Transformation für abgeleitete Spalten in Mapping Data Flow
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Testen Sie Data Factory in Microsoft Fabric, eine All-in-One-Analyselösung für Unternehmen. Microsoft Fabric deckt alle Aufgaben ab, von der Datenverschiebung bis hin zu Data Science, Echtzeitanalysen, Business Intelligence und Berichterstellung. Erfahren Sie, wie Sie kostenlos eine neue Testversion starten!
Datenflüsse sind sowohl in Azure Data Factory als auch in Azure Synapse-Pipelines verfügbar. Dieser Artikel gilt für Zuordnungsdatenflüsse. Wenn Sie noch nicht mit Transformationen arbeiten, lesen Sie den Einführungsartikel Transformieren von Daten mit einem Zuordnungsdatenfluss.
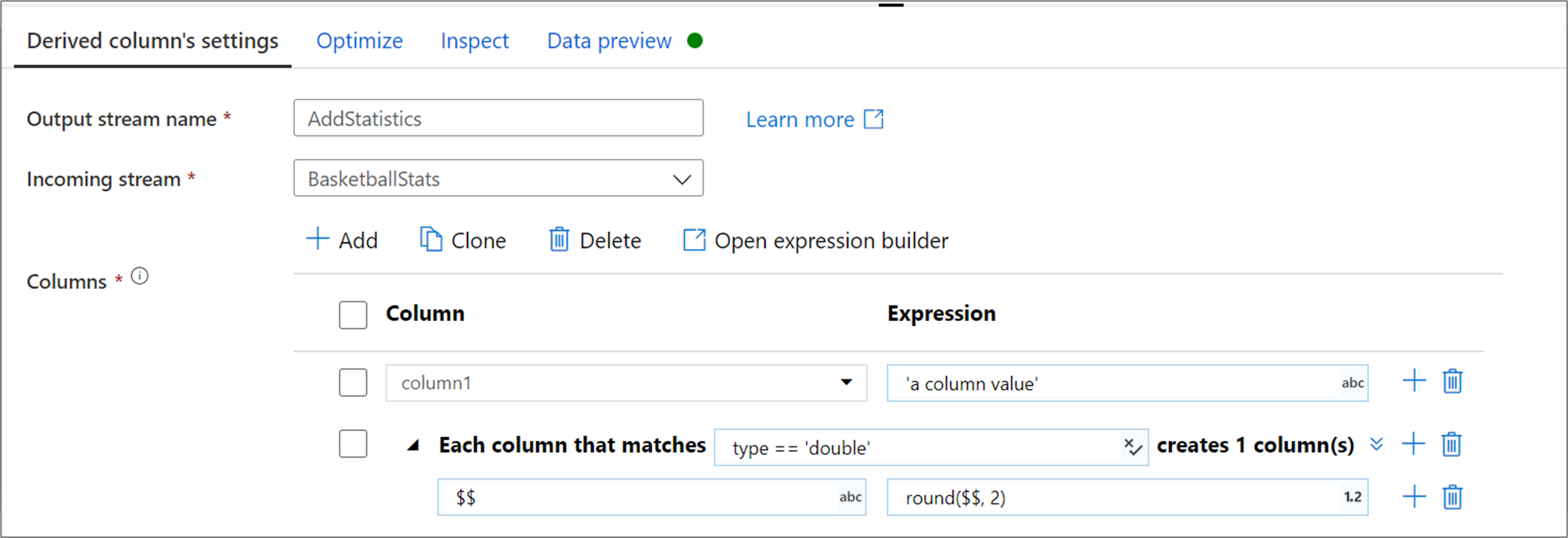
Verwenden Sie die Transformation für abgeleitete Spalten, um in Ihrem Datenfluss neue Spalten zu generieren oder vorhandene Felder zu ändern.
Erstellen und Aktualisieren von Spalten
Beim Erstellen einer abgeleiteten Spalte können Sie entweder eine neue Spalte generieren oder eine vorhandene Spalte aktualisieren. Geben Sie im Textfeld Spalte die Spalte ein, die Sie erstellen. Wenn Sie eine vorhandene Spalte in Ihrem Schema überschreiben möchten, können Sie die Dropdownliste für Spalten verwenden. Um den Ausdruck der abgeleiteten Spalte zu erstellen, klicken Sie auf das Textfeld Ausdruck eingeben. Sie können entweder mit dem Eingeben des Ausdrucks beginnen oder den Ausdrucks-Generator öffnen, um die Logik zu erstellen.

Wenn Sie weitere abgeleitete Spalten hinzufügen möchten, klicken Sie oberhalb der Spaltenliste auf Hinzufügen, oder klicken Sie auf das Pluszeichen („+“) neben einer vorhandenen abgeleiteten Spalte. Klicken Sie entweder auf Spalte hinzufügen oder auf Spaltenmuster hinzufügen.

Spaltenmuster
In Fällen, in denen Ihr Schema nicht explizit definiert ist, oder wenn Sie eine Reihe von Spalten in einem Massenvorgang aktualisieren möchten, sollten Sie Spaltenmuster erstellen. Mithilfe von Spaltenmustern können Sie Spalten anhand von Regeln abgleichen, die auf den Spaltenmetadaten basieren, und abgeleitete Spalten für jede übereinstimmende Spalte erstellen. Weitere Informationen finden Sie unter Erstellen von Spaltenmustern in der Transformation für abgeleitete Spalten.
Erstellen von Schemas mit dem Ausdrucks-Generator
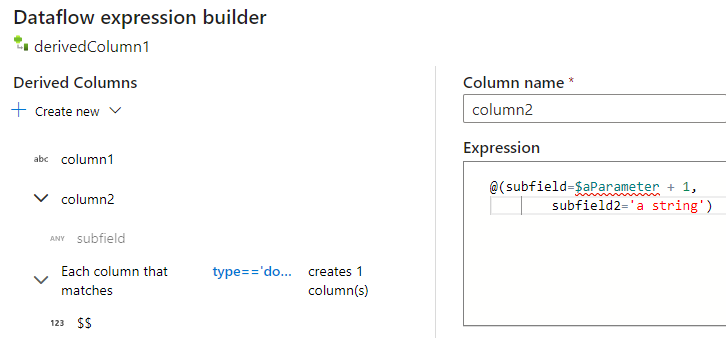
Wenn Sie den Ausdrucks-Generator für Zuordnungsdatenflüsse verwenden, können Sie Ihre abgeleiteten Spalten im Abschnitt Abgeleitete Spalten erstellen, bearbeiten und verwalten. Es werden alle in der Transformation erstellten oder geänderten Spalten aufgelistet. Sie können interaktiv auswählen, welche Spalte oder welches Muster Sie bearbeiten möchten, indem Sie auf den Spaltennamen klicken. Wenn Sie eine zusätzliche Spalte hinzufügen möchten, wählen Sie Neu erstellen aus, und wählen Sie dann aus, ob Sie eine einzelne Spalte oder ein Muster hinzufügen möchten.

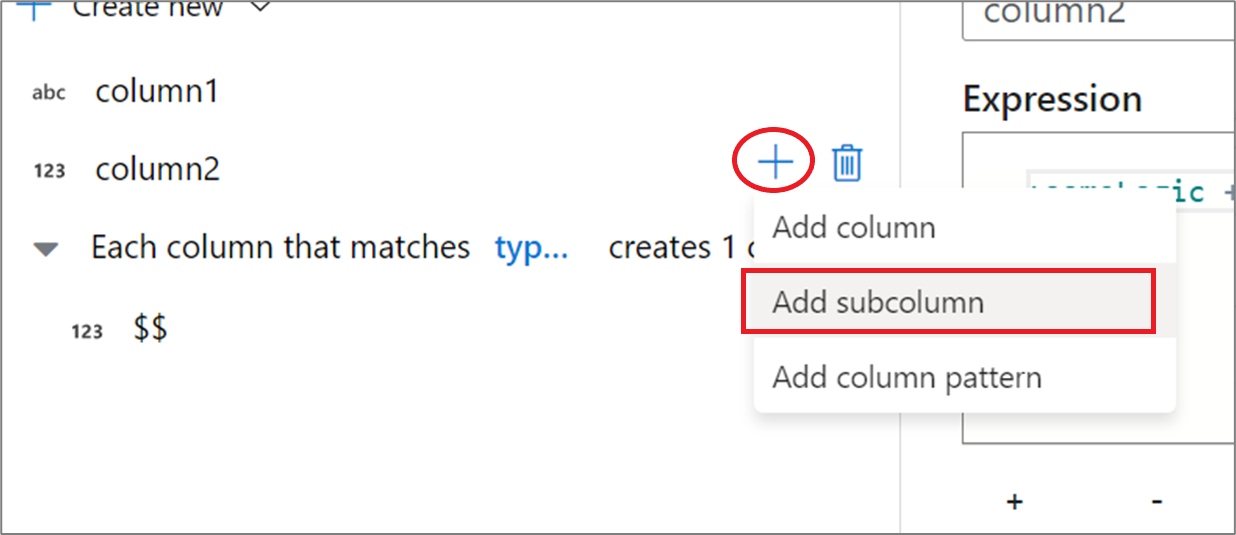
Wenn Sie mit komplexen Spalten arbeiten, können Sie Unterspalten erstellen. Klicken Sie hierzu auf das Pluszeichen („+“) neben einer beliebigen Spalte, und wählen Sie Unterspalte hinzufügen aus. Weitere Informationen zum Umgang mit komplexen Typen im Datenfluss finden Sie unter JSON-Verarbeitung mit Mapping Data Flow.
Weitere Informationen zum Umgang mit komplexen Typen im Datenfluss finden Sie unter JSON-Verarbeitung mit Mapping Data Flow.
Datenflussskript
Syntax
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Beispiel
Das folgende Beispiel ist eine abgeleitete Spalte mit dem Namen CleanData, die aus einem eingehenden Datenstrom MoviesYear zwei abgeleitete Spalten erstellt. Die erste abgeleitete Spalte ersetzt die Spalte Rating durch den Wert für „Rating“ als ganzzahliger Typ. Die zweite abgeleitete Spalte ist ein Muster, das jede Spalte abgleicht, deren Name mit „movies“ beginnt. Für jede übereinstimmende Spalte wird eine Spalte movie erstellt, die dem Wert der übereinstimmenden Spalte entspricht und das Präfix „movie_“ erhält.
In der Benutzeroberfläche sieht diese Transformation wie in der folgenden Abbildung aus:

Das Datenflussskript für diese Transformation befindet sich im folgenden Codeausschnitt:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Zugehöriger Inhalt
- Weitere Informationen finden Sie unter Mapping Data Flow expression language (Mapping Data Flow-Ausdruckssprache).