SQL-Datentypregeln
Gilt für: ![]() Databricks SQL
Databricks SQL ![]() Databricks Runtime
Databricks Runtime
Azure Databricks verwendet mehrere Regeln, um Konflikte zwischen Datentypen zu lösen:
- Erweiterung erweitert einen Typ sicher auf einen höheren Typ.
- Implizites Downcasting grenzt einen Typ ein. Das Gegenteil der Erweiterung.
- Implizites Crosscasting transformiert einen Typ in einen Typ einer anderen Typfamilie.
Sie können auch explizit zwischen vielen Typen umwandeln:
- cast-Funktion wechselt zwischen den meisten Typen und gibt Fehler zurück, wenn dies nicht möglich ist.
- try_cast-Funktion funktioniert wie die cast-Funktion, gibt aber NULL zurück, wenn ungültige Werte übergeben werden.
- Andere integrierte Funktionen werden zwischen Typen mit bereitgestellten Formatdirektiven übertragen.
Typerweiterung
Bei der Typerweiterung wird ein Typ in einen anderen Typ derselben Typfamilie umgewandelt, der alle möglichen Werte des ursprünglichen Typs enthält.
Daher ist die Typerweiterung ein sicherer Vorgang. TINYINT hat z. B. einen Bereich von -128 bis 127. Alle möglichen Werte können sicher auf INTEGER erweitert werden.
Typrangfolgenliste
Die Typrangfolgenliste bestimmt, ob Werte eines bestimmten Datentyps implizit auf einen anderen Datentyp heraufgestuft werden können.
| Datentyp | Rangfolgeliste (vom niedrigsten zum höchsten Typ) |
|---|---|
| TINYINT | TINYINT -> SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| SMALLINT | SMALLINT -> INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| INT | INT -> BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| BIGINT | BIGINT -> DECIMAL -> FLOAT (1) -> DOUBLE |
| DECIMAL | DECIMAL -> FLOAT (1) -> DOUBLE |
| FLOAT | FLOAT (1) -> DOUBLE |
| DOUBLE | Double |
| DATE | DATE -> TIMESTAMP |
| TIMESTAMP | TIMESTAMP |
| ARRAY | ARRAY (2) |
| BINARY | BINARY |
| BOOLEAN | Boolean |
| INTERVAL | INTERVAL |
| MAP | MAP (2) |
| STRING | STRING |
| STRUCT | STRUCT (2) |
| VARIANT | VARIANT |
| OBJECT | OBJECT (3) |
(1) Bei der Auflösung des geringsten gemeinsamen Typs wird FLOAT übersprungen, um Genauigkeitsverluste zu vermeiden.
(2) Bei einem komplexen Typ wird die Rangfolgeregel rekursiv auf die zugehörigen Komponentenelemente angewendet.
(3) OBJECT ist nur innerhalb einer VARIANT-Instanz vorhanden.
Zeichenfolgen und NULL
Für STRINGs und nicht typisierte NULL-Werte gelten spezielle Regeln:
NULLkann auf einen beliebigen anderen Typ erweitert werden.STRINGkann aufBIGINT,BINARY,BOOLEAN,DATE,DOUBLE,INTERVALundTIMESTAMPerweitert werden. Wenn der tatsächliche Zeichenfolgenwert nicht in den kleinsten gemeinsamen Typ umgewandelt werden kann, gibt Azure Databricks einen Laufzeitfehler aus. Beim Erweitern zuINTERVALmuss der Zeichenfolgenwert mit den Intervalleeinheiten übereinstimmen.
Typrangfolgendiagramm
Dies ist eine grafische Darstellung der Rangfolgenhierarchie, die die Typrangfolgenliste sowie Regeln zu Zeichenfolgen und NULLs kombiniert.
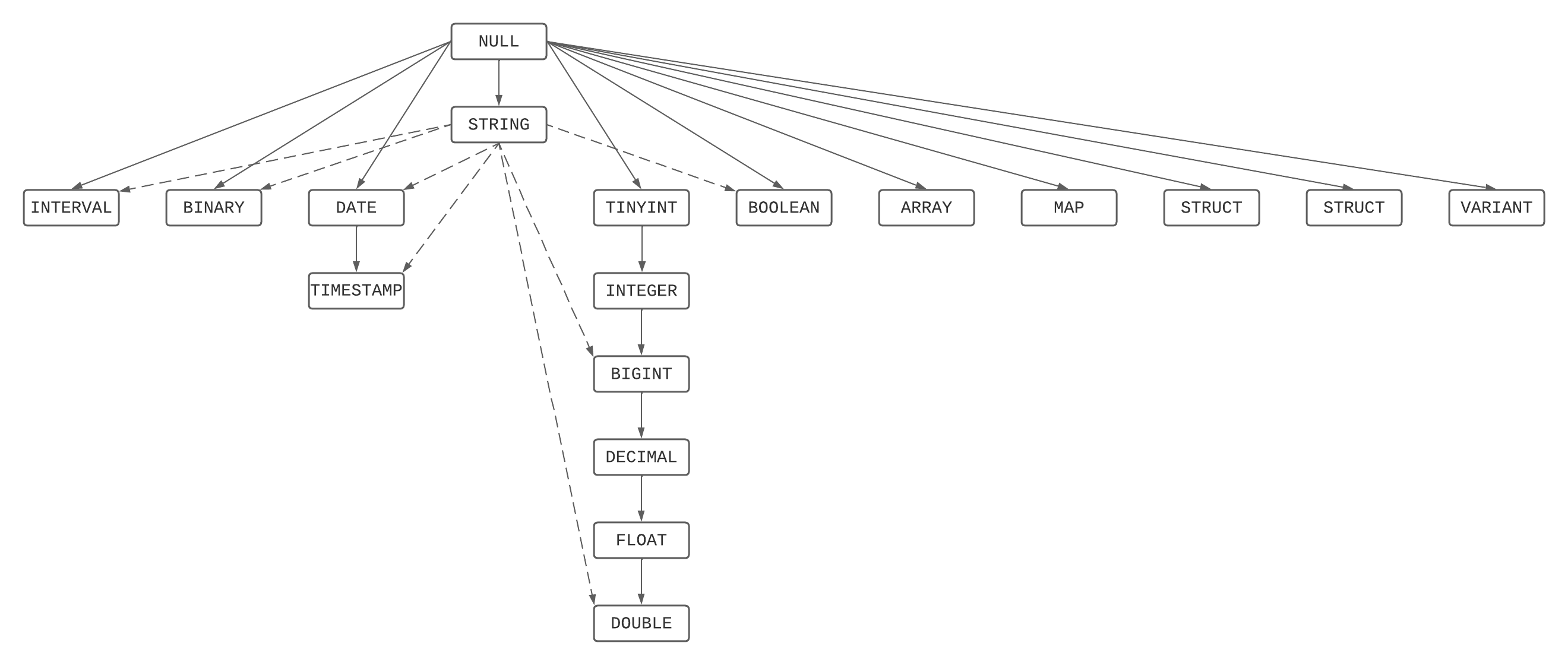
Auflösung des kleinsten gemeinsamen Typs
Der kleinste gemeinsame Typ aus einer Reihe von Typen ist der niedrigste Typ, der aus der Typrangfolgendiagramm von allen Elementen der Reihe von Typen erreicht werden kann.
Die Auflösung des kleinsten gemeinsamen Typs wird für Folgendes verwendet:
- Entscheiden, ob eine Funktion, die einen Parameter eines angegebenen Typs erwartet, mit einem Argument eines niedrigeren Typs aufgerufen werden kann.
- Ableiten des Argumenttyps für eine Funktionen, die einen gemeinsamen Argumenttyp für mehrere Parameter erwartet, z. B. COALESCE, IN, LEAST oder GREATEST.
- Ableiten der Operandentypen für Operatoren wie z. B. arithmetische Operationen oder Vergleiche.
- Ableiten des Ergebnistyps für Ausdrücke wie den CASE-Ausdruck.
- Ableiten der Element-, Schlüssel- oder Werttypen für Array- und Map-Konstruktoren.
- Ableiten des Ergebnistyps der UNION-, INTERSECT- oder EXCEPT-Mengenoperatoren.
Spezielle Regeln werden angewendet, wenn der kleinste gemeinsame Typ in FLOAT aufgelöst wird. Wenn einer der beitragenden Typen ein genauer numerischer Typ (TINYINT, SMALLINT, INTEGER, BIGINT oder DECIMAL) ist, wird der kleinste gemeinsame Typ per Push auf DOUBLE gesetzt, um einen potenziellen Verlust von Ziffern zu vermeiden.
Implizites Downcasting und Crosscasting
Azure Databricks nutzt diese Formen der impliziten Umwandlung nur beim Funktions- und Operatoraufruf und nur dort, wo die Absicht eindeutig bestimmt werden kann.
Implizites Downcasting
Implizites Downcasting wandelt automatisch einen höheren Typ in einen niedrigeren Typ um, ohne dass Sie die Umwandlung explizit angeben müssen. Downcasting ist praktisch, birgt aber das Risiko unerwarteter Laufzeitfehler, wenn der tatsächliche Wert im niedrigeren Typ nicht darstellbar ist.
Bei Downcasting wird die Typrangfolgenliste in umgekehrter Reihenfolge angewendet.
Implizites Crosscasting
Implizites Crosscasting wandelt einen Wert aus einer Typfamilie in eine andere um, ohne dass Sie die Umwandlung explizit angeben müssen.
Azure Databricks unterstützt implizites Crosscasting von:
- Allen einfachen Typen, mit Ausnahme von
BINARYzuSTRING. - Einem
STRINGzu einem Beliebigen einfachen Typ.
- Allen einfachen Typen, mit Ausnahme von
Umwandlung beim Funktionsaufruf
Bei einer aufgelösten Funktion oder einem aufgelösten Operator gelten die folgenden Regeln in der Reihenfolge, in der sie aufgelistet sind, für jedes Parameter-Argumentpaar:
Wenn ein unterstützter Parametertyp Teil des Typrangfolgendiagramms des Arguments ist, erweitert Azure Databricks das Argument auf diesen Parametertyp.
In den meisten Fällen gibt die Funktionsbeschreibung explizit die unterstützten Typen oder die Kette an, z. B. „beliebiger numerischer Typ“.
Beispielsweise wird sin(expr) für
DOUBLEverwendet, akzeptiert aber alle numerischen Werte.Wenn der erwartete Parametertyp eine Zeichenfolge (
STRING) und das Argument ein einfacher Typ ist, wandelt Azure Databricks das Argument mittels Crosscasting in den Zeichenfolgeparametertyp um.Beispielsweise wird bei substr(str, start, len) erwartet, dass
streinSTRINGist. Stattdessen können Sie einen numerischen oder datetime-Typ übergeben.Wenn der Argumenttyp eine Zeichenfolge (
STRING) und der erwartete Parametertyp ein einfacher Typ ist, wandelt Azure Databricks das Zeichenfolgenargument mittels Crosscasting in den allgemeinsten unterstützten Parametertyp um.Zum Beispiel: Date_add(date, days) erwartet ein
DATEund einINTEGER.Wenn Sie
date_add()mit zweiSTRING-Elementen aufrufen, wandelt Azure Databricks mittels Crosscasting das ersteSTRING-Element inDATEund das zweiteSTRING-Element inINTEGERum.Wenn die Funktion einen numerischen Typ erwartet (z. B. einen
INTEGER- oderDATE-Typ), das Argument jedoch ein allgemeinerer Typ ist, (z. B.DOUBLEoderTIMESTAMP), wird das Argument von Azure Databricks mittels Downcasting implizit in diesen Parametertyp umgewandelt.Zum Beispiel: Date_add(date, days) erwartet ein
DATEund einINTEGER.Wenn Sie
date_add()mit einemTIMESTAMP- und einemBIGINT-Element aufrufen, wird dasTIMESTAMP-Element von Azure Databricks mittels Downcasting durch Entfernen der Zeitkomponente inDATEund dasBIGINT-Element inINTEGERumgewandelt.Andernfalls löst Azure Databricks einen Fehler aus.
Beispiele
Die coalesce-Funktion akzeptiert alle Argumenttypen, solange sie einen kleinsten gemeinsamen Typ verwenden.
Der Ergebnistyp ist der kleinste gemeinsame Typ der Argumente.
-- The least common type of TINYINT and BIGINT is BIGINT
> SELECT typeof(coalesce(1Y, 1L, NULL));
BIGINT
-- INTEGER and DATE do not share a precedence chain or support crosscasting in either direction.
> SELECT typeof(coalesce(1, DATE'2020-01-01'));
Error: Incompatible types [INT, DATE]
-- Both are ARRAYs and the elements have a least common type
> SELECT typeof(coalesce(ARRAY(1Y), ARRAY(1L)))
ARRAY<BIGINT>
-- The least common type of INT and FLOAT is DOUBLE
> SELECT typeof(coalesce(1, 1F))
DOUBLE
> SELECT typeof(coalesce(1L, 1F))
DOUBLE
> SELECT typeof(coalesce(1BD, 1F))
DOUBLE
-- The least common type between an INT and STRING is BIGINT
> SELECT typeof(coalesce(5, '6'));
BIGINT
-- The least common type is a BIGINT, but the value is not BIGINT.
> SELECT coalesce('6.1', 5);
Error: 6.1 is not a BIGINT
-- The least common type between a DECIMAL and a STRING is a DOUBLE
> SELECT typeof(coalesce(1BD, '6'));
DOUBLE
Die substring-Funktion erwartet Argumente vom Typ STRING für die Zeichenfolge sowie INTEGER für die Start- und Längenparameter.
-- Promotion of TINYINT to INTEGER
> SELECT substring('hello', 1Y, 2);
he
-- No casting
> SELECT substring('hello', 1, 2);
he
-- Casting of a literal string
> SELECT substring('hello', '1', 2);
he
-- Downcasting of a BIGINT to an INT
> SELECT substring('hello', 1L, 2);
he
-- Crosscasting from STRING to INTEGER
> SELECT substring('hello', str, 2)
FROM VALUES(CAST('1' AS STRING)) AS T(str);
he
-- Crosscasting from INTEGER to STRING
> SELECT substring(12345, 2, 2);
23
|| (CONCAT) ermöglicht implizites Crosscasting in eine Zeichenfolge.
-- A numeric is cast to STRING
> SELECT 'This is a numeric: ' || 5.4E10;
This is a numeric: 5.4E10
-- A date is cast to STRING
> SELECT 'This is a date: ' || DATE'2021-11-30';
This is a date: 2021-11-30
date_add kann mit einem TIMESTAMP oder BIGINT durch implizites Downcasting aufgerufen werden.
> SELECT date_add(TIMESTAMP'2011-11-30 08:30:00', 5L);
2011-12-05
date_add kann mit STRINGn durch implizites Crosscasting aufgerufen werden.
> SELECT date_add('2011-11-30 08:30:00', '5');
2011-12-05