Arbeiten mit Daten in ASP.NET Core-Apps
Tipp
Diese Inhalte sind ein Auszug aus dem E-Book „Architect Modern Web Applications with ASP.NET Core and Azure“, das unter .NET Docs oder als kostenlos herunterladbare PDF-Datei verfügbar ist, die offline gelesen werden kann.

„Daten sind ein wertvolles Gut und werden länger erhalten bleiben als die Systeme.“
Tim Berners-Lee
Der Datenzugriff stellt in beinahe allen Softwareanwendungen einen wichtigen Bestandteil dar. ASP.NET Core unterstützt verschiedene Datenzugriffsoptionen, einschließlich Entity Framework Core und Entity Framework 6, sowie alle .NET-Frameworks für den Datenzugriff. Welches Framework für den Datenzugriff verwendet werden soll, hängt von den Anforderungen der jeweiligen App ab. Wenn Sie die Auswahlmöglichkeiten aus ApplicationCore und Benutzeroberflächenprojekten zusammenfassen und Informationen zur Implementierung in der Infrastruktur kapseln, können sie loser gekoppelte, testbare Software erstellen.
Entity Framework Core (für relationale Datenbanken)
Wenn Sie eine neue ASP.NET Core-Anwendung programmieren, die mit relationalen Datenbanken zusammenarbeiten muss, wird die Verwendung von Entity Framework Core (EF Core) empfohlen, damit die Anwendung auf ihre Daten zugreifen kann. EF Core ist eine objektrelationale Zuordnung (Object-Relational Mapper, O/RM), die es .NET-Entwicklern ermöglicht, Objekte aus Datenquellen zu entnehmen oder diesen hinzuzufügen. In EF Core ist der Großteil des Datenzugriffscodes, den Entwickler in der Regel schreiben müssen, nicht mehr erforderlich. Ähnlich wie ASP.NET Core wurde auch EF Core von Grund auf neu erstellt, um modulare plattformübergreifende Anwendungen zu unterstützen. Sie fügen den Dienst als NuGet-Paket zu Ihrer Anwendung hinzu, konfigurieren dieses beim App-Start und fordern es bei Bedarf per Abhängigkeitsinjektion an.
Wenn Sie EF Core mit einer SQL Server-Datenbank verwenden möchten, führen Sie den folgenden Dotnet-CLI-Befehl aus:
dotnet add package Microsoft.EntityFrameworkCore.SqlServer
Führen Sie den folgenden Befehl zum Testen aus, wenn Sie Unterstützung für eine InMemory-Datenquelle hinzufügen möchten:
dotnet add package Microsoft.EntityFrameworkCore.InMemory
DbContext
Sie benötigen zum Arbeiten mit EF Core eine Unterklasse von DbContext. Diese Klasse enthält Eigenschaften, die Auflistungen der Entitäten darstellt, mit denen Ihre Anwendung arbeiten soll. Das eShopOnWeb-Beispiel umfasst einen CatalogContext mit Auflistungen für Elemente, Marken und Typen:
public class CatalogContext : DbContext
{
public CatalogContext(DbContextOptions<CatalogContext> options) : base(options)
{
}
public DbSet<CatalogItem> CatalogItems { get; set; }
public DbSet<CatalogBrand> CatalogBrands { get; set; }
public DbSet<CatalogType> CatalogTypes { get; set; }
}
Ihr DbContext muss über einen Konstruktor verfügen, der DbContextOptions akzeptiert, und dieses Argument an den Basiskonstruktor DbContext übergeben. Sie können nur eine DbContextOptions-Instanz übergeben, wenn Sie nur über ein DbContext-Element in Ihrer Anwendung verfügen. Wenn es allerdings mehrere Elemente sind, müssen Sie den generischen DbContextOptions<T>-Typ verwenden, der Ihren DbContext-Typ als generischen Parameter übergibt.
Konfigurieren von EF Core
In Ihrer ASP.NET Core-Anwendung konfigurieren Sie in der Regel EF Core in Ihrer Program.cs, zusammen mit den anderen Abhängigkeiten Ihrer Anwendung. EF Core verwendet einen DbContextOptionsBuilder, der mehrere nützliche Erweiterungsmethoden unterstützt, um seine Konfiguration zu optimieren. Zum Konfigurieren von CatalogContext zur Verwendung einer SQL Server-Datenbank mit einer in der Konfiguration definierten Verbindungszeichenfolge sollten Sie den folgenden Code hinzufügen:
builder.Services.AddDbContext<CatalogContext>(
options => options.UseSqlServer(
builder.Configuration.GetConnectionString("DefaultConnection")));
Zur Verwendung in der In-Memory-Datenbank:
builder.Services.AddDbContext<CatalogContext>(options =>
options.UseInMemoryDatabase());
Nachdem Sie EF Core installiert, einen untergeordneten „DbContext“-Typ erstellt und diesen den Diensten der Anwendung hinzugefügt haben, können Sie EF Core verwenden. Sie können in jedem Dienst, der eine Instanz Ihres „DbContext“-Typs benötigt, diese anfordern und damit beginnen, mit Ihren gespeicherten Entitäten unter Verwendung von LINQ so zu arbeiten, als würden diese sich nur in einer Auflistung befinden. EF Core übersetzt Ihre LINQ-Ausdrücke dann in SQL-Abfragen, um Ihre Daten zu speichern und abzurufen.
Sie können wie in Abbildung 8–1 dargestellt die Abfragen abrufen, die EF Core ausführt, indem Sie eine Protokollierung konfigurieren und sicherstellen, dass diese mindestens auf „Information“ festgelegt ist.
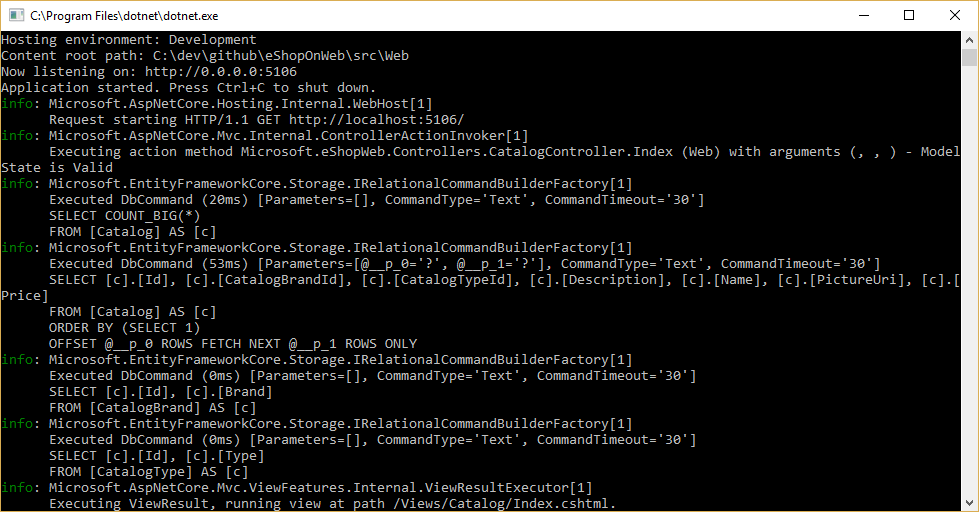
Abbildung 8-1. Protokollieren von EF Core-Abfragen an die Konsole
Abrufen und Speichern von Daten
Greifen Sie zum Abrufen von Daten aus EF Core auf eine passende Eigenschaft zu, und verwenden Sie LINQ, um das Ergebnis zu filtern. Außerdem können Sie LINQ verwenden, um eine Projektion durchzuführen, indem Sie das Ergebnis von einem Typ in einen anderen umwandeln. Über das folgende Beispiel werden CatalogBrands-Elemente abgerufen, die nach Namen sortiert und anhand ihrer Eigenschaft „Enabled“ (Aktiviert) sortiert sind und auf einen SelectListItem-Typ projiziert werden:
var brandItems = await _context.CatalogBrands
.Where(b => b.Enabled)
.OrderBy(b => b.Name)
.Select(b => new SelectListItem {
Value = b.Id, Text = b.Name })
.ToListAsync();
Im oben stehenden Beispiel ist es wichtig, dass der Aufruf zu ToListAsync hinzugefügt wird, um die Abfrage sofort auszuführen. Andernfalls weist die Anweisung ein IQueryable<SelectListItem>-Element zu brandItems zu, das erst ausgeführt wird, nachdem es aufgelistet wurde. Das Zurückgeben von IQueryable-Ergebnissen aus Methoden hat sowohl Vor- als auch Nachteile. Auf der einen Seite kann die Abfrage, die EF Core erstellt, dadurch weiter verändert werden. Auf der anderen Seite kann dies auch Fehler zur Folge haben, die nur zur Laufzeit auftreten, wenn Vorgänge zu der Abfrage hinzugefügt werden, die EF Core nicht übersetzen kann. In der Regel ist es sicherer, Filter an die Methode zu übergeben, die den Datenzugriff durchführt, und eine In-Memory-Auflistung (z. B. List<T>) als Ergebnis zurückzugeben.
EF Core verfolgt Änderungen an Entitäten nach, die aus dem Persistenzspeicher abgerufen werden. Wenn Sie Änderungen an einer nachverfolgten Entität speichern möchten, rufen Sie einfach die SaveChangesAsync-Methode für den DbContext auf und stellen dabei sicher, dass es sich um dieselbe DbContext-Instanz handelt, die auch verwendet wurde, um die Entität abzurufen. Das Hinzufügen und Entfernen von Entitäten geschieht direkt über die entsprechende DbSet-Eigenschaft, auch hier wieder mit einem Aufruf von SaveChangesAsync, um die Datenbankbefehle auszuführen. Im folgenden Beispiel wird dargestellt, wie Sie Entitäten zum Persistenzspeicher hinzufügen, diese darin aktualisieren und aus ihm entfernen.
// create
var newBrand = new CatalogBrand() { Brand = "Acme" };
_context.Add(newBrand);
await _context.SaveChangesAsync();
// read and update
var existingBrand = _context.CatalogBrands.Find(1);
existingBrand.Brand = "Updated Brand";
await _context.SaveChangesAsync();
// read and delete (alternate Find syntax)
var brandToDelete = _context.Find<CatalogBrand>(2);
_context.CatalogBrands.Remove(brandToDelete);
await _context.SaveChangesAsync();
EF Core unterstützt sowohl synchrone als auch asynchrone Methoden zum Abrufen und Speichern. In Webanwendungen wird empfohlen, das Async/Await-Muster mit der Async-Methode zu verwenden, damit keine Webserverthreads blockiert werden, während darauf gewartet wird, dass Datenzugriffsvorgänge abgeschlossen werden.
Weitere Informationen finden Sie unter Puffern und Streaming.
Abrufen zugehöriger Daten
Wenn EF Core Entitäten abruft, werden alle Eigenschaften aufgefüllt, die direkt mit dieser Entität in der Datenbank gespeichert werden. Navigationseigenschaften wie Listen mit verknüpften Entitäten werden nicht aufgefüllt, und ihr Wert ist möglicherweise auf NULL festgelegt. Durch diesen Prozess wird sichergestellt, dass EF Core nicht mehr Daten abruft als nötig. Dies ist besonders für Webanwendungen wichtig, die schnell Anforderungen verarbeiten und auf effiziente Weise Antworten zurückgeben müssen. Geben Sie wie im Folgenden dargestellt unter Verwendung der Erweiterungsmethode „Include“ bei der Abfrage die Eigenschaft an, um über Eager Loading Beziehungen zu einer Entität hinzuzufügen:
// .Include requires using Microsoft.EntityFrameworkCore
var brandsWithItems = await _context.CatalogBrands
.Include(b => b.Items)
.ToListAsync();
Sie können unter Verwendung von ThenInclude mehrere Beziehungen sowie untergeordnete Beziehungen hinzufügen. EF Core führt dann eine einzelne Abfrage aus, um die daraus entstehenden Entitäten abzurufen. Alternativ können Sie die Navigationseigenschaften von Navigationseigenschaften einfügen, indem Sie eine durch Trennzeichen (.) getrennte Zeichenfolge wie im Folgenden dargestellt an die Erweiterungsmethode .Include() übergeben:
.Include("Items.Products")
Zusätzlich zum Kapseln der Filterlogik kann eine Spezifikation die Form der zurückzugebenden Daten angeben, einschließlich der aufzufüllenden Eigenschaften. Das Beispiel „eShopOnWeb“ enthält mehrere Spezifikationen, die das Kapseln von Eager Loading-Informationen in der Spezifikation veranschaulichen. Hier sehen Sie, wie die Spezifikation als Teil einer Abfrage verwendet wird:
// Includes all expression-based includes
query = specification.Includes.Aggregate(query,
(current, include) => current.Include(include));
// Include any string-based include statements
query = specification.IncludeStrings.Aggregate(query,
(current, include) => current.Include(include));
Sie können auch das explizite Laden verwenden, um verknüpfte Daten zu laden. Beim expliziten Laden können Sie zusätzliche Daten in eine Entität laden, die bereits abgerufen wurde. Da dieser Ansatz eine separate Anforderung an die Datenbank umfasst, wird dies nicht für Webanwendungen empfohlen, die die Anzahl von Datenbankroundtrips pro Anforderung reduzieren sollen.
Beim verzögerten Laden handelt es sich um ein Feature, das automatisch verknüpfte Daten lädt, wenn die Anwendung auf dieses verweist. EF Core Version 2.1 unterstützt verzögertes Laden. Verzögertes Laden ist standardmäßig deaktiviert und erfordert die Installation von Microsoft.EntityFrameworkCore.Proxies. Ähnlich wie das explizite Laden sollte das verzögerte Laden in der Regel für Webanwendungen deaktiviert sein, da dessen Verwendung zu zusätzlichen Datenbankabfragen in jeder Webanforderung führt. Der vom verzögerten Laden verursachte zeitliche Mehraufwand wird zur Entwicklungszeit oft nicht beachtet, wenn die Wartezeit kurz ist und die für die Tests verwendeten Datasets klein sind. Allerdings können die zusätzlichen Datenbankanforderungen oft zu schlechter Leistung bei Webanwendungen führen, die intensiven Gebrauch vom verzögerten Laden machen, da in der Produktion mehr Benutzer sowie Daten vorhanden sind und höhere Wartezeiten auftreten.
Es ist eine gute Idee, Ihre Anwendung zu testen, während Sie deren tatsächlich ausgeführten Datenbankabfragen untersuchen. Unter bestimmten Umständen kann EF Core viel mehr Abfragen oder eine teurere Abfrage ausführen, als für die Anwendung optimal ist. Ein solches Problem ist als kartesische Explosion bekannt. Das EF Core-Team stellt die AsSplitQuery-Methode als eine von mehreren Möglichkeiten zur Optimierung des Laufzeitverhaltens zur Verfügung.
Kapseln von Daten
EF Core enthält mehrere Features, mit denen Sie den Zustand des Modells richtig kapseln können. Ein häufiges Problem im Zusammenhang mit Domänenmodellen ist, dass sie Navigationseigenschaften für Sammlungen als öffentlich zugängliche Listentypen zur Verfügung stellen. Dieses Problem erlaubt allen Mitarbeitern das Ändern der Inhalte dieser Sammlungstypen. Dabei können möglicherweise wichtige Geschäftsregeln umgangen werden, die im Zusammenhang mit der Sammlung stehen, wodurch das Objekt in einem ungültigen Zustand hinterlassen wird. Zur Lösung dieses Problems können Sie lediglich schreibgeschützten Zugriff auf verwandte Sammlungen auf gewähren und explizit Methoden zur Verfügung stellen, über die Clients Änderungen vornehmen können. Dieser Vorgang wird im folgenden Beispiel veranschaulicht:
public class Basket : BaseEntity
{
public string BuyerId { get; set; }
private readonly List<BasketItem> _items = new List<BasketItem>();
public IReadOnlyCollection<BasketItem> Items => _items.AsReadOnly();
public void AddItem(int catalogItemId, decimal unitPrice, int quantity = 1)
{
var existingItem = Items.FirstOrDefault(i => i.CatalogItemId == catalogItemId);
if (existingItem == null)
{
_items.Add(new BasketItem()
{
CatalogItemId = catalogItemId,
Quantity = quantity,
UnitPrice = unitPrice
});
}
else existingItem.Quantity += quantity;
}
}
Dieser Entitätstyp stellt keine öffentliche List- oder ICollection-Eigenschaft zur Verfügung, sondern einen IReadOnlyCollection-Typ, der den zugrunde liegenden Listentyp umschließt. Wenn Sie dieses Muster nutzen, können Sie festlegen, dass Entity Framework Core das Unterstützungsfeld folgendermaßen verwendet:
private void ConfigureBasket(EntityTypeBuilder<Basket> builder)
{
var navigation = builder.Metadata.FindNavigation(nameof(Basket.Items));
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
}
Sie können Ihr Domänenmodell auch verbessern, indem Sie Wertobjekte für Typen verwenden, die keine Identitäten besitzen oder sich nur durch ihre Eigenschaften unterscheiden. Durch das Verwenden solcher Typen als Eigenschaften Ihrer Entitäten können Sie sicherstellen, dass die Logik für das entsprechende Wertobjekt spezifisch ist. So kann duplizierte Logik in mehreren Entitäten, die das gleiche Konzept verwenden, vermieden werden. In Entity Framework Core können Sie Wertobjekte in der gleichen Tabelle wie die besitzende Entität speichern, indem Sie den Typ folgendermaßen als nicht eigenständige Entität konfigurieren:
private void ConfigureOrder(EntityTypeBuilder<Order> builder)
{
builder.OwnsOne(o => o.ShipToAddress);
}
In diesem Beispiel weist die ShipToAddress-Eigenschaft den Typ Address auf. Address ist ein Wertobjekt mit mehreren Eigenschaften wie Street und City. EF Core ordnet das Order-Objekt zu seiner Tabelle zu, die eine Spalte pro Address-Eigenschaft enthält. Dabei wird jedem Spaltennamen der Name der Eigenschaft vorangestellt. In diesem Beispiel würde die Tabelle Order Spalten wie ShipToAddress_Street und ShipToAddress_City enthalten. Es ist auf Wunsch auch möglich, nicht eigenständige Typen in gesonderten Tabellen zu speichern.
Erfahren Sie mehr über die Unterstützung nicht eigenständiger Typen in EF Core.
Robuste Verbindungen
Es kann sein, dass externe Ressourcen wie SQL-Datenbanken zeitweise nicht verfügbar sind. Wenn es zu einem temporären Ausfall kommen sollte, können Anwendungen die Wiederholungslogik verwenden, damit keine Ausnahmen ausgelöst werden. Diese Technik wird als Verbindungsresilienz bezeichnet. Sie können Ihre eigene Technik für Wiederholungen mit exponentiellem Backoff verwenden, indem Sie so viele Wiederholungen durchführen, bis die maximale Anzahl von möglichen Wiederholungen erreicht ist, und dabei die Wartezeit zwischen den einzelnen Wiederholungen immer weiter ausdehnen. Diese Technik berücksichtigt den Umstand, dass Cloudressourcen zeitweise nicht verfügbar sein können, wodurch einige Anforderungen fehlschlagen.
Entity Framework Core bietet bereits interne Datenbankverbindungsresilienz und Wiederholungslogik für Azure SQL DB. Jedoch müssen Sie die Entity Framework-Ausführungsstrategie für jede DbContext-Verbindung aktivieren, wenn Sie robuste EF Core-Verbindungen erzielen wollen.
Zum Beispiel aktiviert der folgende Code auf der EF Core-Verbindungsebene robuste SQL-Verbindungen, die wiederholt werden, wenn die Verbindung fehlschlägt.
builder.Services.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(builder.Configuration["ConnectionString"],
sqlServerOptionsAction: sqlOptions =>
{
sqlOptions.EnableRetryOnFailure(
maxRetryCount: 5,
maxRetryDelay: TimeSpan.FromSeconds(30),
errorNumbersToAdd: null);
}
);
});
Ausführungsstrategien und explizite Transaktionen mit „BeginTransaction“ und mehreren DbContext-Objekten
Wenn Wiederholungen in EF Core-Verbindungen aktiviert sind, wird jeder Vorgang, den Sie mit EF Core durchführen, zu einem individuell wiederholbaren Vorgang. Jede Abfrage und jeder Aufruf von SaveChangesAsync wird als eine Einheit wiederholt, wenn ein vorübergehender Fehler auftritt.
Wenn Ihr Code jedoch eine Transaktion mit „BeginTransaction“ ausführt, definieren Sie Ihre eigene Gruppe von Vorgängen, die als Einheit behandelt werden müssen. Alles innerhalb dieser Transaktion wird zurückgesetzt, wenn ein Fehler auftritt. Eine Ausnahme wie die Folgende wird angezeigt, wenn Sie versuchen, diese Transaktion auszuführen, wenn Sie eine EF-Ausführungsstrategie (Wiederholungsrichtlinie) verwenden und darin mehrere SaveChangesAsync-Elemente aus mehreren DbContexts aufnehmen.
System.InvalidOperationException: Die konfigurierte Ausführungsstrategie SqlServerRetryingExecutionStrategy unterstützt keine benutzerseitig initiierten Transaktionen. Verwenden Sie die Ausführungsstrategie, die von DbContext.Database.CreateExecutionStrategy() zurückgegeben wird, um alle Vorgänge in der Transaktion als wiederholbare Einheit auszuführen.
Die Lösung ist, die EF-Ausführungsstrategie mit einem Delegaten manuell aufzurufen, der alle Komponenten darstellt, die ausgeführt werden müssen. Die Ausführungsstrategie ruft den Delegaten erneut auf, wenn ein vorübergehender Fehler auftritt. Im folgenden Codebeispiel wird die Implementierung dieses Ansatzes veranschaulicht:
// Use of an EF Core resiliency strategy when using multiple DbContexts
// within an explicit transaction
// See:
// https://learn.microsoft.com/ef/core/miscellaneous/connection-resiliency
var strategy = _catalogContext.Database.CreateExecutionStrategy();
await strategy.ExecuteAsync(async () =>
{
// Achieving atomicity between original Catalog database operation and the
// IntegrationEventLog thanks to a local transaction
using (var transaction = _catalogContext.Database.BeginTransaction())
{
_catalogContext.CatalogItems.Update(catalogItem);
await _catalogContext.SaveChangesAsync();
// Save to EventLog only if product price changed
if (raiseProductPriceChangedEvent)
{
await _integrationEventLogService.SaveEventAsync(priceChangedEvent);
transaction.Commit();
}
}
});
Der erste DbContext ist der _catalogContext, und der zweite DbContext befindet sich im _integrationEventLogService-Objekt. Zum Schluss wird die Commitaktion unter Verwendung einer EF-Ausführungsstrategie für mehrere DbContext-Objekte ausgeführt.
Ressourcen: Entity Framework Core
- EF Core-Dokumentationhttps://learn.microsoft.com/ef/
- EF Core: Zugehörige Datenhttps://learn.microsoft.com/ef/core/querying/related-data
- Avoid Lazy Loading Entities in ASPNET Applications (Vermeiden von verzögertem Laden von Entitäten in ASP.NET-Anwendungen)https://ardalis.com/avoid-lazy-loading-entities-in-asp-net-applications
EF Core oder Mikro-ORM?
EF Core eignet sich gut zum Verwalten der Persistenz und kapselt vor allem die von Anwendungsentwicklern bereitgestellten Datenbankinformationen. Es gibt hierfür jedoch auch andere Möglichkeiten. Dapper ist z.B. eine Open-Source-Alternative, die häufig verwendet wird. Dabei handelt es sich um eine Mikro-ORM. Bei einer Mikro-ORM handelt es sich um ein Tool mit allen Features, die zum Zuordnen von Objekten zu Datenstrukturen benötigt werden. Bei Dapper hat man sich vor allem auf das Thema Leistung konzentriert, anstatt die zugrunde liegenden Abfragen, die verwendet werden, um Daten abzurufen und zu aktualisieren, vollständig zu kapseln. Da Dapper SQL nicht vom Entwickler abstrahiert, kann dieser sich mehr an der Hardware orientierten und genau die Abfragen schreiben, die er für einen bestimmten Vorgang zum Zugreifen auf Daten verwenden möchte.
EF Core enthält zwei wichtige Features, durch die sich dieses Tool zwar von Dapper unterscheidet, die aber gleichzeitig den Leistungsaufwand erhöhen. Das eine Feature ist die Übersetzung von LINQ-Ausdrücken in SQL. Diese Übersetzungen werden zwar zwischengespeichert, aber es ist trotzdem sehr aufwändig, wenn sie das erste Mal erstellt werden müssen. Das andere Feature ist dafür zuständig, Änderungen an Entitäten nachzuverfolgen, damit effiziente Updateanweisungen generiert werden können. Dieses Verhalten kann für bestimmte Abfragen mit der AsNoTracking-Erweiterung deaktiviert werden. Außerdem generiert EF Core SQL-Abfragen, die sehr effizient sind und kein zu hohes Maß an Leistung erfordern. Wenn Sie zudem die Abfragen, die ausgeführt werden sollen, genau steuern möchten, können Sie auch benutzerdefinierte SQL-Elemente hinzufügen oder eine gespeicherte Prozedur mit EF Core ausführen. In diesem Fall bietet Dapper eine bessere Leistung als EF Core, aber der Unterschied ist nur sehr gering. Aktuelle Benchmark-Leistungsdaten für eine Vielzahl von Datenzugriffsmethoden finden Sie auf der Dapper-Website.
Wenn Sie sehen möchten, wie sich die Dapper-Syntax von der EF Core-Syntax unterscheidet, können Sie auf zwei unterschiedliche Versionen einer Methode zurückgreifen, die eine Liste von Elementen abruft:
// EF Core
private readonly CatalogContext _context;
public async Task<IEnumerable<CatalogType>> GetCatalogTypes()
{
return await _context.CatalogTypes.ToListAsync();
}
// Dapper
private readonly SqlConnection _conn;
public async Task<IEnumerable<CatalogType>> GetCatalogTypesWithDapper()
{
return await _conn.QueryAsync<CatalogType>("SELECT * FROM CatalogType");
}
Wenn Sie komplexere Objektgraphen mit Dapper erstellen möchten, müssen Sie die jeweiligen Abfragen selbst erstellen. Im Gegensatz dazu müssen Sie in EF Core nur ein Include-Element hinzufügen. Diese Funktion wird durch eine Vielzahl verschiedener Syntaxen unterstützt, einschließlich eines Features namens „Multi Mapping“, mit dem Sie einzelne Zeile mehreren zugeordneten Objekten zuordnen können. Angenommen, Sie verfügen über eine Post-Klasse mit einer Owner-Eigenschaft des User-Typs. Dann gibt das folgende SQL-Element alle notwendigen Daten zurück:
select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id
Jede zurückgegebene Zeile umfasst sowohl User- als auch Post-Daten. Da die User-Daten über die Owner-Eigenschaft an die Post-Daten angefügt werden sollten, wird die folgende Funktion verwendet:
(post, user) => { post.Owner = user; return post; }
Im Folgenden wird die vollständig Codeliste dargestellt, über die eine Auflistung von Post-Daten mit der jeweiligen Owner-Eigenschaft, die mit den zugewiesenen User-Daten aufgefüllt ist, zurückgegeben werden kann:
var sql = @"select * from #Posts p
left join #Users u on u.Id = p.OwnerId
Order by p.Id";
var data = connection.Query<Post, User, Post>(sql,
(post, user) => { post.Owner = user; return post;});
Da Entwickler im Zusammenhang mit Dapper weniger Kapselungen vornehmen müssen, ist es erforderlich, dass diese wissen, wie ihre Daten gespeichert werden, wie sie diese effizient abfragen können und wie sie mehr Code schreiben können, um diese Daten abzurufen. Wenn das Modell verändert wird, darf nicht bloß eine neue Migration erstellt werden (ein anderes EF Core-Feature) und/oder Informationen einem Ort in DbContext zugeordnet werden. Stattdessen muss jede Abfrage, die betroffen ist, aktualisiert werden. Für diese Abfragen gibt es keine Garantien hinsichtlich der Kompilierzeit. Das kann zur Laufzeit zu Unterbrechungen führen, wenn Änderungen am Modell oder an der Datenbank vorgenommen werden, sodass es schwieriger wird, Fehler direkt zu ermitteln. Nichtsdestotrotz bietet Dapper eine schnelle Leistung.
Sowohl für die meisten Anwendungen als auch für die meisten Bestandteile von Anwendungen bietet EF Core eine akzeptable Leistung. Somit sind die Vorteile hinsichtlich der Leistung für Entwickler größer als die durch den Leistungsaufwand entstehenden Nachteile. Bei Abfragen, die von Zwischenspeicherungen profitieren können, beansprucht die eigentliche Abfrage nur wenig Zeit, wodurch kleine Unterschiede hinsichtlich der Abfrageleistung nur in der Theorie einen Unterschied machen.
SQL und NoSQL im Vergleich
In der Regel werden vorzugsweise relationale Datenbanken wie SQL Server als beständige Datenspeicher verwendet. Es gibt jedoch auch noch andere Möglichkeiten. Beispielsweise bieten NoSQL-Datenbanken wie MongoDB eine andere Möglichkeit zum Speichern von Objekten. Sie müssen nicht unbedingt Tabellen oder Zeilen Objekten zuordnen, sondern können auch den vollständigen Objektgraphen serialisieren und das Ergebnis speichern. Dieser Ansatz ist, zumindest auf den ersten Blick, einfacher anzuwenden und hat positive Auswirkungen auf die Leistung. Es ist einfacher, ein einzelnes serialisiertes Objekt mit einem Schlüssel zu speichern, als das Objekt in mehrere Tabellen zu zerlegen, die in Beziehung miteinander stehen, und Zeilen zu aktualisieren, die sich seit dem letzten Abrufen des Objekts aus der Datenbank möglicherweise geändert haben. Gleichzeitig ist das Abrufen und Deserialisieren eines einzelnen Objekts aus einem schlüsselbasiertem Speicher viel einfacher und schneller als bei komplizierten Verknüpfungen oder mehreren Datenbankabfragen, die erforderlich sind, um dieses Objekt vollständig aus einer relationalen Datenbank herzustellen. Im Zusammenhang mit NoSQL-Datenbanken gibt es keine Sperren, Transaktionen oder festgelegte Schemata, wodurch die Skalierung für mehrere Computer, die sehr große Datenbanken unterstützen, einfacher wird.
Trotzdem haben NoSQL-Datenbanken auch Nachteile. Relationale Datenbanken verwenden das Prinzip der Normalisierung, um Konsistenz zu erzwingen und zu vermeiden, dass Daten dupliziert werden. Mit diesem Ansatz wird die Gesamtgröße der Datenbank reduziert und sichergestellt, dass Updates von freigegebenen Daten unmittelbar nach deren Freigabe auch für die gesamte Datenbank verfügbar sind. In einer relationalen Datenbank kann beispielsweise in einer Adresstabelle per ID auf eine Landestabelle verwiesen werden. Wird später der Name eines Landes/einer Region geändert, steht diese Aktualisierung auch für die Adressdatensätze zur Verfügung, ohne dass diese selbst aktualisiert werden müssen. Dann kann es hingegen sein, dass die Adresse und das zugehörige Land in einer NoSQL-Datenbank als Bestandteile vieler gespeicherter Objekte serialisiert werden. Nach der Aktualisierung des Namens eines Landes/einer Region müssten alle entsprechenden Objekte aktualisiert werden (nicht nur eine einzelne Zeile). Relationale Datenbanken können auch die relationale Integrität gewährleisten, indem sie Regeln wie Fremdschlüssel erzwingen. NoSQL-Datenbanken bieten solche Einschränkungen für ihre Daten in der Regel nicht.
Außerdem muss im Zusammenhang mit NoSQL-Datenbanken der komplizierte Aspekt der Versionsverwaltung beachtet werden. Wenn sich die Eigenschaften eines Objekts ändern, kann es sein, dass dieses nicht aus früheren gespeicherten Versionen deserialisiert werden kann. Daher müssen alle vorhandenen Objekte, die über eine serialisierte (Vorgänger-)Version des Objekts verfügen, aktualisiert werden, damit sie dem neuen Schema entsprechen. Das Konzept dieses Ansatzes unterscheidet sich nicht von relationalen Datenbanken, bei denen Schemaänderungen manchmal Updateskripts oder Zuordnungsupdates erfordern. Die Anzahl von Einträgen, die geändert werden müssen, ist jedoch beim NoSQL-Ansatz häufig viel höher, da mehr Daten dupliziert werden.
In NoSQL-Datenbanken ist es möglich, mehrere Versionen von Objekten zu speichern. Dies wird von relationalen Datenbanken mit festem Schema in der Regel nicht unterstützt. In diesem Fall muss Ihr Anwendungscode erfassen, ob Vorgängerversionen von Objekten vorhanden sind. Dies macht das Konzept zusätzlich komplexer.
NoSQL-Datenbanken erzwingen in der Regel nicht das ACID-Prinzip, weshalb sie im Hinblick auf die Leistung und Skalierbarkeit einen Vorteil gegenüber relationalen Datenbanken aufweisen. Sie eignen sich besonders gut für extrem große Datasets und Objekte, die sich nicht zum Speichern in genormten Tabellenstrukturen eignen. Sie müssen sich aber nicht zwischen relationalen Datenbanken und NoSQL-Datenbanken entscheiden: Sie können sogar innerhalb einer Anwendung für jeden einzelnen Bestandteil entscheiden, welche Art von Datenbank sich besser eignet.
Azure Cosmos DB
Azure Cosmos DB ist ein vollständig verwalteter Dienst für NoSQL-Datenbanken, der einen cloudbasierten schemalosen Datenspeicher umfasst. Azure Cosmos DB ist auf schnelle und vorhersagbare Leistung, Hochverfügbarkeit, elastische Skalierung und globale Verteilung ausgerichtet. Obwohl es sich um einen Dienst für NoSQL-Datenbanken handelt, können Entwickler aufwändige und vertraute SQL-Abfragefunktionen für JSON-Daten verwenden. Alle Ressourcen in Azure Cosmos DB werden als JSON-Dokumente gespeichert. Ressourcen werden als Elemente, bei denen es sich um Dokumente mit Metadaten handelt, und als Feeds verwaltet, bei denen es sich um Auflistungen von Elementen handelt. In Abbildung 8–2 wird die Beziehung zwischen verschiedenen Azure Cosmos DB-Ressourcen dargestellt.
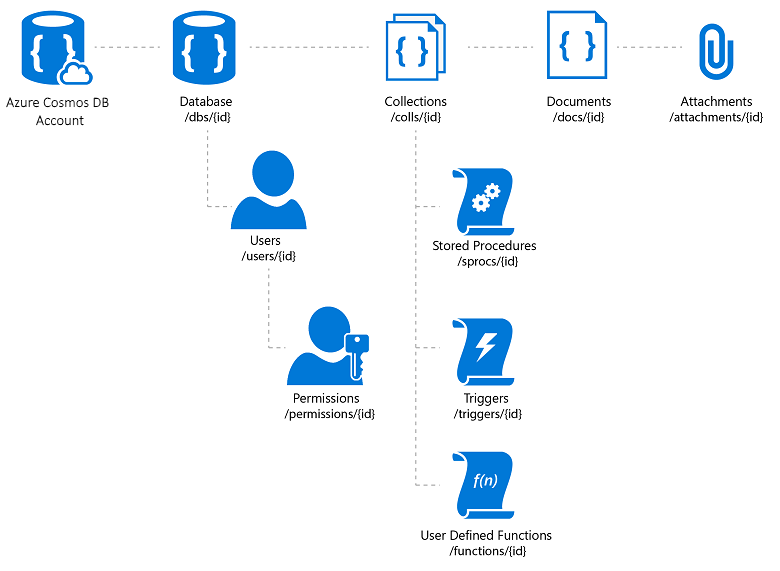
Abbildung 8–2. Azure Cosmos DB-Ressourcenorganisation
Die Azure Cosmos DB-Abfragesprache ist eine einfache und dennoch effektive Schnittstelle für das Abfragen von JSON-Dokumenten. Diese Sprache unterstützt einen Teil der durch das American National Standards Institute (ANSI) festgelegten Grammatik und umfasst eine ausführliche Integration von JavaScript-Objekten, Arrays, Objektkonstruktionen und Funktionsaufrufen.
Verweise: Azure Cosmos DB
- Einführung in Azure Cosmos DB https://learn.microsoft.com/azure/cosmos-db/introduction
Andere Persistenzoptionen
Neben relationalen Speicheroptionen und NoSQL-Optionen können ASP.NET Core-Anwendungen auch Azure Storage verwenden, um verschiedene Datenformate und Dateien auf cloudbasierte, skalierbare Weise zu speichern. Azure Storage ist im großen Umfang skalierbar, d.h., Sie können zunächst kleine Mengen von Daten speichern und zentral hochskalieren, und den Umfang dann auf mehrere Hundert Terrabyte ausweiten, falls dies die Anwendung erfordert. Azure Storage unterstützt vier verschiedene Arten von Daten:
Blob Storage für unstrukturierten Text oder als Binärspeicher (auch als Objektspeicher bezeichnet)
Table Storage für strukturierte Datasets, auf die über Zeilenschlüssel zugegriffen werden kann
Queue Storage für zuverlässiges warteschlangenbasiertes Messaging
File Storage für den Zugriff auf freigegebene Dateien zwischen virtuellen Azure-Computern und lokalen Anwendungen
Ressourcen: Azure Storage
- Einführung in Azure Storage https://learn.microsoft.com/azure/storage/common/storage-introduction
Zwischenspeicherung
In Webanwendungen sollte jede Webanforderung so schnell wie möglich abgeschlossen werden. Eine Möglichkeit, diese Funktionalität zu erreichen, besteht darin, die Anzahl externer Aufrufe einzuschränken, die ein Server stellen muss, um die Anforderung abzuschließen. Das Zwischenspeichern umfasst das Speichern einer Kopie von Daten auf dem Server oder in einem anderen Datenspeicher, der leichter abgefragt werden kann als die Datenquelle. Webanwendungen und insbesondere traditionelle Webanwendungen, bei denen es sich nicht um Single-Page-Webanwendung handelt, müssen mit jeder Anforderung die gesamte Benutzeroberfläche erstellen. Darum müssen bei diesem Ansatz häufig dieselben Datenbankabfragen wiederholt von einer Benutzeranforderung zur nächsten durchgeführt werden. In den meisten Fällen ändern sich diese Daten nur selten, sodass es keinen Grund gibt, sie ständig aus der Datenbank abzufragen. ASP.NET Core unterstützt das Zwischenspeichern von Antworten, ganzen Seiten sowie Daten und somit ein präziseres Zwischenspeicherungsverhalten.
Wenn Sie die Zwischenspeicherung implementieren, müssen Sie das Prinzip „Separation of Concerns“ im Hinterkopf behalten. Fügen Sie möglichst keine Logik für die Zwischenspeicherung in Ihre Logik für den Datenzugriff oder Ihre Benutzeroberfläche ein. Kapseln Sie die Zwischenspeicherung stattdessen in ihren eigenen Klassen, und verwenden Sie die Konfiguration, um ihr Verhalten zu steuern. Dieser Ansatz entspricht dem Offen/Geschlossen-Prinzip und dem Prinzip der einzigen Verantwortung (Single Responsibility) und vereinfacht die Verwaltung der Verwendungsweise der Zwischenspeicherung in Ihrer Anwendung, während diese immer umfangreicher wird.
Zwischenspeichern von Antworten mit ASP.NET Core
ASP.NET Core unterstützt zwei Ebenen des Zwischenspeicherns von Antworten. Auf der ersten Ebene werden zwar keine Elemente auf dem Server zwischengespeichert, aber es werden HTTP-Header hinzugefügt, die Clients und Proxyserver anweisen, Antworten zwischenzuspeichern. Diese Funktion wird implementiert, indem das ResponseCache-Attribut individuellen Controllern oder Aktionen hinzugefügt wird:
[ResponseCache(Duration = 60)]
public IActionResult Contact()
{
ViewData["Message"] = "Your contact page.";
return View();
}
Im vorherigen Beispiel wird der folgende Header der Antwort hinzugefügt, der Clients dazu auffordert, das Ergebnis bis zu 60 Sekunden lang zwischenzuspeichern.
Cache-Control: public,max-age=60
Um der Anwendung serverseitige In-Memory-Zwischenspeicherung hinzuzufügen, müssen Sie auf das NuGet-Paket Microsoft.AspNetCore.ResponseCaching verweisen und dann die Middleware zum Zwischenspeichern von Antworten hinzufügen. Diese Middleware wird während des App-Starts mit Diensten und Middleware konfiguriert:
builder.Services.AddResponseCaching();
// other code omitted, including building the app
app.UseResponseCaching();
Die Antworten zwischenspeichernde Middleware speichert automatisch auf der Grundlage von einigen Bedingungen Antworten zwischen, die Sie anpassen können. Standardmäßig werden nur „200 – OK“-Antworten zwischengespeichert, die über die Methoden GET oder HEAD angefordert werden. Außerdem müssen Anforderungen über eine Antwort mit Cache-Control und öffentlichen Headers verfügen und können keine Header für das Authorization- oder Set-Cookie umfassen. Weitere Informationen finden Sie in einer vollständigen Liste von Zwischenspeicherungsbedingungen, die von der Antworten zwischenspeichernden Middleware verwendet werden.
Zwischenspeichern von Daten
Anstelle des oder neben dem Zwischenspeichern vollständiger Webantworten können Sie auch die Ergebnisse einzelner Datenabfragen zwischenspeichern. Für diese Funktion können Sie die Zwischenspeicherung im Arbeitsspeicher auf dem Webserver oder einen verteilten Cache verwenden. In diesem Abschnitt erfahren Sie, wie Sie das speicherinterne Caching implementieren.
Fügen Sie Unterstützung für Zwischenspeicherung im Arbeitsspeicher (oder verteiltes Zwischenspeichern) mit dem folgenden Code hinzu:
builder.Services.AddMemoryCache();
builder.Services.AddMvc();
Stellen Sie sicher, dass Sie auch das NuGet-Paket Microsoft.Extensions.Caching.Memory hinzufügen.
Sobald Sie den Dienst hinzugefügt haben, fordern Sie bei jedem Zugriff auf den Cache IMemoryCache per Abhängigkeitsinjektion an. In diesem Beispiel verwendet CachedCatalogService das Entwurfsmuster „Proxy“ (oder „Decorator“), indem eine alternative Implementierung von ICatalogService bereitgestellt wird, die den Zugriff auf die zugrunde liegende CatalogService-Implementierung steuert (oder Verhalten zu dieser hinzufügt).
public class CachedCatalogService : ICatalogService
{
private readonly IMemoryCache _cache;
private readonly CatalogService _catalogService;
private static readonly string _brandsKey = "brands";
private static readonly string _typesKey = "types";
private static readonly TimeSpan _defaultCacheDuration = TimeSpan.FromSeconds(30);
public CachedCatalogService(
IMemoryCache cache,
CatalogService catalogService)
{
_cache = cache;
_catalogService = catalogService;
}
public async Task<IEnumerable<SelectListItem>> GetBrands()
{
return await _cache.GetOrCreateAsync(_brandsKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetBrands();
});
}
public async Task<Catalog> GetCatalogItems(int pageIndex, int itemsPage, int? brandID, int? typeId)
{
string cacheKey = $"items-{pageIndex}-{itemsPage}-{brandID}-{typeId}";
return await _cache.GetOrCreateAsync(cacheKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetCatalogItems(pageIndex, itemsPage, brandID, typeId);
});
}
public async Task<IEnumerable<SelectListItem>> GetTypes()
{
return await _cache.GetOrCreateAsync(_typesKey, async entry =>
{
entry.SlidingExpiration = _defaultCacheDuration;
return await _catalogService.GetTypes();
});
}
}
Um die Anwendung für die Verwendung der zwischengespeicherten Version des Diensts zu konfigurieren, wobei der Dienst aber immer noch die Instanz von CatalogService abrufen kann, die er in seinem Konstruktor benötigt, können Sie die folgenden Zeilen in Program.cs hinzufügen:
builder.Services.AddMemoryCache();
builder.Services.AddScoped<ICatalogService, CachedCatalogService>();
builder.Services.AddScoped<CatalogService>();
Wenn dieser Code eingerichtet wurde, sendet die Datenbank anstatt bei jeder Anforderung nur einmal pro Minute einen Aufruf, um die Katalogdaten abzurufen. Je nachdem, wie viel Datenverkehr an die Website gesendet wird, kann dies deutliche Auswirkungen auf die an die Datenbank gesendete Anzahl von Abfragen und die durchschnittliche Seitenladezeit der Startseite haben, die zurzeit von allen drei von diesem Dienst zur Verfügung gestellten Abfragen abhängig ist.
Wenn Sie allerdings das Caching implementieren, kann dies dazu führen, dass veraltete Daten verwendet werden. Damit sind Daten gemeint, die in der Quelle verändert wurden, von denen aber eine veraltete Version im Cache erhalten bleibt. Dieses Problem können Sie umgehen, wenn Sie eine kurze Cachedauer verwenden, da es für häufig verwendete Anwendungen nur wenig hilfreich ist, diese Dauer auszuweiten. Angenommen, Sie verfügen z.B. über eine Seite, die eine einzelne Datenbankabfrage sendet und zehnmal pro Sekunde abgerufen wird. Wenn diese Seite für eine Minute zwischengespeichert wird, hat dies zur Folge, dass die Anzahl der Datenbankabfragen pro Minute von 600 auf 1, also um 99,8 %, reduziert wird. Wenn die Cachedauer stattdessen auf eine Stunde festgelegt wird, würde die Anzahl der Abfragen insgesamt um 99,997 % reduziert werden. Dann kann es jedoch sein, dass die zwischengespeicherten Daten viel häufiger veralten.
Stattdessen können Sie proaktiv Cacheeinträge entfernen, wenn die darin enthaltenen Daten aktualisiert werden. Jeder einzelne Eintrag kann entfernt werden, wenn dessen Schlüssel bekannt ist:
_cache.Remove(cacheKey);
Wenn in Ihrer Anwendung Funktionen zum Aktualisieren von zwischengespeicherten Einträgen enthalten sind, können Sie die jeweiligen Cacheeinträge aus dem Code entfernen, der die Updates ausführt. Es kann manchmal sein, dass es viele verschiedene Einträge gibt, die von verschiedenen Daten abhängig sind. In diesem Fall kann es hilfreich sein, mithilfe von CancellationChangeToken Abhängigkeiten zwischen Cacheeinträgen zu erstellen. Mit einem CancellationChangeToken-Element können Sie festlegen, dass mehrere Cacheeinträge gleichzeitig ablaufen, indem Sie das Token entfernen.
// configure CancellationToken and add entry to cache
var cts = new CancellationTokenSource();
_cache.Set("cts", cts);
_cache.Set(cacheKey, itemToCache, new CancellationChangeToken(cts.Token));
// elsewhere, expire the cache by cancelling the token\
_cache.Get<CancellationTokenSource>("cts").Cancel();
Die Zwischenspeicherung kann die Leistung von Webseiten drastisch verbessern, die immer wieder die gleichen Werte von der Datenbank anfordern. Stellen Sie sicher, dass Sie den Datenzugriff und die Seitenleistung messen, bevor Sie die Zwischenspeicherung hinzufügen. Wenden Sie die Zwischenspeicherung nur für notwendige Verbesserungen an. Das Zwischenspeichern verbraucht Arbeitsspeicherressourcen des Webservers und erhöht die Komplexität der Anwendung, weshalb es wichtig ist, dass Sie diese Art von Optimierung nicht voreilig durchführen.
Abrufen von Daten in BlazorWebAssembly-Apps
Wenn Sie Apps entwickeln, die Blazor Server verwenden, können Sie das Entity Framework und andere direkte Datenzugriffstechnologien verwenden, die in diesem Kapitel bisher erläutert wurden. Wenn Sie jedoch BlazorWebAssembly-Apps wie andere Frameworks für Single-Page-Webanwendung (SPA) entwickeln, benötigen Sie eine andere Strategie für den Datenzugriff. In der Regel greifen diese Anwendungen auf Daten zu und interagieren über Web-API-Endpunkte mit dem Server.
Wenn die Daten oder die ausgeführten Vorgänge vertraulich sind, lesen Sie den Abschnitt zur Sicherheit im vorherigen Kapitel, und schützen Sie Ihre APIs vor nicht autorisiertem Zugriff.
Sie finden ein Beispiel für eine BlazorWebAssembly-App in der eShopOnWeb-Referenzanwendung im Blazor-Admin-Projekt. Dieses Projekt wird im eShopOnWeb-Webprojekt gehostet und ermöglicht es Benutzern in der Gruppe „Administratoren“, die Elemente im Speicher zu verwalten. In Abbildung 8-3 finden Sie einen Screenshot der Anwendung.
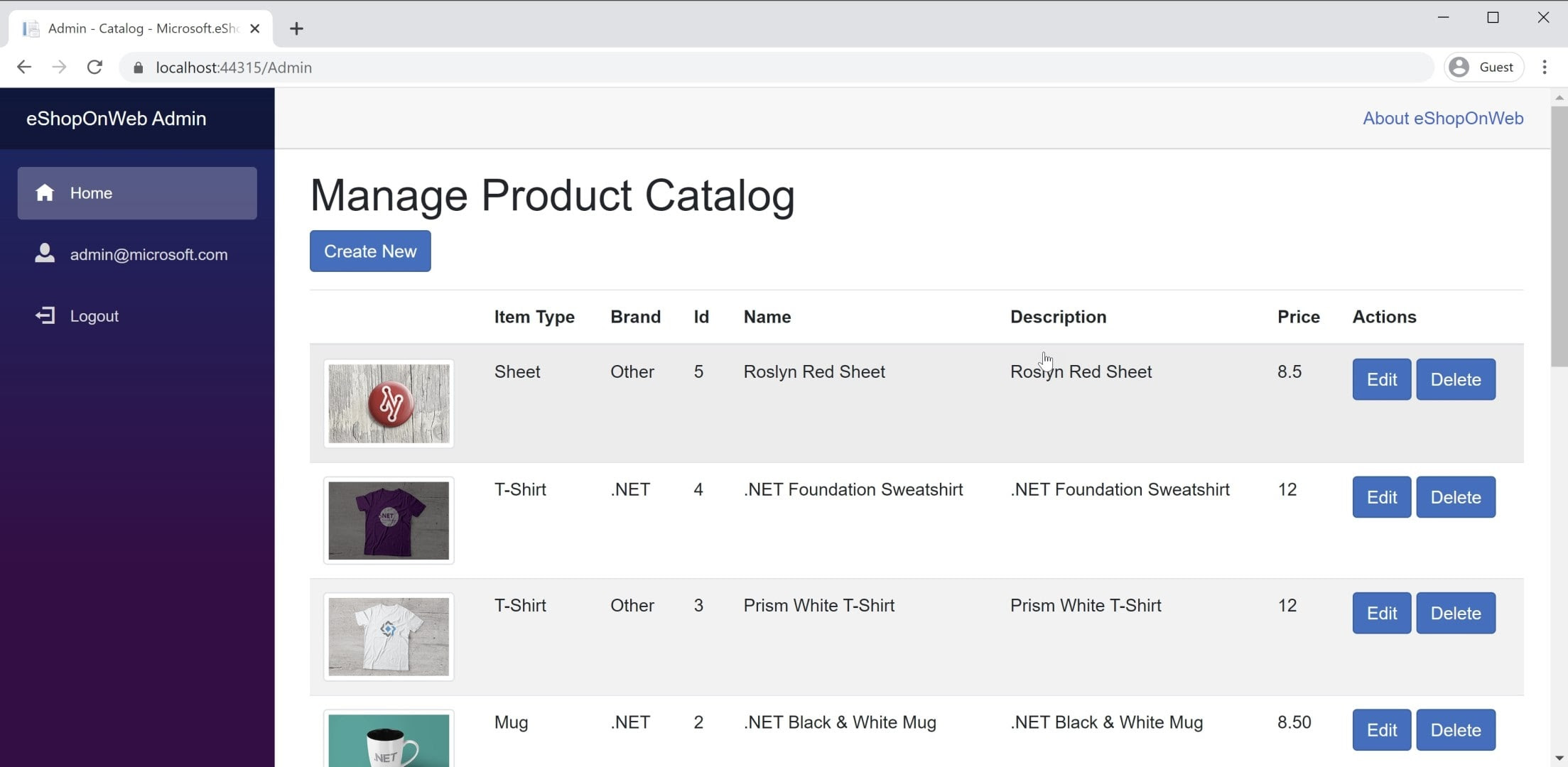
Abbildung 8-3 Screenshot: eShopOnWeb-Katalogadministrator
Beim Abrufen von Daten aus Web-APIs in einer BlazorWebAssembly-App verwenden Sie wie in jeder anderen beliebigen .NET-Anwendung einfach eine Instanz von HttpClient. Die grundlegenden Schritte sind das Erstellen der zu sendenden Anforderung (falls erforderlich, normalerweise für POST- oder PUT-Anforderungen), das Warten auf die Anforderung selbst, das Überprüfen des Statuscodes und das Deserialisieren der Antwort. Wenn Sie viele Anforderungen an eine bestimmte Gruppe von APIs stellen möchten, empfiehlt es sich, Ihre APIs zu kapseln und die HttpClient-Basisadresse zentral zu konfigurieren. Auf diese Weise können Sie die Änderungen an nur einem Ort vornehmen, wenn Sie diese Einstellungen in Abhängigkeit von der Umgebung anpassen müssen. Sie sollten die Unterstützung für diesen Dienst in Ihrer Program.Main-Methode hinzufügen:
builder.Services.AddScoped(sp => new HttpClient
{
BaseAddress = new Uri(builder.HostEnvironment.BaseAddress)
});
Wenn Sie sicher auf Dienste zugreifen müssen, sollten Sie auf ein sicheres Token zugreifen und die HttpClient-Klasse so konfigurieren, dass dieses Token als Authentifizierungsheader übergeben wird:
_httpClient.DefaultRequestHeaders.Authorization =
new AuthenticationHeaderValue("Bearer", token);
Diese Aktivität kann von jeder Komponente aus erfolgen, in die die HttpClient-Klasse eingefügt wurde, vorausgesetzt, dass die HttpClient-Klasse nicht zu den Anwendungsdiensten mit einer Transient-Lebensdauer hinzugefügt wurde. Jeder Verweis auf die HttpClient-Klasse in der Anwendung verweist auf dieselbe Instanz, sodass Änderungen an der Anwendung in einer Komponente für die gesamte Anwendung übernommen werden. Eine gute Stelle zum Durchführen dieser Authentifizierungsüberprüfung (gefolgt von der Angabe des Tokens) befindet sich in einer freigegebenen Komponente wie der Hauptnavigation für die Website. Informieren Sie sich über diesen Ansatz im BlazorAdmin-Projekt in der eShopOnWeb-Referenzanwendung.
Ein Vorteil von BlazorWebAssembly im Vergleich zu herkömmlichen JavaScript-Single-Page-Webanwendungen besteht darin, dass Sie keine Kopien Ihrer synchronisierten Datenübertragungsobjekte (Data Transfer Objects, DTO) aufbewahren müssen. Ihr BlazorWebAssembly-Projekt und Ihr Web-API-Projekt können beide dieselben DTOs in einem gemeinsamen freigegebenen Projekt nutzen. Durch diesen Ansatz entfällt ein Teil der aufwendigen Entwicklung von Single-Page-Webanwendungen.
Sie können die integrierte Hilfsmethode GetFromJsonAsync verwenden, um Daten schnell von einem API-Endpunkt abzurufen. Es gibt ähnliche Methoden für POST, PUT usw. Im Folgenden sehen Sie, wie Sie mithilfe eines konfigurierten HttpClient in einer BlazorWebAssembly-App ein CatalogItem von einem API-Endpunkt abrufen:
var item = await _httpClient.GetFromJsonAsync<CatalogItem>($"catalog-items/{id}");
Wenn Sie über die benötigten Daten verfügen, werden die Änderungen in der Regel lokal nachverfolgt. Wenn Sie Updates für den Back-End-Datenspeicher durchführen möchten, rufen Sie zu diesem Zweck zusätzliche Web-APIs auf.
Verweise: Blazor-Daten
- Aufrufen einer Web-API aus ASP.NET Core Blazorhttps://learn.microsoft.com/aspnet/core/blazor/call-web-api
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Issues stufenweise als Feedbackmechanismus für Inhalte abbauen und durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter https://aka.ms/ContentUserFeedback.
Feedback senden und anzeigen für