Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. In Microsoft Fabric können Sie alle erforderlichen Aufgaben ausführen, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
In diesem Artikel wird beschrieben, wie Sie Daten mithilfe der Copy-Aktivität in Azure Data Factory- und Azure Synapse Analytics-Pipelines aus einer und in eine SQL Server-Datenbank kopieren sowie Daten per Datenfluss in eine SQL Server-Datenbank transformieren. Um mehr zu lernen, lesen Sie den Einführungsartikel für Azure Data Factory oder Azure Synapse Analytics.
Unterstützte Funktionen
Dieser SQL Server-Connector wird für die folgenden Funktionen unterstützt:
| Unterstützte Funktionen | IR |
|---|---|
| Copy-Aktivität (Quelle/Senke) | (1) (2) |
| Zuordnungsdatenfluss (Quelle/Senke) | ① |
| Lookup-Aktivität | (1) (2) |
| GetMetadata-Aktivität | (1) (2) |
| Skript-Aktivität | (1) (2) |
| Aktivität „Gespeicherte Prozedur“ | (1) (2) |
① Azure Integration Runtime ② Selbstgehostete Integration Runtime
Eine Liste der Datenspeicher, die als Quellen oder Senken für die Kopieraktivität unterstützt werden, finden Sie in der Tabelle Unterstützte Datenspeicher.
Dieser SQL Server-Connector unterstützt insbesondere Folgendes:
- SQL Server, Version 2005 und höher.
- Kopieren von Daten unter Verwendung der SQL- oder Windows-Authentifizierung
- Als Quelle das Abrufen von Daten mithilfe einer SQL-Abfrage oder gespeicherten Prozedur Sie können sich auch für das parallele Kopieren aus der SQL Server-Quelle entscheiden. Einzelheiten finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank.
- Als Senke das automatische Erstellen einer Zieltabelle (sofern nicht vorhanden) basierend auf dem Quellschema. Außerdem das Anfügen von Daten an eine Tabelle oder das Aufrufen einer gespeicherten Prozedur mit benutzerdefinierter Logik während des Kopiervorgangs.
SQL Server Express LocalDB wird nicht unterstützt.
Wichtig
Die Datenquelle muss den NVARCHAR-Datentyp unterstützen, da er sich auf die Datencodierung auswirkt, wenn eine nicht universelle Codierung auf die Daten angewendet wird.
Voraussetzungen
Wenn sich Ihr Datenspeicher in einem lokalen Netzwerk, in einem virtuellen Azure-Netzwerk oder in Amazon Virtual Private Cloud befindet, müssen Sie eine selbstgehostete Integration Runtime konfigurieren, um eine Verbindung herzustellen.
Handelt es sich bei Ihrem Datenspeicher um einen verwalteten Clouddatendienst, können Sie die Azure Integration Runtime verwenden. Ist der Zugriff auf IP-Adressen beschränkt, die in den Firewallregeln genehmigt sind, können Sie Azure Integration Runtime-IPs zur Positivliste hinzufügen.
Sie können auch das Feature managed virtual network integration runtime (Integration Runtime für verwaltete virtuelle Netzwerke) in Azure Data Factory verwenden, um auf das lokale Netzwerk zuzugreifen, ohne eine selbstgehostete Integration Runtime zu installieren und zu konfigurieren.
Weitere Informationen zu den von Data Factory unterstützten Netzwerksicherheitsmechanismen und -optionen finden Sie unter Datenzugriffsstrategien.
Erste Schritte
Zum Ausführen der Kopieraktivität mit einer Pipeline können Sie eines der folgenden Tools oder SDKs verwenden:
- Datenkopier-Werkzeug
- Azure-Portal
- .NET SDK
- Python SDK
- Azure PowerShell
- REST-API
- Azure Resource Manager-Vorlage
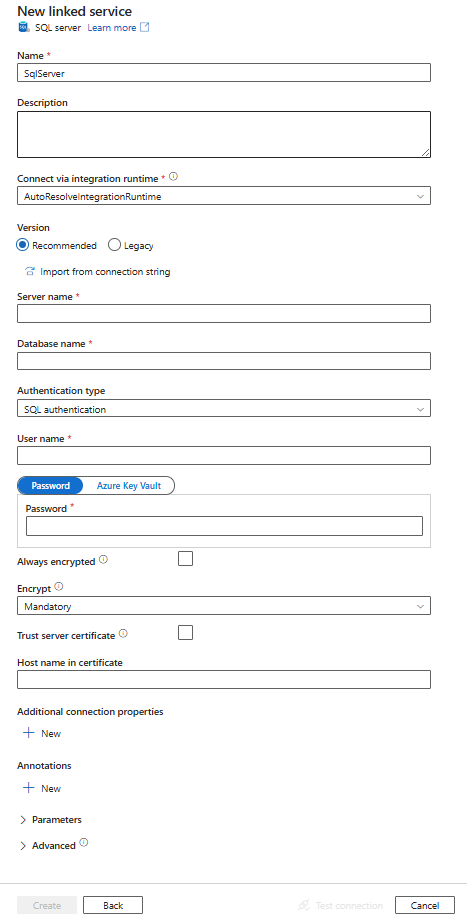
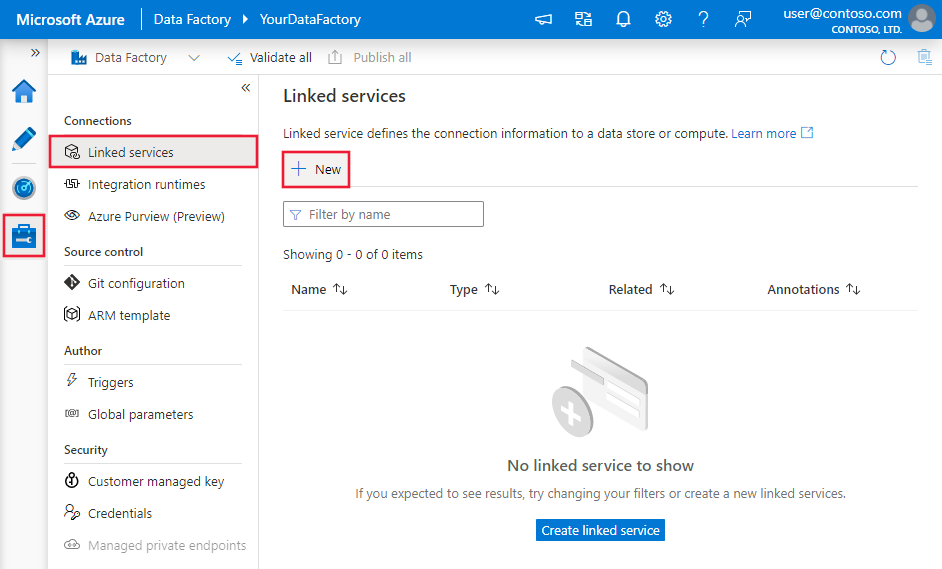
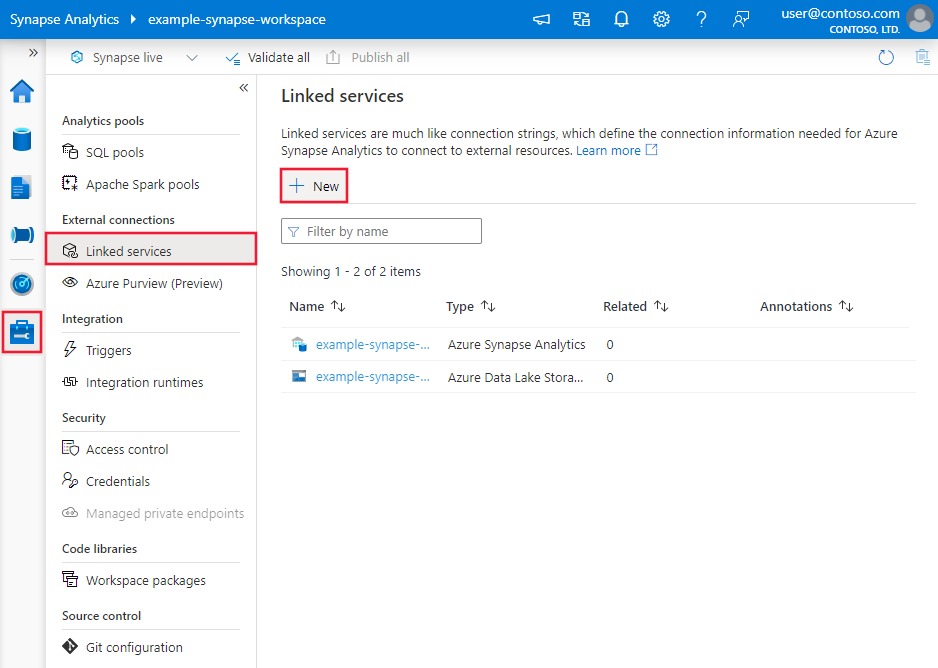
Erstellen eines verknüpften Diensts für SQL Server über die Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um über die Benutzeroberfläche des Azure-Portals einen verknüpften Dienst für SQL Server zu erstellen.
Navigieren Sie in Ihrem Azure Data Factory- oder Synapse-Arbeitsbereich zur Registerkarte „Verwalten“, wählen Sie „Verknüpfte Dienste“ aus, und klicken Sie dann auf „Neu“:
Suchen Sie nach SQL, und wählen Sie den SQL Server-Connector aus.

Konfigurieren Sie die Dienstdetails, testen Sie die Verbindung, und erstellen Sie den neuen verknüpften Dienst.
Details zur Connectorkonfiguration
Die folgenden Abschnitte enthalten Details zu Eigenschaften, die zum Definieren von Entitäten in Data Factory- und Synapse-Pipelines speziell für den SQL Server-Datenbankconnector verwendet werden.
Eigenschaften des verknüpften Diensts
Die empfohlene Version von SQL Server unterstützt TLS 1.3. Lesen Sie diesen Abschnitt, um den mit SQL Server verknüpften Dienst zu aktualisieren, wenn Sie die Legacy-Version verwenden. Einzelheiten zur Eigenschaft finden Sie in den entsprechenden Abschnitten.
Tipp
Wenn ein Fehler mit dem Fehlercode „UserErrorFailedToConnectToSqlServer“ auftritt und eine Meldung wie „Das Sitzungslimit für die Datenbank ist XXX und wurde erreicht“ angezeigt wird, fügen Sie Pooling=false zu Ihrer Verbindungszeichenfolge hinzu, und versuchen Sie es erneut.
Empfohlene Version
Diese generischen Eigenschaften werden für einen mit SQL Server verknüpften Dienst unterstützt, wenn Sie die empfohlene Version anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf SqlServer festgelegt sein. | Ja |
| server | Der Name oder die Netzwerkadresse der SQL Server-Instanz, mit der Sie eine Verbindung herstellen möchten. | Ja |
| database | Der Name der Datenbank. | Ja |
| authenticationType | Der Typ, der für die Authentifizierung verwendet wird. Zulässige Werte sind SQL (Standard), Windows und UserAssignedManagedIdentity- (nur für SQL Server auf Azure VMs). Wechseln Sie zum entsprechenden Abschnitt über spezifische Eigenschaften und Voraussetzungen für die Authentifizierung. | Ja |
| Always Encrypted-Einstellungen | Geben Sie die Informationen zu denAlways Encrypted-Einstellungen an, die erforderlich sind, damit Always Encrypted vertrauliche Daten schützen kann, die auf dem SQL-Server mithilfe der verwalteten Identität oder des Dienstprinzipals gespeichert sind. Weitere Informationen finden Sie im JSON-Beispiel unter der Tabelle sowie in dem Bereich Verwenden von Always Encrypted. Wenn keine Angabe erfolgt, ist die standardmäßige Always Encrypted-Einstellung deaktiviert. | Nein |
| encrypt | Geben Sie an, ob die TLS-Verschlüsselung für alle Daten erforderlich ist, die zwischen dem Client und dem Server gesendet werden. Optionen: obligatorisch (für TRUE, Standard)/optional (für FALSE)/streng. | Nein |
| trustServerCertificate | Geben Sie an, ob der Kanal verschlüsselt sein wird, während die Zertifikatskette zum Überprüfen der Vertrauensstellung umgangen wird. | Nein |
| hostNameInCertificate | Der Hostname, der beim Validieren des Serverzertifikats für die Verbindung verwendet werden soll. Falls nicht angegeben, wird der Servername für die Zertifikatsvalidierung verwendet. | Nein |
| connectVia | Diese Integration Runtime wird zum Herstellen einer Verbindung mit dem Datenspeicher verwendet. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Weitere Verbindungseigenschaften finden Sie in der folgenden Tabelle:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| applicationIntent | Der Workloadtyp der Anwendung beim Herstellen einer Verbindung mit einem Server. Zulässige Werte sind ReadOnly und ReadWrite. |
Nein |
| connectTimeout | Die Zeitspanne (in Sekunden), die auf eine Verbindung mit dem Server gewartet wird, bevor der Versuch abgebrochen wird und ein Fehler generiert wird. | Nein |
| connectRetryCount | Anzahl der versuchten Neuverbindungen, nachdem ein Leerlaufverbindungsfehler erkannt wurde. Der Wert sollte eine ganze Zahl zwischen 0 und 255 sein. | Nein |
| connectRetryInterval | Die Zeitspanne (in Sekunden) zwischen jedem Neuverbindungsversuch, nachdem ein Leerlaufverbindungsfehler erkannt wurde. Der Wert sollte eine ganze Zahl zwischen 1 und 60 sein. | Nein |
| loadBalanceTimeout | Die Mindestdauer (in Sekunden), die eine Verbindung im Verbindungspool verbleiben soll, bevor die Verbindung abgebrochen wird. | Nein |
| commandTimeout | Die Standardwartezeit (in Sekunden), bevor der Versuch einer Befehlsausführung beendet und ein Fehler generiert wird. | Nein |
| integratedSecurity | Die zulässigen Werte sind true oder false. Geben Sie beim Wert false an, ob Benutzername und Kennwort in der Verbindung angegeben werden. Geben Sie beim Wert true an, ob die aktuellen Anmeldeinformationen für das Windows-Konto für die Authentifizierung verwendet werden. |
Nein |
| failoverPartner | Name oder Adresse des Partnerservers, mit dem eine Verbindung hergestellt werden soll, wenn der primäre Server ausgefallen ist. | Nein |
| maxPoolSize | Die im Verbindungspool zulässige maximale Anzahl von Verbindungen für die angegebene Verbindung. | Nein |
| minPoolSize | Die im Verbindungspool zulässige Mindestanzahl von Verbindungen für die angegebene Verbindung. | Nein |
| multipleActiveResultSets | Die zulässigen Werte sind true oder false. Wenn Sie true angeben, kann eine Anwendung mehrere aktive Resultsets (MARS) verwalten. Wenn Sie false angeben, muss eine Anwendung alle Resultsets aus einem Batch verarbeiten oder abbrechen, bevor sie andere Batches über diese Verbindung ausführen kann. |
Nein |
| multiSubnetFailover | Die zulässigen Werte sind true oder false. Wenn Ihre Anwendung eine Verbindung mit einer AlwaysOn-Verfügbarkeitsgruppe (Availability Group, AG) in unterschiedlichen Subnetzen herstellt, ermöglicht das Festlegen dieser Eigenschaft auf true eine schnellere Erkennung des und Verbindung mit dem derzeit aktiven Server. |
Nein |
| packetSize | Die Größe der Netzwerkpakete (in Byte), die bei der Kommunikation mit einer Instanz des Servers verwendet werden. | Nein |
| pooling | Die zulässigen Werte sind true oder false. Wenn Sie true angeben, wird die Verbindung gepoolt. Wenn Sie false angeben, wird die Verbindung bei jeder Anforderung der Verbindung explizit geöffnet. |
Nein |
SQL-Authentifizierung
Um die SQL-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Der Benutzername, der beim Herstellen einer Verbindung mit dem Server verwendet werden soll. | Ja |
| password | Das Kennwort für den Benutzernamen. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Nein |
Beispiel 1: Verwenden der SQL-Authentifizierung
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel 2: Verwenden der SQL-Authentifizierung mit einem Kennwort in Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel: Verwenden von Always Encrypted
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"alwaysEncryptedSettings": {
"alwaysEncryptedAkvAuthType": "ServicePrincipal",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Windows-Authentifizierung
Um die Windows-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| userName | Geben Sie einen Benutzernamen an. Ein Beispiel lautet domainname\username. | Ja |
| password | Geben Sie das Kennwort für das Benutzerkonto an, das Sie für den Benutzernamen angegeben haben. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Hinweis
Windows-Authentifizierung wird in Datenflüssen nicht unterstützt.
Beispiel: Verwenden der Windows-Authentifizierung
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Beispiel 2: Verwenden der Windows-Authentifizierung mit einem Kennwort in Azure Key Vault
{
"name": "SqlServerLinkedService",
"properties": {
"annotations": [],
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "Windows",
"userName": "<domain\\username>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Authentifizierung mit einer benutzerseitig zugewiesenen verwalteten Identität
Hinweis
Die Authentifizierung durch die benutzerseitig zugewiesene verwaltete Identität gilt nur für SQL Server auf Azure-VMs.
Eine Datenfabrik oder ein Synapse-Arbeitsbereich kann mit einer systemzugewiesenen verwalteten Identität für Azure-Ressourcen verknüpft werden, die den Dienst bei der Authentifizierung gegenüber anderen Ressourcen in Azure repräsentiert. Sie können diese verwaltete Identität für die Authentifizierung einer SQL Server auf Azure VM-Instanz verwenden. Die angegebenen Factory oder Synapse Arbeitsbereiche können mittels dieser Identität auf Daten zugreifen und Daten aus der oder in die Datenbank kopieren.
Um die vom Benutzer zugewiesene verwaltete Identitätsauthentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| Anmeldeinformationen | Geben Sie die benutzerseitig zugewiesene verwaltete Identität als Anmeldeinformationsobjekt an. | Ja |
Sie müssen auch die folgenden Schritte ausführen:
Erteilen von Berechtigungen für Ihre benutzerseitig zugewiesene verwaltete Identität
Aktivieren der Microsoft Entra-Authentifizierung für Ihre SQL Server auf Azure-VMs.
Erstellen Sie Benutzer der eigenständigen Datenbank für die benutzerseitig zugewiesene verwaltete Identität. Stellen Sie eine Verbindung mit der Datenbank her, aus der bzw. in die Sie Daten mithilfe von Tools wie SQL Server Management Studio kopieren möchten. Verwenden Sie dazu eine Microsoft Entra-Identität, die mindestens über die Berechtigung ALTER ANY USER verfügt. Führen Sie folgenden T-SQL-Code aus:
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Erstellen Sie mindestens eine benutzerseitig zugewiesene verwaltete Identität, und gewähren Sie dieser Identität die erforderlichen Berechtigungen, wie Sie es normalerweise für SQL- und andere Benutzer tun. Führen Sie den folgenden Code aus. Weitere Optionen finden Sie in diesem Dokument.
ALTER ROLE [role name] ADD MEMBER [your_resource_name];Weisen Sie Ihrer Data Factory eine oder mehrere benutzerseitig zugewiesene verwaltete Identitäten zu, und erstellen Sie Anmeldeinformationen für jede benutzerseitig zugewiesene verwaltete Identität.
Konfigurieren eines mit SQL Server verknüpften Diensts.
Beispiel
{
"name": "SqlServerLinkedService",
"properties": {
"type": "SqlServer",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Legacy-Version
Diese generischen Eigenschaften werden für einen mit SQL Server verknüpften Dienst unterstützt, wenn Sie die Legacy-Version anwenden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft muss auf SqlServer festgelegt sein. | Ja |
| Always Encrypted-Einstellungen | Geben Sie die Informationen zu denAlways Encrypted-Einstellungen an, die erforderlich sind, damit Always Encrypted vertrauliche Daten schützen kann, die auf dem SQL-Server mithilfe der verwalteten Identität oder des Dienstprinzipals gespeichert sind. Weitere Informationen finden Sie im Abschnitt Verwenden von Always Encrypted. Wenn keine Angabe erfolgt, ist die standardmäßige Always Encrypted-Einstellung deaktiviert. | Nein |
| connectVia | Diese Integration Runtime wird zum Herstellen einer Verbindung mit dem Datenspeicher verwendet. Weitere Informationen finden Sie im Abschnitt Voraussetzungen. Wenn kein Wert angegeben ist, wird die standardmäßige Azure Integration Runtime verwendet. | Nein |
Dieser SQL Server-Connector unterstützt die folgenden Authentifizierungstypen. Weitere Informationen finden Sie in den entsprechenden Abschnitten.
SQL-Authentifizierung für die Legacy-Version
Um die SQL-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| connectionString | Geben Sie unter connectionString die Verbindungszeichenfolge an, die zum Herstellen einer Verbindung mit der SQL Server-Datenbank erforderlich ist. Geben Sie einen Anmeldenamen als Ihren Benutzernamen an, und stellen Sie sicher, dass die Datenbank, die Sie verbinden möchten, dieser Anmeldung zugeordnet ist. | Ja |
| password | Wenn Sie ein Kennwort in Azure Key Vault speichern möchten, rufen Sie mithilfe von Pull die password-Konfiguration aus der Verbindungszeichenfolge ab. Weitere Informationen finden Sie unter Speichern von Anmeldeinformationen in Azure Key Vault. |
Nein |
Windows-Authentifizierung für die Legacy-Version
Um die Windows-Authentifizierung zu verwenden, geben Sie zusätzlich zu den im vorherigen Abschnitt beschriebenen allgemeinen Eigenschaften die folgenden Eigenschaften an:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| connectionString | Geben Sie unter connectionString die Verbindungszeichenfolge an, die zum Herstellen einer Verbindung mit der SQL Server-Datenbank erforderlich ist. | Ja |
| userName | Geben Sie einen Benutzernamen an. Ein Beispiel lautet domainname\username. | Ja |
| password | Geben Sie das Kennwort für das Benutzerkonto an, das Sie für den Benutzernamen angegeben haben. Markieren Sie dieses Feld als SecureString, um es sicher zu speichern. Alternativ können Sie auf ein in Azure Key Vault gespeichertes Geheimnis verweisen. | Ja |
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom SQL Server-Dataset unterstützt werden.
Zum Kopieren von Daten aus einer und in eine SQL Server-Datenbank werden die folgenden Eigenschaften unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf SqlServerTable festgelegt werden. | Ja |
| schema | Name des Schemas. | Quelle: Nein, Senke: Ja |
| table | Name der Tabelle/Ansicht. | Quelle: Nein, Senke: Ja |
| tableName | Name der Tabelle/Ansicht mit Schema. Diese Eigenschaft wird aus Gründen der Abwärtskompatibilität weiterhin unterstützt. Verwenden Sie für eine neue Workload schema und table. |
Quelle: Nein, Senke: Ja |
Beispiel
{
"name": "SQLServerDataset",
"properties":
{
"type": "SqlServerTable",
"linkedServiceName": {
"referenceName": "<SQL Server linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Eigenschaften der Kopieraktivität
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der SQL Server-Quelle und -Senke unterstützt werden.
SQL Server als Quelle
Tipp
Weitere Informationen zum effizienten Laden von Daten aus SQL Server mittels Datenpartitionierung finden Sie unter Paralleles Kopieren aus SQL-Datenbank.
Legen Sie zum Kopieren von Daten aus SQL Server den Quellentyp in der Kopieraktivität auf SqlSource fest. Die folgenden Eigenschaften werden im Abschnitt „source“ der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf SqlSource festgelegt sein. | Ja |
| sqlReaderQuery | Verwendet die benutzerdefinierte SQL-Abfrage zum Lesen von Daten. z. B. select * from MyTable. |
Nein |
| sqlReaderStoredProcedureName | Diese Eigenschaft ist der Name der gespeicherten Prozedur, die Daten aus der Quelltabelle liest. Die letzte SQL-Anweisung muss eine SELECT-Anweisung in der gespeicherten Prozedur sein. | Nein |
| storedProcedureParameters | Diese Parameter werden für die gespeicherte Prozedur verwendet. Zulässige Werte sind Namen oder Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen den Namen und der Groß-/Kleinschreibung der Parameter der gespeicherten Prozedur entsprechen. |
Nein |
| isolationLevel | Gibt das Sperrverhalten für Transaktionen für die SQL-Quelle an. Zulässige Werte sind: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Ohne Angabe wird die Standardisolationsstufe der Datenbank verwendet. Weitere Informationen finden Sie in dieser Dokumentation. | Nein |
| partitionOptions | Gibt die Datenpartitionierungsoptionen an, mit denen Daten aus SQL Server geladen werden. Zulässige Werte sind: None (Standard), PhysicalPartitionsOfTable und DynamicRange. Wenn eine Partitionsoption aktiviert ist (nicht None), wird der Grad an Parallelität zum gleichzeitigen Laden von Daten von SQL Server durch die Einstellung parallelCopies für die Kopieraktivität gesteuert. |
Nein |
| partitionSettings | Geben Sie die Gruppe der Einstellungen für die Datenpartitionierung an. Verwenden Sie diese Option, wenn die Partitionsoption nicht None lautet. |
Nein |
Unter partitionSettings: |
||
| partitionColumnName | Geben Sie den Namen der Quellspalte als „integer“ oder „date/datetime“ (int, smallint, bigint, date, smalldatetime, datetime, datetime2 oder datetimeoffset) an, der von der Bereichspartitionierung für das parallele Kopieren verwendet wird. Ohne Angabe wird der Index oder der Primärschlüssel der Tabelle automatisch erkannt und als Partitionsspalte verwendet.Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Wenn Sie die Quelldaten mithilfe einer Abfrage abrufen, integrieren Sie ?DfDynamicRangePartitionCondition in die WHERE-Klausel. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
| partitionUpperBound | Der maximale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
| partitionLowerBound | Der minimale Wert der Partitionsspalte für das Teilen des Partitionsbereichs. Dieser Wert wird zur Entscheidung über den Partitionssprung verwendet, nicht zum Filtern der Zeilen in der Tabelle. Alle Zeilen in der Tabelle oder im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Verwenden Sie diese Option, wenn die Partitionsoption DynamicRange lautet. Ein Beispiel finden Sie im Abschnitt Paralleles Kopieren aus SQL-Datenbank. |
Nein |
Beachten Sie folgende Punkte:
- Wenn sqlReaderQuery für SqlSource angegeben ist, führt die Kopieraktivität diese Abfrage für die SQL Server-Quelle aus, um die Daten abzurufen. Sie können auch eine gespeicherte Prozedur angeben, indem Sie sqlReaderStoredProcedureName und storedProcedureParameters angeben, sofern die gespeicherten Prozeduren Parameter verwenden.
- Wenn Sie zum Abrufen von Daten eine gespeicherte Prozedur in der Quelle verwenden und die gespeicherte Prozedur beim Übergeben eines anderen Parameterwerts ein anderes Schema zurückgibt, kommt es möglicherweise beim Importieren eines Schemas über die Benutzeroberfläche oder beim Kopieren von Daten in eine SQL-Datenbank zu einem Fehler oder einem unerwarteten Ergebnis.
Beispiel: Verwenden einer SQL-Abfrage
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Beispiel: Verwenden einer gespeicherten Prozedur
"activities":[
{
"name": "CopyFromSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<SQL Server input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Definition der gespeicherten Prozedur
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
SQL Server als Senke
Tipp
Weitere Informationen zum unterstützten Schreibverhalten, zu unterstützten Konfigurationen und bewährten Methoden finden Sie unter Bewährte Methode zum Laden von Daten in SQL Server.
Legen Sie zum Kopieren von Daten in SQL Server den Senkentyp in der Kopieraktivität auf SqlSink fest. Die folgenden Eigenschaften werden im Abschnitt „sink“ der Kopieraktivität unterstützt:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Senke der Kopieraktivität muss auf SqlSink festgelegt sein. | Ja |
| preCopyScript | Diese Eigenschaft gibt eine SQL-Abfrage für die Kopieraktivität an, die vor dem Schreiben von Daten in SQL Server ausgeführt wird. Sie wird pro Ausführung der Kopieraktivität nur einmal aufgerufen. Sie können diese Eigenschaft nutzen, um die vorab geladenen Daten zu bereinigen. | Nein |
| tableOption | Gibt an, ob die Senkentabelle auf Basis des Quellschemas automatisch erstellt werden soll, wenn sie nicht vorhanden ist. Die automatische Tabellenerstellung wird nicht unterstützt, wenn die Senke eine gespeicherte Prozedur angibt. Zulässige Werte: none (Standard), autoCreate. |
Nein |
| sqlWriterStoredProcedureName | Der Name der gespeicherten Prozedur, die definiert, wie Quelldaten auf eine Zieltabelle angewandt werden. Diese gespeicherte Prozedur wird pro Batch aufgerufen. Für nur einmalig ausgeführte Vorgänge, die nicht mit Quelldaten in Zusammenhang stehen (etwa Löschen/Kürzen), verwenden Sie die preCopyScript-Eigenschaft.Ein Beispiel finden Sie unter Aufrufen einer gespeicherten Prozedur aus einer SQL-Senke. |
Nein |
| storedProcedureTableTypeParameterName | Der Parametername des Tabellentyps, der in der gespeicherten Prozedur angegeben ist. | Nein |
| sqlWriterTableType | Der Tabellentypname, der in der gespeicherten Prozedur verwendet werden soll. Die Kopieraktivität macht die verschobenen Daten in einer temporären Tabelle mit diesem Tabellentyp verfügbar. Der gespeicherte Prozedurcode kann dann die kopierten Daten mit vorhandenen Daten zusammenführen. | Nein |
| storedProcedureParameters | Parameter für die gespeicherte Prozedur. Zulässige Werte: Name-Wert-Paare. Die Namen und die Groß-/Kleinschreibung von Parametern müssen denen der Parameter der gespeicherten Prozedur entsprechen. |
Nein |
| writeBatchSize | Anzahl der Zeilen, die pro Batch in die SQL-Tabelle eingefügt werden sollen. Zulässige Werte sind Integer-Werte für die Anzahl der Zeilen. Standardmäßig bestimmt der Dienst die geeignete Batchgröße dynamisch auf der Grundlage der Zeilengröße. |
Nein |
| writeBatchTimeout | Die Wartezeit für den Abschluss der Insert- und Upsert-Vorgänge und die gespeicherte Prozedur, bevor ein Timeout auftritt. Zulässige Werte werden für den Zeitraum verwendet. Beispiel: „00:30:00“ für 30 Minuten. Wenn kein Wert festgelegt ist, wird für das Timeout der Standardwert „00:30:00“ verwendet. |
Nein |
| maxConcurrentConnections | Die Obergrenze gleichzeitiger Verbindungen mit dem Datenspeicher während der Aktivitätsausführung. Geben Sie diesen Wert nur an, wenn Sie die Anzahl der gleichzeitigen Verbindungen begrenzen möchten. | Nein |
| WriteBehavior | Geben Sie das Schreibverhalten für die Kopieraktivität an, um Daten in die SQL Server-Datenbank-Instanz zu laden. Die zulässigen Werte sind Insert und Upsert. Standardmäßig verwendet der Dienst „Insert“, um Daten zu laden. |
Nein |
| upsertSettings | Geben Sie die Gruppe der Einstellungen für das Schreibverhalten an. Wenden Sie dies an, wenn die WriteBehavior-Option Upsert ist. |
Nein |
Unter upsertSettings: |
||
| useTempDB | Geben Sie an, ob eine globale temporäre Tabelle oder eine physische Tabelle als Zwischentabelle für Upserts verwendet werden soll. Standardmäßig verwendet der Dienst eine globale temporäre Tabelle als Zwischentabelle. Der Wert lautet true. |
Nein |
| interimSchemaName | Geben Sie das Zwischenschema zum Erstellen einer Zwischentabelle an, wenn eine physische Tabelle verwendet wird. Hinweis: Benutzer müssen über die Berechtigung zum Erstellen und Löschen einer Tabelle verfügen. Standardmäßig verwendet die Zwischentabelle das gleiche Schema wie die Senkentabelle. Wird angewendet, wenn die useTempDB-Option False lautet. |
Nein |
| keys | Geben Sie die Spaltennamen für die eindeutige Zeilenidentifikation an. Es kann entweder ein einzelner Schlüssel oder eine Reihe von Schlüsseln verwendet werden. Bei fehlender Angabe wird der Primärschlüssel verwendet. | Nein |
Beispiel 1: Anfügen von Daten
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBatchSize": 100000
}
}
}
]
Beispiel 2: Aufrufen einer gespeicherten Prozedur während des Kopiervorgangs
Weitere Informationen finden Sie unter Aufrufen einer gespeicherten Prozedur aus einer SQL-Senke.
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"sqlWriterStoredProcedureName": "CopyTestStoredProcedureWithParameters",
"storedProcedureTableTypeParameterName": "MyTable",
"sqlWriterTableType": "MyTableType",
"storedProcedureParameters": {
"identifier": { "value": "1", "type": "Int" },
"stringData": { "value": "str1" }
}
}
}
}
]
Beispiel 3: Upsert-Daten
"activities":[
{
"name": "CopyToSQLServer",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<SQL Server output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "SqlSink",
"tableOption": "autoCreate",
"writeBehavior": "upsert",
"upsertSettings": {
"useTempDB": true,
"keys": [
"<column name>"
]
},
}
}
}
]
Paralleles Kopieren aus SQL-Datenbank
Der SQL Server-Connector in der Kopieraktivität verfügt über eine integrierte Datenpartitionierung zum parallelen Kopieren von Daten. Die Datenpartitionierungsoptionen befinden sich auf der Registerkarte Quelle der Kopieraktivität.
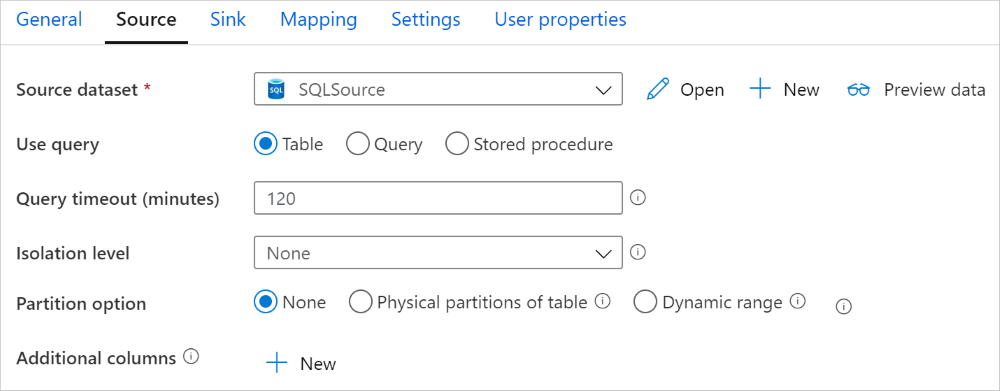
Wenn Sie partitioniertes Kopieren aktivieren, führt die Kopieraktivität parallele Abfragen für Ihre SQL Server-Quelle aus, um Daten anhand von Partitionen zu laden. Der Parallelitätsgrad wird über die Einstellung parallelCopies der Kopieraktivität gesteuert. Wenn Sie z. B. parallelCopies auf vier (4) festlegen, generiert der Dienst gleichzeitig vier Abfragen auf der Grundlage der von Ihnen angegebenen Partitionsoption und -einstellungen und führt sie aus. Dabei ruft jede Abfrage einen Teil der Daten von SQL Server ab.
Es wird empfohlen, das parallele Kopieren mit Datenpartitionierung zu aktivieren. Das gilt insbesondere, wenn Sie große Datenmengen aus Ihrer SQL Server-Instanz laden. Im Anschluss finden Sie empfohlene Konfigurationen für verschiedene Szenarien. Beim Kopieren von Daten in einen dateibasierten Datenspeicher wird empfohlen, mehrere Dateien in einen Ordner zu schreiben (nur den Ordnernamen anzugeben). In diesem Fall ist die Leistung besser als beim Schreiben in eine einzelne Datei.
| Szenario | Empfohlene Einstellungen |
|---|---|
| Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen |
Partitionsoption: Physische Partitionen der Tabelle. Während der Ausführung erkennt der Dienst automatisch die physischen Partitionen und kopiert Daten nach Partitionen. Um zu überprüfen, ob Ihre Tabelle eine physische Partition besitzt oder nicht, können Sie auf diese Abfrage verweisen. |
| Vollständiges Laden aus einer großen Tabelle ohne physische Partitionen, aber mit einer integer- oder datetime-Spalte für die Datenpartitionierung. |
Partitionsoptionen: Partition des dynamischen Bereichs Partitionsspalte (optional): Geben Sie die Spalte für die Datenpartitionierung an. Ohne Angabe wird die Primärschlüsselspalte verwendet. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen in der Tabelle werden partitioniert und kopiert. Wenn keine Angabe erfolgt, erkennt die Copy-Aktivität die Werte automatisch und kann je nach MIN- und MAX-Werten lange dauern. Es wird empfohlen, Ober- und Untergrenzen anzugeben. Wenn Ihre Partitionsspalte "ID" beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20 und die obere Grenze auf 80 und die Parallelkopie auf 4 setzen, ruft der Dienst Daten nach 4 Partitionen ab - IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. |
| Laden einer großen Datenmenge unter Verwendung einer benutzerdefinierten Abfrage ohne physische Partitionen, aber mit einer integer- oder date/datetime-Spalte für die Datenpartitionierung. |
Partitionsoptionen: Partition des dynamischen Bereichs Abfrage: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>Partitionsspalte: Geben Sie die Spalte an, die zum Partitionieren von Daten verwendet wird. Obergrenze der Partition und Untergrenze der Partition (optional): Geben Sie an, ob Sie den Partitionssprung bestimmen möchten. Dies dient nicht zum Filtern der Zeilen in der Tabelle; alle Zeilen im Abfrageergebnis werden partitioniert und kopiert. Wenn nicht angegeben, wird der Wert für die Kopieraktivität automatisch erkannt. Wenn Ihre Partitionsspalte „ID“ beispielsweise einen Wertebereich von 1 bis 100 hat und Sie die untere Grenze auf 20, die obere Grenze auf 80 und die Parallelkopie auf 4 festlegen, ruft der Dienst Daten nach 4 Partitionen ab – IDs im Bereich <=20, [21, 50], [51, 80] bzw. >=81. Hier finden Sie weitere Beispiele für verschiedene Szenarien: 1. Abfragen der gesamten Tabelle: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Abfragen aus einer Tabelle mit Spaltenauswahl und zusätzlichen WHERE-Klausel-Filtern: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Abfragen mit Unterabfragen: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Abfragen mit Partition in Unterabfrage: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Bewährte Methoden zum Laden von Daten mit Partitionierungsoption:
- Wählen Sie eine aussagekräftige Spalte als Partitionsspalte (wie Primärschlüssel oder eindeutiger Schlüssel), um Datenabweichungen zu vermeiden.
- Wenn die Tabelle eine integrierte Partition aufweist, verwenden Sie die Partitionsoption „Physikalische Partitionen der Tabelle“, um eine bessere Leistung zu erzielen.
- Wenn Sie Azure Integration Runtime zum Kopieren von Daten verwenden, können Sie größere „Datenintegrationseinheiten (Data Integration Units, DIU)“ festlegen (> 4), um mehr Computingressourcen zu nutzen. Prüfen Sie dort die anwendbaren Szenarien.
- „Grad der Kopierparallelität“ steuert die Partitionsnummern. Ein zu großer Wert schadet manchmal der Leistung. Deshalb wird empfohlen, diesen Wert wie folgt festzulegen: (DIU oder Anzahl der selbstgehosteten IR-Knoten) × (2 bis 4).
Beispiel: Vollständiges Laden aus einer großen Tabelle mit physischen Partitionen
"source": {
"type": "SqlSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Beispiel: Abfrage mit dynamischer Bereichspartition
"source": {
"type": "SqlSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Beispielabfrage zur Überprüfung der physischen Partition
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Wenn die Tabelle eine physische Partition besitzt, würde „HasPartition“ wie folgt als „Yes“ (Ja) angezeigt werden.

Bewährte Methode zum Laden von Daten in SQL Server
Wenn Sie Daten in SQL Server kopieren, ist möglicherweise ein anderes Schreibverhalten erforderlich:
- Anfügen: Meine Quelldaten enthalten nur neue Datensätze.
- Upsert: Meine Quelldaten umfassen sowohl Einfügungen als auch Aktualisierungen.
- Überschreiben: Ich möchte die gesamte Dimensionstabelle jedes Mal neu laden.
- Schreiben von Daten mit benutzerdefinierter Logik: Ich benötige eine zusätzliche Verarbeitung vor dem endgültigen Einfügen in die Zieltabelle.
Informationen zur Konfiguration und zu bewährten Methoden finden Sie in den entsprechenden Abschnitten.
Anfügen von Daten
Das Anfügen von Daten stellt das Standardverhalten dieses SQL Server-Senkenconnectors dar. Der Dienst führt eine Masseneinfügung durch, um effizient in Ihre Tabelle zu schreiben. Sie können die Quelle und Senke in der Kopieraktivität entsprechend konfigurieren.
Durchführen von Upsert für Daten
Die Kopieraktivität unterstützt ab sofort das native Laden von Daten in eine temporäre Datenbanktabelle und das anschließende Aktualisieren der Daten in der Senkentabelle, wenn der Schlüssel vorhanden ist. Andernfalls werden neue Daten eingefügt. Weitere Informationen zu upsert-Einstellungen in Kopieraktivitäten finden Sie unter SQL Server als Senke.
Überschreiben der gesamten Tabelle
Sie können die preCopyScript-Eigenschaft in einer Kopieraktivitätssenke konfigurieren. In diesem Fall führt Azure Data Factory für jede ausgeführte Copy-Aktivität zuerst das Skript aus. Dann wird der Kopiervorgang ausgeführt, um die Daten einzufügen. Beispiel: Um die gesamte Tabelle mit den neuesten Daten zu überschreiben, geben Sie ein Skript an, um zunächst alle Datensätze zu löschen, bevor die neuen Daten durch Massenladen aus der Quelle eingefügt werden.
Schreiben von Daten mit benutzerdefinierter Logik
Die Schritte zum Schreiben von Daten mit benutzerdefinierter Logik ähneln den im Abschnitt Durchführen von Upsert für Daten beschriebenen Schritten. Wenn vor dem Einfügen von Quelldaten in die Zieltabelle weitere Verarbeitungsschritte erforderlich sind, können Sie die Daten in eine Stagingtabelle laden und dann Aktivitäten einer gespeicherten Prozedur oder eine gespeicherte Prozedur in der Kopieraktivität der Senke aufrufen, um die Daten anzuwenden.
Aufrufen der gespeicherten Prozedur von der SQL-Senke
Beim Kopieren von Daten in eine SQL Server-Datenbank können Sie auch eine vom Benutzer angegebene gespeicherte Prozedur mit zusätzlichen Parametern für jeden Batch der Quelltabelle konfigurieren und aufrufen. Das Feature der gespeicherten Prozedur nutzt Tabellenwertparameter. Beachten Sie, dass der Dienst die gespeicherte Prozedur automatisch in seine eigene Transaktion umschließt, sodass jede in der gespeicherten Prozedur erstellte Transaktion zu einer geschachtelten Transaktion wird und Auswirkungen auf die Ausnahmebehandlung haben kann.
Sie können eine gespeicherte Prozedur nutzen, wenn integrierte Kopiermechanismen nicht den Zweck erfüllen. Ein Beispiel hierfür ist ein Szenario, in dem Sie vor dem endgültigen Einfügen von Quelldaten in die Zieltabelle eine zusätzliche Verarbeitung anwenden möchten. Beispiele für eine zusätzliche Verarbeitung sind das Zusammenführen von Spalten, das Suchen nach zusätzlichen Werten und das Einfügen in mehr als eine Tabelle.
Das folgende Beispiel zeigt, wie Sie eine gespeicherte Prozedur verwenden, um einen einfachen Upsert-Vorgang in eine Tabelle in der SQL Server-Datenbank auszuführen. Wenn Eingabedaten vorhanden sind und die Senkentabelle Marketing heißt, sind drei Spalten vorhanden: ProfileID, State und Category. Führen Sie den Upsert-Vorgang basierend auf der Spalte ProfileID aus, und wenden Sie ihn nur auf die Kategorie „ProductA“ an.
Definieren Sie in Ihrer Datenbank den Tabellentyp mit dem gleichen Namen wie sqlWriterTableType. Das Schema des Tabellentyps muss mit dem Schema übereinstimmen, das von den Eingabedaten zurückgegeben wird.
CREATE TYPE [dbo].[MarketingType] AS TABLE( [ProfileID] [varchar](256) NOT NULL, [State] [varchar](256) NOT NULL, [Category] [varchar](256) NOT NULL )Definieren Sie die gespeicherte Prozedur in Ihrer Datenbank mit demselben Namen wie SqlWriterStoredProcedureName. Sie verarbeitet die Eingabedaten aus der angegebenen Quelle und führt sie mit der Ausgabetabelle zusammen. Der Parametername des Tabellentyps in der gespeicherten Prozedur entspricht dem im Dataset definierten tableName.
CREATE PROCEDURE spOverwriteMarketing @Marketing [dbo].[MarketingType] READONLY, @category varchar(256) AS BEGIN MERGE [dbo].[Marketing] AS target USING @Marketing AS source ON (target.ProfileID = source.ProfileID and target.Category = @category) WHEN MATCHED THEN UPDATE SET State = source.State WHEN NOT MATCHED THEN INSERT (ProfileID, State, Category) VALUES (source.ProfileID, source.State, source.Category); ENDDefinieren Sie den Abschnitt SqlSink in der Kopieraktivität wie folgt:
"sink": { "type": "SqlSink", "sqlWriterStoredProcedureName": "spOverwriteMarketing", "storedProcedureTableTypeParameterName": "Marketing", "sqlWriterTableType": "MarketingType", "storedProcedureParameters": { "category": { "value": "ProductA" } } }
Eigenschaften von Mapping Data Flow
Beim Transformieren von Daten im Zuordnungsdatenfluss können Sie Tabellen in der SQL Server-Datenbank lesen und in diese schreiben. Weitere Informationen finden Sie unter Quellentransformation und Senkentransformation in Zuordnungsdatenflüssen.
Hinweis
Um auf eine lokale SQL Server-Instanz zugreifen zu können, müssen Sie den Azure Data Factory- und Synapse-Arbeitsbereich als verwaltetes virtuelles Netzwerk mit einem privaten Endpunkt verwenden. Ausführliche Schritte finden Sie in diesem Tutorial.
Quellentransformation
In der folgenden Tabelle sind die von einer SQL Server-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Tabelle | Wenn Sie „Tabelle“ als Eingabe auswählen, ruft der Datenfluss alle Daten aus der im Dataset angegebenen Tabelle ab. | Nein | - | - |
| Abfrage | Wenn Sie „Abfrage“ als Eingabe auswählen, geben Sie eine SQL-Abfrage zum Abrufen von Daten aus der Quelle an, die Vorrang vor jeder im Dataset angegebenen Tabelle hat. Die Verwendung von Abfragen stellt eine gute Möglichkeit dar, um die Zeilen für Tests oder Suchvorgänge zu verringern. Die Order By-Klausel wird nicht unterstützt. Sie können aber eine vollständige SELECT FROM-Anweisung festlegen. Sie können auch benutzerdefinierte Tabellenfunktionen verwenden. select * from udfGetData() ist eine benutzerdefinierte Funktion in SQL, mit der eine Tabelle zurückgegeben wird, die Sie im Datenfluss verwenden können. Abfragebeispiel: Select * from MyTable where customerId > 1000 and customerId < 2000 |
Nein | String | Abfrage |
| Batchgröße | Geben Sie eine Batchgröße an, um große Datenmengen in Leseblöcke zu segmentieren. | Nein | Integer | batchSize |
| Isolationsstufe | Wählen Sie eine der folgenden Isolationsstufen aus: – Lesen zugesichert – Lesen nicht zugesichert (Standard) – Wiederholbarer Lesevorgang – Serialisierbar – Keine (Isolationsstufe ignorieren) |
Nein | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZABLE Keine |
isolationLevel |
| Inkrementelle Extrahierung aktivieren | Verwenden Sie diese Option, um ADF mitzuteilen, dass nur Zeilen verarbeitet werden sollen, die seit der letzten Ausführung der Pipeline geändert wurden. | Nein | - | - |
| Spalte für inkrementelles Datum | Wenn Sie das Feature für die inkrementelle Extrahierung verwenden, müssen Sie die Datums-/Uhrzeitspalte auswählen, die Sie als Grenzwert in der Quelltabelle verwenden möchten. | Nein | - | - |
| Natives Change Data Capture aktivieren (Vorschau) | Verwenden Sie diese Option, um ADF mitzuteilen, dass nur Deltadaten verarbeitet werden, die seit dem letzten Ausführen der Pipeline von der SQL-Change Data Capture-Technologie erfasst wurden. Mit dieser Option werden die Deltadaten einschließlich Einfügen, Aktualisieren und Löschen von Zeilen automatisch geladen, ohne dass eine inkrementelle Datumsspalte erforderlich ist. Sie müssen in SQL Server Change Data Capture aktivieren, bevor Sie diese Option in ADF verwenden. Weitere Informationen zu dieser Option in ADF finden Sie unter Natives Change Data Capture. | Nein | - | - |
| Lesen von Anfang an beginnen | Wenn Sie diese Option mit der inkrementellen Extrahierung festlegen, wird ADF angewiesen, alle Zeilen bei der ersten Ausführung einer Pipeline zu lesen, wenn die inkrementelle Extrahierung aktiviert ist. | Nein | - | - |
Tipp
Der allgemeine Tabellenausdruck (CTE) in SQL wird im Abfragemodus des Zuordnungsdatenflusses nicht unterstützt, da dieser Modus voraussetzt, dass Abfragen in der FROM-Klausel der SQL-Abfrage verwendet werden können, was CTEs jedoch nicht tun können. Um CTEs zu verwenden, müssen Sie eine gespeicherte Prozedur mithilfe der folgenden Abfrage erstellen:
CREATE PROC CTESP @query nvarchar(max)
AS
BEGIN
EXECUTE sp_executesql @query;
END
Verwenden Sie dann den Modus Gespeicherte Prozedur in der Quellentransformation des Zuordnungsdatenflusses, und legen Sie @query wie im Beispiel with CTE as (select 'test' as a) select * from CTE fest. Daraufhin können Sie CTEs wie erwartet verwenden.
Beispiel für ein SQL Server-Quellskript
Wenn Sie SQL Server als Quelltyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from MYTABLE',
format: 'query') ~> SQLSource
Senkentransformation
In der folgenden Tabelle sind die von einer SQL Server-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Senkenoptionen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Updatemethode | Geben Sie an, welche Vorgänge für das Datenbankziel zulässig sind. Standardmäßig sind lediglich Einfügevorgänge zulässig. Um Aktualisierungs-, Upsert- oder Löschaktionen auf Zeilen anzuwenden, muss eine Zeilenänderungstransformation zum Kennzeichnen von Zeilen für diese Aktionen erfolgen. |
Ja |
true oder false |
deletable insertable updateable upsertable |
| Schlüsselspalten | Für Update-, Upsert- und Löschvorgänge müssen Schlüsselspalten festgelegt werden, um die Zeile zu bestimmen, die geändert werden soll. Der Spaltenname, den Sie als Schlüssel auswählen, wird als Teil der nachfolgenden Update-, Upsert- und Löschvorgänge verwendet. Daher müssen Sie eine Spalte auswählen, die in der Senkenzuordnung vorhanden ist. |
Nein | Array | keys |
| Schreiben von Schlüsselspalten überspringen | Wenn Sie den Wert nicht in die Schlüsselspalte schreiben möchten, wählen Sie „Schreiben von Schlüsselspalten überspringen“ aus. | Nein |
true oder false |
skipKeyWrites |
| Aktion table | Bestimmt, ob die Zieltabelle vor dem Schreiben neu erstellt werden soll oder alle Zeilen aus der Zieltabelle entfernt werden sollen. - Keine: Es wird keine Aktion an der Tabelle vorgenommen. - Neu erstellen: Die Tabelle wird gelöscht und neu erstellt. Erforderlich, wenn eine neue Tabelle dynamisch erstellt wird. - Abschneiden: Alle Zeilen werden aus der Zieltabelle entfernt. |
Nein |
true oder false |
Neu erstellen truncate |
| Batchgröße | Geben Sie an, wie viele Zeilen in die einzelnen Batches geschrieben werden. Durch größere Batches werden zwar Komprimierung und Arbeitsspeicheroptimierung verbessert, beim Zwischenspeichern von Daten besteht aber die Gefahr, dass Ausnahmen wegen unzureichenden Arbeitsspeichers auftreten. | Nein | Integer | batchSize |
| Pre- und Post-SQL-Skripts | Geben Sie mehrzeilige SQL-Skripts an, die ausgeführt werden, bevor Daten in die Senkendatenbank geschrieben werden (Vorverarbeitung) und danach (Nachbearbeitung). | Nein | String | preSQLs postSQLs |
Tipp
- Es wird empfohlen, einzelne Batchskripts mit mehreren Befehlen in mehrere Batches aufzuteilen.
- In einem Batch können nur DDL- (Data Definition Language) und DML-Anweisungen (Data Manipulation Language) ausgeführt werden, die eine einfache Updatezählung zurückgeben. Weitere Informationen finden Sie unter Ausführen von Batchvorgängen.
Beispiel für ein SQL Server-Senkenskript
Wenn Sie SQL Server als Senkentyp verwenden, sieht das zugehörige Datenflussskript wie folgt aus:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> SQLSink
Datentypzuordnung für SQL Server
Beim Kopieren von Daten aus und in SQL Server werden die folgenden Zuordnungen von SQL Server-Datentypen zu Azure Data Factory-Zwischendatentypen verwendet. Synapse-Pipelines, die Data Factory implementieren, verwenden die gleichen Zuordnungen. Informationen dazu, wie die Kopieraktivität das Quellschema und den Datentyp zur Senke zuordnet, finden Sie unter Schema- und Datentypzuordnungen.
| SQL Server-Datentyp | Data Factory-Zwischendatentyp |
|---|---|
| BIGINT | Int64 |
| BINARY | Byte[] |
| bit | Boolean |
| char | String; Char[] |
| date | Datetime |
| Datetime | Datetime |
| datetime2 | Datetime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| FILESTREAM-Attribut (varbinary(max)) | Byte[] |
| Float | Double |
| image | Byte[] |
| INT | Int32 |
| money | Decimal |
| NCHAR | String; Char[] |
| ntext | String; Char[] |
| NUMERIC | Decimal |
| NVARCHAR | String; Char[] |
| real | Single |
| rowversion | Byte[] |
| smalldatetime | Datetime |
| SMALLINT | Int16 |
| SMALLMONEY | Decimal |
| sql_variant | Object |
| text | String; Char[] |
| time | TimeSpan |
| timestamp | Byte[] |
| TINYINT | Int16 |
| UNIQUEIDENTIFIER | Guid |
| varbinary | Byte[] |
| varchar | String; Char[] |
| Xml | String |
Hinweis
Für Datentypen, die dem Zwischendatentyp „Decimal“ zugeordnet sind, unterstützt die Kopieraktivität derzeit eine Genauigkeit von bis zu 28. Wenn Ihre Daten eine höhere Genauigkeit als 28 erfordern, erwägen Sie, sie per SQL-Abfrage in eine Zeichenfolge zu konvertieren.
Beim Kopieren von Daten aus SQL Server mithilfe von Azure Data Factory wird der Bitdatentyp dem booleschen Zwischendatentyp zugeordnet. Wenn Sie über Daten verfügen, die als Bitdatentyp beibehalten werden müssen, verwenden Sie Abfragen mit T-SQL CAST oder CONVERT.
Eigenschaften der Lookup-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter Lookup-Aktivität.
Eigenschaften der GetMetadata-Aktivität
Ausführliche Informationen zu den Eigenschaften finden Sie unter GetMetadata-Aktivität.
Verwenden von Always Encrypted
Führen Sie beim Kopieren von Daten aus bzw. in SQL Server mit Always Encrypteddie folgenden Schritte aus:
Speichern Sie den Spalten-Hauptschlüssel (Column Master Key, CMK) in einem Azure Key Vault. Weitere Informationen: Konfigurieren von Always Encrypted mithilfe von Azure Key Vault
Stellen Sie sicher, dass der Zugriff auf den Schlüsseltresor gewährt wird, in dem der Spaltenhauptschlüssel (Column Master Key, CMK) gespeichert ist. Die erforderlichen Berechtigungen finden Sie in diesem Artikel.
Erstellen Sie einen verknüpften Dienst, um eine Verbindung mit der SQL-Datenbank herzustellen und aktivieren Sie die „Always Encrypted“-Funktion mithilfe einer verwalteten Identität oder eines Dienstprinzipals.
Hinweis
Der SQL Server Always Encrypted unterstützt die folgenden Szenarien:
- Die Quell- oder Senkendatenspeicher verwenden die verwaltete Identität oder den Dienstprinzipal als Schlüsselanbieter-Authentifizierungstyp.
- Sowohl Quell- als auch Senkendatenspeicher verwenden die verwaltete Identität als Schlüsselanbieter-Authentifizierungstyp.
- Sowohl Quell- als auch Senkendatenspeicher verwenden denselben Dienstprinzipal als Schlüsselanbieter-Authentifizierungstyp.
Hinweis
Derzeit wird Always Encrypted für SQL Server nur für die Quelltransformation in Zuordnungsdatenflüssen unterstützt.
Natives Change Data Capture
Azure Data Factory kann native Change Data Capture-Funktionen für SQL Server, Azure SQL DB und Azure SQL MI unterstützen. Die geänderten Daten einschließlich Einfügen, Aktualisieren und Löschen von Zeilen in SQL-Speichern können durch den ADF-Zuordnungsdatenfluss automatisch erkannt und extrahiert werden. Mit der No-Code-Benutzeroberfläche im Zuordnungsdatenfluss können Benutzer ganz einfach ein Datenreplikationsszenario aus SQL-Speichern einrichten, indem sie eine Datenbank als Zielspeicher anhängen. Darüber hinaus können Benutzer auch eine beliebige Datentransformationslogik zwischenschalten, um ein inkrementelles ETL-Szenario aus SQL-Speichern zu erreichen.
Stellen Sie sicher, dass Sie die Pipeline und den Aktivitätsnamen unverändert lassen, damit der Prüfpunkt von ADF aufgezeichnet werden kann, damit Sie geänderte Daten aus der letzten Ausführung automatisch erhalten. Wenn Sie ihren Pipelinenamen oder Aktivitätsnamen ändern, wird der Prüfpunkt zurückgesetzt, was dazu führt, dass Sie bei der nächsten Ausführung von Anfang an beginnen oder Änderungen von jetzt erhalten. Wenn Sie den Pipelinenamen oder Aktivitätsnamen ändern möchten, aber weiterhin den Prüfpunkt beibehalten möchten, um geänderte Daten aus der letzten Ausführung automatisch abzurufen, verwenden Sie hierzu bitte Ihren eigenen Prüfpunktschlüssel in der Datenflussaktivität.
Wenn Sie die Pipeline debuggen, funktioniert dieses Feature genauso. Beachten Sie, dass der Prüfpunkt zurückgesetzt wird, wenn Sie Ihren Browser während der Debug-Ausfürung aktualisieren. Wenn Sie mit dem Pipelineergebnis der Debug-Ausführung zufrieden sind, können Sie die Pipeline veröffentlichen und auslösen. Wenn Sie ihre veröffentlichte Pipeline zum ersten Mal auslösen, wird sie automatisch von Anfang an neu gestartet oder erhält von nun an Änderungen.
Im Abschnitt „Überwachung“ haben Sie immer die Möglichkeit, eine Pipeline erneut ausführen. Dabei werden die geänderten Daten immer vom vorherigen Prüfpunkt des ausgewählten Pipelinelaufs erfasst.
Beispiel 1:
Wenn Sie eine Quellentransformation, die ein SQL CDC-fähiges Dataset referenziert, direkt mit einer Senkentransformation verketten, die eine Datenbank in einem Zuordnungsdatenfluss referenziert, werden die in der SQL-Quelle vorgenommenen Änderungen automatisch auf die Zieldatenbank angewendet, sodass Sie ganz einfach ein Datenreplikationsszenario zwischen Datenbanken erhalten. Sie können die Updatemethode in der Senkentransformation verwenden, um auszuwählen, ob Sie Einfüge-, Aktualisierungs- oder Löschvorgänge in der Zieldatenbank zulassen möchten. Unten sehen Sie das Beispielskript im Zuordnungsdatenfluss.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 sink(allowSchemaDrift: true,
validateSchema: false,
deletable:true,
insertable:true,
updateable:true,
upsertable:true,
keys:['id'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true,
errorHandlingOption: 'stopOnFirstError') ~> sink1
Beispiel 2:
Wenn Sie ein ETL-Szenario anstelle der Datenreplikation zwischen Datenbanken über SQL CDC aktivieren möchten, können Sie im Zuordnungsdatenfluss Ausdrücke einschließlich isInsert(1), isUpdate(1) und isDelete(1) verwenden, um die Zeilen mit unterschiedlichen Vorgangstypen zu unterscheiden. Nachfolgend sehen Sie eines der Beispielskripts für den Zuordnungsdatenfluss zur Ableitung einer Spalte mit dem Wert 1 zur Kennzeichnung eingefügter Zeilen, 2 zur Kennzeichnung aktualisierter Zeilen und 3 zur Kennzeichnung gelöschter Zeilen für Downstreamtransformationen zur Verarbeitung der Deltadaten.
source(output(
id as integer,
name as string
),
allowSchemaDrift: true,
validateSchema: false,
enableNativeCdc: true,
netChanges: true,
skipInitialLoad: false,
isolationLevel: 'READ_UNCOMMITTED',
format: 'table') ~> source1
source1 derive(operationType = iif(isInsert(1), 1, iif(isUpdate(1), 2, 3))) ~> derivedColumn1
derivedColumn1 sink(allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink1
Bekannte Einschränkung:
- Nur Nettoänderungen von SQL CDC werden von ADF über cdc.fn_cdc_get_net_changes_ geladen.
Beheben von Verbindungsproblemen
Konfigurieren Sie Ihre SQL Server-Instanz für das Zulassen von Remoteverbindungen. Starten Sie SQL Server Management Studio, klicken Sie mit der rechten Maustaste auf Server, und wählen Sie Eigenschaften aus. Wählen Sie in der Liste den Eintrag Verbindungen aus, und aktivieren Sie das Kontrollkästchen Remoteverbindungen mit diesem Server zulassen.
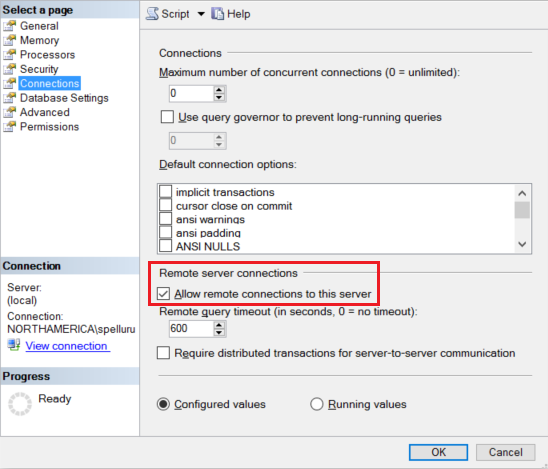
Ausführliche Schritte finden Sie unter Konfigurieren der Serverkonfigurationsoption „Remotezugriff“.
Starten Sie den SQL Server-Konfigurations-Manager. Erweitern Sie SQL Server-Netzwerkkonfiguration für die gewünschte Instanz, und wählen Sie Protokolle für MSSQLSERVER aus. Die Protokolle werden im rechten Bereich angezeigt. Aktivieren Sie TCP/IP, indem Sie mit der rechten Maustaste auf TCP/IP klicken und Aktivieren auswählen.
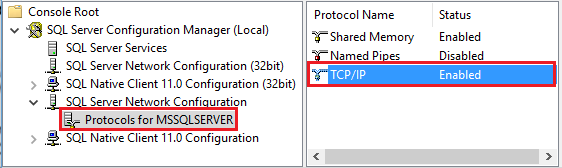
Weitere Informationen und alternative Methoden zum Aktivieren von TCP/IP finden Sie unter Aktivieren oder Deaktivieren eines Servernetzwerkprotokolls.
Doppelklicken Sie im gleichen Fenster auf TCP/IP, um das Fenster TCP/IP-Eigenschaften zu öffnen.
Wechseln Sie zur Registerkarte IP-Adressen. Scrollen Sie nach unten zum Abschnitt IPAll. Notieren Sie sich den TCP-Port. Der Standardport ist 1433.
Erstellen Sie auf dem Computer eine Regel für die Windows-Firewall , um eingehenden Datenverkehr über diesen Port zuzulassen.
Verbindung überprüfen:Verwenden Sie SQL Server Management Studio auf einem anderen Computer, um mit dem vollqualifizierten Namen eine Verbindung mit der SQL Server-Instanz herzustellen. z. B.
"<machine>.<domain>.corp.<company>.com,1433".
Upgrade der SQL Server-Version
Zum Upgrade der SQL Server-Version wählen Sie auf der Seite Verknüpften Dienst bearbeiten unter Version die Option Empfohlen aus, und konfigurieren Sie den verknüpften Dienst. Beziehen Sie sich dabei auf Eigenschaften des verknüpften Diensts für die empfohlene Version.
Unterschiede zwischen der empfohlenen Version und der Legacyversion
In der nachstehenden Tabelle sind die Unterschiede zwischen SQL Server unter Verwendung der empfohlenen Version und der Legacyversion dargestellt.
| Empfohlene Version | Legacy-Version |
|---|---|
Unterstützung von TLS 1.3 über encrypt als strict. |
TLS 1.3 wird nicht unterstützt. |
Verwandte Inhalte
Eine Liste der Datenspeicher, die als Quellen und Senken für die Kopieraktivität unterstützt werden, finden Sie unter Unterstützte Datenspeicher.