Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Note
Das Feature "Lakebase Change Data Feed" befindet sich in der öffentlichen Vorschau.
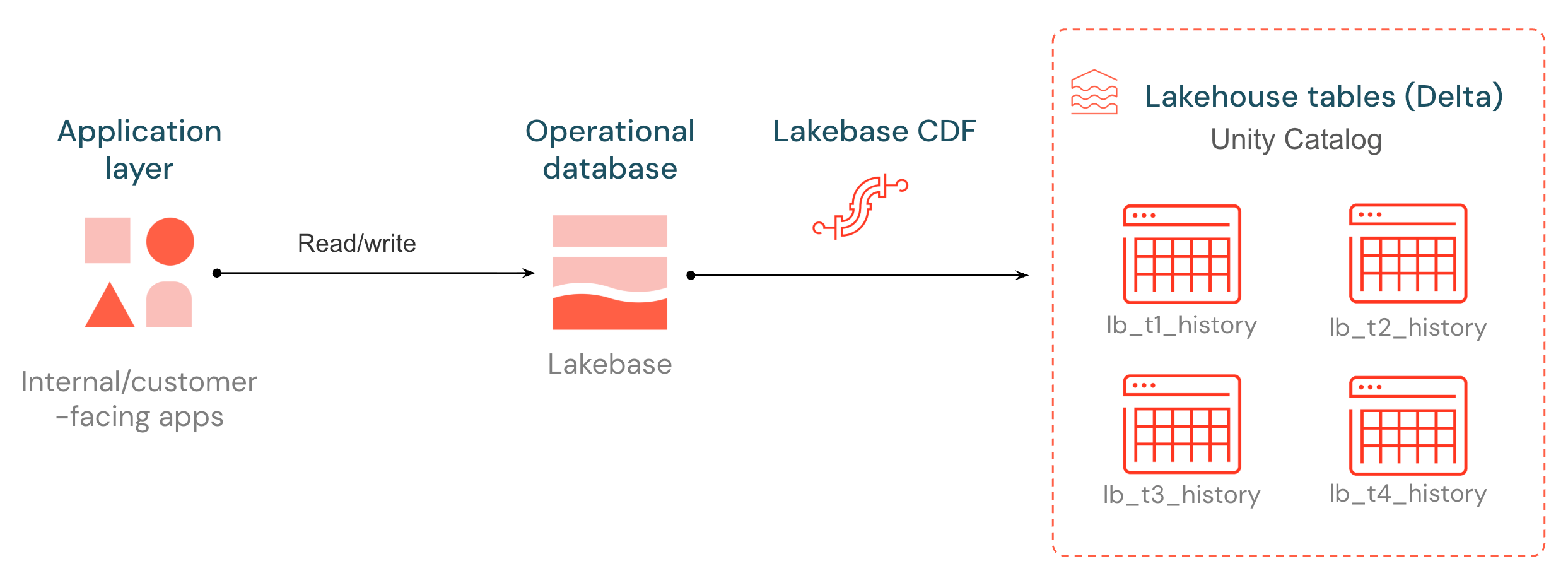
Was ist Lakebase Change Data Feed?
Lakebase führt einen nativen Change Data Feed (CDF) ein und entsperrt Ihre Betriebsdaten für nachgeschaltete Pipelines, Modelle und Anwendungen. Jeder Einfüge-, Aktualisierungs- und Löschvorgang in einer Lakebase-Postgres-Tabelle wird aus dem Write-Ahead-Log erfasst und als neue Zeile in einer von Unity Catalog verwalteten Delta-Tabelle gespeichert, in Batches verarbeitet und etwa alle 15 Sekunden geschrieben. Der Änderungsverlauf wird in einem geöffneten Format gespeichert, das jedes Computemodul lesen kann.
Die Zieltabellen folgen demselben Shape wie der Delta Change Data Feed: Jede Zeile trägt einen _pg_change_typeLSN, eine Transaktions-ID und einen Zeitstempel. Operative Änderungen werden zu einer vollwertigen Quelle für ETL, Audit und nachgelagerte Consumer — ohne einen externen CDC-Stack aufsetzen zu müssen.
Anwendungsfälle
Lakebase CDF bringt Betriebsdaten in das Seehaus ein, sodass nachgelagerte Pipelines und Anwendungen auf Änderungen reagieren können, sobald sie geschehen.
| Anwendungsfall | Description |
|---|---|
| ETL-Pipelines | Verwenden Sie Lakebase als Bronze-Quelle für Medallion-Pipelines. Erstellen Sie inkrementelle SDP- oder Spark Structured Streaming-Aufträge gegen den Änderungsfeed und aktualisieren Sie nachgelagerte Silver- und Gold-Tabellen. |
| Überwachungsprotokolle | Verwalten Sie einen vollständigen, abfragbaren Verlauf jedes Einfügens, Aktualisierens und Löschens in einer Lakebase-Tabelle für Compliance und Forensik. Die Delta-Historie ist unveränderbar. |
| Externe Systeme | Speichern Sie Lakebase-Änderungsdaten in einem offenen Format, das jedes Modul nutzen kann. Da es sich bei dem Ziel um eine Delta-Tabelle im Unity-Katalog handelt, können externe Systeme und Nicht-Databricks-Leser direkt auf den Feed zugreifen. |
Diese Vorschau aktivieren
Ein Arbeitsbereichsadministrator muss die Vorschau für Lakebase Change Data Feed auf der Vorschauseite des Arbeitsbereichs aktivieren.
Requirements
- Lakebase Autoscaling: Ein Lakebase Autocaling-Projekt mit Postgres 17.
-
Quelldatenbank: Tabellen müssen sich in der
databricks_postgresDatenbank in Lakebase befinden. Jedes Projekt wird mit dieser Standarddatenbank erstellt. Dies ist eine bekannte Einschränkung. - Unity-Katalog: Die Identität, die CDF konfiguriert, benötigt USE CATALOG, USE SCHEMAund CREATE TABLE im Zielkatalog und -schema. Siehe Erteilen von Berechtigungen für ein Objekt.
- Standardspeicher: Zielkataloge, die mit Standardspeicher konfiguriert sind, werden nicht unterstützt.
- Lakebase-Projekt: Ihre Postgres-Rolle erfordert CAN MANAGE-Berechtigungen für das Lakebase-Projekt. Projektinhaber verfügen standardmäßig über CAN MANAGE. Siehe "Projektberechtigungen verwalten".
- Datentypen: Siehe Datentypzuordnung. Typen ohne direkte Delta-Entsprechung werden als STRING gespeichert.
Einrichten des Lakebase CDF
Um zu beginnen, legen Sie die Replikatidentität vollständig für die Tabellen fest, die Sie im Feed (Schritt 1) benötigen, und starten Sie dann CDF in der Lakebase-App (Schritt 2). Ihre Daten werden als lb_<table_name>_history Delta-Tabellen im Unity-Katalogkatalog und im von Ihnen ausgewählten Schema angezeigt.
Schritt 1: Festlegen der Replikatidentität vollständig
Damit eine Lakebase-Tabelle an CDF teilnehmen kann, muss für sie REPLICA IDENTITY FULL festgelegt sein. Standardmäßig protokolliert Postgres nur den Primärschlüssel, wenn eine Zeile aktualisiert oder gelöscht wird. Das Festlegen der vollen Replikatidentität veranlasst Postgres, den Zustand der Zeile vor und nach der Änderung im Write-Ahead-Log zu speichern, den CDF benötigt, um eine vollständige Änderungshistorie zu erstellen.
Sie können diese Befehle im Lakebase SQL-Editor oder einem beliebigen Postgres-Client ausführen.
Einzelne Tabelle
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Alle vorhandenen Tabellen in einem Schema
Führen Sie Folgendes aus, um die Replikatidentität für jede vorhandene Tabelle in einem Schemapublic (in diesem Beispiel) festzulegen:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Automatisches Anwenden auf zukünftige Tabellen
Damit jede neu erstellte Tabelle automatisch empfangen wird REPLICA IDENTITY FULL, installieren Sie einen Postgres-Ereignistrigger. Wird nach jedem CREATE TABLE ausgeführt und legt die Identität für die neue Tabelle fest:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Kombinieren Sie den Ereignistrigger mit der Schleife auf der vorherigen Registerkarte, um vorhandene und zukünftige Tabellen in einem Setup abzudecken.
Überprüfen, bei welchen Tabellen die Replikatidentität festgelegt ist
Um zu sehen, welche Tabellen in einem Schema die Replikatidentität konfiguriert haben, führen Sie Folgendes aus:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Nur Zeilen mit replica_identity = 'full' sind für CDF bereit.
Schritt 2: Starten des Änderungsdatenfeeds
Lakebase CDF ist auf Schemaebene konfiguriert. Nach dem Start ist jede aktuelle und zukünftige Tabelle im Quellschema im Feed enthalten.
- Öffnen Sie in Ihrem Azure Databricks Arbeitsbereich Lakebase Postgres über den App-Switcher (oben rechts).
- Wählen Sie Ihr Lakebase-Projekt und den Zweig aus, den Sie verwenden möchten (z. B. Produktion oder Haupt).
- Öffnen Sie die Branch-Übersicht und klicken Sie auf die Registerkarte „Change Data Feed“.
- Klicken Sie auf Start.
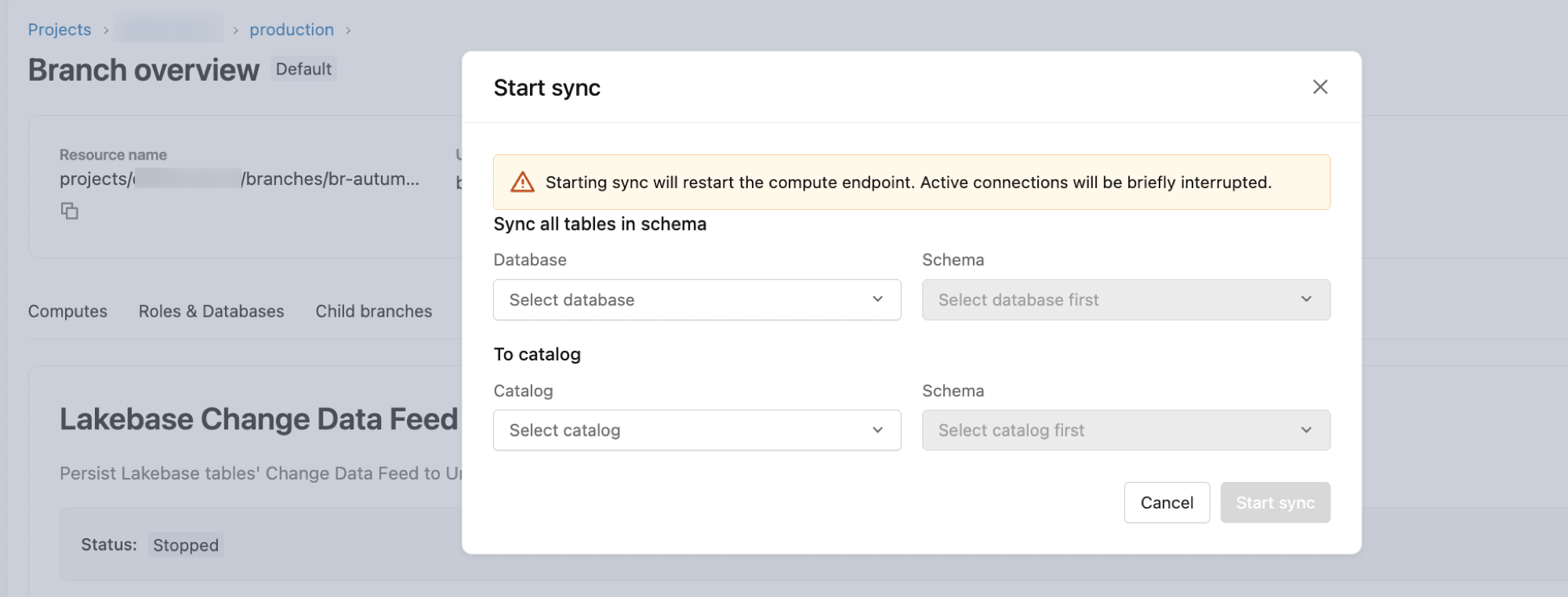
- Im Konfigurationsdialogfeld:
-
Datenbank: Standardmäßig auf
databricks_postgresgesetzt. - Schema: Wählen Sie das Quell-Postgres-Schema aus.
- Zu Katalog: Wählen Sie den Zielkatalog in Unity Catalog aus.
- Schema: Wählen Sie das Zielschema des Unity-Katalogs aus.
-
Datenbank: Standardmäßig auf
- Klicken Sie auf "Start" , um den Feed zu beginnen.
Tabellen erscheinen im Zieltext als lb_<table_name>_history. Um sie zu finden, öffnen Sie den Katalog in der Randleiste, navigieren Sie zum Zielkatalog und zum Schema, und öffnen Sie die Registerkarte "Tabellen ".
Die Registerkarte " Datenfeed ändern" in Lakebase enthält zwei Unterregisterkarten:
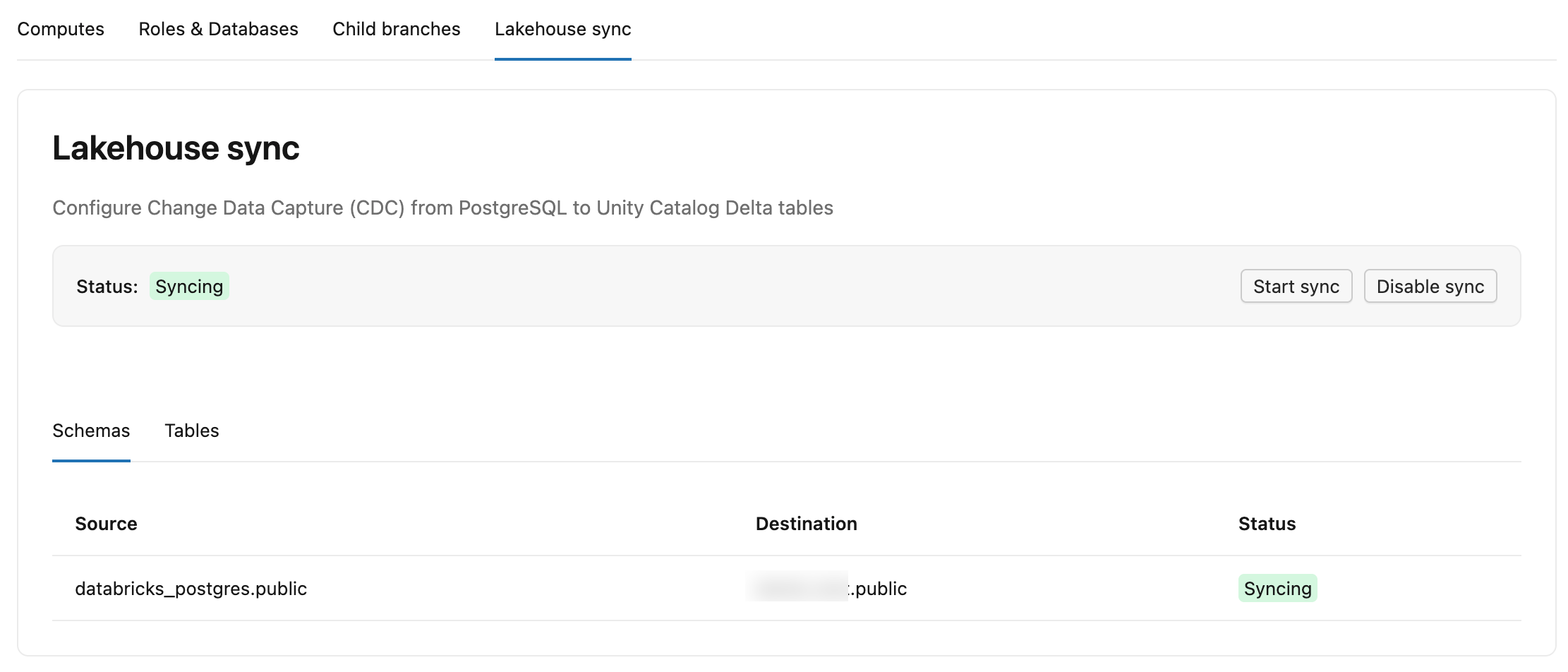
- Schemas: Listet jedes Quellschema, seinen Zielkatalog und sein Schema im Unity-Katalog und einen Status auf.
-
Tabellen: Listet jede Quelltabelle, die zugehörige
lb_<table_name>_historyZieltabelle, den Status (StreamingoderSnapshotting), die Bestätigte LSN (wie weit der Feed nach Delta geschrieben hat, angezeigt als-, solange noch die anfängliche Momentaufnahme läuft) und Letzte Aktualisierung (der letzte Zeitpunkt, zu dem die Tabelle Änderungen erhalten hat) auf.
Sie können den Feedstatus auch von Postgres überprüfen, indem Sie diesen im Lakebase SQL-Editor ausführen:
SELECT * FROM wal2delta.tables;
Das Ergebnis enthält table_oid, status (STREAMING oder SNAPSHOTTING), committed_lsnund last_write_time pro Tabelle.
Important
Was ist wal2delta? Lakebase CDF wird von der Wal2delta Postgres Erweiterung unterstützt, die innerhalb der Lakebase Compute läuft. Es verwendet die logische Dekodierung, um Änderungen aus dem Write-Ahead Log (WAL) zu erfassen und sie in Delta-Tabellen im Unity Catalog zu schreiben.
Zieltabellenschema
CDF schreibt eine Delta-Tabelle pro Quelltabelle, die in Ihrem Zielkatalog und Schema benannt ist lb_<table_name>_history . Neben Ihren Quellspalten enthält jede Zeile die folgenden Systemspalten:
| Kolumne | Typ | Description |
|---|---|---|
_pg_change_type |
TEXT | Vorgangstyp: insert, delete, , update_preimageoder update_postimage. |
_pg_lsn |
BIGINT | Postgres Log Sequence Number. |
_pg_xid |
INTEGER | Postgres Transaction ID. |
_timestamp |
TIMESTAMP | Zeitstempel, als die Änderung verarbeitet wurde (ohne Zeitzone). |
_sort_by |
BIGINT | Monotoner Sortierschlüssel, der zum Sortieren aller Änderungen verwendet wird. |
Allgemeine Änderungsmuster
-
Anfängliche Momentaufnahme: Wenn CDF zum ersten Mal auf einer vorhandenen Lakebase-Tabelle ausgeführt wird, wird jede vorhandene Zeile mit
_pg_change_type = 'insert'geschrieben. -
Updates: Eine Aktualisierung erzeugt zwei Zeilen: eine mit
_pg_change_type = 'update_preimage'(alte Zeile) und eine mit_pg_change_type = 'update_postimage'(neue Zeile). -
Löscht: Ein Löschvorgang erzeugt eine Zeile mit
_pg_change_type = 'delete'.
Hierbei handelt es sich um die gleichen Änderungsereignisse wie delta Change Data Feed, sodass dieselben downstream-Muster angewendet werden.
Betriebsverhalten
-
Benennungskonflikte: Wenn zwei Quelltabellen demselben Zielnamen zugeordnet würden (zum Beispiel, wenn
sales.usersundmarketing.usersbeidelb_users_historyzugeordnet würden), schreibt CDF die erste nachlb_users_historyund hängt an die zweite automatisch ein Suffix an, sodass sie zulb_users_history_1wird. Sie können eine der Zieltabellen im Unity-Katalog umbenennen, und der Feed funktioniert weiterhin. - Bereich auf Schemaebene: Wenn Sie CDF für ein Lakebase-Schema starten, ist jede aktuelle und zukünftige Tabelle in diesem Schema enthalten. Leere Tabellen werden übersprungen – eine Tabelle muss mindestens eine Zeile enthalten, damit sie im Ziel angezeigt wird.
- Abgelegte Quelltabellen: Wenn Sie eine Tabelle in Lakebase ablegen, wird die Zieldelta-Tabelle im Unity-Katalog beibehalten.
Erstellen nachgeschalteter Pipelines
Lakebase CDF ist für nachgelagerte Pipelines konzipiert, die auf betriebsbedingte Änderungen reagieren. Die folgenden Muster zeigen drei Möglichkeiten, den Feed zu nutzen, sortiert von der einfachsten bis zur flexibelsten.
Beispielszenario. Eine E-Commerce-App erfasst Bestellungen in einer Postgres-Tabelle orders, wobei jede Zeile ein item_id und ein quantity enthält. Das Logistikteam benötigt Live-Lagerbestände. Mit CDF wird jede Änderung an orders in der Delta-Tabelle lb_orders_history im Unity Catalog gespeichert. Nachgelagerte Pipelines lesen diesen Änderungsfeed und aktualisieren eine inventory_levels-Tabelle, sobald eine Bestellung aufgegeben, bearbeitet oder storniert wird.
Berechnen des aktuellen Inventars mit einer materialisierten Ansicht
Das einfachste Muster ist eine materialisierte SQL-Ansicht über die Verlaufstabelle. Die MV wird inkrementell aktualisiert, wenn neue Änderungsereignisse eintreffen, und nachgelagerte Nutzer fragen sie wie jede andere Tabelle ab.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
Die beiden Zeilen, die für jede Aktualisierung erstellt wurden, brechen einander ab, mit Ausnahme der Nettoänderung, sodass die laufende Summe korrekt bleibt, wenn Bestellungen bearbeitet werden.
Streamänderungen mit Spark Declarative Pipelines
Verwenden Sie für eine strukturierte Medallion-Architektur Spark Declarative Pipelines (SDP), um Bronze-, Silber- und Goldtabellen zu deklarieren. SDP führt sie als zusammenhängende Pipeline aus, wobei Prüfpunkte und die Abhängigkeitsverwaltung für Sie übernommen werden.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments
lb_orders_history liest inkrementell mit readStream und erzeugt ein Delta pro Ereignis.
inventory_levels aggregiert nach item_id, um den aktuellen Lagerbestand zu berechnen. Es wird erwartet, dass Zeilen verworfen werden, die den Bestand ins Negative bringen würden, was auf einen vorgelagerten Fehler hindeutet.
Eine vollständige End-to-End-Anleitung finden Sie im Tutorial: Erstellen Sie eine ETL-Pipeline mithilfe der Änderungsdatenerfassung.
Benutzerdefinierte Verarbeitung mit Spark Structured Streaming
Wenn Sie vollständige Kontrolle benötigen – z. B. für benutzerdefinierte Zusammenführungen, Seiteneffekte oder mehrere Zielsysteme –, lesen Sie die Verlaufstabelle direkt mit Spark Structured Streaming und verwenden Sie foreachBatch, um in Ihr Zielsystem zu schreiben.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Jeder Mikro-Batch aggregiert die Änderungsereignisse nach item_id und führt die Netto-Deltas in inventory_levels zusammen.
Von Grund auf inkrementell. Jede lb_<table_name>_history Tabelle ist eine Nur-Anfüge-Delta-Tabelle. Jede Quelländerung wird als neue Zeile aufgezeichnet, wobei _pg_change_type den Vorgang kennzeichnet. Databricks SQL materialized views, Lakeflow Spark Declarative Pipelines-Flows und Spark Structured Streaming-Jobs verarbeiten neue Zeilen inkrementell aus dem Delta-Transaktionsprotokoll, sodass nachgelagerte Pipelines nur Arbeit im Verhältnis zu den Änderungen ausführen. Sie müssen den Delta-Änderungsdatenfeed in der Verlaufstabelle nicht aktivieren, da die Änderungssemantik bereits in den Zeilendaten codiert ist.
Datentypzuordnung
CDF unterstützt die meisten standardmäßigen PostgreSQL-Grundtypen. Typen ohne direkte Delta-Entsprechung werden als STRING gespeichert.
| PostgreSQL-Typ | Azure Databricks Delta-Typ | Hinweise |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
| TEXT, VARCHAR, CHAR | STRING | |
| JSONB | STRING | Als JSON-Zeichenfolge gespeichert. |
| Enum | STRING | Wird als Enum-Bezeichnung gespeichert. |
| NUMERISCH /DEZIMAL | DEZIMAL ODER ZEICHENFOLGE | Verwendet nach Möglichkeit die Präzision/Skalierung der Quelle. Führt eine verlustlose Reskalierung für inkompatible Genauigkeits-/Skalierungswerte aus. Fällt auf STRING zurück, wenn die Genauigkeit 38 überschreitet oder wenn Genauigkeit/Skalierung nicht definiert (ungebundene ZAHL) ist. Alle NUMERISCHEn/DEZIMALspalten können nullwerte sein, da NaN-Werte NULL zugeordnet sind. Siehe PostgreSQL-numerische Typen. |
| DATE | DATE | |
| TIMESTAMP | TIMESTAMP_NTZ | |
| TIMESTAMPTZ | TIMESTAMP | |
| FLOAT, DOUBLE | FLOAT, DOUBLE |
Als STRING gespeicherte Typen:
-
Geografie/Geometrie (PostGIS): Typen aus der PostGIS-Erweiterung (z. B
geometry. ,geography). -
Vektor (pgvector): Der
vectorTyp aus der Erweiterung pgvector. -
Zusammengesetzte Typen/Strukturtypen: Benutzerdefinierte Typen, die mit
CREATE TYPE ... AS (field_name type, ...)definiert sind. Hierbei handelt es sich um zeilenähnliche Typen mit benannten Feldern. -
Map: Map-ähnliche Schlüssel-Wert-Typen wie hstore (aus der Erweiterung
hstore). Postgres hat keinen integrierten Kartentyp.hstoreist die gängige Methode zum Speichern von Schlüsselwertpaaren in einer Spalte.
Verwalten von Schemaänderungen
-
Durch das Umbenennen einer Tabelle in Postgres (z. B
ALTER TABLE users RENAME TO customers. ) kann der Feed fortgesetzt werden. Der Name der Ziel-Delta-Tabelle ändert sich nicht — er bleibtlb_users_history. - Schemaänderungen (Hinzufügen einer Spalte, Ablegen einer Spalte oder Ändern des Datentyps einer Spalte) lösen eine erneute Momentaufnahme der betroffenen Tabelle aus. CDF liest die gesamte Tabelle aus Postgres neu und schreibt sie in die Ziel-Delta-Tabelle um.
Lakebase CDF deaktivieren
Durch deaktivieren des CDF wird der Feed für alle Lakebase-Schemas im Projekt beendet.
- Öffnen Sie in Ihrem Azure Databricks Arbeitsbereich Lakebase Postgres über den App-Switcher (oben rechts).
- Wählen Sie Ihr Lakebase-Projekt und den Zweig aus, in dem Sie CDF konfiguriert haben.
- Öffnen Sie die Branch-Übersicht und klicken Sie auf die Registerkarte „Change Data Feed“.
- Klicken Sie auf "Deaktivieren". Überprüfen Sie im Bestätigungsdialog die Warnung, dass keine Änderungen mehr in Delta-Tabellen übernommen werden, und klicken Sie dann zur Bestätigung erneut auf Deaktivieren.
Durch deaktivieren des CDF wird die Berechnung nicht neu gestartet.
Warning
Wenn Sie CDF später erneut aktivieren, führt das System keine vollständige erneute Momentaufnahme durch. Alle Änderungen, die während der Deaktivierung des CDF aufgetreten sind, fehlen dauerhaft in den Delta-Zieltabellen.
Einschränkungen und Problembehandlung
Sie können den Status jeder Tabelle (Snapshot-Erstellung, übersprungen oder Streaming) auf der Registerkarte Change Data Feed anzeigen oder indem Sie Folgendes in Lakebase ausführen:
SELECT * FROM wal2delta.tables;
Häufige Gründe, warum eine Tabelle nicht im Feed angezeigt wird:
-
REPLICA IDENTITY FULLnicht festgelegt: Führen SieALTER TABLE <table_name> REPLICA IDENTITY FULL;für die Tabelle aus. Siehe Schritt 1: Festlegen der Replikatidentität vollständig. - Partitionierte Tabellen: Partitionierte Lakebase-Tabellen werden nicht unterstützt. Ein Schema, das partitionierte Tabellen enthält, führt dazu, dass diese Tabellen fehlschlagen.
- Leere Tabellen: Eine Tabelle mit null Zeilen wird übersprungen, bis mindestens eine Zeile vorhanden ist.
Nächste Schritte
- Erstellen Sie inkrementelle ETL mit Spark Declarative Pipelines. Siehe Lernprogramm: Erstellen einer ETL-Pipeline mithilfe der Änderungsdatenerfassung für eine vollständige exemplarische Vorgehensweise.
- Den Bronze-Layer abfragen mit Databricks SQL. Siehe Erste Schritte mit dem Data Warehousing mit Databricks SQL.
- Prüfverlauf mit Zeitreiseabfragen für die Ziel-Delta-Tabellen.