Automatisieren der Replikation von Schemaänderungen in der Azure SQL-Datensynchronisierung
Gilt für: ![]() Azure SQL-Datenbank
Azure SQL-Datenbank
Wichtig
SQL-Datensynchronisierung wird am 30. September 2027 ausgemustert. Erwägen Sie die Migration zu alternativen Datenreplikations-/Synchronisierungslösungen.
Mit der SQL-Datensynchronisierung können Benutzer*innen Daten zwischen Datenbanken in Azure SQL-Datenbank und SQL Server-Instanzen in eine Richtung oder in beide Richtungen synchronisieren. Eine der aktuellen Einschränkungen der SQL-Datensynchronisierung ist die fehlende Unterstützung für die Replikation von Schemaänderungen. Jedes Mal, wenn Sie das Tabellenschema ändern, müssen Sie die Änderungen manuell auf alle Endpunkte, einschließlich des Hubs und aller Mitglieder, anwenden und dann das Synchronisierungsschema aktualisieren.
Dieser Artikel stellt eine Lösung zur automatisierten Replikation von Schemaänderungen auf alle Endpunkte der SQL-Datensynchronisierung vor.
- Diese Lösung nutzt einen DDL-Trigger, um Schemaänderungen nachzuverfolgen.
- Durch den Trigger werden die Befehle für die Schemaänderung in eine Nachverfolgungstabelle eingefügt.
- Diese Nachverfolgungstabelle wird über den Datensynchronisierungsdienst mit allen Endpunkten synchronisiert.
- DML-Trigger nach dem Einfügen werden verwendet, um die Schemaänderungen auf die anderen Endpunkte anzuwenden.
In diesem Artikel wird ALTER TABLE als Beispiel für eine Schemaänderung verwendet, aber diese Lösung funktioniert auch für andere Arten von Schemaänderungen.
Lesen Sie diesen Artikel sorgfältig, insbesondere die Abschnitte Problembehandlung und Weitere Überlegungen, bevor Sie mit der Implementierung der automatisierten Replikation von Schemaänderungen in Ihrer Synchronisierungsumgebung beginnen. Einige Datenbankvorgänge führen unter Umständen dazu, dass die in diesem Artikel beschriebene Lösung nicht mehr funktioniert. Möglichweise sind zusätzliche Domänenkenntnisse von SQL Server und Transact-SQL erforderlich, um derartige Probleme zu beheben.
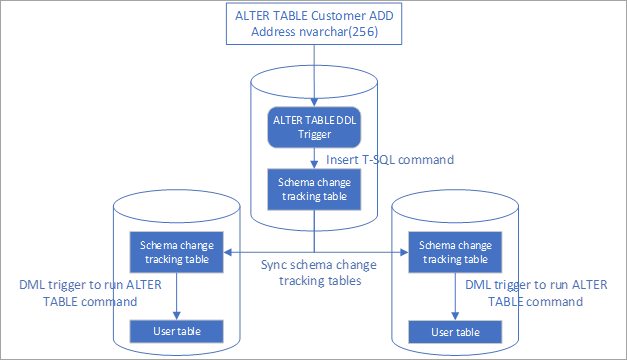
Einrichten der automatisierten Replikation von Schemaänderungen
Erstellen einer Tabelle zum Nachverfolgen von Schemaänderungen
Erstellen Sie eine Tabelle zum Nachverfolgen von Schemaänderungen in allen Datenbanken der Synchronisierungsgruppe:
CREATE TABLE SchemaChanges (
ID bigint IDENTITY(1,1) PRIMARY KEY,
SqlStmt nvarchar(max),
[Description] nvarchar(max)
)
Diese Tabelle weist eine Identitätsspalte auf, damit Sie die Reihenfolge der Schemaänderungen nachvollziehen können. Fügen Sie bei Bedarf zusätzliche Felder hinzu, um weitere Informationen zu protokollieren.
Erstellen einer Tabelle zum Nachverfolgen des Verlaufs der Schemaänderungen
Erstellen Sie für alle Endpunkte eine Tabelle, um die ID des zuletzt verwendeten Schemaänderungsbefehls zu verfolgen.
CREATE TABLE SchemaChangeHistory (
LastAppliedId bigint PRIMARY KEY
)
GO
INSERT INTO SchemaChangeHistory VALUES (0)
Erstellen eines ALTER TABLE-DDL-Triggers in der Datenbank, in der Schemaänderungen vorgenommen werden
Erstellen Sie einen DDL-Trigger für ALTER TABLE-Vorgänge. Sie müssen diesen Trigger nur in der Datenbank erstellen, in der Schemaänderungen vorgenommen werden. Um Konflikte zu vermeiden, lassen Sie nur Schemaänderungen in einer Datenbank einer Synchronisierungsgruppe zu.
CREATE TRIGGER AlterTableDDLTrigger
ON DATABASE
FOR ALTER_TABLE
AS
-- You can add your own logic to filter ALTER TABLE commands instead of replicating all of them.
IF NOT (EVENTDATA().value('(/EVENT_INSTANCE/SchemaName)[1]', 'nvarchar(512)') like 'DataSync')
INSERT INTO SchemaChanges (SqlStmt, Description)
VALUES (EVENTDATA().value('(/EVENT_INSTANCE/TSQLCommand/CommandText)[1]', 'nvarchar(max)'), 'From DDL trigger')
Für jeden ALTER TABLE-Befehl fügt der Trigger einen Datensatz in die Tabelle der Schemaänderungsnachverfolgung ein. In diesem Beispiel wird ein Filter hinzugefügt, um zu vermeiden, dass Schemaänderungen unter dem Schema DataSync repliziert werden, da diese höchstwahrscheinlich vom Datensynchronisierungsdienst vorgenommen werden. Fügen Sie weitere Filter hinzu, wenn Sie nur bestimmte Typen von Schemaänderungen replizieren möchten.
Außerdem haben Sie auch die Möglichkeit, weitere Trigger hinzuzufügen, um andere Typen von Schemaänderungen zu replizieren. Erstellen Sie beispielsweise CREATE_PROCEDURE-, ALTER_PROCEDURE- und DROP_PROCEDURE-Trigger, um Änderungen auf gespeicherte Prozeduren zu replizieren.
Erstellen eines Triggers an anderen Endpunkten zum Anwenden von Schemaänderungen während des Einfügens
Dieser Trigger führt den Befehl für die Schemaänderung aus, wenn er mit anderen Endpunkten synchronisiert wird. Sie müssen diesen Trigger an allen Endpunkten erstellen, mit Ausnahme desjenigen, an dem Schemaänderungen vorgenommen werden (d.h. in der Datenbank, in der im vorherigen Schritt der DDL-Trigger AlterTableDDLTrigger erstellt wurde).
CREATE TRIGGER SchemaChangesTrigger
ON SchemaChanges
AFTER INSERT
AS
DECLARE @lastAppliedId bigint
DECLARE @id bigint
DECLARE @sqlStmt nvarchar(max)
SELECT TOP 1 @lastAppliedId=LastAppliedId FROM SchemaChangeHistory
SELECT TOP 1 @id = id, @SqlStmt = SqlStmt FROM SchemaChanges WHERE id > @lastAppliedId ORDER BY id
IF (@id = @lastAppliedId + 1)
BEGIN
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
WHILE (1 = 1)
BEGIN
SET @id = @id + 1
IF exists (SELECT id FROM SchemaChanges WHERE ID = @id)
BEGIN
SELECT @sqlStmt = SqlStmt FROM SchemaChanges WHERE ID = @id
EXEC sp_executesql @SqlStmt
UPDATE SchemaChangeHistory SET LastAppliedId = @id
END
ELSE
BREAK;
END
END
Dieser Trigger wird nach dem Einfügen ausgelöst und prüft, ob der aktuelle Befehl als Nächstes ausgeführt werden soll. Durch die Codelogik wird sichergestellt, dass keine Schemaänderungsanweisung übersprungen wird, und alle Änderungen werden übernommen, auch wenn die Reihenfolge beim Einfügen falsch ist.
Synchronisieren der Verfolgungstabelle für die Schemaänderungen an allen Endpunkten
Sie können die Verfolgungstabelle für die Schemaänderungen an allen Endpunkten synchronisieren, indem Sie die vorhandene oder eine neue Synchronisierungsgruppe verwenden. Stellen Sie sicher, dass die Änderungen in der Nachverfolgungstabelle mit allen Endpunkten synchronisiert werden können, insbesondere wenn Sie die Synchronisierung in eine Richtung in verwenden.
Synchronisieren Sie die Verlaufstabelle der Schemaänderungen nicht, da diese Tabelle an verschiedenen Endpunkten unterschiedliche Zustände beibehält.
Übernehmen der Schemaänderungen in einer Synchronisierungsgruppe
Es werden nur Schemaänderungen repliziert, die in der Datenbank vorgenommen wurden, in der der DDL-Trigger erstellt wird. In anderen Datenbanken vorgenommene Schemaänderungen werden nicht repliziert.
Nachdem die Schemaänderungen an allen Endpunkten repliziert wurden, müssen Sie zusätzliche Schritte unternehmen, um das Synchronisierungsschema zu aktualisieren, sodass die Synchronisierung der neuen Spalten gestartet bzw. beendet wird.
Hinzufügen von Spalten
Nehmen Sie die Schemaänderung vor.
Vermeiden Sie jede Datenänderung an den neuen Spalten, bis Sie den Schritt zum Erstellen des Triggers abgeschlossen haben.
Warten Sie, bis die Schemaänderungen für alle Endpunkte übernommen wurden.
Aktualisieren Sie das Datenbankschema, und fügen Sie die neue Spalte dem Synchronisierungsschema hinzu.
Die Daten in der neuen Spalte werden beim nächsten Synchronisierungsvorgang synchronisiert.
Entfernen von Spalten
Entfernen Sie die Spalten aus dem Synchronisierungsschema. Die Datensynchronisierung hält die Synchronisierung der Daten in diesen Spalten an.
Nehmen Sie die Schemaänderung vor.
Aktualisieren Sie das Datenbankschema.
Aktualisieren von Datentypen
Nehmen Sie die Schemaänderung vor.
Warten Sie, bis die Schemaänderungen für alle Endpunkte übernommen wurden.
Aktualisieren Sie das Datenbankschema.
Wenn der neue und der alte Datentyp nicht vollständig kompatibel sind, z. B. wenn Sie von
intzubigintwechseln, tritt möglicherweise ein Synchronisierungsfehler auf, bevor die Schritte zum Erstellen des Triggers abgeschlossen sind. Die Synchronisierung ist bei einem erneuten Versuch erfolgreich.
Umbenennen von Spalten oder Tabellen
Durch das Umbenennen von Spalten oder Tabellen wird die Datensynchronisierung angehalten. Erstellen Sie eine neue Tabelle oder Spalte, füllen Sie die Daten ein, und löschen Sie dann die alte Tabelle oder Spalte, anstatt sie umzubenennen.
Andere Typen von Schemaänderungen
Für andere Typen von Schemaänderungen – z.B. das Erstellen von gespeicherten Prozeduren oder das Löschen eines Indexes – ist das Aktualisieren des Synchronisierungsschemas nicht erforderlich.
Problembehandlung bei der automatisierten Replikation von Schemaänderungen
Die in diesem Artikel beschriebene Replikationslogik funktioniert in einigen Situationen nicht mehr. Dies ist z.B. der Fall, wenn Sie eine Schemaänderung in einer lokalen Datenbank vorgenommen haben, die in der Azure SQL-Datenbank-Instanz nicht unterstützt wird. Dann schlägt die Synchronisierung der Tabelle der Schemaänderungsnachverfolgung fehl. Dieses Problem muss manuell behoben werden:
Deaktivieren Sie den DDL-Trigger, und vermeiden Sie weitere Schemaänderungen, bis das Problem behoben ist.
Deaktivieren Sie in der Endpunktdatenbank, in der das Problem auftritt, den AFTER INSERT-Trigger an dem Endpunkt, an dem die Schemaänderung nicht vorgenommen werden kann. Durch diese Aktion kann der Schemaänderungsbefehl synchronisiert werden.
Lösen Sie den Synchronisierungsvorgang aus, um die Tabelle der Schemaänderungsnachverfolgung zu synchronisieren.
In der Endpunktdatenbank, in der das Problem auftritt, fragen Sie die Verlaufstabelle für die Schemaänderungen ab, um die ID des zuletzt angewandten Schemaänderungsbefehls zu erhalten.
Fragen Sie die Tabelle der Schemaänderungsnachverfolgung ab, um alle Befehle aufzulisten, deren ID größer ist als der ID-Wert, den Sie im vorherigen Schritt abgerufen haben.
a. Ignorieren Sie die Befehle, die in der Endpunktdatenbank nicht ausgeführt werden können. Es ist erforderlich, dass Sie sich mit der Schemainkonsistenz befassen. Nehmen Sie die Änderungen am ursprünglichen Schema zurück, wenn sich die Inkonsistenz auf Ihre Anwendung auswirkt.
b. Wenden Sie die Befehle, die angewendet werden sollen, manuell an.
Aktualisieren Sie die Verlaufstabelle für die Schemaänderungen, und setzen Sie die zuletzt verwendete ID auf den richtigen Wert.
Überprüfen Sie nochmals, ob das Schema aktuell ist.
Aktivieren Sie erneut den im zweiten Schritt deaktivierten AFTER INSERT-Trigger.
Aktivieren Sie erneut den im ersten Schritt deaktivierten DDL-Trigger.
Wenn Sie die Datensätze in der Tabelle der Schemaänderungsnachverfolgung bereinigen möchten, verwenden Sie DELETE anstelle von TRUNCATE. Führen Sie niemals ein erneutes Seeding für die Identitätsspalte in der Tabelle der Schemaänderungsnachverfolgung mithilfe von DBCC CHECKIDENT aus. Sie können neue Tabellen der Schemaänderungsnachverfolgung erstellen und den Tabellennamen im DDL-Trigger aktualisieren, wenn ein erneutes Seeding erforderlich ist.
Weitere Überlegungen
Datenbankbenutzer, die die Hub- und Mitgliederdatenbanken konfigurieren, müssen über ausreichende Berechtigungen verfügen, um die Schemaänderungsbefehle auszuführen.
Sie können weitere Filter im DDL-Trigger hinzufügen, um Schemaänderungen nur in ausgewählten Tabellen oder Vorgängen zu replizieren.
Sie können Schemaänderungen nur in der Datenbank vornehmen, in der der DDL-Trigger erste wird.
Wenn Sie eine Änderung in einer SQL Server-Datenbank vornehmen, stellen Sie sicher, dass die Schemaänderung in Azure SQL-Datenbank unterstützt wird.
Wenn Schemaänderungen in anderen Datenbanken als der Datenbank vorgenommen werden, in der der DDL-Trigger erstellt wird, werden die Änderungen nicht repliziert. Zur Vermeidung dieses Problems können Sie DDL-Trigger erstellen, um Änderungen an anderen Endpunkten zu blockieren.
Wenn Sie das Schema der Tabelle der Schemaänderungsnachverfolgung ändern müssen, deaktivieren Sie den DDL-Trigger, bevor Sie die Änderung vornehmen, und wenden Sie die Änderung dann manuell auf alle Endpunkte an. Das Aktualisieren des Schemas in einem AFTER INSERT-Trigger für die gleiche Tabelle funktioniert nicht.
Führen Sie kein erneutes Seeding der Identitätsspalte mit DBCC CHECKIDENT durch.
Verwenden Sie TRUNCATE nicht, um Daten in der Tabelle der Schemaänderungsnachverfolgung zu bereinigen.
Zugehöriger Inhalt
- Was ist die SQL-Datensynchronisierung für Azure?
- Tutorial: Einrichten der SQL-Datensynchronisierung zwischen Datenbanken in Azure SQL-Datenbank und SQL Server
- Verwenden von PowerShell zum Synchronisieren von Daten zwischen mehreren Datenbanken in Azure SQL-Datenbank
- Verwenden von PowerShell zum Synchronisieren von Daten zwischen SQL-Datenbank und SQL Server
- Data Sync Agent für die SQL-Datensynchronisierung
- Best practices for Azure SQL Data Sync (Preview) (Bewährte Methoden für die Azure SQL-Datensynchronisierung-Vorschauversion)
- Überwachung und Leistungsoptimierung in Azure SQL-Datenbank und Azure SQL Managed Instance
- Behandeln von Problemen mit der SQL-Datensynchronisierung
- Verwenden von PowerShell zum Aktualisieren des Synchronisierungsschemas in einer bestehenden Synchronisierungsgruppe