Migrieren Hunderter Terabytes von Daten zu Azure Cosmos DB
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
In Azure Cosmos DB können viele TB an Daten gespeichert werden. Sie können eine umfangreiche Datenmigration durchführen, um Ihre Produktionsworkloads in Azure Cosmos DB zu verschieben. Dieser Artikel beschreibt die Herausforderungen beim Verschieben von umfangreichen Daten in Azure Cosmos DB und stellt Ihnen das Tool vor, das bei der Bewältigung der Herausforderungen hilft und Daten zu Azure Cosmos DB migriert. In dieser Fallstudie hat der Kunde die Azure Cosmos DB-API für NoSQL verwendet.
Bevor Sie die gesamte Workload zu Azure Cosmos DB migrieren, können Sie eine Teilmenge der Daten migrieren, um einige Aspekte wie die Auswahl von Partitionsschlüsseln, die Abfrageleistung und die Datenmodellierung zu überprüfen. Nachdem Sie den Proof of Concept überprüft haben, können Sie die gesamte Workload in Azure Cosmos DB verschieben.
Tools für die Datenmigration
Azure Cosmos DB-Migrationsstrategien unterscheiden sich zurzeit je nach API-Auswahl und Größe der Daten. Um kleinere Datasets zu migrieren (zum Überprüfen der Datenmodellierung, Abfrageleistung, Partitionsschlüsselauswahl usw.) können Sie den Azure Cosmos DB-Connector von Azure Data Factory verwenden. Wenn Sie mit Spark vertraut sind, können Sie auch den Azure Cosmos DB Spark-Connector zum Migrieren von Daten verwenden.
Herausforderungen bei umfangreichen Migrationen
Die vorhandenen Tools zum Migrieren von Daten zu Azure Cosmos DB weisen einige Einschränkungen auf, die bei großen Datenmengen besonders offensichtlich werden:
Eingeschränkte Funktionen für das Aufskalieren: Um Terabyte an Daten so schnell wie möglich zu Azure Cosmos DB zu migrieren und den gesamten bereitgestellten Durchsatz effektiv zu nutzen, sollte für die Migrationsclients die Möglichkeit bestehen, unbegrenzt aufskaliert zu werden.
Fehlende Fortschrittsverfolgung und Prüfpunkte: Es ist wichtig, den Migrationsfortschritt nachzuverfolgen und bei der Migration großer Datasets Prüfpunkte zu verwenden. Andernfalls wird bei allen Fehlern, die während der Migration auftreten, die Migration beendet, und Sie müssen den Prozess von Grund auf neu starten. Es wäre nicht produktiv, den gesamten Migrationsprozess neu zu starten, wenn 99 % davon bereits abgeschlossen sind.
Fehlende Warteschlange für unzustellbare Nachrichten: In großen Datasets kann es in einigen Fällen zu Problemen mit Teilen der Quelldaten kommen. Außerdem treten möglicherweise vorübergehende Probleme mit dem Client oder dem Netzwerk auf. Beide Fälle sollten nicht bewirken, dass die gesamte Migration fehlschlägt. Obwohl die meisten Migrationstools über robuste Wiederholungsfunktionen verfügen, die vor zeitweiligen Problemen schützen, ist dies nicht immer ausreichend. Wenn z.B. weniger als 0,01 % der Quelldatendokumente größer als 2 MB sind, führt dies dazu, dass das Schreiben des Dokuments in Azure Cosmos DB fehlschlägt. Im Idealfall ist es nützlich, wenn das Migrationstool diese „fehlerhaften“ Dokumente in einer anderen Warteschlange für unzustellbare Nachrichten persistent speichert, die nach der Migration verarbeitet werden kann.
Viele dieser Einschränkungen werden für Tools wie Azure Data Factory und Azure Data Migration Services korrigiert.
Benutzerdefiniertes Tool mit BulkExecutor-Bibliothek
Die im obigen Abschnitt beschriebenen Herausforderungen können durch die Verwendung eines benutzerdefinierten Tools gelöst werden, das leicht über mehrere Instanzen hinweg horizontal skaliert werden kann und resistent gegen vorübergehende Fehler ist. Außerdem kann das benutzerdefinierte Tool die Migration an verschiedenen Prüfpunkten anhalten und dann fortsetzen. Azure Cosmos DB stellt bereits die BulkExecutor-Bibliothek bereit, die einige dieser Features enthält. Beispielsweise verfügt die BulkExecutor-Bibliothek bereits über eine Funktionalität zur Behandlung vorübergehender Fehler und kann die Aufskalierung von Threads in einem einzelnen Knoten durchführen, um ungefähr 500.000 RUs pro Knoten zu nutzen. Die BulkExecutor-Bibliothek partitioniert auch das Quelldataset in Mikrobatches, die unabhängig als eine Form von Prüfpunkten verarbeitet werden.
Das benutzerdefinierte Tool verwendet die BulkExecutor-Bibliothek und unterstützt das horizontale Skalieren auf mehreren Clients sowie das Nachverfolgen von Fehlern während des Erfassungsvorgangs. Um dieses Tool zu verwenden, sollten die Quelldaten in verschiedene Dateien in Azure Data Lake Storage (ADLS) unterteilt werden, sodass verschiedene Migrationsworker jede Datei verwenden und in Azure Cosmos DB erfassen können. Das benutzerdefinierte Tool verwendet eine separate Sammlung, in der Metadaten zum Migrationsfortschritt für jede einzelne Quelldatei in ADLS gespeichert und alle damit verbundenen Fehler nachverfolgt werden.
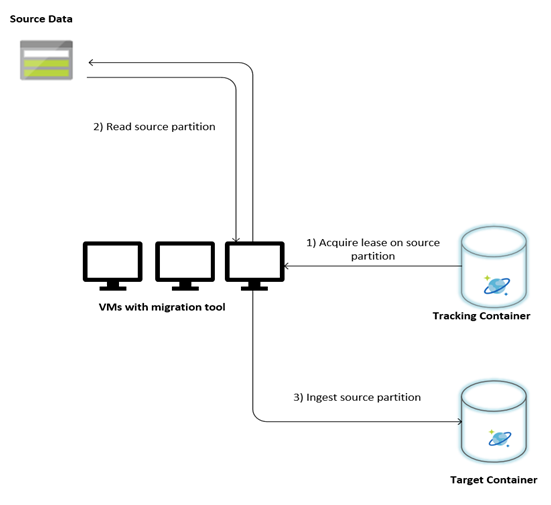
In der folgenden Abbildung wird der Migrationsprozess mithilfe dieses benutzerdefinierten Tools beschrieben. Das Tool wird auf einer Reihe von virtuellen Computern ausgeführt, und jeder virtuelle Computer fragt die Nachverfolgungssammlung in Azure Cosmos DB ab, um eine Lease für eine der Quelldatenpartitionen zu erhalten. Nachdem dies geschehen ist, wird die Quelldatenpartition vom Tool gelesen und mithilfe der BulkExecutor-Bibliothek in Azure Cosmos DB erfasst. Anschließend wird die Nachverfolgungssammlung aktualisiert, um den Fortschritt der Datenerfassung und die aufgetretenen Fehler aufzuzeichnen. Nachdem eine Datenpartition verarbeitet wurde, versucht das Tool, die nächste verfügbare Quellpartition abzufragen. Die Verarbeitung der nächsten Quellpartition wird fortgesetzt, bis alle Daten migriert wurden. Der Quellcode für das Tool ist im Repository für die Massenerfassung in Azure Cosmos DB verfügbar.
Die Nachverfolgungssammlung enthält Dokumente, wie im folgenden Beispiel gezeigt. Diese Dokumente werden für jede Partition in den Quelldaten angezeigt. Jedes Dokument enthält die Metadaten für die Quelldatenpartition, z.B. den Speicherort, den Migrationsstatus und Fehler (sofern vorhanden):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Voraussetzungen für die Datenmigration
Vor dem Start der Datenmigration müssen einige Voraussetzungen erfüllt sein:
Schätzen der Datengröße:
Die Größe der Quelldaten ist möglicherweise nicht genau mit der Datengröße in Azure Cosmos DB identisch. Einige Beispieldokumente aus der Quelle können eingefügt werden, um ihre Datengröße in Azure Cosmos DB zu überprüfen. Abhängig von der Größe des Beispieldokuments kann die Gesamtgröße der Daten in Azure Cosmos DB nach der Migration geschätzt werden.
Wenn beispielsweise jedes Dokument nach der Migration in Azure Cosmos DB etwa 1 KB groß ist und etwa 60 Milliarden Dokumente im Quelldataset vorhanden sind, würde das bedeuten, dass die geschätzte Größe in Azure Cosmos DB fast 60 TB betragen würde.
Voraberstellen von Containern mit einer ausreichenden Menge von RUs:
Obwohl Azure Cosmos DB Speicher automatisch horizontal skaliert, empfiehlt es sich nicht, mit der kleinsten Containergröße zu beginnen. Kleinere Container weisen eine geringere Durchsatzverfügbarkeit auf, was bedeutet, dass die Migration erheblich länger dauern würde. Stattdessen ist es sinnvoll, die Container mit der endgültigen Datengröße (wie im vorherigen Schritt geschätzt) zu erstellen und sicherzustellen, dass die Migrationsworkload den bereitgestellten Durchsatz vollständig nutzt.
Im vorherigen Schritt. Da die Größe der Daten bei ungefähr 60 TB geschätzt wurde, ist ein Container mit mindestens 2,4 Millionen RUs erforderlich, um das gesamte Dataset aufnehmen zu können.
Schätzen der Migrationsgeschwindigkeit:
Unter der Annahme, dass die Migrationsworkload den gesamten bereitgestellten Durchsatz nutzen kann, würde die gesamte Bereitstellung eine Schätzung der Migrationsgeschwindigkeit bereitstellen. Wenn Sie das vorherige Beispiel betrachten, sind 5 RUs erforderlich, um ein 1 KB großes Dokument in das NoSQL-API-Konto in Azure Cosmos DB zu schreiben. 2,4 Millionen RUS ermöglicht eine Übertragung von 480.000 Dokumenten pro Sekunde (oder 480 MB/s). Dies bedeutet, dass die vollständige Migration von 60 TB 125.000 Sekunden oder ungefähr 34 Stunden dauert.
Für den Fall, dass die Migration innerhalb eines Tages abgeschlossen werden soll, sollten Sie den bereitgestellten Durchsatz auf 5 Millionen RUs erhöhen.
Deaktivieren der Indizierung:
Da die Migration so schnell wie möglich abgeschlossen werden sollte, empfiehlt es sich, die Zeit und die RUS zu minimieren, die für die Erstellung von Indizes für die erfassten Dokumente aufgewendet werden. Da Azure Cosmos DB alle Eigenschaften automatisch indiziert, lohnt es sich, die Indizierung auf wenige Begriffe zu minimieren oder für den Verlauf der Migration vollständig zu deaktivieren. Sie können die Indizierungsrichtlinie des Containers deaktivieren, indem Sie den indexingMode in „none“ ändern, wie unten dargestellt:
{
"indexingMode": "none"
}
Nach Abschluss der Migration können Sie die Indizierung aktualisieren.
Migrationsprozess
Nachdem die Voraussetzungen erfüllt sind, können Sie die Daten mit den folgenden Schritten migrieren:
Importieren Sie die Daten zunächst aus der Quelle in Azure Blob Storage. Um die Geschwindigkeit der Migration zu erhöhen, ist es hilfreich, über verschiedene Quellpartitionen hinweg zu parallelisieren. Vor dem Starten der Migration sollte das Quelldataset in Dateien mit einer Größe von ungefähr 200 MB partitioniert werden.
Die BulkExecutor-Bibliothek kann hochskaliert werden, um 500.000 RUs in einer einzelnen Client-VM zu nutzen. Da der verfügbare Durchsatz 5 Millionen RUs beträgt, sollten 10 Ubuntu 16.04-VMs (Standard_D32_v3) in der gleichen Region bereitgestellt werden, in der sich auch Ihre Azure Cosmos DB-Datenbank befindet. Sie sollten diese VMs mit dem Migrationstool und der zugehörigen Einstellungsdatei vorbereiten.
Führen Sie den Warteschlangenschritt auf einem der virtuellen Clientcomputer aus. In diesem Schritt wird die Nachverfolgungssammlung erstellt, die den ADLS-Container scannt und für jede der Partitionsdateien des Quelldatasets ein Dokument erstellt, das den Fortschritt nachverfolgt.
Führen Sie anschließend den Importschritt auf allen Client-VMs aus. Jeder der Clients kann den Besitz für eine Quellpartition übernehmen und seine Daten in Azure Cosmos DB erfassen. Sobald der Vorgang abgeschlossen ist und der Status in der Nachverfolgungssammlung aktualisiert wurde, können die Clients die nächste verfügbare Quellpartition in der Nachverfolgungssammlung abfragen.
Dieser Vorgang wird fortgesetzt, bis der gesamte Satz von Quellpartitionen erfasst wurde. Nachdem alle Quellpartitionen verarbeitet wurden, sollte das Tool im Fehlerkorrekturmodus für dieselbe Nachverfolgungssammlung erneut ausgeführt werden. Dieser Schritt ist erforderlich, um die Quellpartitionen zu identifizieren, die aufgrund von Fehlern erneut verarbeitet werden sollten.
Einige dieser Fehler können auf falsche Dokumente in den Quelldaten zurückzuführen sein. Diese sollten identifiziert und korrigiert werden. Anschließend sollten Sie den Importschritt für die fehlerhaften Partitionen erneut ausführen, um sie erneut zu erfassen.
Nachdem die Migration abgeschlossen ist, können Sie überprüfen, ob die Anzahl der Dokumente in Azure Cosmos DB mit der Anzahl der Dokumente in der Quelldatenbank identisch ist. In diesem Beispiel hat sich eine Gesamtgröße in Azure Cosmos DB von 65 Terabyte ergeben. Nach der Migration kann die Indizierung selektiv aktiviert werden, und die RUs können auf die Ebene verringert werden, die für die Vorgänge der Workload erforderlich ist.
Nächste Schritte
- Erfahren Sie mehr darüber, indem Sie die Beispielanwendungen ausprobieren, die die BulkExecutor-Bibliothek in .NET und Java nutzen.
- Die Bulk Executor-Bibliothek ist in den Spark-Connector für Azure Cosmos DB integriert. Weitere Informationen finden Sie im Artikel Spark-Connector für Azure Cosmos DB.
- Wenden Sie sich an das Azure Cosmos DB-Produktteam, indem Sie unter dem Problemtyp „Allgemeine Ratschläge“ und dem Problemuntertyp „Umfangreiche Migrationen (TB+)“ ein Supportticket öffnen, um weitere Hilfe zu größeren Migrationen zu erhalten.
- Versuchen Sie, die Kapazitätsplanung für eine Migration zu Azure Cosmos DB durchzuführen? Sie können Informationen zu Ihrem vorhandenen Datenbankcluster für die Kapazitätsplanung verwenden.
- Wenn Sie nur die Anzahl der virtuellen Kerne und Server in Ihrem vorhandenen Datenbankcluster kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mithilfe von virtuellen Kernen oder virtuellen CPUs
- Wenn Sie die typischen Anforderungsraten für Ihre aktuelle Datenbankworkload kennen, lesen Sie die Informationen zum Schätzen von Anforderungseinheiten mit dem Azure Cosmos DB-Kapazitätsplaner
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für