Hinzufügen der Zustimmung zu VoIP-Talenten zum professionellen VoIP-Projekt
Ein Sprecher ist eine Einzelperson oder Zielsprecher, dessen Stimmen aufgezeichnet und verwendet werden, um neuronale Stimmmodelle zu erstellen.
Bevor Sie eine neuronale Stimme trainieren können, müssen Sie eine Aufzeichnung der Einwilligungserklärung des/der Sprecher*in einreichen. Die Erklärung des/der Sprecher*in ist eine Aufzeichnung des/der Sprecher*in beim Verlesen einer Erklärung, dass er/sie der Verwendung seiner/ihrer Sprachdaten zum Trainieren eines benutzerdefinierten Stimmmodells zustimmt. Die Einwilligungserklärung wird außerdem verwendet, um zu überprüfen, ob es sich bei dem Sprecher um dieselbe Person wie dem Sprecher der Trainingsdaten handelt.
Tipp
Bevor Sie in Speech Studio beginnen, definieren Sie Ihre Stimm-Persona, und wählen Sie den richtigen Sprecher aus.
Sie finden diese Erklärung zur mündlichen Zustimmung in mehreren Sprachen auf GitHub. Die Sprache der verbalen Anweisung muss mit Ihrer Aufzeichnung identisch sein. Siehe auch die Offenlegung für Sprecher.
Sprecher*in hinzufügen
Führen Sie die folgenden Schritte aus, um ein Sprecherprofil hinzuzufügen und die Zustimmungserklärung des Sprechers/der Sprecherin hochzuladen:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Custom Voice> Ihr Projektname >Sprecher einrichten>Sprecher hinzufügen aus.
- Beschreiben Sie im Assistenten zum Hinzufügen neuer Sprecher die Merkmale der Stimme, die Sie erstellen möchten. Die Szenarien, die Sie hier angeben, müssen mit Ihren Angaben im Antragsformular übereinstimmen.
- Klicken Sie auf Weiter.
- Wechseln Sie zu Seite Sprechererklärung hochladen, und befolgen Sie die Anweisungen zum Hochladen der Sprechererklärung, die Sie zuvor aufgezeichnet haben. Vergewissern Sie sich, dass die mündliche Erklärung mit den gleichen Einstellungen, in der gleichen Umgebung und im gleichen Sprechstil wie Ihre Trainingsdaten aufgezeichnet wurde.
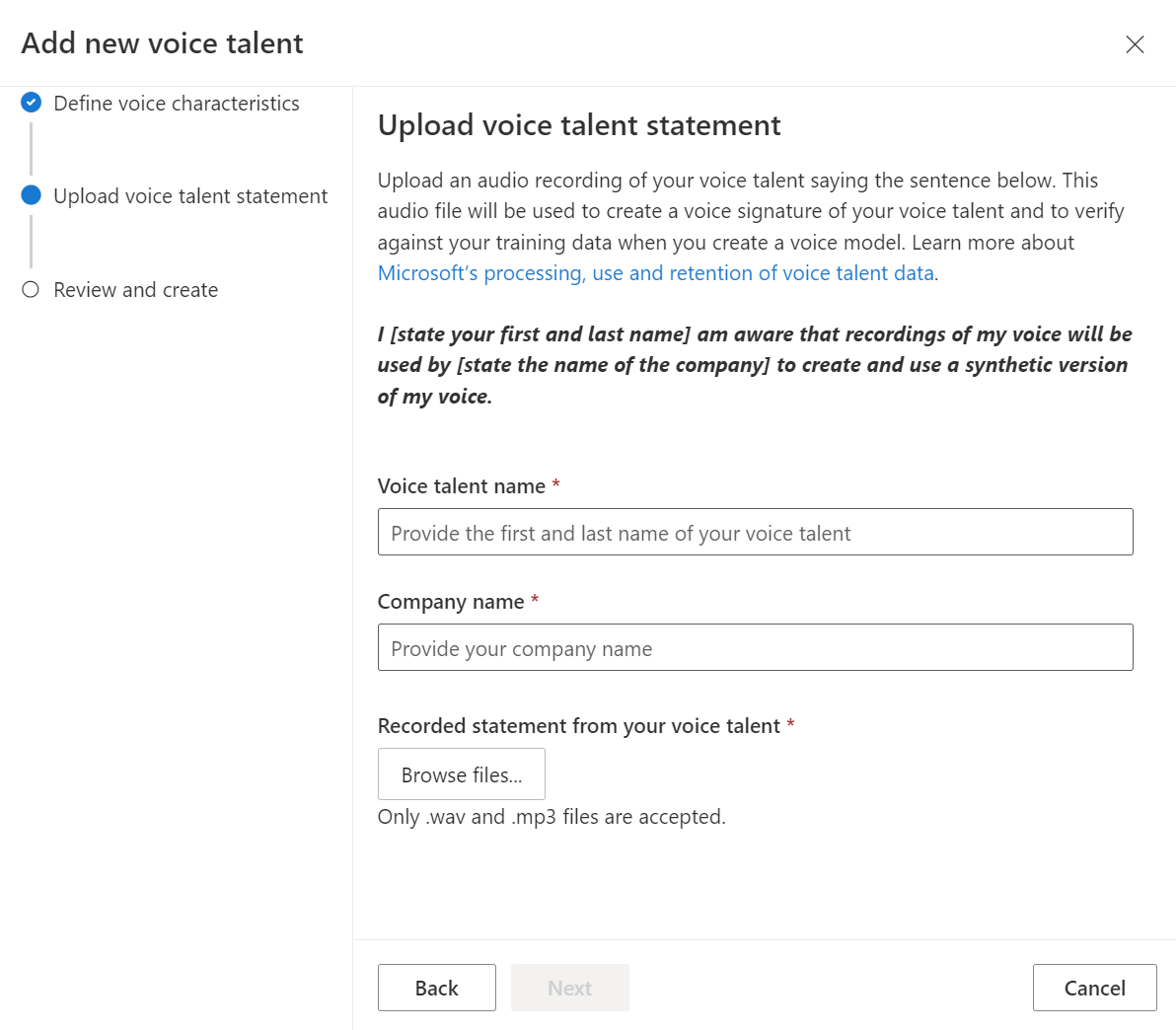
- Geben Sie den Namen des Sprechers und den Firmennamen ein. Der Name des Sprechers muss der Name der Person sein, die die Zustimmungserklärung aufgezeichnet hat. Geben Sie den Namen in derselben Sprache ein, die in der aufgezeichneten Anweisung verwendet wird. Der Firmenname muss mit dem Firmennamen übereinstimmen, der in der aufgezeichneten Erklärung gesprochen wurde. Stellen Sie sicher, dass der Firmenname in derselben Sprache wie die aufgezeichnete Anweisung eingegeben wird.
- Wählen Sie Weiter aus.
- Überprüfen Sie die Details zu Sprecher und Persona, und wählen Sie Übermitteln aus.
Nachdem der Status des Sprechers auf Erfolgreich festgelegt wurde, können Sie mit dem Training Ihres benutzerdefinierten Sprachmodells fortfahren.
Nächste Schritte
Mit der professionellen Sprachfunktion ist es erforderlich, dass jede Stimme mit expliziter Zustimmung des Benutzers erstellt wird. Es ist eine aufgezeichnete Erklärung des Benutzers erforderlich, in der er bestätigt, dass der Kunde (Eigentümer der Azure KI Speech-Ressource) seine Stimme erstellen und verwenden wird.
Um die Zustimmung des Sprechers bzw. der Sprecherin zum Projekt „Professionelle Stimme“ hinzuzufügen, rufen Sie die voraufgezeichnete Zustimmungsaudiodatei über eine öffentlich zugängliche URL (Consents_Create) ab, oder laden Sie die Audiodatei hoch (Consents_Post). In diesem Artikel fügen Sie eine Zustimmung aus einer URL hinzu.
Zustimmungserklärung
Sie benötigen eine Audioaufzeichnung des Benutzers, der die Zustimmungserklärung spricht.
Sie können den Text der Zustimmungserklärung für jedes Gebietsschema aus dem Text in das GitHub-Repository für Sprachsynthese abrufen. Siehe SpeakerAuthorization.txt für die Zustimmungserklärung für das en-US-Gebietsschema:
"I [state your first and last name] am aware that recordings of my voice will be used by [state the name of the company] to create and use a synthetic version of my voice."
Hinzufügen der Zustimmung aus einer URL
Um die Einwilligung zum Projekt „Professionelle Stimme“ über die URL einer Audiodatei hinzuzufügen, verwenden Sie den Consents_Create-Vorgang der benutzerdefinierten VoIP-API. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die erforderliche
projectId-Eigenschaft fest. Siehe Erstellen eines Projekts. - Legen Sie die erforderliche
voiceTalentName-Eigenschaft fest. Der Name des Sprechers muss der Name der Person sein, die die Zustimmungserklärung aufgezeichnet hat. Geben Sie den Namen in derselben Sprache ein, die in der aufgezeichneten Anweisung verwendet wird. Der Name des Sprachtalents kann später nicht geändert werden. - Legen Sie die erforderliche
companyName-Eigenschaft fest. Der Firmenname muss mit dem Firmennamen übereinstimmen, der in der aufgezeichneten Aussage genannt wird. Stellen Sie sicher, dass der Firmenname in derselben Sprache wie die aufgezeichnete Anweisung eingegeben wird. Der Firmenname kann später nicht geändert werden. - Legen Sie die erforderliche
audioUrl-Eigenschaft fest. Die URL der Audiodatei zur Zustimmung von VoIP-Talenten. Verwenden Sie einen URI mit dem SAS-Token (Shared Access Signatures). - Legen Sie die erforderliche
locale-Eigenschaft fest. Dies sollte das Gebietsschema der Zustimmung sein. Das Gebietsschema können Sie später nicht mehr ändern. Hier finden Sie den Text zur Sprachsynthese-Gebietsliste.
Senden Sie eine HTTP PUT-Anforderung unter Verwendung des URI, wie im folgenden Beispiel Consents_Create gezeigt.
- Ersetzen Sie
YourResourceKeydurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
YourResourceRegiondurch Ihre Speech-Ressourcenregion. - Ersetzen Sie
JessicaConsentIddurch eine Zustimmungs-ID Ihrer Wahl. Die URI der Zustimmung wird bei der Groß-/Kleinschreibung beachtet und kann später nicht geändert werden.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "Consent for Jessica voice",
"projectId": "ProjectId",
"voiceTalentName": "Jessica Smith",
"companyName": "Contoso",
"audioUrl": "https://contoso.blob.core.windows.net/public/jessica-consent.wav?mySasToken",
"locale": "en-US"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/consents/JessicaConsentId?api-version=2024-02-01-preview"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"id": "JessicaConsentId",
"description": "Consent for Jessica voice",
"projectId": "ProjectId",
"voiceTalentName": "Jessica Smith",
"companyName": "Contoso",
"locale": "en-US",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Der Antwortheader enthält die Operation-Location-Eigenschaft. Verwenden Sie diesen URI, um Details zum Consents_Create-Vorgang abzurufen. Hier ist ein Beispiel für die Antwort:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/070f7986-ef17-41d0-ba2b-907f0f28e314?api-version=2024-02-01-preview
Operation-Id: 070f7986-ef17-41d0-ba2b-907f0f28e314