Tutorial: Einrichten der SQL-Datensynchronisierung zwischen Datenbanken in Azure SQL-Datenbank und SQL Server
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Wichtig
SQL-Datensynchronisierung wird am 30. September 2027 ausgemustert. Erwägen Sie die Migration zu alternativen Datenreplikations-/Synchronisierungslösungen.
In diesem Tutorial erfahren Sie, wie Sie die SQL-Datensynchronisierung einrichten, indem Sie eine Synchronisierungsgruppe erstellen, die sowohl Azure SQL-Datenbank- als auch SQL Server-Instanzen enthält. Die Synchronisierungsgruppe ist speziell konfiguriert und verwendet den von Ihnen festgelegten Synchronisierungszeitplan.
In dem Tutorial wird davon ausgegangen, dass Sie über eine gewisse Erfahrung mit SQL-Datenbank und SQL Server verfügen.
Eine Übersicht über die SQL-Datensynchronisierung finden Sie unter Was ist die SQL-Datensynchronisierung für Azure?
PowerShell-Beispiele für die Konfiguration der SQL-Datensynchronisierung finden Sie unter Verwenden von PowerShell zum Synchronisieren von Daten zwischen mehreren Datenbanken in Azure SQL-Datenbank und zwischen Datenbanken in Azure SQL-Datenbank und SQL Server.
Die Hub-Datenbank ist der zentrale Endpunkt einer Synchronisierungstopologie, bei der eine Synchronisierungsgruppe mehrere Datenbankendpunkte enthält. Alle anderen Mitgliedsdatenbanken mit Endpunkten in der gleichen Synchronisierungsgruppe werden mit der Hub-Datenbank synchronisiert. Die SQL-Datensynchronisierung wird nur für Azure SQL-Datenbank unterstützt. Die Hub-Datenbank muss eine Azure SQL-Datenbank sein.
Azure SQL-Datenbank Hyperscale wird nur als Mitgliedsdatenbank und nicht als Hub-Datenbank unterstützt.
Erstellen der Synchronisierungsgruppe
Öffnen Sie das Azure-Portal. Suchen und wählen Sie SQL-Datenbanken aus, um eine vorhandene Azure SQL-Datenbank zu finden.
Wählen Sie die vorhandene Datenbank aus, die Sie als die Hub-Datenbank für die Datensynchronisierung verwenden möchten.
Wählen Sie im Menü SQL-Datenbank für die ausgewählte Datenbank unter Datenverwaltungdie Option Mit anderen Datenbankensynchronisieren aus.
Wählen Sie auf der Seite Mit anderen Datenbanken synchronisieren die Option Neue Synchronisierungsgruppe aus. Die Seite Datensynchronisierungsgruppe erstellen wird ebenfalls geöffnet.
Konfigurieren Sie auf der Seite Datensynchronisierungsgruppe erstellen die folgenden Einstellungen:
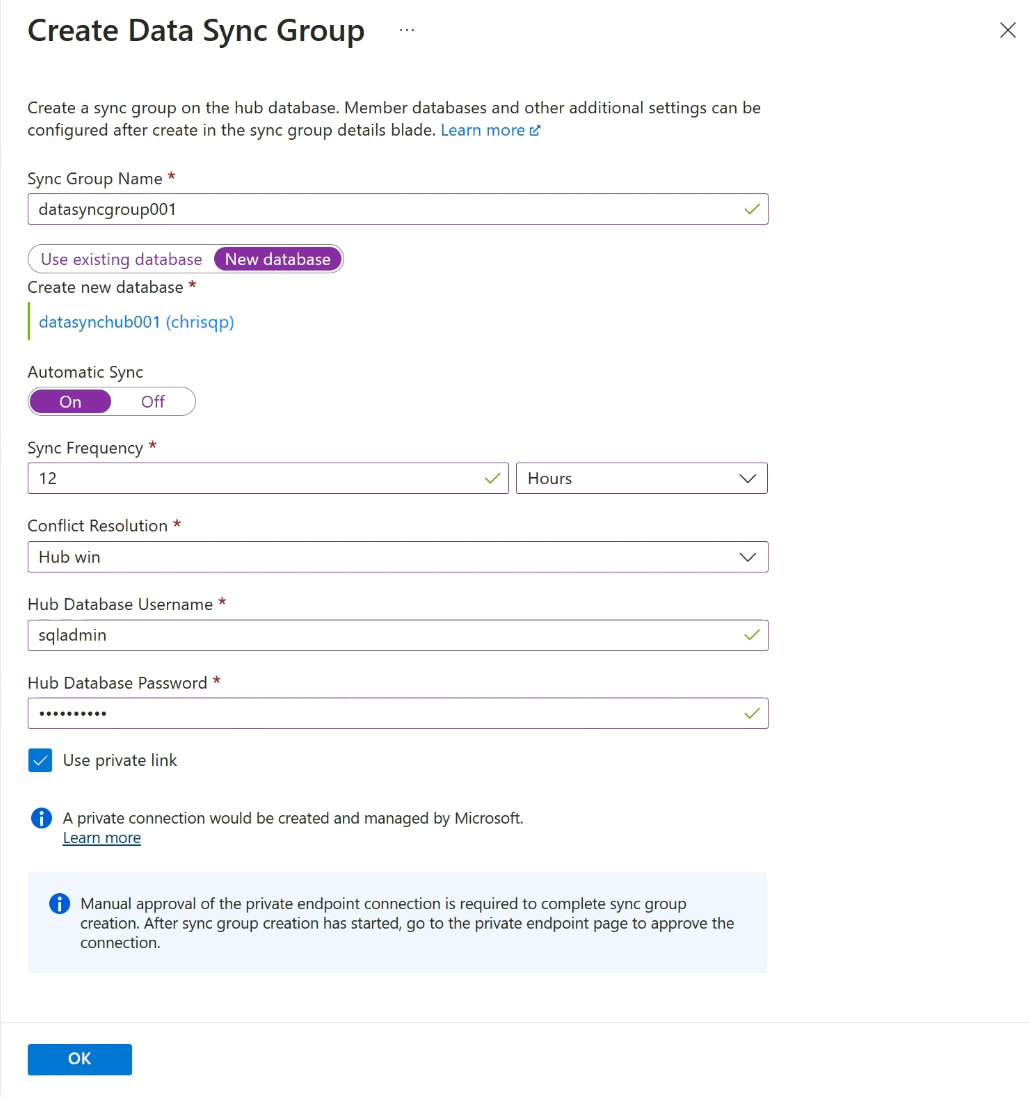
Einstellung Beschreibung Name der Synchronisierungsgruppe Geben Sie einen Namen für die neue Synchronisierungsgruppe ein. Dieser Name unterscheidet sich vom Namen der Datenbank. Datenbank für Synchronisierungsmetadaten Erstellen Sie eine Datenbank (empfohlen), oder verwenden Sie eine vorhandene Datenbank, die als Datenbank für Synchronisierungsmetadaten dient.
Microsoft empfiehlt, eine neue, leere Datenbank als Synchronisierungs-Metadatendatenbank zu erstellen. Durch die Datensynchronisierung werden Tabellen in Datenbanken erstellt und eine häufige Workload ausgeführt. Diese Datenbank wird als Datenbank für Synchronisierungsmetadaten für alle Synchronisierungsgruppen in einer ausgewählten Region und in einem ausgewählten Abonnement freigegeben. Sie können die Datenbank oder den Datenbanknamen nicht ändern, ohne alle Synchronisierungsgruppen und Synchronisierungs-Agents in der Region zu entfernen.
Wenn Sie sich für eine neue Datenbank entscheiden, wählen Sie Neue Datenbank aus. Wählen Sie Konfigurieren der Datenbankeinstellungen Auswählen Benennen und konfigurieren Sie dann eine neue Azure SQL-Datenbank auf der Seite SQL-Datenbank, und wählen Sie OK aus.
Wenn Sie sich für Vorhandene Datenbank verwenden entscheiden, wählen Sie Dropdown-Liste Datenbank für Synchronisierungsmetadaten die Datenbank aus.Automatische Synchronisierung Wählen Sie Ein oder Aus aus.
Geben Sie bei Verwendung von Ein im Abschnitt Synchronisierungshäufigkeit eine Zahl ein, und wählen Sie Sekunden, Minuten, Stunden oder Tage aus.
Die erste Synchronisierung beginnt, wenn das ausgewählte Intervall nach dem Speichern der Konfiguration abgelaufen ist.Konfliktlösung Wählen Sie Hub hat Vorrang oder Mitglied hat Vorrang aus.
Hub hat Vorrang bedeutet, dass bei einem Konflikt die in Konflikt stehenden Daten in der Mitgliedsdatenbank durch die Daten in der Hub-Datenbank überschrieben werden.
Mitglied hat Vorrang bedeutet, dass bei einem Konflikt die in Konflikt stehenden Daten in der Hub-Datenbank durch die Daten in der Mitgliedsdatenbank überschrieben werden.Benutzername für Hub-Datenbank und Kennwort für Hub-Datenbank Geben Sie den Benutzernamen und das Kennwort für die durch SQL authentifizierte Anmeldung des Serveradministrators für die Hub-Datenbank an. Dies ist der Benutzername und das Kennwort des Serveradministrators für denselben logischen Azure SQL-Server, auf dem Sie begonnen haben. Die Microsoft Entra-Authentifizierung (bisher Azure Active Directory) wird nicht unterstützt. Use private link (Private Verbindung verwenden) Wählen Sie einen dienstseitig verwalteten privaten Endpunkt aus, um eine sichere Verbindung zwischen dem Synchronisierungsdienst und der Hub-Datenbank einzurichten. Wählen Sie OK aus, und warten Sie, bis die Synchronisierungsgruppe erstellt und bereitgestellt wurde.
Wenn Sie auf der Seite Neue Synchronisierungsgruppe das Kontrollkästchen Use private link (Private Verbindung verwenden) aktiviert haben, müssen Sie die Verbindung mit dem privaten Endpunkt genehmigen. Über den Link in der Infomeldung gelangen Sie zur Umgebung für Verbindungen mit privaten Endpunkten, wo Sie die Verbindung genehmigen können.
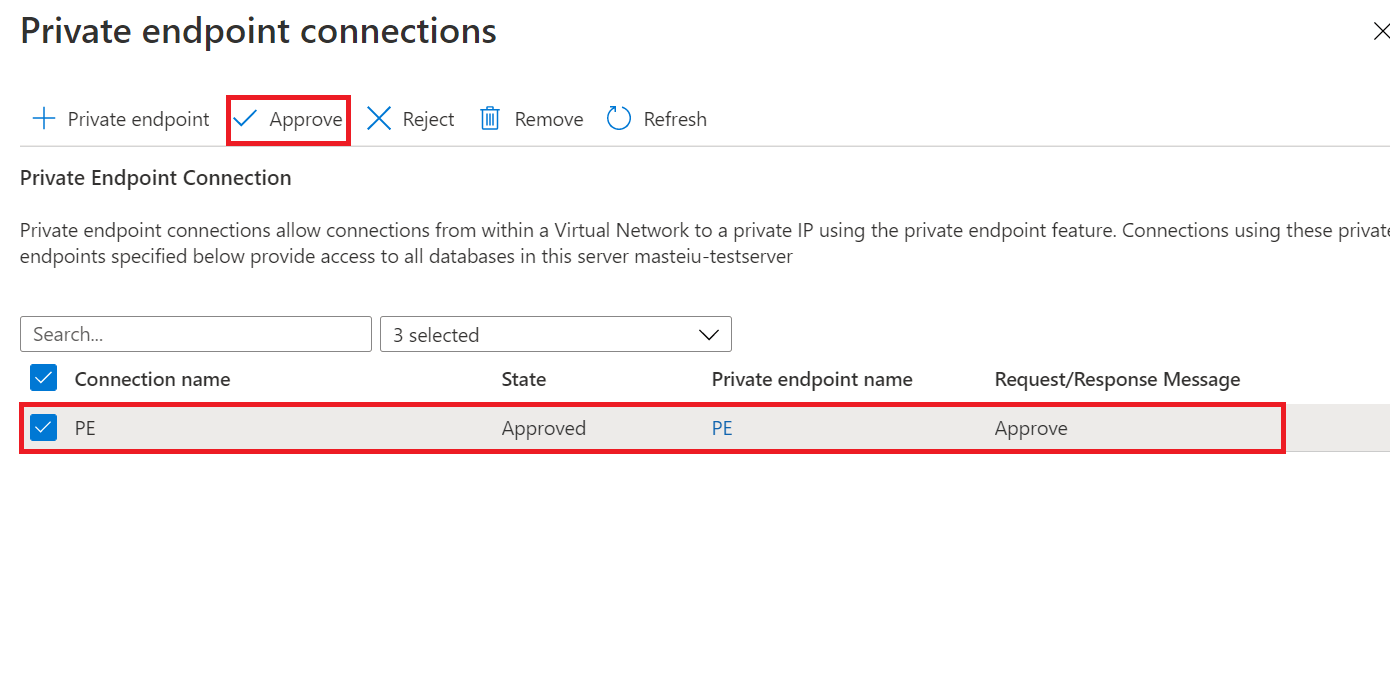
Hinweis
Die privaten Verbindungen für die Synchronisierungsgruppe und die Synchronisierungsmitglieder müssen separat erstellt, genehmigt und deaktiviert werden.


Hinzufügen von Synchronisierungsmitgliedern
Öffnen Sie nach der Erstellung und Bereitstellung der neuen Synchronisierungsgruppe die Synchronisierungsgruppe, und greifen Sie auf die Seite Datenbanken zu, auf der Sie Synchronisierungsmitglieder auswählen.
Hinweis
Um den Benutzernamen und das Kennwort für Ihre Hub-Datenbank zu aktualisieren oder einzufügen, navigieren Sie auf der Seite Synchronisierungsmitglieder auswählen zum Abschnitt Hub-Datenbank.
Hinzufügen einer Datenbank in der Azure SQL-Datenbank als Mitglied zu einer Synchronisierungsgruppe
Fügen Sie im Abschnitt Synchronisierungsmitglieder auswählen optional eine Datenbank in Azure SQL-Datenbank zur Synchronisierungsgruppe hinzu, indem Sie Azure SQL-Datenbank hinzufügen auswählen. Die Seite Azure-Datenbank konfigurieren wird geöffnet.
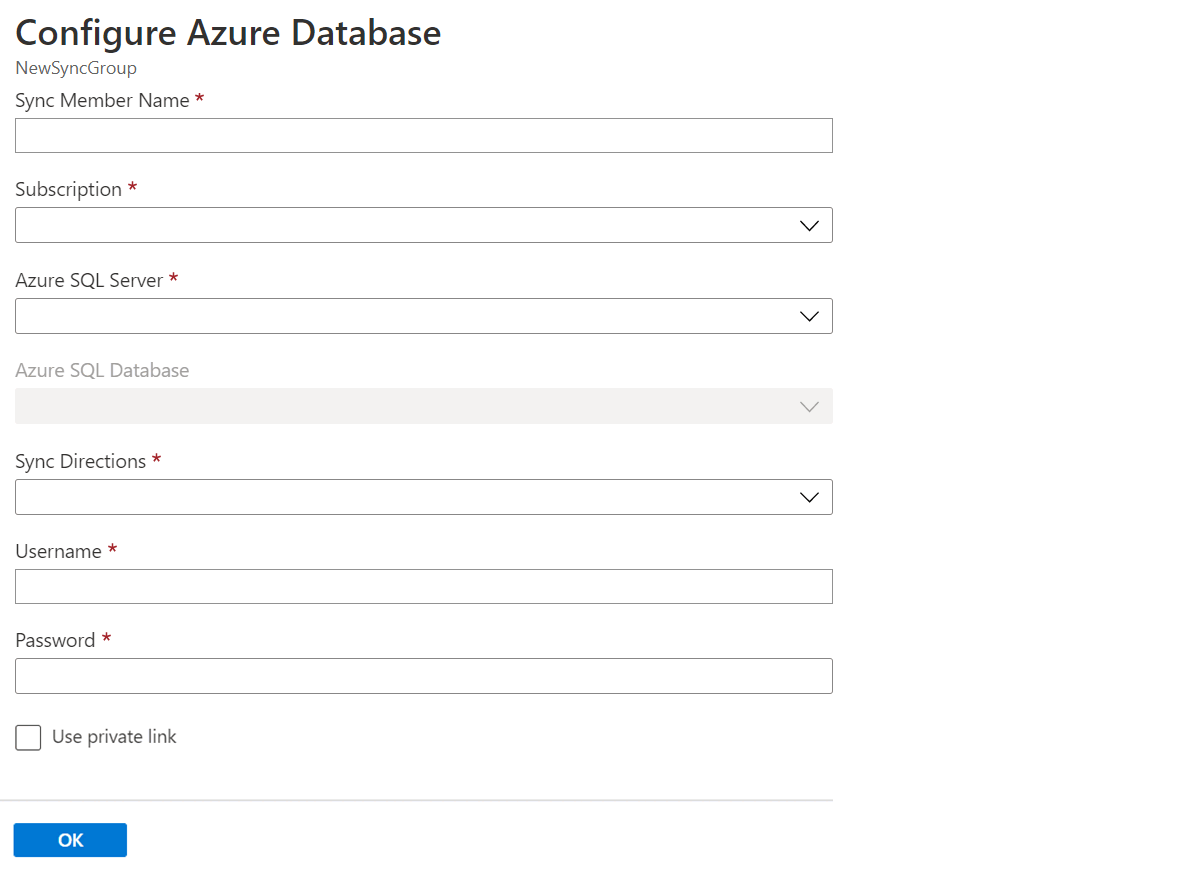
Ändern Sie auf der Seite Azure SQL-Datenbank konfigurieren die folgenden Einstellungen:
Einstellung Beschreibung Name des Synchronisierungsmitglieds Geben Sie einen Namen für das neue Synchronisierungsmitglied an. Dieser Name unterscheidet sich vom Namen der Datenbank. Abonnement Wählen Sie das verknüpfte Azure-Abonnement für die Abrechnung aus. Azure SQL Server Wählen Sie den vorhandenen Server aus. Azure SQL-Datenbank Wählen Sie die vorhandene Datenbank in SQL-Datenbank aus. Synchronisierungsrichtungen Für die Synchronisierungsrichtung kann also Vom Hub zum Mitglied, Vom Mitglied zum Hub oder beides gelten. Wählen Sie Vom Hub, Zum Hub oder Bidirektionale Synchronisierung aus. Weitere Informationen finden Sie unter Funktionsweise. Benutzername und Kennwort Geben Sie die vorhandenen Anmeldeinformationen für den Server ein, auf dem sich die Mitgliedsdatenbank befindet. Geben Sie in diesem Abschnitt keine neuen Anmeldeinformationen ein. Use private link (Private Verbindung verwenden) Wählen Sie einen dienstseitig verwalteten privaten Endpunkt aus, um eine sichere Verbindung zwischen dem Synchronisierungsdienst und der Mitgliedsdatenbank einzurichten. Klicken Sie auf OK, und warten Sie, bis die neue Synchronisierungsmitglied erstellt und bereitgestellt wird.

Hinzufügen einer Datenbank in einer SQL Server-Instanz als Mitglied zu einer Synchronisierungsgruppe
Im Abschnitt Mitgliedsdatenbank können Sie der Synchronisierungsgruppe optional eine SQL Server-Instanz hinzufügen, indem Sie die Option Lokale Datenbank hinzufügen auswählen.
Auf der daraufhin geöffneten Seite Lokale Konfiguration haben Sie folgende Möglichkeiten:
Klicken Sie auf Synchronisierungs-Agent-Gateway auswählen. Die Seite Synchronisierungs-Agent auswählen wird geöffnet.
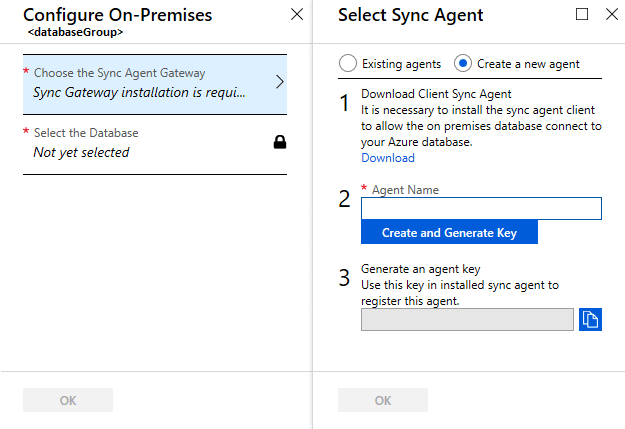
Wählen Sie auf der Seite Synchronisierungs-Agent auswählen aus, ob Sie einen vorhandenen Agent verwenden oder einen Agent erstellen möchten.
Wenn Sie sich für Vorhandene Agents entscheiden, wählen Sie den vorhandenen Agent aus der Liste aus.
Wenn Sie sich für Neuen Agent erstellen entscheiden, führen Sie folgende Schritte aus:
Laden Sie über den bereitgestellten Link den Datensynchronisierungs-Agent herunter, und installieren Sie ihn auf einem Server, der nicht der Server ist, auf dem sich die SQL-Server-Instanz befindet. Sie können den Agent auch direkt unter SQL Azure Data Sync Agent herunterladen. Bewährte Methoden für den Synchronisierungsclient-Agent finden Sie unter Bewährte Methoden für die Microsoft SQL-Datensynchronisierung.
Wichtig
Sie müssen den ausgehenden TCP-Port 1433 in der Firewall öffnen, damit der Client-Agent mit dem Server kommunizieren kann.
Geben Sie einen Agent-Namen ein.
Wählen Sie Schlüssel erstellen und generieren aus, und kopieren Sie den Agent-Schlüssel in die Zwischenablage.
Klicken Sie auf OK, um die Seite Synchronisierungs-Agent auswählen zu schließen.
Suchen Sie auf dem Server, auf dem der Synchronisierungsclient-Agent installiert ist, die Clientsynchronisierungs-Agent-App, und führen Sie sie aus.
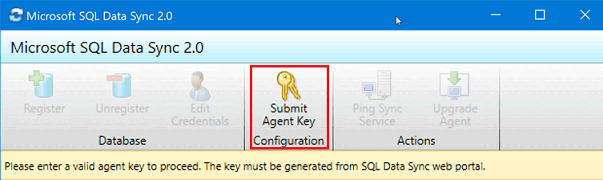
Klicken Sie in der Synchronisierungs-Agent-Anwendung auf Submit Agent Key (Agent-Schlüssel übermitteln). Das Dialogfeld Sync Metadata Database Configuration (Konfiguration der Datenbank für Synchronisierungsmetadaten) wird geöffnet.
Fügen Sie im Dialogfeld Konfiguration der Datenbank für Synchronisierungsmetadaten den Agent-Schlüssel ein, den Sie aus dem Azure-Portal kopiert haben. Geben Sie auch die vorhandenen Anmeldeinformationen für den Server ein, auf dem sich die Datenbank für Synchronisierungsmetadaten befindet. Klicken Sie auf OK, und warten Sie, bis die Konfiguration abgeschlossen ist.
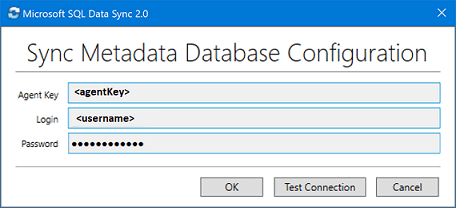
Hinweis
Sollte ein Firewallfehler auftreten, erstellen Sie in Azure eine Firewallregel, um eingehenden Datenverkehr des SQL Server-Computers zuzulassen. Sie können die Regel manuell über das Portal oder in SQL Server Management Studio (SSMS) erstellen. Stellen Sie in SSMS eine Verbindung mit der Hub-Datenbank in Azure her, indem Sie ihren Namen im Format
<hub_database_name>.database.windows.neteingeben.Wählen Sie Registrieren aus, um eine SQL Server-Datenbank beim Agent zu registrieren. Das Dialogfeld SQL Server-Konfiguration wird geöffnet.
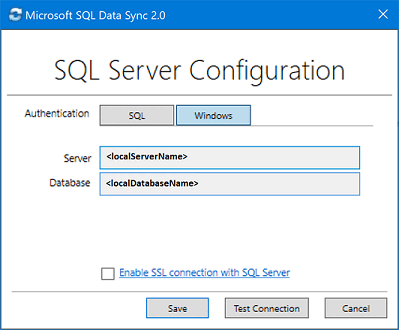
Wählen Sie im Dialogfeld SQL Server-Konfiguration aus, ob bei der Verbindungsherstellung die SQL Server-Authentifizierung oder die Windows-Authentifizierung verwendet werden soll. Wenn Sie sich für die SQL Server-Authentifizierung entscheiden, geben Sie die vorhandenen Anmeldeinformationen ein. Geben Sie den SQL Server-Namen und den Namen der Datenbank an, die Sie synchronisieren möchten, und wählen Sie Verbindung testen aus, um Ihre Einstellungen zu testen. Wählen Sie anschließend Speichern aus. Die registrierte Datenbank wird daraufhin in der Liste angezeigt.
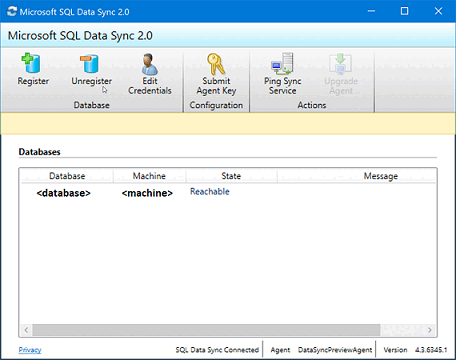
Schließen Sie App „Clientsynchronisierungs-Agent“.
Wählen Sie im Azure-Portal auf der Seite Lokale Konfiguration die Option Datenbank auswählen aus.
Geben Sie auf der Seite Datenbank auswählen im Feld Name des Synchronisierungsmitglieds einen Namen für das neue Synchronisierungsmitglied an. Dieser Name unterscheidet sich vom Namen der Datenbank. Wählen Sie die Datenbank aus der Liste aus. Wählen Sie im Feld Synchronisierungsrichtungen die Option Bidirektionale Synchronisierung, Zum Hub oder Vom Hub aus.
Klicken Sie auf OK, um die Seite Datenbank auswählen zu schließen. Klicken Sie dann auf OK, um die Seite Lokale Konfiguration zu schließen, und warten Sie, bis das neue Synchronisierungsmitglied erstellt und bereitgestellt wurde. Wählen abschließend OK aus, um die Seite Synchronisierungsmitglieder auswählen zu schließen.
Hinweis
Um eine Verbindung mit der SQL-Datensynchronisierung und dem lokalen Agent herzustellen, fügen Sie Ihren Benutzername der Rolle DataSync_Executor hinzu. Die Datensynchronisierung erstellt diese Rolle auf der SQL Server-Instanz.
Konfigurieren der Synchronisierungsgruppe
Navigieren Sie nach dem Erstellen und Bereitstellen neuer Synchronisierungsgruppenmitglieder auf der Seite Datenbanksynchronisierungsgruppe zum Abschnitt Tabellen.

Wählen Sie auf der Seite Tabellen eine Datenbank aus der Liste der Synchronisierungsgruppenmitglieder aus, und wählen Sie anschließend Schema aktualisieren aus. Rechnen Sie mit einer Verzögerung von einigen Minuten bei der Schemaaktualisierung. Bei Verwendung einer privaten Verbindung kann die Verzögerung etwas länger sein.
Wählen Sie in der Liste die Tabellen aus, die Sie synchronisieren möchten. Standardmäßig sind alle Spalten ausgewählt. Deaktivieren Sie daher die Kontrollkästchen der Spalten, die Sie nicht synchronisieren möchten. Achten Sie darauf, dass die Primärschlüsselspalte ausgewählt bleibt.
Wählen Sie Speichern aus.
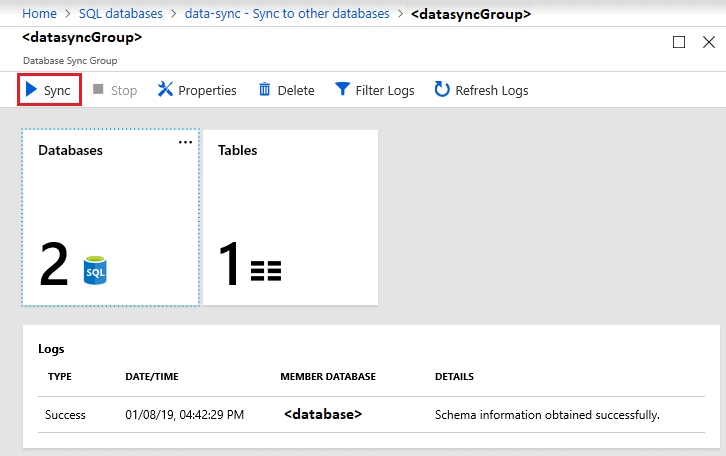
Standardmäßig werden Datenbanken erst synchronisiert, wenn dies per Zeitplan konfiguriert oder eine manuelle Synchronisierung ausgeführt wird. Navigieren Sie zum Ausführen einer manuellen Synchronisierung im Azure-Portal zu Ihrer Datenbank in SQL-Datenbank, wählen Sie Mit anderen Datenbanken synchronisieren aus, und wählen Sie dann die Synchronisierungsgruppe aus. Die Seite Datensynchronisierung wird geöffnet. Klicken Sie auf Synchronisieren.
Häufig gestellte Fragen
In diesem Abschnitt werden häufig gestellte Fragen zum Azure SQL Data Sync-Dienst beantwortet.
Werden von der SQL-Datensynchronisierung Tabellen vollständig erstellt?
Sollten in der Zieldatenbank Synchronisierungsschematabellen fehlen, werden sie von der SQL-Datensynchronisierung mit den von Ihnen ausgewählten Spalten erstellt. Allerdings wird dabei aus folgenden Gründen kein vollständig identisches Schema erstellt:
- In der Zieltabelle werden nur von Ihnen ausgewählte Spalten erstellt. Nicht ausgewählte Spalten werden ignoriert.
- In der Zieltabelle werden nur ausgewählte Spaltenindizes erstellt. Für nicht ausgewählte Spalten werden diese Indizes ignoriert.
- Es werden keine Indizes für XML-Spalten erstellt.
- Es werden keine CHECK-Einschränkungen erstellt.
- Es werden keine Trigger für die Quelltabellen erstellt.
- Es werden keine Sichten und gespeicherten Prozeduren erstellt.
Aufgrund dieser Einschränkungen wird Folgendes empfohlen:
- Erstellen Sie für Produktionsumgebungen das vollständig identische Schema selbst.
- Verwenden Sie die automatische Bereitstellung, wenn Sie mit dem Dienst experimentieren.
Warum werden Tabellen angezeigt, die ich nicht erstellt habe?
Die Datensynchronisierung erstellt in der Datenbank zusätzliche Tabellen für die Änderungsnachverfolgung. Löschen Sie diese Tabellen nicht, da ansonsten die Datensynchronisierung nicht mehr funktioniert.
Sind meine Daten nach einer Synchronisierung konvergent?
Nicht unbedingt. Stellen Sie sich beispielsweise eine Synchronisierungsgruppe mit einem Hub und drei Spokes (A, B und C) vor, bei der Synchronisierungen zwischen dem Hub und A, dem Hub und B und dem Hub und C erfolgen. Wenn die Datenbank A nach der Synchronisierung des Hubs mit A geändert wird, wird diese Änderung erst im Rahmen der nächsten Synchronisierungsaufgabe in die Datenbank B oder C geschrieben.
Wie übertrage ich Schemaänderungen in eine Synchronisierungsgruppe?
Alle Schemaänderungen müssen manuell vorgenommen und verteilt werden.
- Replizieren Sie die Schemaänderungen manuell auf dem Hub und auf allen Synchronisierungsmitgliedern.
- Aktualisieren Sie das Synchronisierungsschema.
Informationen zum Hinzufügen neuer Tabellen und Spalten:
Neue Tabellen und Spalten haben keine Auswirkungen auf die aktuelle Synchronisierung. Sie werden von der Datensynchronisierung ignoriert, bis sie dem Synchronisierungsschema hinzugefügt werden. Halten Sie sich beim Hinzufügen neuer Datenbankobjekte an die folgende Reihenfolge:
- Fügen Sie neue Tabellen oder Spalten dem Hub und allen Synchronisierungsmitgliedern hinzu.
- Fügen Sie neue Tabellen oder Spalten dem Synchronisierungsschema hinzu.
- Beginnen Sie mit dem Einfügen von Werten in die neuen Tabellen und Spalten.
So ändern Sie den Datentyp einer Spalte
Wenn Sie den Datentyp einer vorhandenen Spalte ändern, funktioniert die Datensynchronisierung weiterhin – vorausgesetzt, die neuen Werte sind mit dem ursprünglich im Synchronisierungsschema definierten Datentyp kompatibel. Wenn Sie also beispielsweise in der Quelldatenbank den Typ von int in bigint ändern, funktioniert die Datensynchronisierung weiterhin, solange Sie keinen Wert einfügen, der für den Datentyp int zu groß ist. Replizieren Sie die Schemaänderung manuell auf dem Hub sowie auf allen Synchronisierungsmitgliedern, und aktualisieren Sie anschließend das Synchronisierungsschema, um die Änderung abzuschließen.
Wie kann ich eine Datenbank mithilfe der Datensynchronisierung exportieren und importieren?
Nachdem Sie eine Datenbank als .bacpac exportiert und die Datei zum Erstellen einer neuen Datenbank importiert haben, gehen Sie wie folgt vor, um die Datensynchronisierung in der neuen Datenbank zu verwenden:
- Bereinigen Sie in der neuen Datenbank mithilfe der cleanup.sql Datensynchronisierung abgeschlossen. Das Skript löscht alle erforderlichen Datensynchronisierungsobjekte aus der Datenbank.
- Erstellen Sie die Synchronisierungsgruppe mit der neuen Datenbank neu. Wenn Sie die alte Synchronisierungsgruppe nicht mehr benötigen, löschen Sie sie.
Wo finde ich Informationen zum Client-Agent?
Häufig gestellte Fragen zum Client-Agent finden Sie unter Agent – Häufig gestellte Fragen.
Muss die Verbindung manuell genehmigt werden, damit sie verwendet werden kann?
Ja. Sie müssen den vom Dienst verwalteten privaten Endpunkt manuell genehmigen – entweder während der Synchronisierungsgruppenbereitstellung im Azure-Portal auf der Seite „Verbindungen mit privatem Endpunkt“ oder mithilfe von PowerShell.
Warum tritt ein Firewallfehler auf, wenn der Synchronisierungsauftrag meine Azure-Datenbank bereitstellt?
Dieser Fehler kann auftreten, wenn Azure-Ressourcen nicht auf Ihren Server zugreifen dürfen. Es gibt zwei Lösungen:
- Stellen Sie sicher, dass für die Firewall in der Azure-Datenbank die Einstellung Anderen Azure-Diensten und -Ressourcen den Zugriff auf diesen Server gestatten auf Ja festgelegt ist. Weitere Informationen finden Sie unter Azure SQL-Datenbank und Netzwerkzugriffssteuerung.
- Konfigurieren Sie eine private Verbindung für die Datensynchronisierung, die nicht auf Azure Private Link basiert. Private Link bietet die Möglichkeit, Synchronisierungsgruppen mithilfe einer sicheren Verbindung mit Datenbanken zu erstellen, die sich hinter einer Firewall befinden. Private Link für die SQL-Datensynchronisierung ist ein von Microsoft verwalteter Endpunkt, der intern ein Subnetz innerhalb des vorhandenen virtuellen Netzwerks erstellt, sodass kein weiteres virtuelles Netzwerk oder Subnetz erstellt werden muss.
Zugehöriger Inhalt
- Was ist die SQL-Datensynchronisierung für Azure?
- Data Sync Agent für die SQL-Datensynchronisierung
- Best practices for Azure SQL Data Sync (Preview) (Bewährte Methoden für die Azure SQL-Datensynchronisierung-Vorschauversion)
- Behandeln von Problemen mit der SQL-Datensynchronisierung
- Überwachung und Leistungsoptimierung in Azure SQL-Datenbank und Azure SQL Managed Instance
- Automatisieren der Replikation von Schemaänderungen in der Azure SQL-Datensynchronisierung
- Verwenden von PowerShell zum Aktualisieren des Synchronisierungsschemas in einer bestehenden Synchronisierungsgruppe
- Was ist Azure SQL-Datenbank?
- Datenbank-Lebenszyklusverwaltung