Hinzufügen eines professionellen VoIP-Trainingsdatensatzes
Wenn Sie bereit sind, eine benutzerdefinierte Stimme für die Sprachsynthese zu erstellen, besteht der erste Schritt darin, Audioaufnahmen und zugehörige Skripts für das Training des Stimmmodells zusammenzustellen. Weitere Informationen zum Aufzeichnen von Stimmbeispielen finden Sie im Tutorial. Der Speech-Dienst erstellt anhand dieser Daten eine einzigartige Stimme, die der Stimme in den Aufnahmen entspricht. Nachdem Sie die Stimme trainiert haben, können Sie mit dem Synthetisieren von Sprache in Ihren Anwendungen beginnen.
Alle Daten, die Sie hochladen, müssen die Anforderungen für den ausgewählten Datentyp erfüllen. Es ist wichtig, dass Sie Ihre Daten vor dem Hochladen ordnungsgemäß formatieren. Dadurch wird sichergestellt, dass sie vom Spracherkennungsdienst korrekt verarbeitet werden. Informationen zum korrekten Format Ihrer Daten finden Sie unter Trainingsdatentypen.
Hinweis
- Benutzer mit einem Standardabonnement (S0) können fünf Dateien gleichzeitig hochladen. Wenn Sie das Limit erreichen, warten Sie, bis der Import mindestens einer Datei beendet ist. Versuchen Sie es anschließend noch mal.
- Die maximale Anzahl von Dateien, die pro Abonnement importiert werden können, beträgt 500 ZIP-Dateien für Benutzer des Standardabonnements (S0). Weitere Informationen finden Sie unter Speech-Dienst – Kontingente und Grenzwerte.
Hochladen Ihrer Daten
Wenn Sie bereit sind, Ihre Daten hochzuladen, wechseln Sie zur Registerkarte zum Vorbereiten von Trainingsdaten, um Ihren ersten Trainingssatz hinzuzufügen und Daten hochzuladen. Ein Trainingssatz besteht aus einer Reihe von Audioäußerungen und den ihnen zugeordneten Skripts, die zum Trainieren eines Stimmmodells verwendet werden. Sie können einen Trainingssatz verwenden, um Ihre Trainingsdaten zu organisieren. Jeder Trainingssatz wird vom Dienst auf Datenbereitschaft überprüft. Sie können mehrere Daten in einen Trainingssatz importieren.
Führen Sie die folgenden Schritte aus, um Trainingsdaten hochzuladen:
- Melden Sie sich in Speech Studio an.
- Wählen Sie Custom Voice> Ihr Projektname >Trainingsdaten vorbereiten>Daten hochladen aus.
- Wählen Sie im Assistenten zum Hochladen von Daten einen Datentyp aus, und wählen Sie dann Weiter aus.
- Wählen Sie lokale Dateien von Ihrem Computer aus, oder geben Sie die Azure Blob Storage-URL ein, um Daten hochzuladen.
- Wählen Sie unter Zieltrainingssatz angeben einen vorhandenen Trainingssatz aus, oder erstellen Sie einen neuen. Wenn Sie einen neuen Trainingssatz erstellt haben, vergewissern Sie sich, dass er in der Dropdownliste ausgewählt ist, bevor Sie fortfahren.
- Klicken Sie auf Weiter.
- Geben Sie einen Namen und eine Beschreibung für Ihre Daten ein, und wählen Sie dann Weiter aus.
- Überprüfen Sie die Details zum Upload, und wählen Sie Übermitteln aus.
Hinweis
Doppelte IDs werden nicht akzeptiert. Äußerungen mit derselben ID werden entfernt.
Doppelte Audionamen werden aus dem Training entfernt. Achten Sie darauf, dass die ausgewählten Daten in der ZIP-Datei oder in mehreren ZIP-Dateien nicht die gleichen Audionamen enthalten. Doppelte Äußerungs-IDs (in Audio- oder Skriptdateien) werden abgelehnt.
Durch Klicken auf Senden werden die Dateien automatisch überprüft. Bei der Datenüberprüfung werden Format, Größe und Samplingrate der Audiodateien geprüft. Beheben Sie ggf. auftretende Fehler, und klicken Sie erneut auf „Senden“.
Nachdem die Daten hochgeladen wurden, können Sie die Details in der Detailansicht des Trainingssatzes überprüfen. Auf der Detailseite können Sie die Aussprachebewertungen und den Rauschpegel Ihrer jeweiligen Daten genauer überprüfen. Die Aussprachebewertung auf Satzebene reicht von 0 bis 100. Werte unter 70 deuten in der Regel auf einen Aussprachefehler oder auf einen Fehler bei der Skriptzuordnung hin. Äußerungen mit einer Gesamtbewertung von weniger als 70 werden abgelehnt. Ein starker Akzent kann die Aussprachebewertung verringern und die Qualität der erzeugten digitalen Stimme negativ beeinflussen.
Onlinebehebung von Datenproblemen
Nach dem Hochladen können Sie die Datendetails des Trainingssatzes überprüfen. Bevor Sie damit fortfahren, ihr Stimmmodell zu trainieren, sollten Sie versuchen, alle Datenprobleme zu beheben.
Sie können Datenprobleme für jede Äußerung einzeln in Speech Studio beheben.
Navigieren Sie auf der Detailseite zur Seite Akzeptierte Daten oder Abgelehnte Daten. Wählen Sie einzelne Äußerungen aus, die Sie ändern möchten, und wählen Sie dann Bearbeiten aus.
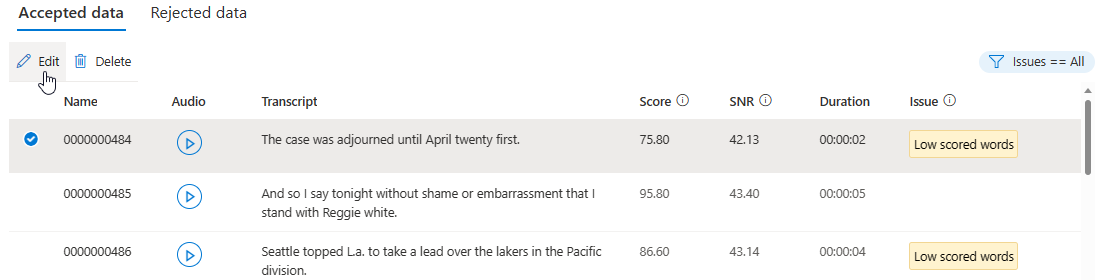
Ausgehend von Ihren Kriterien können Sie auswählen, welche Datenprobleme angezeigt werden sollen.
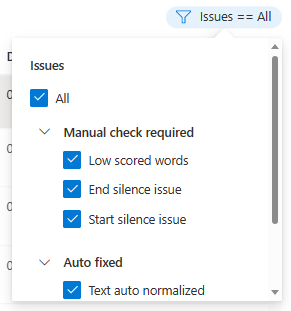
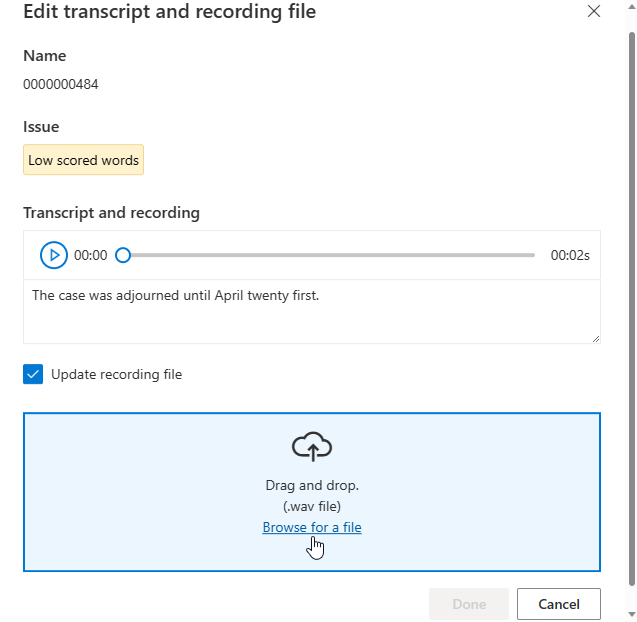
Das Bearbeitungsfenster wird angezeigt.
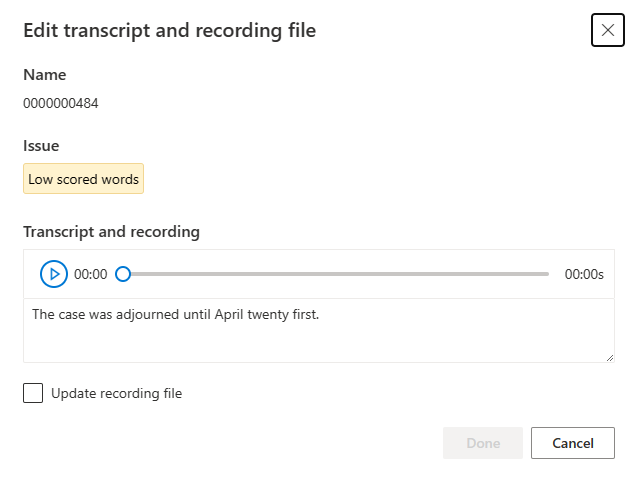
Aktualisieren Sie die Transkript- oder Aufzeichnungsdatei entsprechend der Problembeschreibung im Bearbeitungsfenster.
Sie können das Transkript im Textfeld bearbeiten und dann Fertig auswählen.
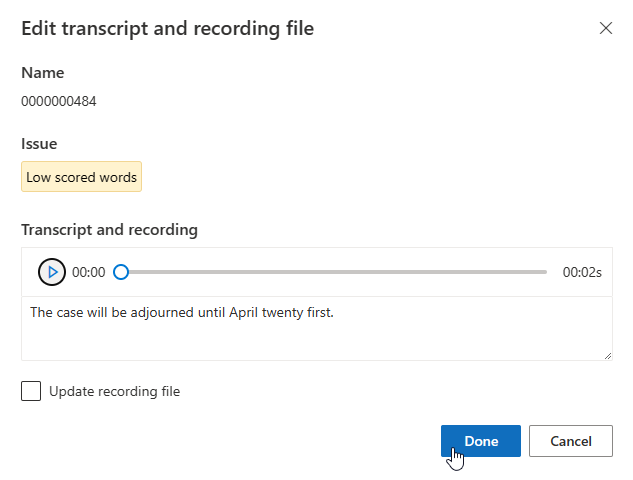
Wenn Sie die Aufzeichnungsdatei aktualisieren müssen, wählen Sie Aufzeichnungsdatei aktualisieren aus, und laden Sie die korrigierte Aufzeichnungsdatei (WAV) hoch.
Nachdem Sie Änderungen an Ihren Daten vorgenommen haben, müssen Sie die Datenqualität überprüfen, indem Sie auf Daten analysieren klicken, bevor Sie dieses Dataset für das Training verwenden.
Sie können diesen Trainingssatz nicht für das Trainingsmodell auswählen, bevor die Analyse abgeschlossen ist.
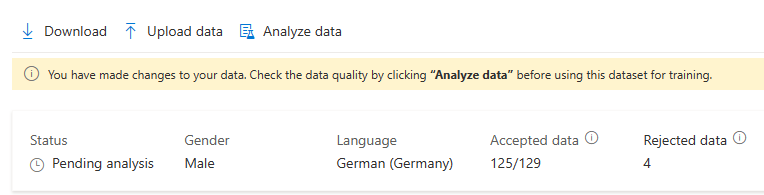
Sie können auch Äußerungen mit Problemen löschen, indem Sie sie auswählen und auf Löschen klicken.
Typische Datenprobleme
Die Probleme sind in drei Typen unterteilt. In den folgenden Tabellen finden Sie Informationen zu den jeweiligen Fehlertypen.
Automatisch abgelehnt
Daten mit diesen Fehlern werden nicht für das Training verwendet. Importierte Daten mit Fehlern werden ignoriert, sodass Sie sie nicht löschen müssen. Sie können diese Datenfehler online beheben oder die korrigierten Daten erneut zum Training hochladen.
| Category | Name | BESCHREIBUNG |
|---|---|---|
| Skript | Ungültiges Trennzeichen | Äußerungs-ID und Skriptinhalt müssen durch ein Tabstoppzeichen getrennt werden. |
| Skript | Ungültige Skript-ID | Die Skriptzeilen-ID muss numerisch sein. |
| Skript | Dupliziertes Skript | Jede Zeile des Skriptinhalts muss eindeutig sein. Die Zeile wird mit {} dupliziert. |
| Skript | Skript zu lang | Das Skript darf 1.000 Zeichen nicht überschreiten. |
| Skript | Keine Audioübereinstimmung | Die ID jeder Äußerung (jeder Zeile der Skriptdatei) muss mit der Audio-ID übereinstimmen. |
| Skript | Kein gültiges Skript | In diesem Dataset wurde kein gültiges Skript gefunden. Korrigieren Sie die Skriptzeilen, die in der detaillierten Problemliste angezeigt werden. |
| Audio | Keine Skriptübereinstimmung | Keine Audiodatei stimmt mit der Skript-ID überein. Der Name der WAV-Dateien muss mit den IDs in der Skriptdatei übereinstimmen. |
| Audio | Ungültiges Audioformat | Das Audioformat der WAV-Dateien ist ungültig. Überprüfen Sie das WAV-Dateiformat mithilfe eines Audiotools wie SoX. |
| Audio | Niedrige Samplingrate | Die Samplingrate der WAV-Dateien darf nicht unter 16 KHz liegen. |
| Audio | Zu lange Audioinhalte | Die Audiodauer ist länger als 30 Sekunden. Teilen Sie den langen Audioinhalt in mehrere Dateien auf. Die Äußerungen sollten kürzer als 15 Sekunden sein. |
| Audio | Keine gültigen Audiodaten | In diesem Dataset wurden keine gültigen Audiodaten gefunden. Überprüfen Sie Ihre Audiodaten, und laden Sie sie erneut hoch. |
| Konflikt | Niedrig bewertete Äußerung | Die Bewertung auf Satzebene ist niedriger als 70. Überprüfen Sie Skript- und Audioinhalte, um sicherzustellen, dass sie übereinstimmen. |
Automatisch korrigiert
Die folgenden Fehler werden automatisch behoben, aber Sie sollten dies überprüfen und bestätigen, dass die Korrekturen richtig ausgeführt wurden.
| Category | Name | Beschreibung |
|---|---|---|
| Konflikt | Stille automatisch korrigiert | Es wurde erkannt, dass die Stille zu Beginn weniger als 100 ms dauert, und sie wurde automatisch auf 100 ms erweitert. Laden Sie das normalisierte Dataset herunter, und überprüfen Sie es. |
| Konflikt | Stille automatisch korrigiert | Es wurde erkannt, dass die Stille am Ende weniger als 100 ms dauert, und sie wurde automatisch auf 100 ms erweitert. Laden Sie das normalisierte Dataset herunter, und überprüfen Sie es. |
| Skript | Automatisch normalisierter Text | Text wird für Ziffern, Symbole und Abkürzungen automatisch normalisiert. Überprüfen Sie das Skript und die Audioinhalte, um sicherzustellen, dass sie übereinstimmen. |
Manuelle Überprüfung erforderlich
Werden die Fehler in der folgenden Tabelle nicht behoben, wirkt sich dies negativ auf die Trainingsqualität aus. Jedoch werden Daten, die diese Fehler enthalten, nicht vom Training ausgeschlossen. Sie sollten diese Fehler manuell beheben, um die Qualität des Trainings zu verbessern.
| Category | Name | BESCHREIBUNG |
|---|---|---|
| Skript | Nicht normalisierter Text | Dieses Skript enthält Symbole. Normalisieren Sie die Symbole so, dass sie mit den Audiodaten übereinstimmen. Normalisieren Sie / z. B. in Schrägstrich. |
| Skript | Zu wenige Frageäußerungen | Mindestens 10 % aller Äußerungen sollten Fragesätze sein. Dies hilft dem Stimmmodell, eine richtige Fragenbetonung auszudrücken. |
| Skript | Zu wenige Ausrufeäußerungen | Mindestens 10 % aller Äußerungen sollten Ausfrufesätze sein. Dies hilft dem Stimmmodell, einen aufgeregten Ton richtig auszudrücken. |
| Skript | Keine gültige Interpunktion am Ende | Fügen Sie am Ende der Zeile eins der folgenden Elemente hinzu: Punkt (halbe Breite '.' oder normale Breite '。'), Ausrufezeichen (halbe Breite '!' oder normale Breite '!') oder Fragezeichen (halbe Breite '?' oder normale Breite '?'). |
| Audio | Niedrige Samplingrate für neuronale Stimme | Sie sollten für ihre WAV-Dateien eine Samplingrate von mindestens 24 KHz verwenden, um neuronale Stimmen zu erstellen. Niedrigere Raten werden automatisch auf 24 KHz erhöht. |
| Volume | Gesamtlautstärke zu niedrig | Die Lautstärke sollte nicht unter -18 dB liegen (10 % der maximalen Lautstärke). Halten Sie den durchschnittlichen Lautstärkepegel während der Beispielaufzeichnung oder Datenvorbereitung im richtigen Bereich. |
| Lautstärke | Lautstärkeüberlauf | Ein Lautstärkeüberlauf wird unter {}s erkannt. Passen Sie die Aufzeichnungsgeräte an, um einen Lautstärkeüberlauf beim Spitzenwert zu vermeiden. |
| Lautstärke | Problem mit der Stille zu Beginn | Die ersten 100 ms Stille sind nicht absolut. Reduzieren Sie den Rauschpegel der Aufzeichnung, und lassen Sie die ersten 100 ms still. |
| Lautstärke | Problem mit der Stille am Ende | Die letzten 100 ms Stille sind nicht absolut. Reduzieren Sie den Rauschpegel der Aufzeichnung, und lassen Sie die letzten 100 ms still. |
| Konflikt | Niedrige Bewertung von Wörtern | Überprüfen Sie, ob das Skript und die Audioinhalte übereinstimmen, und steuern Sie den Rauschpegel. Reduzieren Sie Phasen langer Stille, oder teilen Sie die Audiodaten in mehrere Äußerungen auf, wenn sie zu lang sind. |
| Konflikt | Problem mit der Stille zu Beginn | Zusätzliche Audioinhalte waren vor dem ersten Wort zu hören. Überprüfen Sie Skript- und Audioinhalte, um sicherzustellen, dass sie übereinstimmen, steuern Sie den Rauschpegel, und sorgen Sie für die ersten 100 ms Stille. |
| Konflikt | Problem mit der Stille am Ende | Zusätzliche Audioinhalte waren nach dem letzten Wort zu hören. Überprüfen Sie Skript- und Audioinhalte, um sicherzustellen, dass sie übereinstimmen, steuern Sie den Rauschpegel, und sorgen Sie für die letzten 100 ms Stille. |
| Konflikt | Niedriges Signal-Rausch-Verhältnis | Der Pegel des Signal-Rausch-Verhältnisses ist niedriger als 20 dB. Es werden mindestens 35 dB empfohlen. |
| Konflikt | Keine Bewertung verfügbar | Fehler beim Erkennen von Sprachinhalten in diesem Audio. Überprüfen Sie Audio- und Skriptinhalte, um sicherzustellen, dass die Audiodaten gültig sind und mit dem Skript übereinstimmen. |
Nächste Schritte
Sie benötigen ein Trainingsdatenset, um eine professionelle Stimme zu erstellen. Ein Trainingsdatensatz umfasst Audio- und Skriptdateien. Die Audiodateien sind Aufzeichnungen des Sprachtalents, das die Skriptdateien liest. Die Skriptdateien sind der Text der Audiodateien.
In diesem Artikel erstellen Sie einen Trainingssatz und rufen seine Ressourcen-ID ab. Anschließend können Sie mithilfe der Ressourcen-ID eine Reihe von Audio- und Skriptdateienhochladen.
Einen Trainingssatz erstellen
Verwenden Sie den Vorgang TrainingSets_Create der Custom Voice-API, um einen Trainingssatz zu erstellen. Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Legen Sie die erforderliche
projectId-Eigenschaft fest. Siehe Erstellen eines Projekts. - Legen Sie die erforderliche
voiceKind-Eigenschaft aufMaleoderFemalefest. Die Art kann später nicht geändert werden. - Legen Sie die erforderliche
locale-Eigenschaft fest. Dies sollte das Gebietsschema der Trainingssatzdaten sein. Das Gebietsschema des Trainingssatzes sollte mit dem Gebietsschema der Zustimmungserklärungübereinstimmen. Das Gebietsschema können Sie später nicht mehr ändern. Hier finden Sie den Text zur Sprachgebietsschemaliste. - Legen Sie optional die
description-Eigenschaft für die Beschreibung des Trainingssatzes fest. Die Beschreibung des Trainingssatzes kann später geändert werden.
Senden Sie eine HTTP PUT-Anforderung, und verwenden Sie dabei den URI, wie im folgenden Beispiel für TrainingSets_Create gezeigt.
- Ersetzen Sie
YourResourceKeydurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
YourResourceRegiondurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
JessicaTrainingSetIddurch eine Trainingssatz-ID Ihrer Wahl. Die ID der Groß-/Kleinschreibung wird im URI des Trainingssatzes verwendet und kann später nicht geändert werden.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId?api-version=2024-02-01-preview"
Sie sollten einen Antworttext im folgenden Format erhalten:
{
"id": "JessicaTrainingSetId",
"description": "300 sentences Jessica data in general style.",
"projectId": "ProjectId",
"locale": "en-US",
"voiceKind": "Female",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Hochladen von Trainingssatzdaten
Verwenden Sie den Vorgang TrainingSets_UploadData der Custom Voice-API, um einen Trainingssatz mit Audio und Skripts hochzuladen.
Speichern Sie vor dem Aufrufen dieser API Aufzeichnungs- und Skriptdateien in Azure Blob. Im folgenden Beispiel sind Aufzeichnungsdateien https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.wav, Skriptdateien sind https://contoso.blob.core.windows.net/voicecontainer/jessica300/*.txt.
Erstellen Sie den Anforderungstext gemäß den folgenden Anweisungen:
- Setzen Sie die gewünschte Eigenschaft
kindaufAudioAndScript. Die Art bestimmt den Typ des Trainingssatzes. - Legen Sie die erforderliche
audios-Eigenschaft fest. Legen Sie innerhalb deraudios-Eigenschaft die folgenden Eigenschaften fest:- Legen Sie die erforderliche
containerUrl-Eigenschaft auf die URL des Azure Blob Storage-Containers fest, der die Audiodateien enthält. Verwenden Sie freigegebene Zugriffssignaturen (SAS) für einen Container mit Lese- und Listenberechtigungen. - Legen Sie die erforderliche
extensions-Eigenschaft auf die Erweiterungen der Audiodateien fest. - Legen Sie optional die
prefix-Eigenschaft fest, um ein Präfix für den Blobnamen festzulegen.
- Legen Sie die erforderliche
- Legen Sie die erforderliche
scripts-Eigenschaft fest. Legen Sie innerhalb derscripts-Eigenschaft die folgenden Eigenschaften fest:- Legen Sie die erforderliche
containerUrl-Eigenschaft auf die URL des Azure Blob Storage-Containers fest, der die Skriptdateien enthält. Verwenden Sie freigegebene Zugriffssignaturen (SAS) für einen Container mit Lese- und Listenberechtigungen. - Legen Sie die erforderliche
extensions-Eigenschaft auf die Erweiterungen der Skriptdateien fest. - Legen Sie optional die
prefix-Eigenschaft fest, um ein Präfix für den Blobnamen festzulegen.
- Legen Sie die erforderliche
Senden Sie eine HTTP POST-Anforderung, und verwenden Sie dabei den URI, wie im folgenden Beispiel für TrainingSets_UploadData gezeigt.
- Ersetzen Sie
YourResourceKeydurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
YourResourceRegiondurch Ihren Speech-Ressourcenschlüssel. - Ersetzen Sie
JessicaTrainingSetId, wenn Sie im vorherigen Schritt eine andere Trainingssatz-ID angegeben haben.
curl -v -X POST -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"kind": "AudioAndScript",
"audios": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".wav"
]
},
"scripts": {
"containerUrl": "https://contoso.blob.core.windows.net/voicecontainer?mySasToken",
"prefix": "jessica300/",
"extensions": [
".txt"
]
}
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/trainingsets/JessicaTrainingSetId:upload?api-version=2024-02-01-preview"
Der Antwortheader enthält die Operation-Location-Eigenschaft. Verwenden Sie diesen URI, um Details zum Vorgang TrainingSets_UploadData abzurufen. Hier ist ein Beispiel für die Antwort:
Operation-Location: https://eastus.api.cognitive.microsoft.com/customvoice/operations/284b7e37-f42d-4054-8fa9-08523c3de345?api-version=2024-02-01-preview
Operation-Id: 284b7e37-f42d-4054-8fa9-08523c3de345