Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Azure
Ermöglichen Sie einer Anwendung beim Herstellen einer Verbindung mit einem Dienst oder einer Netzwerkressource die Behandlung vorübergehender Fehler, indem ein fehlgeschlagener Vorgang transparent wiederholt wird. Dies kann die Stabilität der Anwendung verbessern.
Kontext und Problem
Eine Anwendung, die mit in der Cloud ausgeführten Elementen kommuniziert, muss gegenüber vorübergehenden Fehlern empfindlich sein, die in dieser Umgebung auftreten können. Fehler umfassen den vorübergehenden Verlust der Netzwerkkonnektivität mit Komponenten und Diensten, die vorübergehende Nichtverfügbarkeit eines Diensts oder Timeouts, die auftreten, wenn ein Dienst ausgelastet ist.
Diese Fehler werden in der Regel automatisch behoben, und wenn die Aktion, die einen Fehler ausgelöst hat, nach einer angemessenen Verzögerung wiederholt wird, wird sie wahrscheinlich erfolgreich ausgeführt. Beispielsweise kann ein Datenbankdienst, der eine große Anzahl gleichzeitiger Anforderungen verarbeitet, eine Drosselungsstrategie implementieren, durch die weitere Anforderungen vorübergehend abgelehnt werden, bis die Arbeitsauslastung abgenommen hat. Eine Anwendung, die auf die Datenbank zuzugreifen versucht, kann möglicherweise keine Verbindung herstellen, doch ist bei einem wiederholten Versuch nach einer Verzögerung der Zugriff möglich.
Lösung
In der Cloud ist mit vorübergehenden Fehlern zu rechnen, und eine Anwendung sollte so entworfen sein, dass diese elegant und transparent behandelt werden. Dadurch verringern sich die Auswirkungen, die Fehler auf die Geschäftsaufgaben haben können, die von der Anwendung ausgeführt werden. Das am häufigsten verwendete Entwurfsmuster ist die Einführung eines Wiederholungsmechanismus.
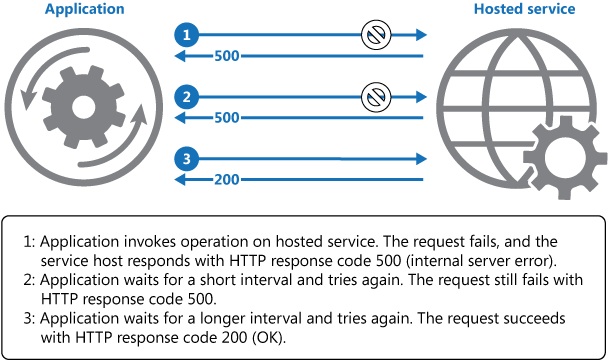
Das obige Diagramm veranschaulicht das Aufrufen eines Vorgangs in einem gehosteten Dienst mithilfe eines Wiederholungsmechanismus. Wenn die Anforderung nach einer vordefinierten Anzahl von Versuchen nicht erfolgreich ausgeführt werden kann, sollte die Anwendung den Fehler als Ausnahme behandeln und entsprechend vorgehen.
Hinweis
Aufgrund der Alltäglichkeit vorübergehender Fehler stehen in vielen Client-Bibliotheken und Clouddiensten mittlerweile integrierte Wiederholungsmechanismen zur Verfügung, die eine gewisse Konfigurierbarkeit der maximalen Anzahl von Wiederholungsversuchen, der Verzögerung zwischen den Wiederholungsversuchen und anderer Parameter ermöglichen. Beispielsweise bietet Entity Framework Core Funktionen zum Wiederholen von fehlgeschlagenen Datenbankoperationen.
Wiederholungsstrategien
Wenn eine Anwendung beim Senden einer Anforderung an einen Remotedienst einen Fehler erkennt, kann dieser mithilfe der folgenden Strategien behandelt werden:
Abbrechen. Wenn der Fehler anzeigt, dass er nicht vorübergehend ist oder durch eine Wiederholung wahrscheinlich nicht erfolgreich behoben werden kann, sollte die Anwendung den Vorgang abbrechen und eine Ausnahme melden.
Sofortiger Wiederholungsversuch. Wenn der gemeldete spezifische Fehler ungewöhnlich oder selten ist, z. B. wenn ein Netzwerkpaket beschädigt wird, während es übertragen wurde, kann die beste Aktion sein, die Anforderung sofort erneut zu versuchen.
Wiederholen nach Verzögerung. Wenn der Fehler durch einen der häufigeren Verbindungs- oder Überlastungsfehler verursacht wird, benötigt das Netzwerk oder der Dienst möglicherweise eine kurze Zeitspanne, während die Konnektivitätsprobleme behoben werden oder der Arbeitsrückstand gelöscht wird. Eine geplante Verzögerung des erneuten Versuches ist daher eine gute Strategie. In vielen Fällen sollte der Zeitraum zwischen den Wiederholungsversuchen so gewählt werden, dass Anfragen von mehreren Instanzen der Anwendung möglichst gleichmäßig verteilt werden, um die Wahrscheinlichkeit zu verringern, dass ein ausgelasteter Dienst weiterhin überlastet ist.
Schlägt die Anforderung immer noch fehl, kann die Anwendung warten und einen erneuten Versuch unternehmen. Bei Bedarf kann dieser Vorgang mit zunehmender Verzögerung zwischen den Wiederholungsversuchen ausgeführt werden, bis eine maximale Anzahl von Anforderungsversuchen unternommen wurde. Die Verzögerung kann inkrementell oder exponentiell erhöht werden, je nach Art des Fehlers und der Wahrscheinlichkeit, dass er während dieser Zeit behoben wird.
Die Anwendung sollte alle Zugriffsversuche auf einen Remotedienst in Code einschließen, der eine Wiederholungsrichtlinie implementiert, die einer der oben aufgeführten Strategien entspricht. Anforderungen, die an verschiedene Dienste gesendet werden, können unterschiedliche Richtlinien unterliegen.
Eine Anwendung sollte die Details der Fehler und fehlgeschlagenen Vorgänge protokollieren. Diese Informationen sind für Betreiber nützlich. Davon abgesehen ist es, um Betreiber nicht mit einer Flut von Betriebswarnungen zu Vorgängen zu überschwemmen, die bei der Wiederholung dann doch erfolgreich ausgeführt wurden, empfehlenswert, frühe Fehler als Informationseinträge und nur fehlgeschlagene letzte Wiederholungen als echte Fehler zu protokollieren. Hier sehen Sie ein Beispiel dafür, wie dieses Protokollierungsmodell aussehen würde.
Wenn ein Dienst häufig nicht verfügbar oder ausgelastet ist, liegt dies oft daran, dass die Ressourcen des Diensts ausgeschöpft sind. Sie können die Häufigkeit dieser Fehler reduzieren, indem Sie den Dienst skalieren. Wenn beispielsweise ein Datenbankdienst ständig überlastet ist, kann es nützlich sein, die Datenbank zu partitionieren und die Last auf mehrere Server zu verteilen.
Probleme und Überlegungen
Bei der Entscheidung, wie dieses Muster implementiert werden soll, sind die folgenden Punkte zu beachten.
Auswirkungen auf die Leistung
Die Wiederholungsrichtlinie sollte entsprechend den geschäftlichen Anforderungen der Anwendung und der Art des Fehlers angepasst werden. Bei einigen nicht kritischen Vorgängen ist es besser, schnell zu fehlschlagen, anstatt mehrmals erneut zu versuchen und den Durchsatz der Anwendung zu beeinflussen. Bei einer interaktiven Webanwendung, die auf einen Remotedienst zugreift, ist es beispielsweise besser, nach wenigen Versuchen mit kurzen Verzögerungen dazwischen abzubrechen und dem Benutzer eine entsprechende Meldung anzuzeigen (z. B. „Bitte versuchen Sie es später erneut“). Bei einer Batchanwendung ist es möglicherweise besser, die Anzahl der Wiederholungsversuche mit einer exponentiell zunehmenden Verzögerung zwischen den einzelnen Versuchen zu erhöhen.
Eine aggressive Wiederholungsrichtlinie mit minimaler Verzögerung zwischen den Versuchen und einer hohen Anzahl von Wiederholungen könnte einen Dienst, der nahezu oder an seiner Kapazitätsgrenze arbeitet, zusätzlich belasten. Diese Wiederholungsrichtlinie könnte sich auch auf die Reaktionsfähigkeit der Anwendung auswirken, wenn ständig versucht wird, einen fehlgeschlagenen Vorgang auszuführen.
Wenn eine Anforderung nach einer erheblichen Anzahl von Wiederholungen immer noch fehlschlägt, ist es besser, dass die Anwendung weitere Anforderungen an dieselbe Ressource verhindert und sofort einen Fehler meldet. Nach Ablauf des Zeitraums kann die Anwendung eine oder mehrere Anforderungen vorläufig zulassen, um festzustellen, ob diese erfolgreich ausgeführt werden. Weitere Informationen zu dieser Strategie finden Sie unter Circuit Breaker Pattern.
Idempotenz
Achten Sie darauf, ob der Vorgang idempotent ist. Wenn das der Fall ist, ist eine Wiederholung grundsätzlich sicher. Andernfalls könnte der Vorgang bei Wiederholungen mehr als einmal ausgeführt werden, was unbeabsichtigte Nebeneffekte haben kann. Beispielsweise kann ein Dienst die Anforderung empfangen, sie erfolgreich verarbeiten, jedoch das Senden einer Antwort fehlschlagen. An diesem Punkt kann die Wiederholungslogik die Anforderung erneut senden, da davon ausgegangen wird, dass die erste Anforderung nicht empfangen wurde.
Ausnahmetyp
Eine Anforderung an einen Dienst kann aus verschiedenen Gründen fehlschlagen und unterschiedliche Ausnahmen auslösen, abhängig von der Art des Fehlers. Einige Ausnahmen geben einen Fehler an, der schnell behoben werden kann, während andere angeben, dass der Fehler länger andauert. Es ist nützlich, wenn bei der Wiederholungsrichtlinie der Zeitraum zwischen den Wiederholungsversuchen entsprechend dem Typ der Ausnahme angepasst wird.
Transaktionskonsistenz
Beachten Sie, wie sich das Wiederholen eines Vorgangs, der Teil einer Transaktion ist, auf die Transaktionskonsistenz insgesamt auswirkt. Nehmen Sie eine Feinanpassung der Wiederholungsrichtlinie für Transaktionsvorgänge vor, um die Wahrscheinlichkeit einer erfolgreichen Ausführung zu erhöhen und die Notwendigkeit zu verringern, alle Transaktionsschritte rückgängig zu machen.
Allgemeine Hinweise
Stellen Sie sicher, dass der gesamte Wiederholungscode vollständig auf verschiedene Fehlerbedingungen getestet wurde. Vergewissern Sie sich, dass er keine schwerwiegenden Auswirkungen auf die Leistungsfähigkeit oder Zuverlässigkeit der Anwendung hat, keine übermäßige Auslastung von Diensten und Ressourcen bewirkt und auch keine Racebedingungen oder Engpässe erzeugt.
Implementieren Sie eine Wiederholungslogik nur unter Berücksichtigung des gesamten Kontexts eines fehlgeschlagenen Vorgangs. Wenn beispielsweise eine Aufgabe, die eine Wiederholungsrichtlinie enthält, eine andere Aufgabe aufruft, die ebenfalls eine Wiederholungsrichtlinie enthält, kann diese zusätzliche Ebene von Wiederholungen zu lange Verzögerungen bei der Verarbeitung führen. Möglicherweise ist es besser, die Aufgabe auf niedrigerer Ebene so zu konfigurieren, dass sie Fail-Fast-fähig ist und die Ursache des Fehlers an die Aufgabe zurückmeldet, von der sie aufgerufen wurde. Diese Aufgabe auf höherer Ebene kann dann den Fehler basierend auf die eigene Strategie behandeln.
Protokollieren Sie alle Konnektivitätsfehler, die zu einer Wiederholung führen, damit zugrunde liegende Probleme mit der Anwendung, Diensten oder Ressourcen ermittelt werden können.
Untersuchen Sie die Fehler, die am wahrscheinlichsten für einen Dienst oder eine Ressource auftreten können, um festzustellen, ob diese wahrscheinlich lang andauernd oder terminal sind. Wenn das der Fall ist, sollte der Fehler besser als Ausnahme behandelt werden. Die Anwendung kann die Ausnahme melden oder protokollieren und dann fortfahren, indem entweder ein alternativer Dienst (sofern verfügbar) aufgerufen oder eingeschränkte Funktionalität geboten wird. Weitere Informationen zum Erkennen und Behandeln lang andauernder Fehler finden Sie im Circuit Breaker-Muster.
Wann dieses Muster verwendet werden sollte
Verwenden Sie dieses Muster, wenn es bei einer Anwendung zu vorübergehenden Fehlern bei der Interaktion mit einem Remotedienst oder dem Zugriff auf eine Remoteressource kommen kann. Diese Fehler sind erwartungsgemäß von kurzer Dauer und das Wiederholen einer zuvor fehlgeschlagenen Anforderung kann bei einem weiteren Versuch erfolgreich sein.
Dieses Muster ist in folgenden Fällen möglicherweise nicht geeignet:
- Wenn ein Fehler wahrscheinlich länger andauert, da sich dies auf die Reaktionsfähigkeit einer Anwendung auswirken kann. Die Anwendung verschwendet möglicherweise Zeit und Ressourcen bei dem Versuch, eine Anforderung zu wiederholen, die wahrscheinlich fehlschlägt.
- Bei der Behandlung von Fehlern, die nicht auf vorübergehenden Fehlern basieren, z. B. interne Ausnahmen, die auf Fehler in der Geschäftslogik einer Anwendung zurückzuführen sind.
- Als Alternative zur Behebung von Skalierbarkeitsproblemen in einem System. Wenn bei einer Anwendung häufig Auslastungsfehler auftreten, ist dies oft ein Zeichen dafür, dass der Dienst oder die Ressource, auf den bzw. die zugegriffen wird, hochskaliert werden sollte.
Entwurf des Arbeitslastenmodells
Ein Architekt sollte evaluieren, wie das Retry-Pattern im Design seiner Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Säulen des Azure Well-Architected Framework behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Die Abschwächung vorübergehender Fehler in einem verteilten System ist eine zentrale Technik zur Verbesserung der Widerstandsfähigkeit einer Arbeitslast. - RE:07 Selbsterhaltung - RE:07 Vorübergehende Fehler |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
In der Anleitung Implementierung einer Wiederholungsrichtlinie mit .NET finden Sie ein ausführliches Beispiel zur Verwendung des Azure SDK mit integrierter Unterstützung für Wiederholungsmechanismen.
Nächste Schritte
Bevor Sie benutzerdefinierte Wiederholungslogik schreiben, sollten Sie ein allgemeines Framework wie z. B. Polly für .NET oder Resilience4j für Java in Betracht ziehen.
Beachten Sie bei der Verarbeitung von Befehlen, die Geschäftsdaten ändern, dass Wiederholungsversuche dazu führen können, dass die Aktion zweimal ausgeführt wird. Dies kann problematisch sein, wenn diese Aktion etwa die Belastung der Kreditkarte eines Kunden ist. Mit dem in diesem Blogbeitrag beschriebenen Idempotenzmuster können Sie diese Situationen in den Griff bekommen.
Zugehörige Ressourcen
Für die meisten Azure-Dienste enthalten die Client-SDKs integrierte Wiederholungslogik.
Circuit-Breaker-Muster. Wenn bei einem Fehler davon ausgegangen wird, dass er länger andauert, ist es möglicherweise besser, das Trennschalter-Muster zu implementieren. Die Kombination von Wiederholungs-und Schutzschaltermustern stellt einen umfassenden Ansatz für die Behandlung von Fehlern dar.