscriptionName: Ersetzen Sie diesen Wert durch den Namen Ihres Azure-Abonnements.ReplaceWith_PoCResourceGroupName: Ersetzen Sie diesen Wert durch den Namen der Ressourcengruppe, die Sie erstellen möchten.ReplaceWith_AzureSQLDBServerName: Ersetzen Sie diesen Wert durch den Namen des logischen Azure SQL-Datenbank-Servers, den Sie mithilfe des Azure-Portals erstellen.ReplaceWith_AzureSQLDBSQLServerLoginName: Ersetzen Sie diesen Wert durch den Wert des SQL Server-Benutzernamens, den Sie im Azure-Portal erstellen.ReplaceWith_AzureSQLDBSQLServerLoginPassword: Ersetzen Sie diesen Wert durch den Wert des SQL Server-Benutzerkennworts, das Sie im Azure-Portal erstellen.ReplaceWith_AzureSQLDBDatabaseName: Ersetzen Sie diesen Wert durch den Namen der Azure SQL-Datenbank, die Sie mithilfe des Azure-Portals erstellen.ReplaceWith_AzureContainerRegistryName: Ersetzen Sie diesen Wert durch den Namen der Azure-Containerregistrierung, die Sie erstellen möchten.ReplaceWith_AzureKubernetesServiceName: Ersetzen Sie diesen Wert durch den Namen des Azure Kubernetes-Diensts, den Sie erstellen möchten.
Die Entwickler von AdventureWorks verwenden eine Mischung aus Windows-, Linux- und Apple-Systemen für die Entwicklung, und verwenden somit Visual Studio Code als Umgebung und Git für die Quellcodeverwaltung, die beide plattformübergreifend ausgeführt werden.
Für das PoC erfordert das Team die folgenden Voraussetzungen:
Python, Pip und Pakete – Das Entwicklungsteam wählt die Python-Programmiersprache als Standard für diese webbasierte Anwendung aus. Derzeit verwenden sie Version 3.9, aber jede Version, die die erforderlichen PoC-Pakete unterstützt, ist akzeptabel.
- Sie können Python Version 3.9 von python.org herunterladen.
Das Team verwendet das
pyodbc-Paket für den Datenbankzugriff.- Sie können das Pyodbc-Paket mit Pip-Befehlen installieren.
- Möglicherweise benötigen Sie auch die Microsoft ODBC-Treibersoftware, wenn Sie diese noch nicht installiert haben.
Das Team verwendet das
ConfigParser-Paket zum Steuern und Festlegen von Konfigurationsvariablen.Das Team verwendet das Flask-Paket für eine Weboberfläche für die Anwendung.
Als Nächstes hat das Team das Azure CLI-Tool installiert, das leicht mit der
az-Syntax identifiziert werden kann. Dieses plattformübergreifende Tool ermöglicht einen Befehlszeilen- und Skriptansatz für den PoC, sodass sie die Schritte wiederholen können, während sie Änderungen und Verbesserungen vornehmen.- Sie können das Azure CLI-Tool herunterladen und installieren.
Bei der Einrichtung der Azure CLI meldet sich das Team bei ihrem Azure-Abonnement an und legt den Abonnementnamen fest, den es für den PoC verwendet hat. Anschließend wurde sichergestellt, dass auf den Azure SQL-Datenbank Server und die Datenbank für das Abonnement zugegriffen werden kann:
az login az account set --name "ReplaceWith_AzureSubscriptionName" az sql server list az sql db list ReplaceWith_AzureSQLDBDatabaseNameEine Microsoft Azure-Ressourcengruppe ist ein logischer Container, der zu einer Azure-Lösung gehörige Ressourcen enthält. Im Allgemeinen werden Ressourcen, die den gleichen Lebenszyklus haben, der Ressourcengruppe hinzugefügt, damit Sie diese einfacher als Gruppe bereitstellen, aktualisieren und löschen können. Die Ressourcengruppe speichert Metadaten über die Ressourcen und Sie können einen Standort für die Ressourcengruppe angeben.
Ressourcengruppen können über das Azure-Portal oder die Azure CLI erstellt und verwaltet werden. Sie können auch verwendet werden, um verwandte Ressourcen für eine Anwendung zu gruppieren und sie in Gruppen für die Produktion und Nichtproduktion oder eine andere von Ihnen bevorzugte Organisationsstruktur aufzuteilen.
Im folgenden Codeschnipsel sehen Sie den
az-Befehl zum Erstellen einer Ressourcengruppe. In unserem Beispiel verwenden wir die eastus-Region von Azure.az group create --name ReplaceWith_PoCResourceGroupName --location eastusDas Entwicklungsteam erstellt mit einer SQL-authentifizierten Anmeldung eine Azure SQL-Datenbank, die die
AdventureWorksLTBeispieldatenbank installiert hat.AdventureWorks ist auf der Microsoft SQL Server-Managementsystem für relationale Datenbanken-Plattform standardisiert, und das Entwicklungsteam möchte einen verwalteten Dienst für die Datenbank verwenden, anstatt lokal zu installieren. Die Verwendung von Azure SQL-Datenbank ermöglicht es diesem verwalteten Dienst, vollständig codekompatibel zu sein, unabhängig davon, wo sie das SQL Server-Modul ausführen: lokal, in einem Container, in Linux oder Windows oder sogar in einer IoT-Umgebung (Internet of Things).
Während der Erstellung haben sie das Azure-Verwaltungsportal verwendet, um die Firewall für die Anwendung auf den lokalen Entwicklungscomputer festzulegen und den hier angezeigten Standardwert zu ändern, um alle Azure-Dienste zu aktivieren und auch die Verbindungsanmeldeinformationen abzurufen.
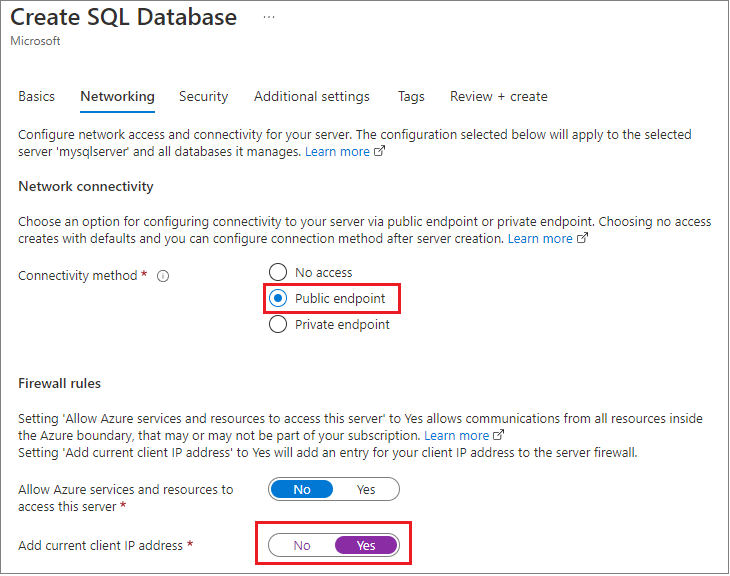
Bei diesem Ansatz kann auf die Datenbank in einer anderen Region oder sogar in einem anderen Abonnement zugegriffen werden.
Das Team hat eine SQL-authentifizierte Anmeldung für Tests eingerichtet, wird diese Entscheidung aber in einer Sicherheitsüberprüfung erneut überprüfen.
Das Team hat die Beispieldatenbank
AdventureWorksLTfür das PoC mit derselben PoC-Ressourcengruppe verwendet. Keine Sorge, am Ende dieses Lernprogramms räumen wir alle Ressourcen in dieser neuen PoC-Ressourcengruppe auf.Sie können das Azure-Portal verwenden, um die Azure SQL-Datenbank einzusetzen. Wählen Sie beim Erstellen der Azure SQL-Datenbank auf der Registerkarte „Zusätzliche Einstellungen“ für die Option „Vorhandene Daten verwenden“ die Option „Beispiel“ aus.

Schließlich hat das Entwicklungsteam auf der Registerkarte der neuen Azure SQL-Datenbank „Kategorien“ Tag-Metadagen für diese Azure-Ressource bereitgestellt, z. B. „Owner“, „ServiceClass“ oder „WorkloadName“.

Erstellen der Anwendung
Als Nächstes hat das Entwicklungsteam eine einfache Python-Anwendung erstellt, die eine Verbindung mit Azure SQL-Datenbank öffnet und eine Liste von Produkten zurückgibt. Dieser Code wird durch komplexere Funktionen ersetzt und kann auch mehr als eine Anwendung enthalten, die in der Kubernetes-Pods in der Produktion bereitgestellt wird, um einen robusten, manifestgesteuerten Ansatz für Anwendungslösungen zu erhalten.
Das Team hat eine einfache Textdatei erstellt,
.envgenannt, um Variablen für die Serververbindungen und andere Informationen zu speichern. Mithilfe derpython-dotenv-Bibliothek können sie dann die Variablen vom Python-Code trennen. Dies ist ein gemeinsamer Ansatz zum Aufbewahren von Geheimnissen und anderen Informationen aus dem Code selbst.SQL_SERVER_ENDPOINT = ReplaceWith_AzureSQLDBServerName SQL_SERVER_USERNAME = ReplaceWith_AzureSQLDBSQLServerLoginName SQL_SERVER_PASSWORD = ReplaceWith_AzureSQLDBSQLServerLoginPassword SQL_SERVER_DATABASE = ReplaceWith_AzureSQLDBDatabaseNameAchtung
Aus Gründen der Klarheit und Einfachheit verwendet diese Anwendung eine Konfigurationsdatei, die aus Python gelesen wird. Da der Code mit dem Container bereitgestellt wird, können die Verbindungsinformationen möglicherweise von den Inhalten abgeleitet werden. Sie sollten die verschiedenen Methoden für die Arbeit mit Sicherheit, Verbindungen und Geheimnissen sorgfältig prüfen und die beste Stufe und den besten Mechanismus bestimmen, den Sie für unsere Anwendung verwenden sollten. Wählen Sie immer die höchste Sicherheitsstufe und sogar mehrere Ebenen aus, um sicherzustellen, dass Ihre Anwendung sicher ist. Sie haben mehrere Möglichkeiten, mit geheimen Informationen wie Verbindungszeichenfolgen und dergleichen zu arbeiten. In der folgenden Liste sind einige dieser Optionen aufgeführt.
Weitere Informationen finden Sie unter Azure SQL-Datenbank-Sicherheit.
- Eine weitere Methode zum Arbeiten mit Geheimnissen in Python ist die Verwendung der Python-Geheimnis-Bibliothek.
- Überprüfen Sie Docker-Sicherheit und Geheimnisse.
- Überprüfen Sie Kubernetes Geheimnisse.
- Sie können auch weitere Informationen zur Microsoft Entra-Authentifizierung (vormals Azure Active Directory) erhalten.
Das Team schrieb als nächstes die PoC-Anwendung und nannte sie
app.py.Das folgende Skript führt die folgenden Schritte aus:
- Einrichten der Bibliotheken für die Konfigurations- und Basiswebschnittstellen.
- Laden der Variablen aus der
.env-Datei. - Erstellen der Flask-RESTful-Anwendung.
- Aufrufen der Azure SQL-Datenbank Verbindungsinformationen mithilfe der
config.ini-Dateiwerte. - Erstellen einer Verbindung zur Azure SQL-Datenbank mithilfe der
config.ini-Dateiwerte. - Herstellen einer Verbindung mit einer Azure SQL-Datenbank mithilfe des
pyodbc-Pakets. - Erstellen der SQL-Abfrage, die in der Datenbank ausgeführt werden soll.
- Erstellen der Klasse, die verwendet wird, um die Daten aus der API zurückzugeben.
- Festlegen des API-Endpunkts auf die
Products-Klasse. - Und schließlich das Starten der App auf dem Standardmäßigen Flask-Port 5000.
# Set up the libraries for the configuration and base web interfaces from dotenv import load_dotenv from flask import Flask from flask_restful import Resource, Api import pyodbc # Load the variables from the .env file load_dotenv() # Create the Flask-RESTful Application app = Flask(__name__) api = Api(app) # Get to Azure SQL Database connection information using the config.ini file values server_name = os.getenv('SQL_SERVER_ENDPOINT') database_name = os.getenv('SQL_SERVER_DATABASE') user_name = os.getenv('SQL_SERVER_USERNAME') password = os.getenv('SQL_SERVER_PASSWORD') # Create connection to Azure SQL Database using the config.ini file values ServerName = config.get('Connection', 'SQL_SERVER_ENDPOINT') DatabaseName = config.get('Connection', 'SQL_SERVER_DATABASE') UserName = config.get('Connection', 'SQL_SERVER_USERNAME') PasswordValue = config.get('Connection', 'SQL_SERVER_PASSWORD') # Connect to Azure SQL Database using the pyodbc package # Note: You may need to install the ODBC driver if it is not already there. You can find that at: # https://learn.microsoft.com/sql/connect/odbc/download-odbc-driver-for-sql-server connection = pyodbc.connect(f'Driver=ODBC Driver 17 for SQL Server;Server={ServerName};Database={DatabaseName};uid={UserName};pwd={PasswordValue}') # Create the SQL query to run against the database def query_db(): cursor = connection.cursor() cursor.execute("SELECT TOP (10) [ProductID], [Name], [Description] FROM [SalesLT].[vProductAndDescription] WHERE Culture = 'EN' FOR JSON AUTO;") result = cursor.fetchone() cursor.close() return result # Create the class that will be used to return the data from the API class Products(Resource): def get(self): result = query_db() json_result = {} if (result == None) else json.loads(result[0]) return json_result, 200 # Set the API endpoint to the Products class api.add_resource(Products, '/products') # Start App on default Flask port 5000 if __name__ == "__main__": app.run(debug=True)Sie haben überprüft, ob diese Anwendung lokal ausgeführt wird, und eine Seite nach
http://localhost:5000/productszurückbringt.
Wichtig
Verwenden Sie beim Erstellen von Produktionsanwendungen nicht das Administratorkonto, um auf die Datenbank zuzugreifen. Weitere Informationen finden Sie unter Einrichten eines Kontos für Ihre Anwendung. Der Code in diesem Artikel ist vereinfacht, sodass Sie schnell mit Anwendungen beginnen können, die Python und Kubernetes in Azure verwenden.
Realistischererweise könnten Sie einen eigenständigen Datenbankbenutzer mit schreibgeschützten Berechtigungen oder einem Anmelde- oder eigenständigen Datenbankbenutzer verwenden, der mit einer benutzerseitig zugewiesenen verwalteten Identität mit schreibgeschützten Berechtigungen verbunden ist.
Weitere Informationen können Sie durch Überprüfung eines vollständigen Beispiels, wie Sie eine API mit Python und Azure SQL-Datenbank erstellen, erhalten.

Bereitstellen der Anwendung in einem Docker-Container
Ein Container ist ein reservierter, geschützter Bereich in einem Computersystem, das Isolation und Kapselung bereitstellt. Verwenden Sie zum Erstellen eines Containers eine Manifestdatei, bei der es sich lediglich um eine Textdatei handelt, die die Binärdateien und den Code beschreibt, den Sie enthalten möchten. Mithilfe einer Container-Runtime (z. B. Docker) können Sie dann ein binäres Image erstellen, das alle Dateien enthält, die Sie ausführen und referenzieren möchten. Von dort aus können Sie das binäre Image „ausführen“, was Container heißt, auf den Sie verweisen können, als wäre es ein vollständiges Computersystem. Das ist eine einfachere Möglichkeit, Ihre Anwendungslaufzeiten und -umgebung abstrahieren zu können, als eine vollständige virtuelle Maschine zu verwenden. Weitere Informationen erhalten Sie unter Container und Docker.
Das Team begann mit einer DockerFile-Datei (dem Manifest), die die Elemente, die das Teams verwenden möchte, abstuft. Sie beginnen mit einem Basis-Python-Image, das bereits die pyodbc-Bibliotheken installiert hat, und führen dann alle Befehle aus, die erforderlich sind, um die Programm- und Konfigurationsdatei im vorherigen Schritt zu enthalten.
Die folgenden Dockerfile-Dateien haben die folgenden Schritte:
- Beginnen Sie mit einer Container-Binärdatei, die bereits Python und
pyodbcinstalliert hat. - Erstellen Sie ein Arbeitsverzeichnis für die Anwendung.
- Kopieren Sie den gesamten Code aus dem aktuellen Verzeichnis in das
WORKDIR. - Installieren Sie die erforderlichen Bibliotheken.
- Sobald der Container gestartet wird, führen Sie die Anwendung aus, und öffnen Sie alle TCP/IP-Ports.
# syntax=docker/dockerfile:1
# Start with a Container binary that already has Python and pyodbc installed
FROM laudio/pyodbc
# Create a Working directory for the application
WORKDIR /flask2sql
# Copy all of the code from the current directory into the WORKDIR
COPY . .
# Install the libraries that are required
RUN pip install -r ./requirements.txt
# Once the container starts, run the application, and open all TCP/IP ports
CMD ["python3", "-m" , "flask", "run", "--host=0.0.0.0"]
Mit der Datei vor Ort und Stelle hat das Team eine Eingabeaufforderung im Codierungsverzeichnis abgelegt und den folgenden Code ausgeführt, um das binäre Image aus dem Manifest zu erstellen, und dann einen weiteren Befehl zum Starten des Containers:
docker build -t flask2sql .
docker run -d -p 5000:5000 -t flask2sql
Erneut testet das Team den http://localhost:5000/products-Link, um sicherzustellen, dass der Container auf die Datenbank zugreifen kann; es wird die folgende Rückgabe angezeigt:

Bereitstellen des Images in einer Docker-Registrierung
Der Container funktioniert jetzt, ist aber nur auf dem Computer des Entwicklers verfügbar. Das Entwicklungsteam möchte dieses Anwendungsimage für den Rest des Unternehmens und dann für die Produktionsbereitstellung auf Kubernetes verfügbar machen.
Der Speicherbereich für Containerimages wird als Repository bezeichnet, und es kann sowohl öffentliche als auch private Repositorys für Containerimages geben. Tatsächlich hat AdvenureWorks ein öffentliches Image für die Python-Umgebung in ihrer Dockerfile-Datei verwendet.
Das Team möchte den Zugriff auf das Image steuern und es nicht im Web platzieren, es hat sondern entschieden, dass es es selbst hosten möchte, jedoch in Microsoft Azure, wo es volle Kontrolle über Sicherheit und Zugriff hat. Weitere Informationen zur Microsoft Azure Container Registry finden Sie hier.
Wenn Sie zur Befehlszeile zurückkehren, verwendet das Entwicklungsteam az CLI, um einen Containerregistrierungsdienst hinzuzufügen, ein Verwaltungskonto zu aktivieren, es während der Testphase auf anonyme „Pulls“ festzulegen und einen Anmeldekontext für die Registrierung festzulegen:
az acr create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureContainerRegistryName --sku Standard
az acr update -n ReplaceWith_AzureContainerRegistryName --admin-enabled true
az acr update --name ReplaceWith_AzureContainerRegistryName --anonymous-pull-enabled
az acr login --name ReplaceWith_AzureContainerRegistryName
Dieser Kontext wird in nachfolgenden Schritten verwendet.
Markieren Sie das lokale Docker-Image, um es für den Upload vorzubereiten
Der nächste Schritt besteht darin, das lokale Anwendungscontainerimage an den Azure Container Registry (ACR)-Dienst zu senden, damit es in der Cloud verfügbar ist.
- Im folgenden Beispielskript verwendet das Team die Docker-Befehle, um die Images auf dem Computer auflisten zu können.
- Es verwendet das
az CLI-Hilfsprogramm, um die Images im ACR-Dienst auflisten. - Es verwendet den Docker-Befehl, um das Image mit dem Zielnamen des im vorherigen Schritt erstellten ACR zu markieren und eine Versionsnummer für ordnungsgemäße DevOps festzulegen.
- Schließlich werden die lokalen Image-Informationen erneut aufgeführt, um sicherzustellen, dass das Tag korrekt angewendet wurde.
docker images
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
docker tag flask2sql ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
docker images
Mit dem Code geschrieben und getestet, dem Dockerfile, Image und Container ausgeführt und getestet, dem ACR-Dienst und allen Tags angewandt, kann das Team das Image in den ACR-Dienst hochladen.
Es verwendet den Docker-Befehl „Push“, um die Datei, und dann das az CLI-Dienstprogramm zu senden, um sicherzustellen, dass das Image geladen wurde:
docker push ReplaceWith_AzureContainerRegistryName.azurecr.io/azure-flask2sql:v1
az acr repository list --name ReplaceWith_AzureContainerRegistryName --output table
Bereitstellen in Kubernetes
Das Team kann einfach Container ausführen und die Anwendung in lokalen und in Cloudumgebungen bereitstellen. Es möchte jedoch mehrere Kopien der Anwendung zur Skalierung und Verfügbarkeit hinzufügen, weitere Container hinzufügen, die unterschiedliche Aufgaben ausführen, und der gesamten Lösung Überwachung und Instrumentierung hinzufügen.
Um Container in eine komplette Lösung zu gruppieren, entschied sich das Team, Kubernetes zu verwenden. Kubernetes wird lokal und in allen wichtigen Cloudplattformen ausgeführt. Microsoft Azure verfügt über eine vollständige verwaltete Umgebung für Kubernetes, den sogenannten Azure Kubernetes-Dienst (Azure Kubernetes Service, AKS). Erfahren Sie mehr über AKS mit der Einführung in Kubernetes auf dem Azure-Schulungspfad.
Mithilfe des az CLI Hilfsprogramms fügt das Team AKS zur gleichen Ressourcengruppe hinzu, die es zuvor erstellt hat. Mit einem einzigen az-Befehl führt das Entwicklungsteam die folgenden Schritte aus:
- Hinzufügen von zwei „Knoten“ oder Computerumgebungen zur Resilienz in der Testphase
- Automatisches Generieren von SSH-Schlüsseln für den Zugriff auf die Umgebung
- Anfügen des ACR-Dienstes, den es in den vorherigen Schritten erstellt hat, damit der AKS-Cluster die Images finden kann, die es für die Bereitstellung verwenden möchte
az aks create --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName --node-count 2 --generate-ssh-keys --attach-acr ReplaceWith_AzureContainerRegistryName
Kubernetes verwendet ein Befehlszeilentool, um auf einen Cluster, der kubectl gennant wird, zuzugreifen und zu steuern. Das Team verwendet das az CLI-Hilfsprogramm, um das kubectl-Tool herunterzuladen und zu installieren:
az aks install-cli
Da es derzeit über eine Verbindung mit AKS verfügt, kann es dieses bitten, die SSH-Schlüssel zu senden, um die Verbindung zu verwenden, wenn es das kubectl Dienstprogramm ausführt:
az aks get-credentials --resource-group ReplaceWith_PoCResourceGroupName --name ReplaceWith_AzureKubernetesServiceName
Diese Schlüssel werden in einer Datei namens .config im Verzeichnis des Benutzers gespeichert. Mit diesem Sicherheitskontextsatz verwendet das Team kubectl get nodes, um die Knoten im Cluster anzuzeigen:
kubectl get nodes
Nun verwendet das Team das az CLI-Tool zum Auflisten der Bilder im ACR-Dienst:
az acr list --resource-group ReplaceWith_PoCResourceGroupName --query "[].{acrLoginServer:loginServer}" --output table
Jetzt kann es das Manifest erstellen, das Kubernetes zum Steuern der Bereitstellung verwendet. Dies ist eine Textdatei, die in einem Yaml-Format gespeichert ist. Dies ist der kommentierte Text in der flask2sql.yaml-Datei:
apiVersion: apps/v1
# The type of commands that will be sent, along with the name of the deployment
kind: Deployment
metadata:
name: flask2sql
# This section sets the general specifications for the application
spec:
replicas: 1
selector:
matchLabels:
app: flask2sql
strategy:
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
minReadySeconds: 5
template:
metadata:
labels:
app: flask2sql
spec:
nodeSelector:
"kubernetes.io/os": linux
# This section sets the location of the Image(s) in the deployment, and where to find them
containers:
- name: flask2sql
image: bwoodyflask2sqlacr.azurecr.io/azure-flask2sql:v1
# Recall that the Flask application uses (by default) TCIP/IP port 5000 for access. This line tells Kubernetes that this "pod" uses that address.
ports:
- containerPort: 5000
---
apiVersion: v1
# This is the front-end of the application access, called a "Load Balancer"
kind: Service
metadata:
name: flask2sql
spec:
type: LoadBalancer
# this final step then sets the outside exposed port of the service to TCP/IP port 80, but maps it internally to the app's port of 5000
ports:
- protocol: TCP
port: 80
targetPort: 5000
selector:
app: flask2sql
Jetzt, da die flask2sql.yaml-Datei definiert ist, kann das Team die Anwendung auf dem ausgeführten AKS-Cluster bereitstellen. Dies geschieht mit dem kubectl apply-Befehl, der, wie Sie sich erinnern, immer noch über einen Sicherheitskontext für den Cluster verfügt. Anschließend wird der kubectl get service-Befehl gesendet, um den Cluster so zu überwachen, wie er erstellt wird.
kubectl apply -f flask2sql.yaml
kubectl get service flask2sql --watch
Nach ein paar Momenten gibt der Befehl „Watch“ eine externe IP-Adresse zurück. An diesem Punkt drückt das Team STRG-C, um den Überwachungsbefehl zu unterbrechen, und zeichnet die externe IP-Adresse des Lastenausgleichs auf.
Testen der App
Mit der IP-Adresse (Endpunkt), die es im letzten Schritt abgerufen hat, überprüft das Team, um die gleiche Ausgabe wie die lokale Anwendung und den Docker-Container sicherzustellen:
Bereinigung
Nachdem die Anwendung erstellt, bearbeitet, dokumentiert und getestet wurde, kann das Team die Anwendung jetzt „abreißen“. Wenn alles in einer einzelnen Ressourcengruppe in Microsoft Azure beibehalten wird, macht es das einfach, die PoC-Ressourcengruppe mithilfe des az CLI-Dienstprogramms zu löschen:
az group delete -n ReplaceWith_PoCResourceGroupName -y
Hinweis
Wenn Sie Ihre Azure SQL-Datenbank in einer anderen Ressourcengruppe erstellt haben und sie nicht mehr benötigen, können Sie das Azure-Portal verwenden, um sie zu löschen.
Das Teammitglied, das das PoC-Projekt leitet, verwendet Microsoft Windows als Arbeitsstation und möchte die geheime Datei von Kubernetes beibehalten, sie aber als aktiver Speicherort aus dem System entfernen. Sie können die Datei einfach in eine config.old-Textdatei kopieren und dann löschen:
copy c:\users\ReplaceWith_YourUserName\.kube\config c:\users\ReplaceWith_YourUserName\.kube\config.old
del c:\users\ReplaceWith_YourUserName\.kube\config
Zugehöriger Inhalt
- Übersicht über die Anwendungsentwicklung: SQL-Datenbank und SQL Managed Instance
- Herstellen einer Verbindung zu Azure SQL-Datenbank und Abfragen dieser Datenbank mithilfe von Python und dem pyodbc-Treiber
- Veröffentlichen eines Datenbankprojekts für Azure SQL-Datenbank auf dem lokalen Emulator
- Codebeispiele für Azure SQL-Datenbank durchsuchen
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für