Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Wichtig
- Öffentliche Vorschaureleases von Azure KI Language bieten frühzeitigen Zugriff auf Features, die sich in der aktiven Entwicklung befinden.
- Features, Ansätze und Prozesse können sich auf der Grundlage von Benutzerfeedback ändern, bevor die allgemeine Verfügbarkeit (GA) erreicht wird.
Azure KI Language ist ein cloudbasierter Dienst, der Features zur linguistischen Datenverarbeitung (Natural Language Processing, NLP) auf textbasierte Daten anwendet. Die Dokumentzusammenfassung verwendet linguistische Datenverarbeitung, um extraktive (Extraktion wichtiger Sätze) oder abstrahierende (kontextbezogene Wortextraktion) Zusammenfassungen für Dokumente zu generieren. Sowohl AbstractiveSummarization- als auch ExtractiveSummarization-APIs unterstützen die Verarbeitung nativer Dokumente. Ein natives Dokument bezieht sich auf das Dateiformat, das zur Erstellung des Originaldokuments verwendet wurde, z. B. Microsoft Word (docx) oder eine portierbare Dokumentdatei (pdf). Durch die Unterstützung nativer Dokumente ist vor der Verwendung von Azure KI Language-Ressourcen keine Textvorverarbeitung mehr erforderlich. Mit der Funktion zur Unterstützung nativer Dokumente können Sie API-Anforderungen asynchron senden, indem Sie einen HTTP POST-Anforderungstext verwenden, um Ihre Daten und die HTTP GET-Anforderungsabfragezeichenfolge zum Abrufen der Statusergebnisse zu senden. Ihre verarbeiteten Dokumente befinden sich in Ihrem Azure Blob Storage-Zielcontainer.
Unterstützte Dokumentformate
Anwendungen verwenden native Dateiformate, um native Dokumente zu erstellen, zu speichern oder zu öffnen. Derzeit unterstützen Funktionen für personenbezogene Informationen und Dokumentzusammenfassung die folgenden nativen Dokumentformate:
| Dateityp | Dateierweiterung | BESCHREIBUNG |
|---|---|---|
| Text | .txt |
Ein unformatiertes Textdokument. |
| Adobe PDF | .pdf |
Ein als portierbare Dokumentdatei formatiertes Dokument |
| Microsoft Word | .docx |
Eine Microsoft Word-Dokumentdatei |
Eingaberichtlinien
Unterstützte Dateiformate
| Typ | Unterstützung und Einschränkungen |
|---|---|
| PDF-Dateien | Vollständig gescannte PDF-Dateien werden nicht unterstützt. |
| Text in Bildern | Digitale Bilder mit eingebetteten Text werden nicht unterstützt. |
| Digitale Tabellen | Tabellen in gescannten Dokumenten werden nicht unterstützt. |
Dokumentgröße
| Attribut | Eingabebegrenzung |
|---|---|
| Gesamtanzahl von Dokumenten pro Anforderung | ≤ 20 |
| Gesamtgröße des Inhalts pro Anforderung | ≤ 10 MB |
Einschließen nativer Dokumente in eine HTTP-Anforderung
Fangen wir an:
Für dieses Projekt verwenden wir das Befehlszeilentool cURL, um REST-API-Aufrufe auszuführen.
Hinweis
Das cURL-Paket ist in den meisten Windows 10- und Windows 11-Versionen sowie den meisten macOS- und Linux-Distributionen vorinstalliert. Sie können die Paketversion mithilfe der folgenden Befehle überprüfen: Windows:
curl.exe -V, macOS:curl -V, Linux:curl --versionWenn cURL nicht installiert ist, finden Sie hier Installationslinks für Ihre Plattform:
Ein aktives Azure-Konto. Falls Sie noch kein Konto haben, können Sie ein kostenloses Konto erstellen.
Ein Azure Blob Storage-Konto. Für Ihre Quell- und Zieldateien müssen Sie in Ihrem Azure Blob Storage-Konto auch Container erstellen:
- Quellcontainer: In diesen Container laden Sie Ihre nativen Dateien für die Analyse hoch (erforderlich).
- Zielcontainer: In diesem Container werden Ihre analysierten Dateien gespeichert (erforderlich).
Eine Ressource mit einer einzigen Dienstsprache (keine Azure AI Foundry-Ressource mit mehreren Diensten):
Füllen Sie die Felder für das Sprachressourcenprojekt und die Instanzdetails wie folgt aus:
Abonnement: Wählen Sie eines Ihrer verfügbaren Azure-Abonnements aus.
Ressourcengruppe. Sie können eine neue Ressourcengruppe erstellen oder Ihre Ressource zu einer bereits vorhandenen Ressourcengruppe hinzufügen, die denselben Lebenszyklus, dieselben Berechtigungen und dieselben Richtlinien aufweist.
Ressourcenregion: Wählen Sie die Option Global aus, es sei denn, Ihr Unternehmen oder Ihre Anwendung erfordert eine spezifische Region. Wenn Sie planen, eine systemseitig zugewiesene verwaltete Identität für die Authentifizierung zu verwenden, wählen Sie eine geografische Region wie USA, Westen aus.
Name: Geben Sie den Namen ein, den Sie für Ihre Ressource ausgewählt haben. Der ausgewählte Name muss innerhalb von Azure eindeutig sein.
Preisstufe: Sie können den kostenlosen Tarif (
Free F0) verwenden, um den Dienst zu testen, und später für die Produktion auf einen kostenpflichtigen Tarif upgraden.Wählen Sie Überprüfen + Erstellen aus.
Lesen Sie die Nutzungsbedingungen, und klicken Sie auf Erstellen, um Ihre Ressource bereitzustellen.
Nachdem die Ressource erfolgreich bereitgestellt wurde, wählen Sie Zu Ressource wechseln aus.
Rufen Sie Ihren Schlüssel und Ihren Sprachdienstendpunkt ab
Für Anforderungen an den Sprachdienst benötigen Sie einen schreibgeschützten Schlüssel und einen benutzerdefinierten Endpunkt zur Authentifizierung des Zugriffs.
Wählen Sie Zu Ressource wechseln aus, nachdem eine von Ihnen erstellte neue Ressource bereitgestellt wurde. Navigieren Sie direkt zu Ihrer Ressourcenseite, falls Sie über eine bestehende Sprachdienstressource verfügen.
Klicken Sie in der linken Schiene unter Ressourcenverwaltung auf Schlüssel und Endpunkt.
Sie können
keyundlanguage service instance endpointkopieren und in die Codebeispiele einfügen, um Ihre Anforderung an den Sprachdienst zu authentifizieren. Für einen API-Aufruf ist nur ein Schlüssel erforderlich.
Erstellen von Azure Blob Storage-Containern
Erstellen Sie Container in Ihrem Azure Blob Storage-Konto für Quell- und Zieldateien.
- Quellcontainer: In diesen Container laden Sie Ihre nativen Dateien für die Analyse hoch (erforderlich).
- Zielcontainer: In diesem Container werden Ihre analysierten Dateien gespeichert (erforderlich).
Authentifizierung
Ihrer Sprachressource muss Zugriff auf Ihr Speicherkonto gewährt werden, damit Blobs erstellt, gelesen oder gelöscht werden können. Es gibt zwei primäre Methoden, mit denen Sie Zugriff auf Ihre Speicherdaten gewähren können:
SAS-Token (Shared Access Signature). SAS-Token für die Benutzerdelegierung werden mit Microsoft Entra-Anmeldeinformationen geschützt. SAS-Token ermöglichen den sicheren, delegierten Zugriff auf Ressourcen in Ihrem Azure-Speicherkonto.
Rollenbasierte Zugriffssteuerung (Role-Based Access Control, RBAC) mit verwalteter Identität. Verwaltete Identitäten für Azure-Ressourcen sind Dienstprinzipale, die eine Microsoft Entra-Identität und bestimmte Berechtigungen für verwaltete Azure-Ressourcen erstellen.
Für dieses Projekt authentifizieren wir den Zugriff auf die source location- und target location-URLs mit SAS-Token (Shared Access Signature), die als Abfragezeichenfolgen angefügt werden. Jedem Token wird ein bestimmtes Blob (Datei) zugewiesen.

- Ihr Quellcontainer oder Blob muss über Zugriff vom Typ Lesen und Auflisten verfügen.
- Ihr Zielcontainer oder Blob muss über Zugriff vom Typ Schreiben und Auflisten verfügen.
Die API für die extraktive Zusammenfassung verwendet Verarbeitungstechniken für natürliche Sprache, um Kernsätze in einem unstrukturierten Textdokument zu finden. Diese Sätze vermitteln zusammen die Hauptidee des Dokuments.
Die Extraktive Zusammenfassung gibt einen Rangwert als Teil der Antwort des Systems zusammen mit extrahierten Sätzen und ihrer Position in den ursprünglichen Dokumenten zurück. Eine Rangfolge gibt an, als wie relevant für die Hauptidee eines Dokuments ein Satz eingestuft wird. Das Modell gibt für jeden Satz eine Bewertung zwischen 0 und 1 (einschließlich) an und gibt pro Anforderung die Sätze mit der höchsten Bewertung zurück. Wenn Sie beispielsweise eine Zusammenfassung mit drei Sätzen anfordern, gibt der Dienst die drei am höchsten bewerteten Sätze zurück.
Ein weiteres Feature in Azure KI Language, die Extraktion von Schlüsselbegriffen, kann Schlüsselinformationen extrahieren. Um zwischen schlüsselausdrückender Extraktion und extraktiver Zusammenfassung zu entscheiden, sind hier hilfreiche Überlegungen:
- Die Schlüsselbegriffsextraktion gibt Ausdrücke zurück, während die extraktive Zusammenfassung Sätze zurückgibt.
- Die extraktive Zusammenfassung gibt Sätze zusammen mit einer Rangfolge zurück, und Sätze mit dem höchsten Rang werden pro Anforderung zurückgegeben.
- Die extraktive Zusammenfassung gibt auch die folgenden Positionsinformationen zurück:
- Offset: Die Anfangsposition jedes extrahierten Satzes.
- Länge: Die Länge jedes extrahierten Satzes.
Festlegen der Art der Datenverarbeitung (optional)
Übermitteln der Daten
Sie übermitteln Dokumente als Textzeichenfolgen an die API. Die Analyse wird bei Eingang der Anfrage durchgeführt. Da es sich um eine asynchrone API handelt, kann es zu einer Verzögerung zwischen dem Senden einer API-Anforderung und dem Erhalt der Ergebnisse kommen.
Wenn Sie dieses Feature verwenden, sind die API-Ergebnisse ab der Erfassung der Anforderung wie in der Antwort angegeben 24 Stunden lang verfügbar. Nach diesem Zeitraum werden die Ergebnisse endgültig gelöscht und stehen nicht mehr zum Abruf zur Verfügung.
Abrufen von Textzusammenfassungsergebnissen
Wenn Sie Ergebnisse von der Sprachenerkennung erhalten, können Sie die Ergebnisse an eine Anwendung streamen oder die Ausgabe in einer Datei im lokalen System speichern.
Hier ist ein Beispiel für Inhalte, die Sie zur Zusammenfassung übermitteln können, die mithilfe des Microsoft-Blogartikels Eine ganzheitliche Darstellung integrativer KI-extrahiert wird. Dieser Artikel ist nur ein Beispiel. Die API kann längeren Eingabetext akzeptieren. Weitere Informationen finden Sie unter Daten- und Diensteinschränkungen.
„Bei Microsoft verfolgen wir das Ziel, KI über den aktuellen Stand der Technik hinaus zu verbessern. Dabei wählen wir einen ganzheitlicheren, benutzerzentrierten Ansatz für das Lernen und Verstehen.“ Als Chief Technology Officer von Azure KI Services habe ich mit einem Team von erstaunlichen Wissenschaftlern und Ingenieuren zusammengearbeitet, um dieses Vorhaben in die Tat umzusetzen. „In meiner Rolle sehe ich die Beziehung der drei Attribute der menschlichen Wahrnehmung aus einer ganz besonderen Perspektive: einsprachiger Text (X), Audiosignale oder visuelle Signale (Y) und mehrsprachiger Text (Z).“ An der Schnittstelle aller drei Attribute entsteht Magie—was wir als XYZ-Code bezeichnen, wie in Abbildung 1 dargestellt—eine gemeinsame Darstellung zur Schaffung einer leistungsfähigeren KI, die besser sprechen, hören, sehen und Menschen verstehen kann. Wir sind der Meinung, dass XYZ-Code uns die Möglichkeit gibt, unsere langfristige Vision zu realisieren: domänenübergreifender Lerntransfer über Modalitäten und Sprachgrenzen hinweg. Das Ziel besteht in der Verfügbarkeit vortrainierter Modelle, die gemeinsam Darstellungen erlernen können, um eine Vielzahl von nachgelagerten KI-Aufgaben zu unterstützen, ganz ähnlich wie Menschen es heute tun. Im Lauf der letzten fünf Jahre haben wir bei Benchmarks für Spracherkennung in Unterhaltungen, maschinelle Übersetzung, Beantwortung von Fragen im Unterhaltungskontext, maschinelles Leseverständnis und Bildbeschriftung ein menschliches Leistungsniveau erzielt. Diese fünf Durchbrüche waren für uns ein starkes Signal im Hinblick auf unser ehrgeizigeres Ziel, einen Sprung in den KI-Fähigkeiten zu erreichen, indem wir zu einem multisensorischen und mehrsprachigen Lernen gelangen, das dem menschlichen Lernen und Verstehen ähnlicher ist. Meiner Meinung nach ist der gemeinsame XYZ-Code eine grundlegende Komponente dieser Bestrebung, wenn er mit externen Wissensquellen in den nachgelagerten KI-Aufgaben verankert ist.
Die Anforderung der Textzusammenfassung-API wird nach Erhalt der Anforderung verarbeitet, indem ein Auftrag für das API Back-End erstellt wird. Wenn der Auftrag erfolgreich war, wird das Ergebnis der API geliefert. Die Ausgabe kann 24 Stunden lang abgerufen werden. Anschließend wird die Ausgabe gelöscht. Aufgrund der Unterstützung von Emojis und mehreren Sprachen enthält der Antworttext unter Umständen Textverschiebungen. Weitere Informationen finden Sie unter Verarbeiten von Versätzen.
Wenn Sie das vorangehende Beispiel verwenden, gibt die API möglicherweise die folgenden zusammengefassten Sätze zurück:
Extraktive Zusammenfassung:
- „Bei Microsoft verfolgen wir das Ziel, KI über den aktuellen Stand der Technik hinaus zu verbessern. Dabei wählen wir einen ganzheitlicheren, benutzerzentrierten Ansatz für das Lernen und Verstehen.“
- „Wir sind der Meinung, dass XYZ-Code uns die Möglichkeit gibt, unsere langfristige Vision zu realisieren: domänenübergreifender Lerntransfer über Modalitäten und Sprachgrenzen hinweg.“
- „Das Ziel besteht in der Verfügbarkeit vortrainierter Modelle, die gemeinsam Darstellungen erlernen können, um eine Vielzahl von nachgelagerten KI-Aufgaben zu unterstützen, ganz ähnlich wie Menschen es heute tun.“
Abstrakte Zusammenfassung:
- „Microsoft verfolgt einen ganzheitlicheren, auf den Menschen ausgerichteten Ansatz für das Lernen und Verstehen. Wir sind der Meinung, dass XYZ-Code uns die Möglichkeit gibt, unsere langfristige Vision zu realisieren: domänenübergreifender Lerntransfer über Modalitäten und Sprachgrenzen hinweg. In den letzten fünf Jahren haben wir menschliche Leistung auf Benchmarks erreicht.“
Testen Sie die extraktive Textzusammenfassung
Sie können die extraktive Textzusammenfassung verwenden, um Zusammenfassungen von Artikeln, Paper oder Dokumenten zu erhalten. Ein Beispiel dazu finden Sie im Schnellstartartikel.
Verwenden Sie den Parameter sentenceCount, um anzugeben, wie viele Sätze zurückgegeben wurden, wobei 3 der Standardwert ist. Der Bereich liegt zwischen 1 und 20.
Sie können auch mit dem Parameter sortby angeben, in welcher Reihenfolge die extrahierten Sätze zurückgegeben werden sollen. Dabei sind die Optionen Offset oder Rank verfügbar, wobei Offset der Standardwert ist.
| Parameterwert | BESCHREIBUNG |
|---|---|
| Rang | Sätze werden gemäß ihrer Relevanz im Eingabedokument vom Dienst sortiert. |
| Offset | Die ursprüngliche Reihenfolge der Sätze im Eingabedokument wird beibehalten. |
Testen Sie die abstrakte Textzusammenfassung
Das folgende Beispiel verhilft Ihnen zu einem Einstieg in die abstrakte Textzusammenfassung:
- Kopieren Sie den folgenden Befehl, und fügen Sie ihn in einen Text-Editor ein. Im BASH-Beispiel wird das Zeilenfortsetzungszeichen
\verwendet. Wenn Ihre Konsole oder Ihr Terminal ein anderes Zeilenfortsetzungszeichen nutzt, verwenden Sie stattdessen dieses Zeichen.
curl -i -X POST https://<your-language-resource-endpoint>/language/analyze-text/jobs?api-version=2023-04-01 \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>" \
-d \
'
{
"displayName": "Text Abstractive Summarization Task Example",
"analysisInput": {
"documents": [
{
"id": "1",
"language": "en",
"text": "At Microsoft, we have been on a quest to advance AI beyond existing techniques, by taking a more holistic, human-centric approach to learning and understanding. As Chief Technology Officer of Azure AI services, I have been working with a team of amazing scientists and engineers to turn this quest into a reality. In my role, I enjoy a unique perspective in viewing the relationship among three attributes of human cognition: monolingual text (X), audio or visual sensory signals, (Y) and multilingual (Z). At the intersection of all three, there's magic—what we call XYZ-code as illustrated in Figure 1—a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We believe XYZ-code enables us to fulfill our long-term vision: cross-domain transfer learning, spanning modalities and languages. The goal is to have pretrained models that can jointly learn representations to support a broad range of downstream AI tasks, much in the way humans do today. Over the past five years, we have achieved human performance on benchmarks in conversational speech recognition, machine translation, conversational question answering, machine reading comprehension, and image captioning. These five breakthroughs provided us with strong signals toward our more ambitious aspiration to produce a leap in AI capabilities, achieving multi-sensory and multilingual learning that is closer in line with how humans learn and understand. I believe the joint XYZ-code is a foundational component of this aspiration, if grounded with external knowledge sources in the downstream AI tasks."
}
]
},
"tasks": [
{
"kind": "AbstractiveSummarization",
"taskName": "Text Abstractive Summarization Task 1",
}
]
}
'
Nehmen Sie die folgenden Änderungen im Befehl vor, falls dies erforderlich ist:
- Ersetzen Sie den Wert
your-language-resource-keydurch Ihren Schlüssel. - Ersetzen Sie den ersten Teil der Anforderungs-URL
your-language-resource-endpointdurch Ihre Endpunkt-URL.
- Ersetzen Sie den Wert
Öffnen Sie ein Eingabeaufforderungsfenster (z. B. BASH).
Fügen Sie den Befehl aus dem Text-Editor in das Eingabeaufforderungsfenster ein, und führen Sie den Befehl dann aus.
Rufen Sie
operation-locationaus dem Antwortheader ab. Der Wert ähnelt der folgenden URL:
https://<your-language-resource-endpoint>/language/analyze-text/jobs/12345678-1234-1234-1234-12345678?api-version=2022-10-01-preview
- Verwenden Sie den folgenden cURL-Befehl, um die Ergebnisse der Anforderung abzurufen. Ersetzen Sie
<my-job-id>durch den numerischen ID-Wert, den Sie aus dem vorherigenoperation-location-Antwortheader erhalten haben:
curl -X GET https://<your-language-resource-endpoint>/language/analyze-text/jobs/<my-job-id>?api-version=2022-10-01-preview \
-H "Content-Type: application/json" \
-H "Ocp-Apim-Subscription-Key: <your-language-resource-key>"
Beispiel-JSON-Antwort für abstraktive Textzusammenfassung
{
"jobId": "cd6418fe-db86-4350-aec1-f0d7c91442a6",
"lastUpdateDateTime": "2022-09-08T16:45:14Z",
"createdDateTime": "2022-09-08T16:44:53Z",
"expirationDateTime": "2022-09-09T16:44:53Z",
"status": "succeeded",
"errors": [],
"displayName": "Text Abstractive Summarization Task Example",
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "AbstractiveSummarizationLROResults",
"taskName": "Text Abstractive Summarization Task 1",
"lastUpdateDateTime": "2022-09-08T16:45:14.0717206Z",
"status": "succeeded",
"results": {
"documents": [
{
"summaries": [
{
"text": "Microsoft is taking a more holistic, human-centric approach to AI. We've developed a joint representation to create more powerful AI that can speak, hear, see, and understand humans better. We've achieved human performance on benchmarks in conversational speech recognition, machine translation, ...... and image captions.",
"contexts": [
{
"offset": 0,
"length": 247
}
]
}
],
"id": "1"
}
],
"errors": [],
"modelVersion": "latest"
}
}
]
}
}
| Parameter | BESCHREIBUNG |
|---|---|
-X POST <endpoint> |
Gibt Ihren Sprachressourcenendpunkt für den Zugriff auf die API an. |
--header Content-Type: application/json |
Der Inhaltstyp zum Senden von JSON-Daten |
--header "Ocp-Apim-Subscription-Key:<key> |
Gibt den Sprachressourcenschlüssel für den Zugriff auf die API an |
-data |
Die JSON-Datei mit den Daten, die Sie mit Ihrer Anforderung übergeben möchten. |
Die folgenden cURL-Befehle werden über eine Bash-Shell ausgeführt. Fügen Sie in diese Befehle Ihren Ressourcennamen und Ressourcenschlüssel sowie Ihre JSON-Werte ein. Versuchen Sie, native Dokumente zu analysieren, indem Sie das Codebeispielprojekt Personally Identifiable Information (PII) oder Document Summarization auswählen:
Beispieldokument für Zusammenfassung
Für dieses Projekt benötigen Sie ein Quelldokument, das in Ihren Quellcontainer hochgeladen wurde. Sie können unser Microsoft Word-Beispieldokument oder Adobe PDF für diesen Schnellstart herunterladen. Die Quellsprache ist Englisch.
Erstellen der POST-Anforderung
Erstellen Sie mit Ihrem bevorzugten Editor oder Ihrer bevorzugten IDE ein neues Verzeichnis namens
native-documentfür Ihre App.Erstellen Sie in Ihrem Verzeichnis namens native-document eine neue JSON-Datei namens document-summarization.json.
Kopieren Sie das Anforderungsbeispiel für die Dokumentzusammenfassung, und fügen Sie es in Ihre Datei
document-summarization.jsonein. Ersetzen Sie{your-source-container-SAS-URL}und{your-target-container-SAS-URL}durch die Werte Ihrer Speicherkontocontainer-Instanz aus dem Azure-Portal:
Anforderungsbeispiel
{
"tasks": [
{
"kind": "ExtractiveSummarization",
"parameters": {
"sentenceCount": 6
}
}
],
"analysisInput": {
"documents": [
{
"source": {
"location": "{your-source-blob-SAS-URL}"
},
"targets": {
"location": "{your-target-container-SAS-URL}"
}
}
]
}
}
Ausführen der POST-Anforderung
Ersetzen Sie vor dem Ausführen der POST-Anforderung {your-language-resource-endpoint} und {your-key} durch den Endpunktwert Ihrer Sprachressourceninstanz im Azure-Portal.
Wichtig
Denken Sie daran, den Schlüssel aus Ihrem Code zu entfernen, wenn Sie fertig sind, und ihn niemals zu veröffentlichen. Verwenden Sie für die Produktion eine sichere Art der Speicherung und des Zugriffs auf Ihre Anmeldeinformationen wie Azure Key Vault. Weitere Informationen finden Sie unter Azure KI Services-Sicherheit.
PowerShell
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" -i -X POST --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
Eingabeaufforderung/Terminal
curl -v -X POST "{your-language-resource-endpoint}/language/analyze-documents/jobs?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}" --data "@document-summarization.json"
Beispielantwort:
HTTP/1.1 202 Accepted
Content-Length: 0
operation-location: https://{your-language-resource-endpoint}/language/analyze-documents/jobs/f1cc29ff-9738-42ea-afa5-98d2d3cabf94?api-version=2024-11-15-preview
apim-request-id: e7d6fa0c-0efd-416a-8b1e-1cd9287f5f81
x-ms-region: West US 2
Date: Thu, 25 Jan 2024 15:12:32 GMT
POST-Antwort (jobId)
Sie erhalten eine Antwort vom Typ 202 (Erfolg), die einen schreibgeschützten Operation-Location-Header enthält. Der Wert dieses Headers enthält eine jobId, die abgefragt werden kann, um den Status des asynchronen Vorgangs und die Ergebnisse mithilfe einer GET-Anforderung abzurufen:
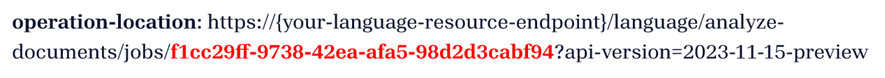
Abrufen von Analyseergebnissen (GET-Anforderung)
Nach der erfolgreichen POST-Anforderung können Sie den in der POST-Anforderung zurückgegebenen Operation-Location-Header abfragen, um die verarbeiteten Daten anzuzeigen.
Dies ist die Struktur der GET-Anforderung:
GET {cognitive-service-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-previewNehmen Sie die folgenden Änderungen vor, bevor Sie den Befehl ausführen:
Ersetzen Sie {jobId} durch den Operation-Location-Header aus der POST-Antwort.
Ersetzen Sie {your-language-resource-endpoint} und {your-key} durch die Werte aus Ihrer Sprachdienstinstanz im Azure-Portal.
Get-Anforderung
cmd /c curl "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" -i -X GET --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
curl -v -X GET "{your-language-resource-endpoint}/language/analyze-documents/jobs/{jobId}?api-version=2024-11-15-preview" --header "Content-Type: application/json" --header "Ocp-Apim-Subscription-Key: {your-key}"
Antwort untersuchen
Sie erhalten die Antwort vom Typ 200 (Erfolg) mit einer JSON-Ausgabe. Das erste Feld Status gibt das Ergebnis des Vorgangs an. Wenn der Vorgang nicht abgeschlossen ist, ist der Wert von Status entweder „running“ oder „notStarted“, und Sie müssen die API entweder manuell oder über ein Skript erneut aufrufen. Ein Intervall von mindestens einer Sekunde zwischen den Aufrufen wird empfohlen.
Beispielantwort
{
"jobId": "f1cc29ff-9738-42ea-afa5-98d2d3cabf94",
"lastUpdatedDateTime": "2024-01-24T13:17:58Z",
"createdDateTime": "2024-01-24T13:17:47Z",
"expirationDateTime": "2024-01-25T13:17:47Z",
"status": "succeeded",
"errors": [],
"tasks": {
"completed": 1,
"failed": 0,
"inProgress": 0,
"total": 1,
"items": [
{
"kind": "ExtractiveSummarizationLROResults",
"lastUpdateDateTime": "2024-01-24T13:17:58.33934Z",
"status": "succeeded",
"results": {
"documents": [
{
"id": "doc_0",
"source": {
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-input/input.pdf"
},
"targets": [
{
"kind": "AzureBlob",
"location": "https://myaccount.blob.core.windows.net/sample-output/df6611a3-fe74-44f8-b8d4-58ac7491cb13/ExtractiveSummarization-0001/input.result.json"
}
],
"warnings": []
}
],
"errors": [],
"modelVersion": "2023-02-01-preview"
}
}
]
}
}
Nach erfolgreichem Abschluss:
- Die analysierten Dokumente befinden sich in Ihrem Zielcontainer.
- Bei erfolgreicher Ausführung gibt die POST-Methode den Antwortcode
202 Acceptedzurück, der anzeigt, dass die Batch-Anforderung vom Dienst erstellt wurde. - Die POST-Anfrage hat auch Antwortheader zurückgegeben, unter anderem
Operation-Location. Dieser Header stellt einen Wert bereit, der in nachfolgenden GET-Anforderungen verwendet wird.
Bereinigen von Ressourcen
Wenn Sie ein Azure KI Services-Abonnement bereinigen und entfernen möchten, können Sie die Ressource oder die Ressourcengruppe löschen. Wenn Sie die Ressourcengruppe löschen, werden auch alle anderen Ressourcen gelöscht, die ihr zugeordnet sind.