Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
GILT FÜR: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisieren, um auf neue Funktionen in data Science, Echtzeitanalysen und Berichterstellung zuzugreifen.
Nutzen Sie diesen Artikel, wenn Sie die JSON-Dateien analysieren oder Daten im JSON-Format schreiben möchten.
Das JSON-Format wird für folgende Connectors unterstützt:
- Amazon S3
- Amazon S3 Compatible Storage
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Azure Files
- Dateisystem
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Dataset-Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften, die zum Definieren von Datasets zur Verfügung stehen, finden Sie im Artikel zu Datasets. Dieser Abschnitt enthält eine Liste der Eigenschaften, die vom JSON-Dataset unterstützt werden.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft des Datasets muss auf Json festgelegt werden. | Ja |
| location | Speicherorteinstellungen der Datei(en) Jeder dateibasierte Connector verfügt unter location über seinen eigenen Speicherorttyp und unterstützte Eigenschaften.
Informationen hierzu finden Sie im Abschnitt > „Dataset-Eigenschaften“ des Artikels über Connectors. |
Ja |
| encodingName | Der zu Lesen/Schreiben von Testdateien verwendete Codierungstyp. Folgende Werte sind zulässig: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". |
Nein |
| compression | Gruppe von Eigenschaften zum Konfigurieren der Dateikomprimierung. Konfigurieren Sie diesen Abschnitt, wenn Sie während der Aktivitätsausführung eine Komprimierung/Dekomprimierung durchführen möchten. | Nein |
| type (unter compression ) |
Der zum Lesen und Schreiben von JSON-Dateien verwendete Komprimierungscodec. Zulässige Werte sind bzip2, gzip, deflate, ZipDeflate, TarGzip, Tar, snappy und lz4. Standardmäßig erfolgt keine Komprimierung. Beachten Sie, dass bei Verwendung der Kopieraktivität zum Dekomprimieren von ZipDeflate-/TarGzip-/Tar-Dateien und zum Schreiben in den dateibasierten Senkendatenspeicher diese Dateien standardmäßig in den Ordner <path specified in dataset>/<folder named as source compressed file>/ extrahiert werden. Verwenden Sie in diesem Fall preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder als Quelle der Kopieraktivität, um zu steuern, ob der Name der komprimierten Dateien als Ordnerstruktur beibehalten werden soll. |
Nein. |
| level (unter compression ) |
Das Komprimierungsverhältnis. Zulässige Werte sind Optimal oder Sehr schnell. - Sehr schnell: Der Komprimierungsvorgang wird schnellstmöglich abgeschlossen, auch wenn die resultierende Datei nicht optimal komprimiert ist. - Optimal: Die Daten sollten optimal komprimiert sein, auch wenn der Vorgang eine längere Zeit in Anspruch nimmt. Weitere Informationen finden Sie im Thema Komprimierungsstufe . |
Nein |
Im Folgenden finden Sie ein Beispiel für JSON-Datasets für Azure Blob Storage:
{
"name": "JSONDataset",
"properties": {
"type": "Json",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compression": {
"type": "gzip"
}
}
}
}
Copy activity Eigenschaften
Eine vollständige Liste mit den Abschnitten und Eigenschaften zum Definieren von Aktivitäten finden Sie im Artikel Pipelines. Dieser Abschnitt enthält eine Liste der Eigenschaften, die von der JSON-Quelle und -Senke unterstützt werden.
Unter Schema- und Datentypzuordnung in Kopieraktivität erfahren Sie, wie Sie Daten aus JSON-Dateien extrahieren und dem Senkendatenspeicher/-format zuordnen (oder umgekehrt).
JSON als Quelle
Die folgenden Eigenschaften werden im Abschnitt *source* der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf Source festgelegt werden. | Ja |
| formatSettings | Eine Gruppe von Eigenschaften. Weitere Informationen zu JSON-Leseeinstellungen finden Sie in der Tabelle unten. | Nein |
| storeSettings | Eine Gruppe von Eigenschaften für das Lesen von Daten aus einem Datenspeicher. Jeder dateibasierte Connector verfügt unter storeSettings über eigene unterstützte Leseeinstellungen.
Details finden Sie im Connectorartikel -> Copy activity Eigenschaftenabschnitt. |
Nein |
Unterstützte JSON-Leseeinstellungen unter formatSettings:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Der Typ von „formatSettings“ muss auf JsonReadSettings festgelegt werden. | Ja |
| compressionProperties | Eine Gruppe von Eigenschaften zur Festlegung, wie Daten bei einem bestimmten Komprimierungscodec dekomprimiert werden können. | Nein |
| preserveZipFileNameAsFolder (unter compressionProperties->type als ZipDeflateReadSettings) |
Diese Eigenschaft gilt, wenn das Eingabedataset mit der ZipDeflate-Komprimierung konfiguriert wurde. Sie gibt an, ob der Name der ZIP-Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. – Lautet der Wert true (Standard) , schreibt der Dienst die entpackten Dateien in <path specified in dataset>/<folder named as source zip file>/.– Lautet der Wert false, schreibt der Dienst die entpackten Dateien direkt in <path specified in dataset>. Stellen Sie sicher, dass es in unterschiedlichen ZIP-Quelldateien keine doppelten Dateinamen gibt, um Racebedingungen oder unerwartetes Verhalten zu vermeiden. |
Nein |
| preserveCompressionFileNameAsFolder (unter compressionProperties->type als TarGZipReadSettings oder TarReadSettings) |
Gilt, wenn das Eingabedataset mit der Komprimierung TarGzip/Tar konfiguriert wurde. Gibt an, ob der Name der komprimierten Quelldatei während Kopiervorgängen als Ordnerstruktur beibehalten werden soll. – Lautet der Wert true (Standard) , schreibt der Dienst die dekomprimierten Dateien in <path specified in dataset>/<folder named as source compressed file>/. – Lautet der Wert false, schreibt der Dienst die dekomprimierten Dateien direkt in <path specified in dataset>. Stellen Sie sicher, dass es in unterschiedlichen Quelldateien keine doppelten Dateinamen gibt, um Racebedingungen oder unerwartetes Verhalten zu vermeiden. |
Nein |
JSON als Senke
Die folgenden Eigenschaften werden im Abschnitt *sink* der Kopieraktivität unterstützt.
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Die type-Eigenschaft der Quelle der Kopieraktivität muss auf JSONSink festgelegt werden. | Ja |
| formatSettings | Eine Gruppe von Eigenschaften. Weitere Informationen zu JSON-Schreibeinstellungen finden Sie in der Tabelle unten. | Nein |
| storeSettings | Eine Gruppe von Eigenschaften für das Schreiben von Daten in einen Datenspeicher. Jeder dateibasierte Connector verfügt unter storeSettings über eigene unterstützte Schreibeinstellungen.
Details finden Sie im Connectorartikel -> Copy activity Eigenschaftenabschnitt. |
Nein |
Unterstützte JSON-Schreibeinstellungen unter formatSettings:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| type | Der Typ von „formatSettings“ muss auf JsonWriteSettings festgelegt werden. | Ja |
| filePattern | Geben Sie das Muster der in jeder JSON-Datei gespeicherten Daten an. Zulässige Werte sind setOfObjects (JSON-Zeilen) und arrayOfObjects. Der Standardwert ist setOfObjects. Weitere Informationen zu diesen Mustern finden Sie im Abschnitt JSON-Dateimuster. | Nein |
JSON-Dateimuster
Beim Kopieren von Daten aus JSON-Dateien kann die Kopieraktivität die folgenden Muster von JSON-Dateien automatisch erkennen und analysieren. Beim Schreiben von Daten in JSON-Dateien können Sie das Dateimuster für die Senke der Kopieraktivität konfigurieren.
Typ I: setOfObjects
Jede Datei enthält ein einzelnes Objekt, JSON-Zeilen oder verkettete Objekte.
JSON-Beispiel mit einzelnem Objekt
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }JSON-Zeilen (Standard bei Senke)
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"} {"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"} {"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}JSON-Beispiel mit Verkettung
{ "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" } { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" } { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" }
Typ II: arrayOfObjects
Jede Datei enthält ein Array von Objekten.
[ { "time": "2015-04-29T07:12:20.9100000Z", "callingimsi": "466920403025604", "callingnum1": "678948008", "callingnum2": "567834760", "switch1": "China", "switch2": "Germany" }, { "time": "2015-04-29T07:13:21.0220000Z", "callingimsi": "466922202613463", "callingnum1": "123436380", "callingnum2": "789037573", "switch1": "US", "switch2": "UK" }, { "time": "2015-04-29T07:13:21.4370000Z", "callingimsi": "466923101048691", "callingnum1": "678901578", "callingnum2": "345626404", "switch1": "Germany", "switch2": "UK" } ]
Eigenschaften von Mapping Data Flow
In Datenflüssen können Sie das JSON-Format in den folgenden Datenspeichern lesen und schreiben: Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 und SFTP und Sie können das JSON-Format in Amazon S3 lesen.
Quelleigenschaften
In der folgenden Tabelle sind die von einer JSON-Quelle unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Quelloptionen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Platzhalterpfade | Alle Dateien, die dem Platzhalterpfad entsprechen, werden verarbeitet. Überschreibt den Ordner und den Dateipfad, die im Dataset festgelegt sind. | nein | String[] | wildcardPaths |
| Partitionsstammpfad | Für partitionierte Dateidaten können Sie einen Partitionsstammpfad eingeben, um partitionierte Ordner als Spalten zu lesen. | nein | String | partitionRootPath |
| Liste mit den Dateien | Gibt an, ob Ihre Quelle auf eine Textdatei verweist, in der die zu verarbeitenden Dateien aufgelistet sind. | nein |
true oder false |
fileList |
| Spalte, in der der Dateiname gespeichert wird | Erstellt eine neue Spalte mit dem Namen und Pfad der Quelldatei. | nein | String | rowUrlColumn |
| Nach Abschluss | Löscht oder verschiebt die Dateien nach der Verarbeitung. Dateipfad beginnt mit dem Containerstamm | nein | Löschen: true oder false Verschieben: ['<from>', '<to>'] |
purgeFiles moveFiles |
| Nach der letzten Änderung filtern | Filtern Sie Dateien nach dem Zeitpunkt ihrer letzten Änderung. | nein | Zeitstempel | modifiedAfter modifiedBefore |
| Einzelnes Dokument | Zuordnungsdatenflüsse lesen aus jeder Datei ein JSON-Dokument. | nein |
true oder false |
singleDocument |
| Spaltennamen ohne Anführungszeichen | Wenn Spaltennamen ohne Anführungszeichen ausgewählt ist, liest Mapping Data Flow JSON-Spalten, die nicht in Anführungszeichen eingeschlossen sind. | nein |
true oder false |
unquotedColumnNames |
| Mit Kommentaren | Wählen Sie Mit Kommentaren aus, wenn die JSON-Daten Kommentare im C- oder C++-Stil enthalten. | nein |
true oder false |
asComments |
| Einfache Anführungszeichen | Liest JSON-Spalten, die nicht in Anführungszeichen eingeschlossen sind. | nein |
true oder false |
singleQuoted |
| Umgekehrter Schrägstrich mit Escapezeichen | Wählen Sie Umgekehrter Schrägstrich mit Escapezeichen aus, wenn in den JSON-Daten umgekehrte Schrägstriche als Escapezeichen verwendet werden. | nein |
true oder false |
backslashEscape |
| Finden keiner Dateien zulässig | „true“ gibt an, dass kein Fehler ausgelöst wird, wenn keine Dateien gefunden werden. | nein |
true oder false |
ignoreNoFilesFound |
Inline-Dataset
Zuordnungsdatenflüsse unterstützen „Inline-Datasets“ als Option zum Definieren Ihrer Quelle und Senke. Ein JSON-Inline-Dataset wird direkt in Ihren Quell- und Senkentransformationen definiert und außerhalb des definierten Dataflows nicht freigegeben. Es ist nützlich, um Dataset-Eigenschaften direkt in Ihrem Datenfluss zu parametrisieren und kann von einer verbesserten Leistung gegenüber freigegebenen ADF-Datasets profitieren.
Wenn Sie eine große Anzahl von Quellordnern und -dateien lesen, können Sie die Leistung der Erkennung von Datenflussdateien verbessern, indem Sie die Option „Vom Benutzer projiziertes Schema“ im Dialogfeld für Schemaoptionen unter „Projektion“ aktivieren. Diese Option deaktiviert die standardmäßige automatische Schemaerkennung von ADF und verbessert die Leistung der Dateierkennung erheblich. Bevor Sie diese Option festlegen, müssen Sie die JSON-Projektion importieren, damit ADF über ein vorhandenes Schema für die Projektion verfügt. Diese Option funktioniert nicht mit Schemaabweichung.
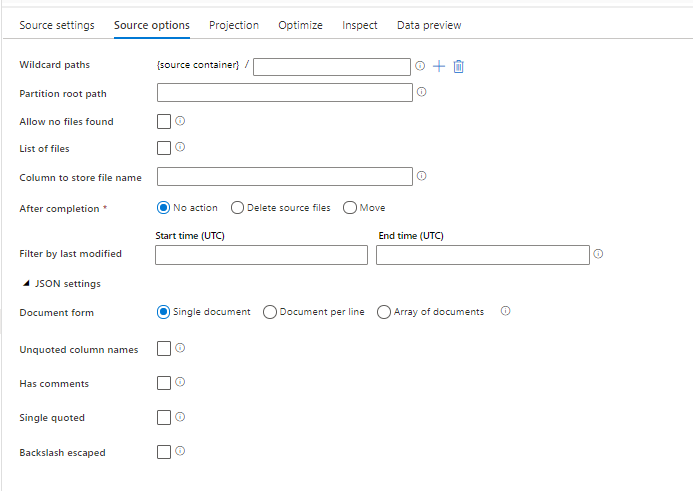
Quellformatoptionen
Wenn Sie ein JSON-Dataset als Quelle in Ihrem Datenfluss verwenden, können Sie fünf weitere Einstellungen festlegen. Diese Einstellungen befinden sich auf der Registerkarte Quell Optionen unter dem Wert für JSON-Einstellungen. Für die Einstellung Dokument-Formular können Sie den Typ einzelnes Dokument, Dokument pro Zeile oder ein Array von Dokumenten auswählen.
Standard
JSON-Daten werden standardmäßig im folgenden Format gelesen.
{ "json": "record 1" }
{ "json": "record 2" }
{ "json": "record 3" }
Einzelnes Dokument
Wenn Einzelnes Dokument ausgewählt ist, liest Mapping Data Flow ein einzelnes JSON-Dokument aus jeder Datei.
File1.json
{
"json": "record 1"
}
File2.json
{
"json": "record 2"
}
File3.json
{
"json": "record 3"
}
Wenn Dokument pro Zeile ausgewählt ist, wird von Zuordnungsdatenflüssen jeweils ein einzelnes JSON-Dokument aus jeder Zeile einer Datei gelesen.
File1.json
{"json": "record 1"}
File2.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
File3.json
{"time":"2015-04-29T07:12:20.9100000Z","callingimsi":"466920403025604","callingnum1":"678948008","callingnum2":"567834760","switch1":"China","switch2":"Germany"}
{"time":"2015-04-29T07:13:21.0220000Z","callingimsi":"466922202613463","callingnum1":"123436380","callingnum2":"789037573","switch1":"US","switch2":"UK"}
{"time":"2015-04-29T07:13:21.4370000Z","callingimsi":"466923101048691","callingnum1":"678901578","callingnum2":"345626404","switch1":"Germany","switch2":"UK"}
Wenn Array von Dokumenten ausgewählt ist, wird von Zuordnungsdatenflüssen ein einzelnes Array von Dokument aus einer Datei gelesen.
File.json
[
{
"time": "2015-04-29T07:12:20.9100000Z",
"callingimsi": "466920403025604",
"callingnum1": "678948008",
"callingnum2": "567834760",
"switch1": "China",
"switch2": "Germany"
},
{
"time": "2015-04-29T07:13:21.0220000Z",
"callingimsi": "466922202613463",
"callingnum1": "123436380",
"callingnum2": "789037573",
"switch1": "US",
"switch2": "UK"
},
{
"time": "2015-04-29T07:13:21.4370000Z",
"callingimsi": "466923101048691",
"callingnum1": "678901578",
"callingnum2": "345626404",
"switch1": "Germany",
"switch2": "UK"
}
]
Hinweis
Wenn Datenflüsse bei der Vorschau Ihrer JSON-Daten einen Fehler zu einem „beschädigten Datensatz“ (corrupt_record) ausgeben, ist es wahrscheinlich, dass die Daten ein einzelnes Dokument in der JSON-Datei enthalten. Durch Festlegen von „einzelnes Dokument“ sollte sich dieser Fehler beseitigen lassen.
Spaltennamen ohne Anführungszeichen
Wenn Spaltennamen ohne Anführungszeichen ausgewählt ist, liest Mapping Data Flow JSON-Spalten, die nicht in Anführungszeichen eingeschlossen sind.
{ json: "record 1" }
{ json: "record 2" }
{ json: "record 3" }
Mit Kommentaren
Wählen Sie Mit Kommentaren aus, wenn die JSON-Daten Kommentare im C- oder C++-Stil enthalten.
{ "json": /** comment **/ "record 1" }
{ "json": "record 2" }
{ /** comment **/ "json": "record 3" }
Einfache Anführungszeichen
Wählen Sie Einfache Anführungszeichen aus, wenn für JSON-Felder und -Werte einfache Anführungszeichen anstelle von doppelten Anführungszeichen verwendet werden.
{ 'json': 'record 1' }
{ 'json': 'record 2' }
{ 'json': 'record 3' }
Umgekehrter Schrägstrich mit Escapezeichen
Wählen Sie Umgekehrter Schrägstrich mit Escapezeichen aus, wenn in den JSON-Daten umgekehrte Schrägstriche als Escapezeichen verwendet werden.
{ "json": "record 1" }
{ "json": "\} \" \' \\ \n \\n record 2" }
{ "json": "record 3" }
Senkeneigenschaften
In der folgenden Tabelle sind die von einer JSON-Senke unterstützten Eigenschaften aufgeführt. Sie können diese Eigenschaften auf der Registerkarte Einstellungen bearbeiten.
| Name | Beschreibung | Erforderlich | Zulässige Werte | Datenflussskript-Eigenschaft |
|---|---|---|---|---|
| Ordner löschen | Wenn der Zielordner vor dem Schreiben gelöscht wird. | nein |
true oder false |
truncate |
| Dateinamenoption | Das Namensformat der geschriebenen Daten. Standardmäßig eine Datei pro Partition im Format part-#####-tid-<guid>. |
nein | Muster: Zeichenfolge Pro Partition: Zeichenfolge[] Als Daten in Spalte: Zeichenfolge Ausgabe in eine einzelne Datei: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
Erstellen von JSON-Strukturen in abgeleiteten Spalten
Sie können Ihrem Datenfluss eine komplexe Spalte über den Ausdrucks-Editor für abgeleitete Spalten hinzufügen. Fügen Sie in der Transformation für abgeleitete Spalten eine neue Spalte hinzu, und öffnen Sie den Ausdrucks-Generator, indem Sie auf das blaue Feld klicken. Um eine Spalte komplex zu gestalten, können Sie die JSON-Struktur manuell eingeben oder die Benutzeroberfläche verwenden, um Unterspalten interaktiv hinzuzufügen.
Verwenden der Benutzeroberfläche des Ausdrucks-Generators
Zeigen Sie im Seitenbereich des Ausgabeschemas mit dem Mauszeiger auf eine Spalte, und klicken Sie auf das Pluszeichen. Wählen Sie Unterspalte hinzufügen aus, um die Spalte als komplexen Typ zu gestalten.
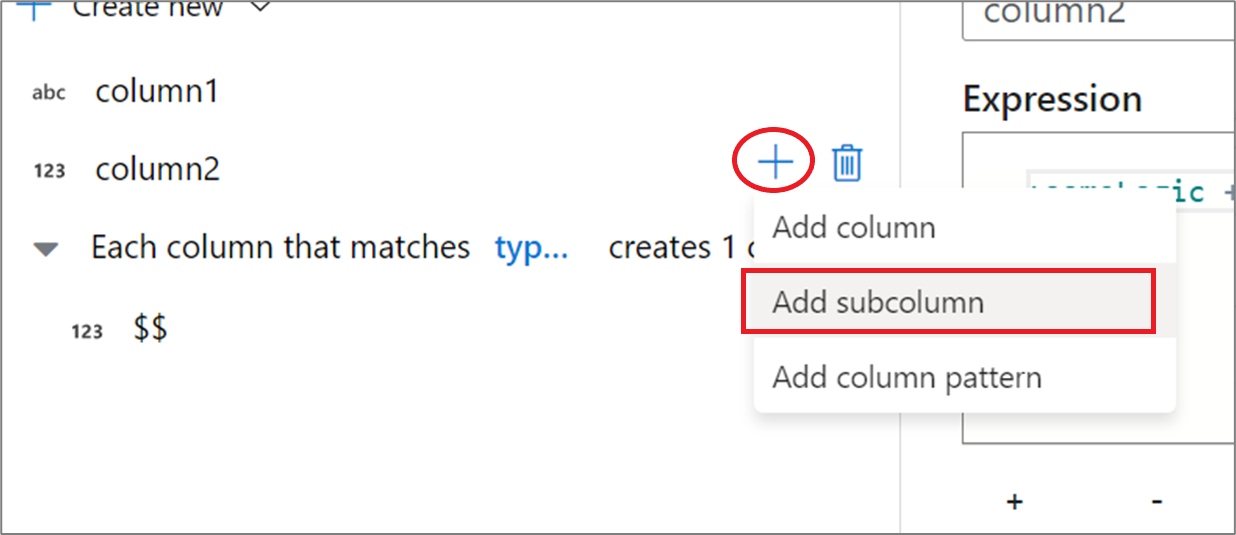
Sie können weitere Spalten und Unterspalten auf die gleiche Weise hinzufügen. Im Ausdrucks-Editor auf der rechten Seite kann für jedes nicht komplexe Feld ein Ausdruck hinzugefügt werden.
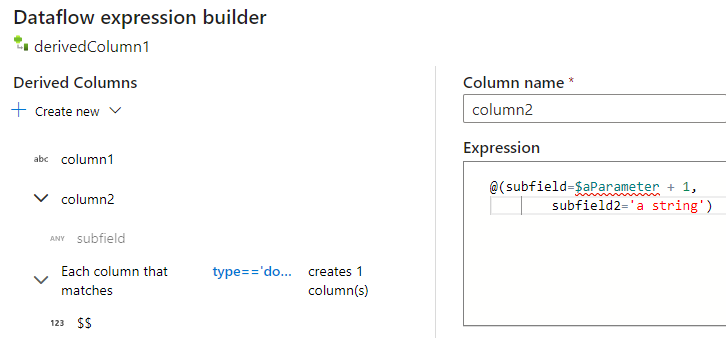
Manuelles Eingeben der JSON-Struktur
Zum manuellen Hinzufügen einer JSON-Struktur fügen Sie eine neue Spalte hinzu, und geben Sie den Ausdruck im Editor ein. Der Ausdruck weist das folgende allgemeine Format auf:
@(
field1=0,
field2=@(
field1=0
)
)
Wenn dieser Ausdruck für eine Spalte mit dem Namen „complexColumn“ eingegeben wird, wird er als der folgende JSON-Code in die Senke geschrieben:
{
"complexColumn": {
"field1": 0,
"field2": {
"field1": 0
}
}
}
Beispiel für ein manuelles Skript für eine vollständige hierarchische Definition
@(
title=Title,
firstName=FirstName,
middleName=MiddleName,
lastName=LastName,
suffix=Suffix,
contactDetails=@(
email=EmailAddress,
phone=Phone
),
address=@(
line1=AddressLine1,
line2=AddressLine2,
city=City,
state=StateProvince,
country=CountryRegion,
postCode=PostalCode
),
ids=[
toString(CustomerID), toString(AddressID), rowguid
]
)
Verwandte Connectors und Formate
Hier sind einige gängige Connectors und Formate im Zusammenhang mit dem JSON-Format aufgeführt:
Zugehöriger Inhalt
- übersicht über Copy activity
- Mapping Data Flow
- Lookup-Aktivität
- GetMetadata-Aktivität