Konfigurieren einer Failovergruppe für eine verwaltete SQL-Instanz
Gilt für: ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In diesem Artikel wird erläutert, wie Sie eine Failover-Gruppe für Azure SQL Managed Instance über das Azure-Portal und Azure PowerShell konfigurieren.
Wenn Sie ein End-to-End-PowerShell-Skript zum Erstellen beider Instanzen innerhalb einer Failovergruppe benötigen, lesen Sie Instanz zu einer Failover-Gruppe mit PowerShell hinzufügen.
Voraussetzungen
Um eine Failover-Gruppe zu konfigurieren, sollten Sie bereits über erforderliche Berechtigungen oder eine SQL Managed Instance verfügen, die Sie als primäre Instanz einsetzen möchten. Lesen Sie Erstellen einer Instance als Erste Schritte.
Überprüfen Sie unbedingt die Einschränkungen, bevor Sie Ihre sekundäre Instanz und Failovergruppe erstellen.
Konfigurationsanforderungen
Um eine Failover-Gruppe zwischen einer primären und sekundären SQL-verwaltete Instance zu konfigurieren, berücksichtigen Sie die folgenden Anforderungen:
- Die sekundäre verwaltete Instanz muss leer sein und ohne Benutzerdatenbanken.
- Die beiden Instanzen müssen dieselbe Dienstebene und die gleiche Speichergröße aufweisen. Auch wenn dies nicht erforderlich ist, wird dringend empfohlen, dass beide Instanzen die gleiche Computegröße aufweisen, um sicherzustellen, dass die sekundäre Instanz Änderungen, die von der primären Instanz repliziert werden, dauerhaft verarbeiten kann, auch während Zeiten hoher Aktivität.
- Der Adressbereich für das virtuelle Netzwerk der primären Instanz darf sich nicht mit dem Adressbereich des virtuellen Netzwerks für die sekundäre verwaltete Instanz, die Sie erstellen möchten, und mit keinem anderen virtuellen Netzwerk, das mit dem primären oder sekundären virtuellen Netzwerk verbunden ist, überschneiden.
- Beide Instanzen müssen sich in derselben DNS-Zone befinden. Wenn Sie Ihre sekundäre verwaltete Instanz erstellen, müssen Sie die DNS-Zone-ID der primären Instanz spezifizieren. Wenn Sie sie nicht spezifizieren, wird die Zonen-ID als zufällige Zeichenfolge generiert, wenn die erste Instanz in jedem virtuellen Netzwerk erstellt wird, und dieselbe ID wird allen anderen Instanzen im selben Subnetz zugewiesen. Nach der Zuweisung kann die DNS-Zone nicht geändert werden.
- Regeln von Netzwerksicherheitsgruppen (Network Security Groups, NSG) für die Subnetze beider Instanzen müssen offene eingehende und ausgehende TCP-Verbindungen für Port 5022 und Portbereich 11000-11999 aufweisen, um die Kommunikation zwischen den beiden Instanzen zu erleichtern.
- Verwaltete Instanzen sollten aus Leistungsgründen für Regionspaare bereitgestellt werden. Verwaltete Instanzen, die sich in geografischen Regionspaaren befinden, profitieren im Vergleich zu nicht gekoppelten Regionen von einer deutlich höheren Geschwindigkeit der Georeplikation.
- Beide Instanzen müssen dieselbe Update-Richtlinie verwenden.
Erstellen der sekundären Instanz
Wenn Sie die sekundäre Instanz erstellen, müssen Sie ein Virtual Network verwenden, das über einen IP-Adressraum verfügt, der nicht mit dem IP-Adressraumbereich der primären Instanz überlappt. Wenn Sie die neue sekundäre Instanz konfigurieren, müssen Sie außerdem die Zonen-ID der primären Instanz angeben.
Sie können das sekundäre Virtual Network konfigurieren und die sekundäre Instance mithilfe der Azure-Portal und PowerShell erstellen.
Virtuelles Netzwerk erstellen
Um ein Virtual Network für Ihre sekundäre Instanz im Azure-Portal zu erstellen, gehen Sie wie folgt vor:
Überprüfen Sie den Adressraum für die primäre Instance. Gehen Sie zu der virtuellen Netzwerkressource für die primäre Instanz im Azure-Portal und wählen Sie unter Einstellungen Adressraum. Überprüfen Sie den Bereich unter Adressbereich:
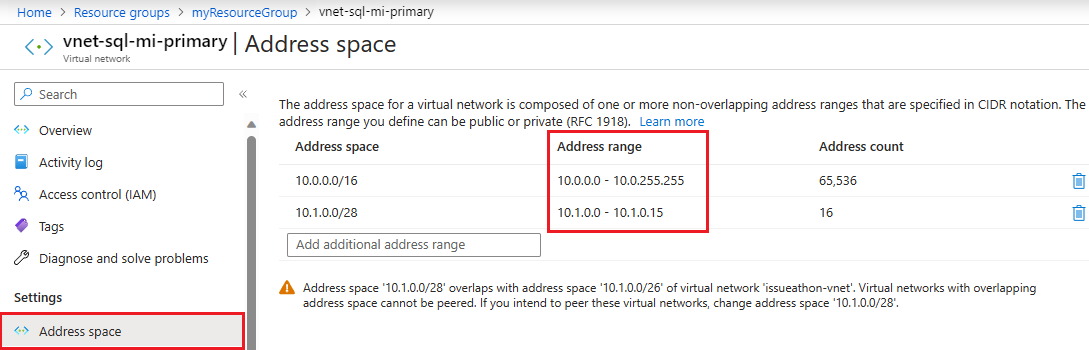
Erstellen Sie ein neues Virtual Network, das Sie für die sekundäre Instance verwenden möchten, indem Sie zur Seite Virtual Network erstellen wechseln.
Auf der Registerkarte Grundeinstellungen auf der Seite Virtual Network erstellen:
- Wählen Sie die Ressourcengruppe aus, die Sie für die sekundäre Instance verwenden möchten. Erstellen Sie einen neuen, falls noch keiner vorhanden ist.
- Geben Sie unter Name einen Namen für Ihr virtuelles Netzwerk an, wie zum Beispiel
vnet-sql-mi-secondary. - Wählen Sie einen Bereich aus, der mit dem Bereich gekoppelt ist, in dem sich die primäre Instance befindet.
Auf der Registerkarte IP-Adressen auf der Seite Virtual Network erstellen:
- Verwenden Sie Adressraum löschen, um den vorhandenen IPv4-Adressraum zu löschen.
- Nachdem der Adressraum gelöscht wurde, wählen Sie IPv4-Adressraum hinzufügen aus, um einen neuen Speicherplatz hinzuzufügen, und geben Sie dann einen IP-Adressraum an, der sich vom Virtual Network der primären Instance unterscheidet. Wenn Ihre aktuelle primäre Instance beispielsweise einen Adressraum von 10.0.0.16 verwendet, geben Sie
10.1.0.0/16für den Adressraum des Virtual Network ein, das Sie für die sekundäre Instance verwenden möchten. - Verwenden Sie + Ein Subnetz hinzufügen, um ein Standardsubnetz mit Standardwerten hinzuzufügen.
- Verwenden Sie + Fügen Sie ein Subnetz hinzu, um ein leeres Subnetz mit Namen
ManagedInstancehinzuzufügen, das der sekundären Instance zugewiesen wird, wobei ein Adressbereich verwendet wird, der sich vom Standardsubnetz unterscheidet. Wenn Ihre primäre Instance beispielsweise einen Adressbereich von 10.0.0.0 -10.0.255.255 verwendet, stellen Sie einen Subnetzbereich von10.1.1.0 - 10.1.1.255für das Subnetz der sekundären Instance bereit.

Verwenden Sie Überprüfen + Erstellen, um die Einstellungen zu überprüfen, und wählen Sie anschließend Erstellen aus, um Ihr neues Virtual Network zu erstellen.

Erstellen sekundäre Instanz
Nachdem Ihr Virtual Network fertig ist, führen Sie die folgenden Schritte aus, um ihre sekundäre Instance im Azure-Portal zu erstellen:
Navigieren Sie zu Erstellen einer Instanz von Azure SQL Managed Instance im Azure-Portal.
Auf der Registerkarte Grundlagen auf der Seite Azure SQL Managed Instance erstellen:
- Wählen Sie eine Region für Ihre sekundäre Instance aus, die mit der primären Instanz gekoppelt ist.
- Wählen Sie eine Dienstebene aus, die der Dienstebene der primären Instance entspricht.
Verwenden Sie auf der Registerkarte Netzwerk auf der Seite Azure SQL Managed Instance erstellen die Dropdownliste unter Virtual Network/Subnetz, um das virtuelle Netzwerk und das zuvor erstellte Subnetz auszuwählen:

Wählen Sie auf der Registerkarte Zusätzliche Einstellungen auf der Seite Azure SQL Managed Instance erstellen Ja aus, um als sekundäres Failover zu verwenden, und wählen Sie dann in der Dropdownliste die entsprechende primäre Instance aus.
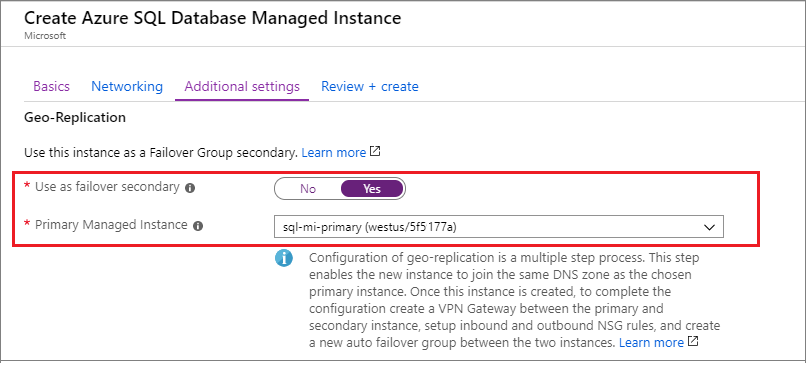
Konfigurieren Sie den Rest der Instance entsprechend Ihren geschäftlichen Anforderungen und erstellen Sie sie dann mithilfe von Überprüfen + Erstellen.

Herstellen der Verbindung zwischen den Instanzen
Um einen unterbrechungsfreien Datenfluss bei der Georeplikation zu gewährleisten, müssen Sie die Konnektivität zwischen den virtuellen Netzwerk-Subnetzen herstellen, in denen die primäre und die sekundäre Instance untergebracht sind. Es gibt mehrere Möglichkeiten verwaltete Instanzen in verschiedenen Azure-Regionen zu verbinden, darunter:
- Globales Peering virtueller Netzwerke
- Azure ExpressRoute
- VPN-Gateways
Globales Peering virtueller Netzwerke wird als die leistungsfähigste und robusteste Methode zum Einrichten der Konnektivität empfohlen. Es bietet eine private Verbindung mit geringer Latenz und hoher Bandbreite zwischen virtuellen Netzwerken mit Peering mithilfe der Microsoft-Backbone-Infrastruktur. Für die Kommunikation zwischen virtuellen Netzwerken mit Peering werden kein öffentliches Internet, keine Gateways und keine zusätzliche Verschlüsselung benötigt.
Wichtig
Alternative Methoden zum Verbinden von Instanzen, die zusätzliche Netzwerkgeräte umfassen, können die Problembehandlung bei Der Konnektivität oder Replikationsgeschwindigkeit erschweren, möglicherweise die aktive Einbindung von Netzwerkadministratoren und potenziell eine erhebliche Verlängerung der Auflösungszeit.
Wenn Sie einen anderen Mechanismus zur Herstellung der Konnektivität zwischen den Instanzen verwenden als das empfohlene globale Peering virtueller Netzwerke, stellen Sie Folgendes sicher:
- Netzwerkgeräte wie Firewalls oder virtuelle Netzwerkgeräte (VIRTUAL Appliances, NVAs) blockieren keinen Datenverkehr für eingehende und ausgehende Verbindungen für Port 5022 (TCP) und Portbereich 11000-11999.
- Das Routing ist ordnungsgemäß konfiguriert, und asymmetrisches Routing wird vermieden.
- Wenn Sie Failover-Gruppen in einer regionsübergreifenden Hub-and-Spoke-Netzwerktopologie bereitstellen, um Konnektivitäts- und Replikationsgeschwindigkeitsprobleme zu vermeiden, sollte der Replikationsverkehr direkt zwischen den beiden Subnetzen verwalteter Instanzen und nicht über die Hubnetzwerke geleitet werden.
Dieser Artikel führt Sie zum Konfigurieren des globalen Peerings virtueller Netzwerke zwischen den Netzwerken der beiden Instanzen mithilfe von Azure-Portal und PowerShell.
Navigieren Sie im Azure-Portal zur Ressource Virtuelles Netzwerk für Ihre primäre verwaltete Instanz.
Wählen Sie Peerings unter Einstellungen aus, um die Seite Peerings zu öffnen, und verwenden Sie dann +Hinzufügen in der Befehlsleiste, um die Seite Peering hinzufügen zu öffnen.
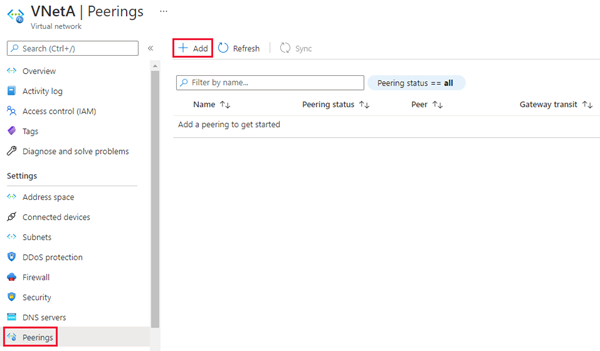
Geben Sie auf der Seite Peering hinzufügen Werte für folgende Einstellungen ein, oder wählen Sie sie aus:
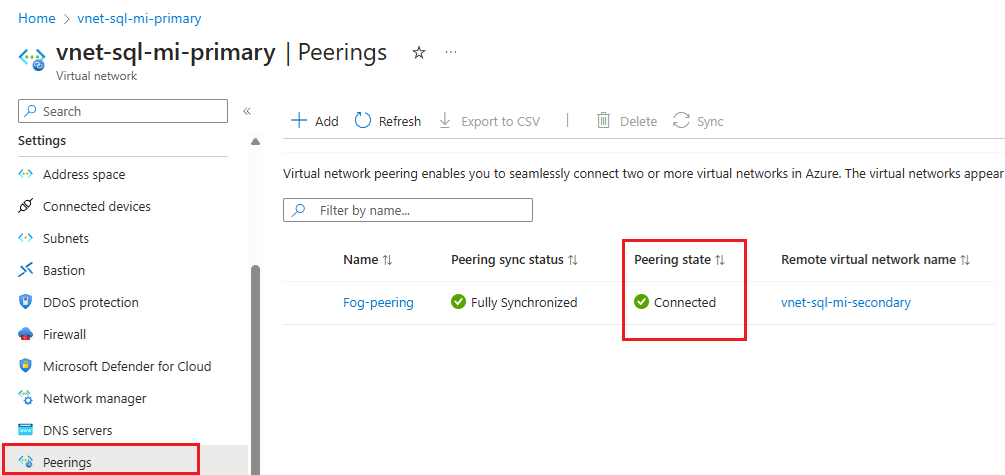
Einstellungen Beschreibung Zusammenfassung zu virtuellen Remotenetzwerken Name des Peeringlinks Der Name für das Peering muss innerhalb des virtuellen Netzwerks eindeutig sein. In diesem Artikel wird Fog-peeringverwendet.Bereitstellungsmodell für das virtuelle Netzwerk Wählen Sie Ressourcen-Manager aus. Ich kenne meine Ressourcen-ID Sie können dieses Kontrollkästchen deaktiviert lassen, es sei denn, Sie kennen die Ressourcen-ID. Abonnement Wählen Sie in der Dropdownliste Abonnement aus. Virtuelles Netzwerk Wählen Sie in der Dropdownliste das Virtual Network für die sekundäre Instance aus. Einstellungen für das Peering virtueller Remotenetzwerke Zulassen des „sekundären Virtual Network“ für den Zugriff auf das „primäre Virtual Network“ Aktivieren Sie das Kontrollkästchen, um die Kommunikation zwischen den beiden Netzwerken zuzulassen. Durch die Aktivierung der Kommunikation zwischen virtuellen Netzwerken können Ressourcen, die mit einem der beiden virtuellen Netzwerke verbunden sind, mit derselben Bandbreite und Latenz kommunizieren, als ob sie mit demselben virtuellen Netzwerk verbunden wären. Die gesamte Kommunikation zwischen Ressourcen in den beiden virtuellen Netzwerken erfolgt über das private Azure-Netzwerk. Zulassen des „sekundären Virtual Network“ zum Erhalten von weitergeleitetem Datenverkehr vom „primären Virtual Network“ Sie können dieses Kontrollkästchen entweder aktivieren oder deaktivieren. Dies funktioniert entweder für diesen Leitfaden. Weitere Informationen finden Sie unter Erstellen eines Peerings. Zulassen des Gateway oder Routing-Servers in „sekundäres Virtual Network“, um Datenverkehr an das „primäre Virtual Network“ weiterleiten Sie können dieses Kontrollkästchen entweder aktivieren oder deaktivieren. Dies funktioniert entweder für diesen Leitfaden. Weitere Informationen finden Sie unter Erstellen eines Peerings. Aktivieren Sie „sekundäres Virtual Network“, um das Remote-Gateway oder den Routenserver des „primären Virtual Network“ zu verwenden Lassen Sie dieses Kontrollkästchen deaktiviert. Weitere Informationen zu den anderen verfügbaren Optionen finden Sie unter Erstellen eines Peerings. Lokales virtuelles Netzwerk: Zusammenfassung Name des Peeringlinks Der Name des gleichen Peerings, das für das virtuelle Remotenetzwerk verwendet wurde. In diesem Artikel wird Fog-peeringverwendet.Zulassen des „primären Virtual Network“ für den Zugriff auf das „sekundäre Virtual Network“ Aktivieren Sie das Kontrollkästchen, um die Kommunikation zwischen den beiden Netzwerken zuzulassen. Durch die Aktivierung der Kommunikation zwischen virtuellen Netzwerken können Ressourcen, die mit einem der beiden virtuellen Netzwerke verbunden sind, mit derselben Bandbreite und Latenz kommunizieren, als ob sie mit demselben virtuellen Netzwerk verbunden wären. Die gesamte Kommunikation zwischen Ressourcen in den beiden virtuellen Netzwerken erfolgt über das private Azure-Netzwerk. Zulassen des „primären Virtual Network“ zum Erhalten von weitergeleitetem Datenverkehr vom „sekundären Virtual Network“ Sie können dieses Kontrollkästchen entweder aktivieren oder deaktivieren. Dies funktioniert entweder für diesen Leitfaden. Weitere Informationen finden Sie unter Erstellen eines Peerings. Zulassen des Gateway oder Routing-Servers in „primäres Virtual Network“, um Datenverkehr an das „ sekundäre Virtual Network“ weiterleiten Sie können dieses Kontrollkästchen entweder aktivieren oder deaktivieren. Dies funktioniert entweder für diesen Leitfaden. Weitere Informationen finden Sie unter Erstellen eines Peerings. Aktivieren Sie „primäres Virtual Network“, um das Remote-Gateway oder den Routenserver des „sekundären Virtual Network“ zu verwenden Lassen Sie dieses Kontrollkästchen deaktiviert. Weitere Informationen zu den anderen verfügbaren Optionen finden Sie unter Erstellen eines Peerings. Verwenden Sie Hinzufügen, um Peering mit dem von Ihnen ausgewählten virtuellen Netzwerk zu konfigurieren, und navigieren Sie automatisch zur Seite Peerings, auf der die beiden Netzwerke verbunden sind:
Konfigurieren von Ports und NSG-Regeln
Unabhängig vom gewählten Verbindungsmechanismus zwischen den beiden Instanzen müssen Ihre Netzwerke die folgenden Anforderungen für den Fluss des Georeplikationsdatenverkehrs erfüllen:
- Die Routingtabelle und Netzwerksicherheitsgruppen, die den Subnetzen der verwalteten Instanzen zugewiesen sind, werden nicht von den beiden virtuellen Netzwerken mit Peer-Rechten gemeinsam genutzt.
- Die NSG-Regeln (Network Security Group) für beide Subnetze, die jede Instance hosten, ermöglichen sowohl eingehenden als auch ausgehenden Datenverkehr an die andere Instance am Port 5022 und den Portbereich 11000-11999.
Sie können die Port-Kommunikation und NSG-Regeln mithilfe von Azure-Portal und PowerShell konfigurieren.
Führen Sie die folgenden Schritte aus, um die NSG-Ports (Network Security Group) im Azure-Portal zu öffnen:
Wechseln Sie zur Netzwerksicherheitsgruppenressource für die primäre Instance.
Wählen Sie unter Einstellungen die Option Eingangssicherheitsregeln. Überprüfen Sie, ob Sie bereits Regeln haben, die Datenverkehr für Port 5022 und den Bereich 11000-11999 zulassen. Wenn Sie dies tun und die Quelle Ihren geschäftlichen Anforderungen entspricht, überspringen Sie diesen Schritt. Wenn die Regeln nicht vorhanden sind oder Sie eine andere Quelle (z. B. die sicherere IP-Adresse) verwenden möchten, löschen Sie die vorhandene Regel, und wählen Sie dann auf der Befehlsleiste + Hinzufügen aus, um den Bereich Eingangssicherheitsregel hinzufügen zu öffnen:

Geben Sie im Bereich Eingangssicherheitsregel hinzufügen Werte für die folgenden Einstellungen ein bzw. wählen Sie diese aus:
Einstellungen Empfohlener Wert Beschreibung Grundlage IP-Adresse oder beliebiges Diensttag Der Filter für die Quelle der Kommunikation. Die IP-Adresse ist die sicherste und wird für Produktionsumgebungen empfohlen. Das Diensttag ist für Nichtproduktionsumgebungen geeignet. Quelldiensttag Wenn Sie das Diensttag als Quelle ausgewählt haben, geben Sie VirtualNetworkals Quellen-Tag an.Standardtags sind vordefinierte Bezeichner, die eine Kategorie von IP-Adressen darstellen. Das VirtualNetwork-Tag zeigt alle virtuellen und lokalen Netzwerkadressräume an. Quell-IP-Adressen Wenn Sie IP-Adressen als Quelle ausgewählt haben, geben Sie die IP-Adresse der sekundären Instance an. Geben Sie einen Adressbereich mithilfe der CIDR-Notation an (z. B. 192.168.99.0/24 oder 2001:1234::/64), oder eine IP-Adresse (z. B. 192.168.99.0 oder 2001:1234::). Sie können auch eine durch Kommas getrennte Liste von IP-Adressen oder Adressbereichen mit entweder IPv4 oder IPv6 bereitstellen. Quellportbereiche 5022 Dies gibt an, für welche Ports dieser Regel Datenverkehr zulässig ist. Dienst Benutzerdefiniert Der Dienst gibt das Zielprotokoll und den Portbereich für diese Regel an. Zielportbereiche 5022 Dies gibt an, für welche Ports dieser Regel Datenverkehr zulässig ist. Dieser Port sollte mit dem Quell-Port-Bereich übereinstimmen. Aktion Zulassen Kommunikation über den angegebenen Port zulassen. Protokoll TCP Bestimmt das Protokoll für die Port-Kommunikation. Priorität 1200 Regeln werden in der Reihenfolge der Priorität verarbeitet: je niedriger die Zahl, desto höher die Priorität. Name allow_geodr_inbound Der Name der Regel. Beschreibung Optional Sie können eine Beschreibung angeben oder dieses Feld leer lassen. Wählen Sie Hinzufügen aus, um Ihre Einstellungen zu speichern und die neue Regel hinzuzufügen.
Wiederholen Sie diese Schritte, um eine weitere eingehende Sicherheitsregel für den Portbereich
11000-11999mit einem Namen wie allow_redirect_inbound und einer Priorität hinzuzufügen, die etwas höher als die 5022-Regel ist, z. B.1100.Wählen Sie unter Einstellungen die Option Sicherheitsregeln für ausgehenden Datenverkehr aus. Überprüfen Sie, ob Sie bereits Regeln haben, die Datenverkehr für Port 5022 und den Bereich 11000-11999 zulassen. Wenn Sie dies tun und die Quelle Ihren geschäftlichen Anforderungen entspricht, überspringen Sie diesen Schritt. Wenn die Regeln nicht vorhanden sind oder Sie eine andere Quelle (z. B. die sicherere IP-Adresse) verwenden möchten, löschen Sie die vorhandene Regel, und wählen Sie dann auf der Befehlsleiste +Hinzufügen aus, um den Bereich Ausgangssicherheitsregel hinzufügen zu öffnen.
Verwenden Sie im Bereich Ausgangssicherheitsregel hinzufügen dieselbe Konfiguration für Port 5022 und den Bereich
11000-11999wie für die eingehenden Ports.Wechseln Sie zur Netzwerksicherheitsgruppe für die sekundäre Instance und wiederholen Sie diese Schritte, damit beide Netzwerksicherheitsgruppen die folgenden Regeln haben:
- Lassen Sie eingehenden Datenverkehr an Port 5022 zu
- Eingehenden Datenverkehr im Port-Bereich
11000-11999zulassen - Lassen Sie ausgehenden Datenverkehr an Port 5022 zu
- Ausgehenden Datenverkehr im Port-Bereich
11000-11999zulassen
Erstellen der Failovergruppe
Erstellen Sie die Failovergruppe für Ihre verwalteten Instanzen mithilfe des Azure-Portals oder PowerShell.
Erstellen Sie die Failovergruppe für Ihre verwalteten Azure SQL-Instanzen mithilfe des Azure-Portals.
Wählen Sie im linken Menü im Azure-Portal die Option Azure SQL aus. Wenn Azure SQL nicht in der Liste aufgeführt wird, wählen Sie Alle Dienste aus, und geben Sie dann im Suchfeld „Azure SQL“ ein. (Optional) Wählen Sie den Stern neben Azure SQL aus, um es als bevorzugtes Element im linken Navigationsbereich hinzuzufügen.
Wählen Sie die primäre verwaltete Instanz aus, die Sie der Failovergruppe hinzufügen möchten.
Wählen Sie unter Datenverwaltung Failover-Gruppen und verwenden Sie dann Gruppe hinzufügen, um die Seite Instance-Failover-Gruppe zu öffnen:
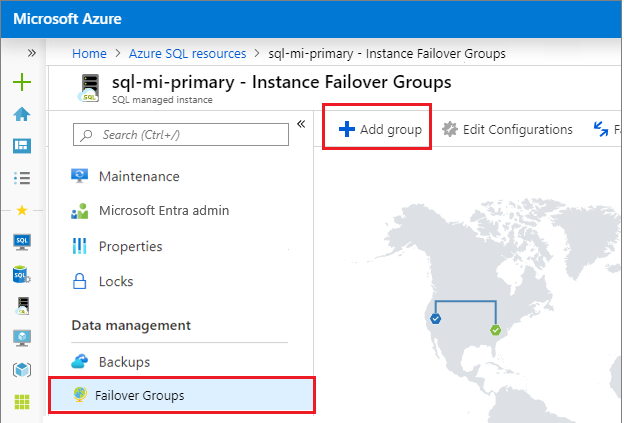
Auf der Seite Instance-Failover-Gruppe:
- Die primäre verwaltete Instanz ist vorab ausgewählt.
- Geben Sie unter dem Namen der Failover-Gruppe einen Namen für die Failover-Gruppe ein.
- Wählen Sie unter der sekundären verwalteten Instanz die verwaltete Instanz aus, die Sie als sekundäre Instanz in der Failover-Gruppe verwenden möchten.
- Wählen Sie eine Lese- /Schreib-Failover-Richtlinie aus der Dropdownliste aus. Manuell wird empfohlen, um die Kontrolle über Failover zu haben.
- Lassen Sie Failover-Rechte aktivieren auf Aus, es sei denn, Sie möchten dieses Replikat nur für die Notfallwiederherstellung verwenden.
- Verwenden Sie Erstellen, um Ihre Einstellungen zu speichern und Ihre Failover-Gruppe zu erstellen.
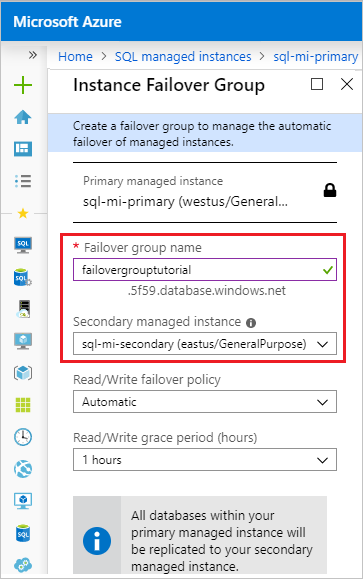
Nachdem die Bereitstellung der Failover-Gruppe startet, gelangen Sie erneut auf die Seite Failover-Gruppen. Die Seite wird aktualisiert, um die neue Failover-Gruppe nach Abschluss der Bereitstellung anzuzeigen.
Testfailover
Testen Sie das Failover Ihrer Failover-Gruppe mithilfe des Azure-Portals oder PowerShell.
Hinweis
Wenn sich die Instanzen in verschiedenen Abonnements oder Ressourcengruppen befinden, initiieren Sie das Failover von der sekundären Instance.
Testen Sie das Failover Ihrer Failovergruppe mithilfe des Azure-Portals.
Wechseln Sie entweder zur primären oder sekundären verwalteten Instanz innerhalb des Azure-Portals.
Wählen Sie unter Datenverwaltung die Option Failovergruppen aus.
Beachten Sie im Bereich Failover-Gruppen, welche Instanz die primäre Instanz ist und welche Instanz die sekundäre Instanz ist.
Wählen Sie im Bereich Failover-Gruppen die Option Failover in der Befehlsleiste aus. Wählen Sie Ja aus, wenn TDS-Sitzungen getrennt werden, und notieren Sie sich die Lizenzierungsimplikation.
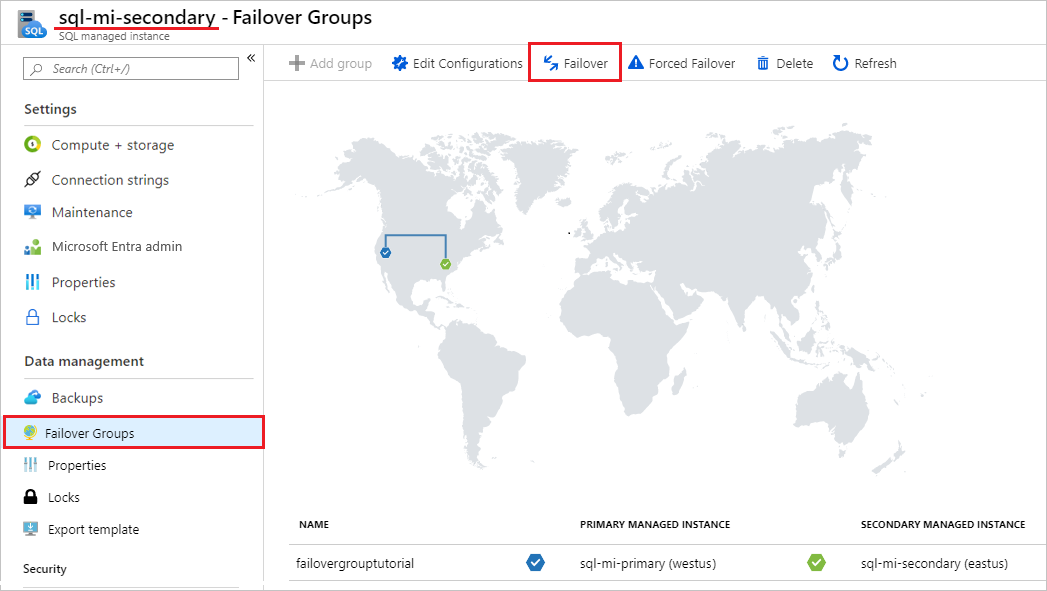
Im Bereich Failover-Gruppen wechselt die Instanz nach erfolgreichem Failover die Rollen, sodass die vorherige sekundäre zur neuen primären Instanz und die vorherige primäre zur neuen sekundären Instanz wird.
Wichtig
Wenn die Rollen nicht gewechselt wurden, überprüfen Sie die Konnektivität zwischen den Instanzen und den zugehörigen NSG- und Firewall-Regeln. Fahren Sie erst nach dem Rollenwechsel mit dem nächsten Schritt fort.
(Optional) Verwenden Sie im Bereich Failover-Gruppen die Option Failover, um die Rollen wieder zurück zu wechseln, damit die ursprüngliche primäre Instanz wieder die primäre Instanz wird.

Vorhandene Failovergruppe verändern
Sie können eine vorhandene Failovergruppe verändern, z. B. um die Failoverrichtlinie zu ändern, indem Sie Azure-Portal, PowerShell, Azure CLI und REST-APIs verwenden.
Um eine vorhandenen Failovergruppe über das Azure-Portal zu verändern, befolgen Sie diese Schritte:
Navigieren Sie im Azure-Portal zu Ihrer Instanz von SQL Managed Instance.
Wählen Sie unter Datenverwaltung die Option Failovergruppen aus, um den Bereich Failovergruppen zu öffnen.
Wählen Sie im Bereich Failovergruppen in der Befehlsleiste die Option Konfigurationen bearbeiten aus, um den Bereich Failovergruppe bearbeiten zu öffnen:

Listenerendpunkt suchen
Aktualisieren Sie nach der Konfiguration der Failover-Gruppe die Verbindungszeichenfolge für Ihre Anwendung so, dass sie auf den Lese-/Schreib-Listener-Endpunkt verweist, damit ihre Anwendung weiterhin eine Verbindung mit der Instance herstellt, die nach dem Failover primär ist. Wenn Sie den Listener-Endpunkt verwenden, müssen Sie Ihre Verbindungszeichenfolge nicht jedes Mal, wenn Ihre Failover-Gruppe fehlschlägt, manuell aktualisieren, da der Datenverkehr immer an die aktuelle primäre Stelle weitergeleitet wird. Sie können auch auf den Schreibgeschützten Listener-Endpunkt verweisen.
Wichtig
Obwohl die Verbindung mit einer Instanz in einer Failovergruppe mithilfe der instanzspezifischen Verbindungszeichenfolge unterstützt wird, wird dringend davon abgeraten. Verwenden Sie stattdessen die Listenerendpunkte.
Um den Listener-Endpunkt im Azure-Portal zu finden, wechseln Sie zu Ihrer verwalteten SQL-Instanz und wählen Sie unter Datenverwaltung Failover-Gruppen aus.
Scrollen Sie nach unten, um die Listener-Endpunkte zu finden:
- Der Lese-/Schreib-Listener-Endpunkt in Form von
fog-name.dns-zone.database.windows.netleitet den Datenverkehr an die primäre Instance weiter. - Der Schreibgeschützte Listener-Endpunkt in Form von
fog-name.secondary.dns-zone.database.windows.netleitet Datenverkehr an die sekundäre Instance weiter.

Erstellen einer Failovergruppe zwischen Instanzen in verschiedenen Subscriptions
Sie können eine Failovergruppe zwischen SQL Managed Instances in zwei verschiedenen Subscriptions erstellen, solange Subscriptions dem gleichen Microsoft Entra-Mandanten zugeordnet sind.
- Wenn Sie die PowerShell-API verwenden, können Sie dazu den Parameter
PartnerSubscriptionIdfür die sekundäre SQL Managed Instance angeben. - Wenn Sie die REST-API verwenden, kann jede im Parameter
properties.managedInstancePairsenthaltene Instanz-ID eine eigene Subscription-ID haben. - Das Erstellen von Failover-Gruppen über verschiedene Subscriptions hinweg wird im Azure-Portal nicht unterstützt.
Wichtig
Das Erstellen von Failovergruppen über verschiedene Subscriptions hinweg wird im Azure-Portal nicht unterstützt. Für die Failovergruppen in verschiedenen Subscriptions oder Ressourcengruppen kann das Failover von der primären Instanz von SQL Managed Instance aus nicht manuell im Azure-Portal initiiert werden. Initiieren Sie das Failover stattdessen über die sekundäre Geoinstanz.
Verhinderung des Verlusts kritischer Daten
Aufgrund der hohen Latenzzeit von WANs verwendet die Georeplikation einen asynchronen Replikationsmechanismus. Bei der asynchronen Replikation ist die Möglichkeit eines Datenverlusts unvermeidbar, wenn die primäre Datenbank ausfällt. Zum Schutz kritischer Transaktionen vor Datenverlust, kann ein Anwendungsentwickler die gespeicherte Prozedur sp_wait_for_database_copy_sync unmittelbar nach dem Commit der Transaktion aufrufen. Der Aufruf von sp_wait_for_database_copy_sync blockiert den aufrufenden Thread, bis die letzte committete Transaktion übertragen und im Transaktionsprotokoll der sekundären Datenbank gehärtet wurde. Er wartet jedoch nicht darauf, dass die übertragenen Transaktionen in der sekundären Datenbank wiedergegeben (wiederholt) werden. sp_wait_for_database_copy_sync ist auf eine bestimmte Georeplikationslink beschränkt. Jeder Benutzer mit den Rechten zum Herstellen der Verbindung mit der primären Datenbank kann diese Prozedur aufrufen.
Hinweis
sp_wait_for_database_copy_sync verhindert Datenverluste nach einem Geofailover für bestimmte Transaktionen, garantiert aber keine vollständige Synchronisierung für Lesezugriffe. Die durch einen sp_wait_for_database_copy_sync-Prozeduraufruf verursachte Verzögerung kann beträchtlich sein und hängt von der Größe des noch nicht übertragenen Transaktionsprotokolls auf der Primärseite zum Zeitpunkt des Aufrufs ab.
Ändern der sekundären Region
Angenommen, Instanz A ist die primäre Instanz, Instanz B die vorhandene sekundäre Instanz und Instanz C die neue sekundäre Instanz in der dritten Region. Führen Sie diese Schritte aus, um die Umstellung durchzuführen:
- Erstellen Sie Instanz C mit der gleichen Größe wie A und in derselben DNS-Zone.
- Löschen Sie die Failovergruppe zwischen den Instanzen A und B. An diesem Punkt treten bei Anmeldungen Fehler auf, weil die SQL-Aliase für die Failovergruppenlistener gelöscht wurden und das Gateway den Namen der Failovergruppe nicht erkennt. Die sekundären Datenbanken werden von den primären Replikaten getrennt und werden zu Datenbanken mit Lese-/Schreibzugriff.
- Erstellen Sie eine Failovergruppe mit dem gleichen Namen zwischen Instanz A und C. Befolgen Sie die Anleitung im Tutorial zu Failovergruppen mit verwalteten Instanzen. Dies ist ein Vorgang, bei dem der Umfang der Daten eine Rolle spielt. Er ist abgeschlossen, wenn für alle Datenbanken von Instanz A das Seeding und die Synchronisierung durchgeführt wurde.
- Löschen Sie Instanz B, wenn sie nicht benötigt wird, um unnötige Kosten zu vermeiden.
Hinweis
Nach Schritt 2 und bis zum Abschluss von Schritt 3 sind die Datenbanken auf Instanz A vor dem Ausfall von Instanz A aufgrund eines Katastrophenfalls ungeschützt.
Ändern der primären Region
Angenommen, Instanz A ist die primäre Instanz, Instanz B die vorhandene sekundäre Instanz und Instanz C die neue primäre Instanz in der dritten Region. Führen Sie diese Schritte aus, um die Umstellung durchzuführen:
- Erstellen Sie Instanz C mit der gleichen Größe wie B und in derselben DNS-Zone.
- Initiieren Sie ein manuelles Failover von Instanz B, um es zur neuen primären Instanz zu machen. Instanz A wird automatisch zur neuen sekundären Instanz.
- Löschen Sie die Failovergruppe zwischen den Instanzen A und B. An diesem Punkt treten bei Anmeldeversuchen, die Failovergruppenendpunkte verwenden, Fehler auf. Die sekundären Datenbanken auf A werden von den primären Datenbanken getrennt und werden zu Datenbanken mit Lese-/Schreibzugriff.
- Erstellen Sie eine Failover-Gruppe mit demselben Namen zwischen Instance B und C. Dies ist ein Datengrößevorgang und wird abgeschlossen, wenn für alle Datenbanken aus Instance B mit Instance C das Seeding und die Synchronisierung durchgeführt wurde. An diesem Punkt können Anmeldeversuche nicht mehr erfolgreich sein.
- Führen Sie ein manuelles Failover durch, um für die C-Instanz zur primären Rolle zu wechseln. Instanz B wird automatisch zur neuen sekundären Instanz.
- Löschen Sie Instanz A, wenn sie nicht benötigt wird, um unnötige Kosten zu vermeiden.
Achtung
Nach Schritt 3 und bis zum Abschluss von Schritt 4 sind die Datenbanken auf Instanz A vor dem Ausfall von Instanz A aufgrund eines Katastrophenfalls ungeschützt.
Wichtig
Wenn die Failovergruppe gelöscht wird, werden auch die DNS-Einträge für die Listenerendpunkte gelöscht. An diesem Punkt ist nicht völlig ausgeschlossen, dass eine andere Person eine Failovergruppe mit dem gleichen Namen erstellt. Da Failovergruppennamen global eindeutig sein müssen, wird verhindert, dass Sie denselben Namen noch mal verwenden. Verwenden Sie keine generischen Namen für Failovergruppen um dieses Risiko zu minimieren.
Ändern der Updaterichtlinie
Instanzen in einer Failovergruppe müssen über übereinstimmende Updaterichtlinien verfügen. Um die Always-up-to-date-Updaterichtlinie für Instanzen zu aktivieren, die Teil einer Failovergruppe sind, aktivieren Sie zuerst die Always-up-to-date-Updaterichtlinie für die sekundäre Instanz. Warten Sie, bis die Änderung wirksam wird, und aktualisieren Sie dann die Richtlinie für die primäre Instanz.
Das Ändern der Updaterichtlinie auf der primären Instanz in der Failovergruppe führt zwar zum Failover der Instanz auf einen anderen lokalen Knoten (ähnlich wie bei Verwaltungsvorgängen auf Instanzen, die nicht Teil einer Failovergruppe sind), aber nicht zum Failover der Failovergruppe, so dass die primäre Instanz in der primären Rolle bleibt.
Achtung
Nachdem die aktualisierte Richtlinie auf Always-up-to-date geändert wurde, ist es nicht mehr möglich, sie wieder in die SQL Server 2022-Update-Richtlinie zu ändern.
Aktivieren von Szenarien in Abhängigkeit von Objekten in den Systemdatenbanken
Systemdatenbanken werden nicht in die sekundäre Instanz in einer Failovergruppe repliziert. Um Szenarien zu ermöglichen, in denen Objekte aus den Systemdatenbanken erforderlich sind, stellen Sie sicher, dass diese Objekte in der sekundären Instanz erstellt werden, und synchronisieren Sie sie mit der primären Instanz.
Wenn Sie beispielsweise in der sekundären Instanz die gleichen Anmeldungen nutzen möchten, stellen Sie sicher, dass sie mit identischer SID erstellt werden.
-- Code to create login on the secondary instance
CREATE LOGIN foo WITH PASSWORD = '<enterStrongPasswordHere>', SID = <login_sid>;
Weitere Informationen finden Sie unter Azure SQL Managed Instance – Sync Agent Jobs and Logins in Failover Groups (Azure SQL Managed Instance: Synchronisieren von Agent-Aufträgen und Anmeldungen bei Failovergruppen).
Synchronisieren von Instanzeigenschaften und Aufbewahrungsrichtlinien
Instanzen in einer Failovergruppe bleiben separate Azure-Ressourcen, und Änderungen an der Konfiguration der primären Instanz werden nicht automatisch in die sekundäre Instanz repliziert. Stellen Sie sicher, dass Sie alle relevanten Änderungen in der primären und der sekundären Instanz vornehmen. Wenn Sie beispielsweise die Sicherungsspeicherredundanz oder die Richtlinie für die langfristige Sicherungsaufbewahrung für die primäre Instanz ändern, stellen Sie sicher, dass Sie sie auch in der sekundären Instanz ändern.
Skalieren von Instanzen
Sie können die primäre und sekundäre Instanz auf eine andere Computegröße innerhalb derselben Dienstebene oder auf eine andere Dienstebene hoch- oder herunterskalieren. Beim Hochskalieren innerhalb derselben Dienstebene sollten Sie zunächst die geo-sekundäre und dann die primäre Instanz hochskalieren. Beim Herunterskalieren innerhalb derselben Dienstebene gehen Sie in umgekehrter Reihenfolge vor: Skalieren Sie zuerst die primäre Datenbank herunter, dann die sekundäre Datenbank. Folgen Sie derselben Reihenfolge, wenn Sie eine Instanz auf eine andere Dienstebene skalieren.
Diese Reihenfolge ist zur Vermeidung von Problemen empfehlenswert, die dadurch entstehen, dass die geo-sekundäre Instanz bei einer niedrigeren SKU überlastet wird und beim Upgrade- oder Downgradevorgang ein erneutes Seeding durchgeführt werden muss.
Berechtigungen
Berechtigungen für eine Failovergruppe werden über die rollenbasierte Zugriffssteuerung in Azure (Azure Role-Based Access Control, Azure RBAC) verwaltet.
Die Rolle Mitwirkender an SQL Managed Instance, die auf die Ressourcengruppen der primären und der sekundären verwalteten Instanz festgelegt ist, reicht aus, um alle Verwaltungsvorgänge für Failovergruppen auszuführen.
Die folgende Tabelle enthält eine präzise Übersicht über minimal erforderliche Berechtigungen und die entsprechenden minimal erforderlichen Umfangsebenen für Verwaltungsvorgänge in Failovergruppen:
| Verwaltungsvorgang | Berechtigung | Umfang |
|---|---|---|
| Erstellen/Aktualisieren einer Failovergruppe | Microsoft.Sql/locations/instanceFailoverGroups/write |
Ressourcengruppen der primären und sekundären verwalteten Instanz |
| Erstellen/Aktualisieren einer Failovergruppe | Microsoft.Sql/managedInstances/write |
Primäre und sekundäre verwaltete Instanz |
| Failover für eine Failovergruppe | Microsoft.Sql/locations/instanceFailoverGroups/failover/action |
Ressourcengruppen der primären und sekundären verwalteten Instanz |
| Failover für eine Failovergruppe erzwingen | Microsoft.Sql/locations/instanceFailoverGroups/forceFailoverAllowDataLoss/action |
Ressourcengruppen der primären und sekundären verwalteten Instanz |
| Löschen einer Failovergruppe | Microsoft.Sql/locations/instanceFailoverGroups/delete |
Ressourcengruppen der primären und sekundären verwalteten Instanz |
Begrenzungen
Beachten Sie beim Erstellen einer neuen Failovergruppe die folgenden Einschränkungen:
- Failovergruppen können nicht zwischen zwei Instanzen in derselben Azure-Region erstellt werden.
- Eine Instanz kann gleichzeitig nur an einer Failovergruppe teilnehmen.
- Eine Failovergruppe kann nicht zwischen zwei Instanzen erstellt werden, die zu unterschiedlichen Azure-Mandanten gehören.
- Das Erstellen einer Failover-Gruppe zwischen zwei Instanzen in verschiedenen Ressourcengruppen oder Abonnements wird nur mit Azure PowerShell oder der REST-API und nicht der Azure-Portal oder der Azure CLI unterstützt. Nachdem die Failover-Gruppe erstellt wurde, ist sie im Azure-Portal sichtbar, und alle Vorgänge werden im Azure-Portal oder mit der Azure CLI unterstützt. Failover muss von der sekundären Instance initiiert werden.
- Wenn die anfängliche Ermittlung der Setzliste aller Datenbanken nicht innerhalb von sieben Tagen abgeschlossen ist, schlägt das Erstellen der Failovergruppe fehl, und alle erfolgreich replizierten Datenbanken werden aus der sekundären Instanz gelöscht.
- Das Erstellen einer Failover-Gruppe mit einer Instance, die mit einer verknüpften verwalteten Instance konfiguriert ist, wird derzeit nicht unterstützt.
- Failovergruppen können nicht zwischen Instanzen erstellt werden, wenn sich eine von ihnen in einem Instanzpool befindet.
- Datenbanken, die mithilfe des Protokollwiedergabedienstes (LRS) zu Azure SQL Managed Instance migriert wurden, können erst dann zu einer Failovergruppe hinzugefügt werden, wenn der Cutover-Schritt ausgeführt ist.
Beachten Sie beim Verwenden von Failovergruppen folgende Einschränkungen:
- Failovergruppen können nicht umbenannt werden. Sie müssen die Gruppe löschen und unter einem anderen Namen neu erstellen.
- Eine Failovergruppe enthält genau zwei verwaltete Instanzen. Das Hinzufügen zusätzlicher Instanzen zur Failovergruppe wird nicht unterstützt.
- Vollständige Sicherungen werden automatisch vorgenommen:
- vor der anfänglichen Ermittlung der Setzliste und können den Start des anfänglichen Ermittlungsprozesses deutlich verzögern.
- nach dem Failover und können ein nachfolgendes Failover verzögern oder verhindern.
- Die Datenbankumbenennung wird für Datenbanken in der Failovergruppe nicht unterstützt. Sie müssen die Failover-Gruppe vorübergehend löschen, um eine Datenbank umzubenennen.
- Systemdatenbanken werden nicht in die sekundäre Instanz in einer Failovergruppe repliziert. Daher erfordern Szenarien, die von Objekten in den Systemdatenbanken abhängen (z. B. Serveranmeldungen und Agent-Aufträge), dass die Objekte manuell für die sekundären Instanzen erstellt und auch manuell synchron gehalten werden, nachdem Änderungen an der primären Instanz vorgenommen wurden. Die einzige Ausnahme ist der Diensthauptschlüssel (Service Master Key, SMK) für SQL Managed Instance, der während dem Erstellen der Failovergruppe automatisch in die sekundäre Instanz repliziert wird. Alle nachfolgenden Änderungen des SMK auf der primären Instanz werden jedoch nicht auf die sekundäre Instanz repliziert. Weitere Informationen finden Sie unter Aktivieren von Szenarien in Abhängigkeit von Objekten in den Systemdatenbanken.
- Für Instanzen in einer Failover-Gruppe wird das Ändern der Dienstebene in oder von der Ebene „Universell der nächsten Generation“ nicht unterstützt. Sie müssen zunächst die Failovergruppe löschen, bevor Sie ein Replikat ändern, und dann die Failovergruppe erneut erstellen, nachdem die Änderung wirksam wurde.
- SQL-verwaltete Instanzen in einer Failovergruppe müssen dieselbe Updaterichtlinie aufweisen, aber es ist möglich, die Updaterichtlinie für Instanzen innerhalb einer Failovergruppe zu ändern.
Programmgesteuertes Verwalten von Failovergruppen
Gruppen für automatisches Failover können auch programmgesteuert mit Azure PowerShell, Azure CLI und der REST-API verwaltet werden. Die folgenden Tabellen beschreiben den verfügbaren Satz von Befehlen. Die aktive Georeplikation umfasst eine Reihe von Azure Resource Manager-APIs für die Verwaltung. Hierzu zählen unter anderem die Azure SQL-Datenbank-REST-API und Azure PowerShell-Cmdlets. Diese APIs erfordern die Verwendung von Ressourcengruppen und unterstützen die rollenbasierte Zugriffssteuerung (Azure RBAC) in Azure. Weitere Informationen zur Implementierung von Zugriffsrollen finden Sie unter Rollenbasierte Zugriffssteuerung in Azure (Azure RBAC).
| Cmdlet | BESCHREIBUNG |
|---|---|
| New-AzSqlDatabaseInstanceFailoverGroup | Dieser Befehl erstellt eine Failovergruppe und registriert sie auf primären und sekundären Instanzen |
| Set-AzSqlDatabaseInstanceFailoverGroup | Ändert die Konfiguration einer Failovergruppe |
| Get-AzSqlDatabaseInstanceFailoverGroup | Ruft die Konfiguration einer Failovergruppe ab |
| Switch-AzSqlDatabaseInstanceFailoverGroup | Löst das Failover einer Failovergruppe auf der sekundären Instanz aus |
| Remove-AzSqlDatabaseInstanceFailoverGroup | Entfernt eine Failovergruppe |