Tutorial: Ausführen von Python auf einem Cluster und als Auftrag mithilfe der Databricks-Erweiterung für Visual Studio Code
Dieses Tutorial führt Sie durch die Einrichtung der Databricks-Erweiterung für Visual Studio Code und dann durch die Ausführung von Python in einem Azure Databricks-Cluster und als Azure Databricks-Auftrag in Ihrem Remotearbeitsbereich. Weitere Informationen finden Sie unter Was ist die Databricks-Erweiterung für Visual Studio Code?.
Anforderungen
Für dieses Tutorial ist Folgendes erforderlich:
- Sie müssen die Databricks-Erweiterung für Visual Studio Code installiert haben. Weitere Informationen finden Sie unter Installieren der Databricks-Erweiterung für Visual Studio Code.
- Sie müssen einen Azure Databricks-Remotecluster haben, den Sie verwenden können. Notieren Sie sich den Namen des Clusters. Klicken Sie zum Anzeigen der verfügbaren Cluster in der Randleiste Ihres Azure Databricks-Arbeitsbereichs auf Compute. Siehe Compute.
Schritt 1: Erstellen eines neuen Databricks-Projekts
In diesem Schritt erstellen Sie ein neues Databricks-Projekt und konfigurieren die Verbindung mit Ihrem Azure Databricks-Remotearbeitsbereich.
- Starten Sie Visual Studio Code, klicken Sie dann auf Datei > Ordner öffnen und öffnen Sie einen leeren Ordner auf Ihrem lokalen Entwicklungscomputer.
- Klicken Sie in der Randleiste auf das Databricks-Logosymbol. Dadurch wird die Databricks-Erweiterung geöffnet.
- Klicken Sie in der Ansicht Konfiguration auf Zu einem Databricks-Projekt migrieren.
- Die Befehlspalette zum Konfigurieren des Databricks-Arbeitsbereichs wird geöffnet. Geben Sie für Databricks-Host Ihre arbeitsbereichsspezifische URL ein oder wählen Sie sie aus, z. B.
https://adb-1234567890123456.7.azuredatabricks.net. - Wählen Sie ein Authentifizierungsprofil für das Projekt aus. Weitere Informationen finden Sie unter Einrichten der Authentifizierung für die Databricks-Erweiterung für Visual Studio Code.
Schritt 2: Hinzufügen von Clusterinformationen zur Databricks-Erweiterung und Starten des Clusters
Klicken Sie bei bereits geöffneter Ansicht Konfiguration auf Cluster auswählen oder auf das Zahnradsymbol (Cluster konfigurieren).
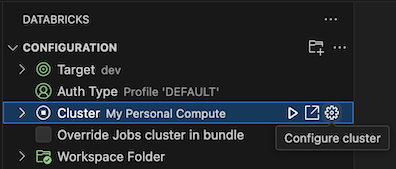
Wählen Sie in der Befehlspalette den Namen des zuvor erstellten Clusters aus.
Klicken Sie auf das Wiedergabesymbol (Cluster starten), wenn noch nicht gestartet.
Schritt 3: Erstellen und Ausführen von Python-Code
Erstellen Sie eine lokale Python-Codedatei: Klicken Sie auf der Seitenleiste auf das Ordnersymbol (Explorer).
Klicken Sie im Hauptmenü auf File > New File. Geben Sie der Datei den Namen demo.py und speichern Sie sie im Projektstamm.
Fügen Sie der Datei den folgenden Code hinzu, und speichern Sie sie. Dieser Code erstellt und zeigt den Inhalt eines einfachen PySpark-DataFrames an:
from pyspark.sql import SparkSession from pyspark.sql.types import * spark = SparkSession.builder.getOrCreate() schema = StructType([ StructField('CustomerID', IntegerType(), False), StructField('FirstName', StringType(), False), StructField('LastName', StringType(), False) ]) data = [ [ 1000, 'Mathijs', 'Oosterhout-Rijntjes' ], [ 1001, 'Joost', 'van Brunswijk' ], [ 1002, 'Stan', 'Bokenkamp' ] ] customers = spark.createDataFrame(data, schema) customers.show() # Output: # # +----------+---------+-------------------+ # |CustomerID|FirstName| LastName| # +----------+---------+-------------------+ # | 1000| Mathijs|Oosterhout-Rijntjes| # | 1001| Joost| van Brunswijk| # | 1002| Stan| Bokenkamp| # +----------+---------+-------------------+Klicken Sie auf das Symbol In Databricks ausführen neben der Liste der Editor-Registerkarten und dann auf Datei hochladen und ausführen. Die Ausgabe wird in der Ansicht Debugging-Konsole angezeigt.
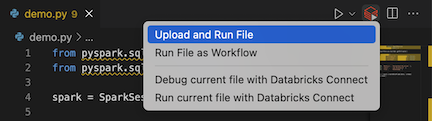
Alternativ dazu können Sie in der Ansicht Explorer mit der rechten Maustaste auf die Datei
demo.pyund dann auf In Databricks ausführen>Datei hochladen und ausführen klicken.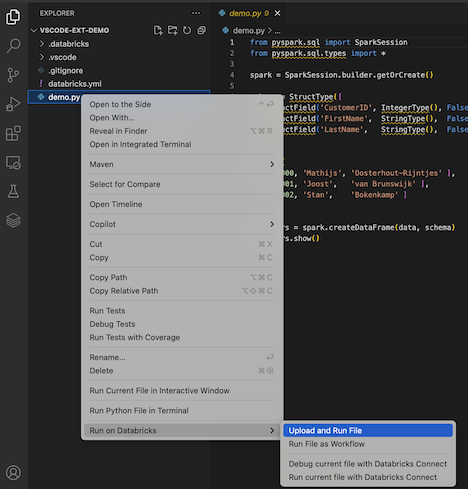
Schritt 4: Ausführen des Codes als Auftrag
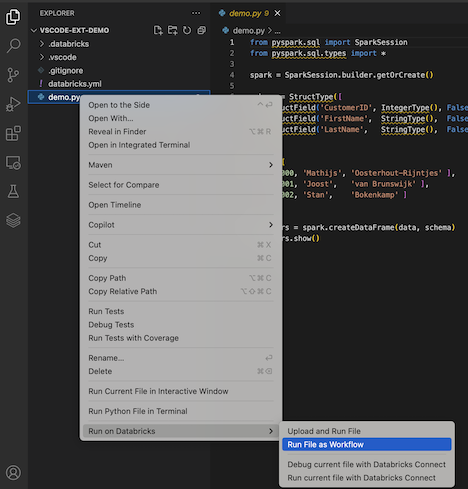
Klicken Sie zum Ausführen von demo.py als Auftrag neben der Liste der Editorregisterkarten auf das Symbol In Databricks ausführen und dann auf Datei als Workflow ausführen. Die Ausgabe wird auf einer separaten Editor-Registerkarte neben dem demo.py-Datei-Editor angezeigt.
![]()
Alternativ dazu können Sie im Bereich Explorer mit der rechten Maustaste auf die Datei demo.pyklicken und dann In Databricks ausführen>Datei als Workflow ausführen auswählen.
Nächste Schritte
Nachdem Sie nun die Databricks-Erweiterung für Visual Studio Code erfolgreich zum Hochladen und Remote-Ausführen einer lokalen Python-Datei verwendet haben, können Sie auch:
- Ressourcen und Variablen für Databricks Asset Bundles über die Benutzeroberfläche der Erweiterung erkunden. Siehe Erweiterungsfeatures für Databricks Asset Bundles.
- Python-Code mit Databricks Connect ausführen oder debuggen. Siehe Debuggen von Code mithilfe von Databricks Connect für die Databricks-Erweiterung für Visual Studio Code.
- Eine Datei oder ein Notebook als Azure Databricks-Auftrag ausführen. Siehe Ausführen einer Datei auf einem Cluster oder einer Datei oder eines Notebooks als Auftrag in Azure Databricks mithilfe der Databricks-Erweiterung für Visual Studio Code.
- Test mit
pytestausführen. Siehe Ausführen von Tests mit pytest mithilfe der Databricks-Erweiterung für Visual Studio Code.