Batchendpunkte
Azure Machine Learning ermöglicht es Ihnen, Batchendpunkte und Bereitstellungen zu implementieren, um lang ausgeführtes, asynchrones Rückschließen mit Machine Learning-Modellen und -Pipelines durchzuführen. Wenn Sie ein Machine Learning-Modell oder eine Pipeline trainieren, müssen Sie es bereitstellen, damit andere es mit neuen Eingabedaten verwenden können, um Vorhersagen zu generieren. Dieser Prozess der Generierung von Vorhersagen mit dem Modell oder der Pipeline wird als Rückschließen bezeichnet.
Mit Batchendpunkten werden Zeiger auf Daten empfangen und Aufträge asynchron ausgeführt, um die Daten in Computeclustern parallel zu verarbeiten. Auf Batchendpunkten werden Ausgaben zur weiteren Analyse in einem Datenspeicher gespeichert. Verwenden Sie Batchendpunkte in folgenden Situationen:
- Sie verfügen über teure Modelle oder Pipelines, für die die Ausführung mehr Zeit in Anspruch nimmt.
- Sie möchten Machine Learning-Pipelines operationalisieren und Komponenten wiederverwenden.
- Sie müssen Rückschlüsse auf große Datenmengen durchführen, die auf mehrere Dateien verteilt sind.
- Sie haben keine niedrigen Latenzanforderungen.
- Die Eingaben Ihres Modells werden in einem Speicherkonto oder in einem Azure Machine Learning-Datenobjekt gespeichert.
- Sie können die Parallelisierung nutzen.
Batchbereitstellungen
Bei einer Bereitstellung handelt es sich um eine Reihe von Ressourcen und Computes, die erforderlich sind, um die vom Endpunkt bereitgestellte Funktionalität zu implementieren. Jeder Endpunkt kann mehrere Bereitstellungen mit unterschiedlichen Konfigurationen hosten, und diese Funktionalität hilft dabei, die Schnittstelle des Endpunkts von den Implementierungsdetails zu entkoppeln, die von der Bereitstellung definiert werden. Wenn ein Batchendpunkt aufgerufen wird, leitet er den Client automatisch an seine Standardbereitstellung weiter. Diese Standardbereitstellung kann jederzeit konfiguriert und geändert werden.

Zwei Arten von Bereitstellungen sind in Azure Machine Learning-Batchendpunkten möglich:
Modellimplementierung
Die Modellbereitstellung ermöglicht die Operationalisierung des Modellrückschlusses im Großen und Ganzen, sodass Sie große Datenmengen in geringer Latenz und asynchroner Weise verarbeiten können. Azure Machine Learning steuert die Skalierbarkeit automatisch, indem es die Rückschlussprozesse über mehrere Knoten in einem Rechencluster hinweg parallelisiert.
Verwenden Sie die Modellbereitstellung in folgenden Fällen:
- Sie verfügen über teure Modelle, für die die Ausführung des Rückschlusses mehr Zeit in Anspruch nimmt.
- Sie müssen Rückschlüsse auf große Datenmengen durchführen, die auf mehrere Dateien verteilt sind.
- Sie haben keine niedrigen Latenzanforderungen.
- Sie können die Parallelisierung nutzen.
Der Hauptvorteil von Modellbereitstellungen besteht darin, dass Sie dieselben Ressourcen verwenden können, die für die Echtzeit-Rückschließung auf Onlineendpunkte bereitgestellt werden, aber jetzt können Sie sie im Batch skalieren. Wenn Ihr Modell eine einfache Vor- oder Nachverarbeitung erfordert, können Sie ein Bewertungsskript erstellen, das die erforderlichen Datentransformationen ausführt.
Um eine Modellbereitstellung in einem Batchendpunkt zu erstellen, müssen Sie die folgenden Elemente angeben:
- Modell
- Computecluster
- Bewertungsskript (optional für MLflow-Modelle)
- Umgebung (optional für MLflow-Modelle)
Bereitstellung von Pipelinekomponenten
Die Bereitstellung von Pipelinekomponenten ermöglicht die Operationalisierung ganzer Verarbeitungsgraphen (oder Pipelines), um Batchrückschlüsse mit geringer Latenz und auf asynchrone Weise durchzuführen.
Verwenden Sie die Bereitstellung von Pipelinekomponenten in folgenden Fällen:
- Sie müssen vollständige Computediagramme operationalisieren, die in mehrere Schritte zerlegt werden können.
- Sie müssen Komponenten aus Trainingspipelines in Ihrer Rückschlusspipeline wiederverwenden.
- Sie haben keine niedrigen Latenzanforderungen.
Der Hauptvorteil von Pipelinekomponentenbereitstellungen ist die Wiederverwendbarkeit von Komponenten, die bereits in Ihrer Plattform vorhanden sind, und die Fähigkeit, komplexe Rückschlussroutinen zu operationalisieren.
Um eine Bereitstellung in einer Pipelinekomponente zu erstellen, müssen Sie die folgenden Elemente angeben:
- Pipelinekomponente
- Konfiguration des Computeclusters
Mit Batch-Endpunkten können Sie auch Pipeline-Komponentenbereitstellungen aus einem vorhandenen Pipeline-Auftrag erstellen. Dabei erstellt Azure Machine Learning automatisch eine Pipelinekomponente aus dem Auftrag. Dies vereinfacht die Verwendung dieser Art von Bereitstellungen. Es empfiehlt sich jedoch, Pipelinekomponenten immer explizit zu erstellen, um Ihre MLOps-Praxis zu optimieren.
Kostenverwaltung
Beim Aufrufen eines Batchendpunkts wird ein asynchroner Batchrückschlussauftrag ausgelöst. Azure Machine Learning stellt automatisch Rechenressourcen bereit, wenn der Auftrag beginnt, und gibt sie automatisch frei, wenn der Auftrag abgeschlossen ist. So zahlen Sie nur für Computeressourcen, wenn Sie diese auch nutzen.
Tipp
Bei der Bereitstellung von Modellen können Sie die Einstellungen der Rechenressourcen (z. B. Anzahl der Instanzen) und erweiterte Einstellungen (z. B. Mini-Batch-Größe, Fehlerschwelle usw.) für jeden einzelnen Batch-Inferenzauftrag ändern, um die Ausführung zu beschleunigen und die Kosten zu senken. Durch die Nutzung dieser spezifischen Konfigurationen können Sie möglicherweise die Ausführung beschleunigen und Kosten reduzieren.
Batchendpunkte können auch auf VMs mit niedriger Priorität ausgeführt werden. Batchendpunkte können automatisch von zugeordneten VMs wiederherstellen und die Arbeit an der Stelle fortsetzen, an der sie beim Bereitstellen von Modellen für Rückschlüsse verlassen wurden. Weitere Informationen zum Verwenden von VMs mit niedriger Priorität, um die Kosten für Batch-Rückschlüsse auf Workloads zu reduzieren, finden Sie unter Verwenden von VMs mit niedriger Priorität in Batchendpunkten.
Schließlich berechnet Ihnen Azure Machine Learning keine Gebühren für Batchendpunkte oder Batchbereitstellungen selbst, sodass Sie Ihre Endpunkte und Bereitstellungen entsprechend Ihrem Szenario organisieren können. Endpunkte und Bereitstellungen können unabhängige oder freigegebene Cluster verwenden, sodass Sie eine differenzierte Kontrolle darüber erhalten können, welche Computevorgänge die Aufträge nutzen. Verwenden Sie scale-to-zero in Clustern, um sicherzustellen, dass keine Ressourcen verbraucht werden, wenn sie sich im Leerlauf befinden.
Optimieren der MLOps-Methode
Batchendpunkte können mehrere Bereitstellungen unter demselben Endpunkt verarbeiten, sodass Sie die Implementierung des Endpunkts ändern können, ohne die URL, die Ihre Consumer zum Aufrufen des Endpunkts verwenden, zu ändern.
Sie können Bereitstellungen hinzufügen, entfernen und aktualisieren, ohne dass sich dies auf den Endpunkt selbst auswirkt.
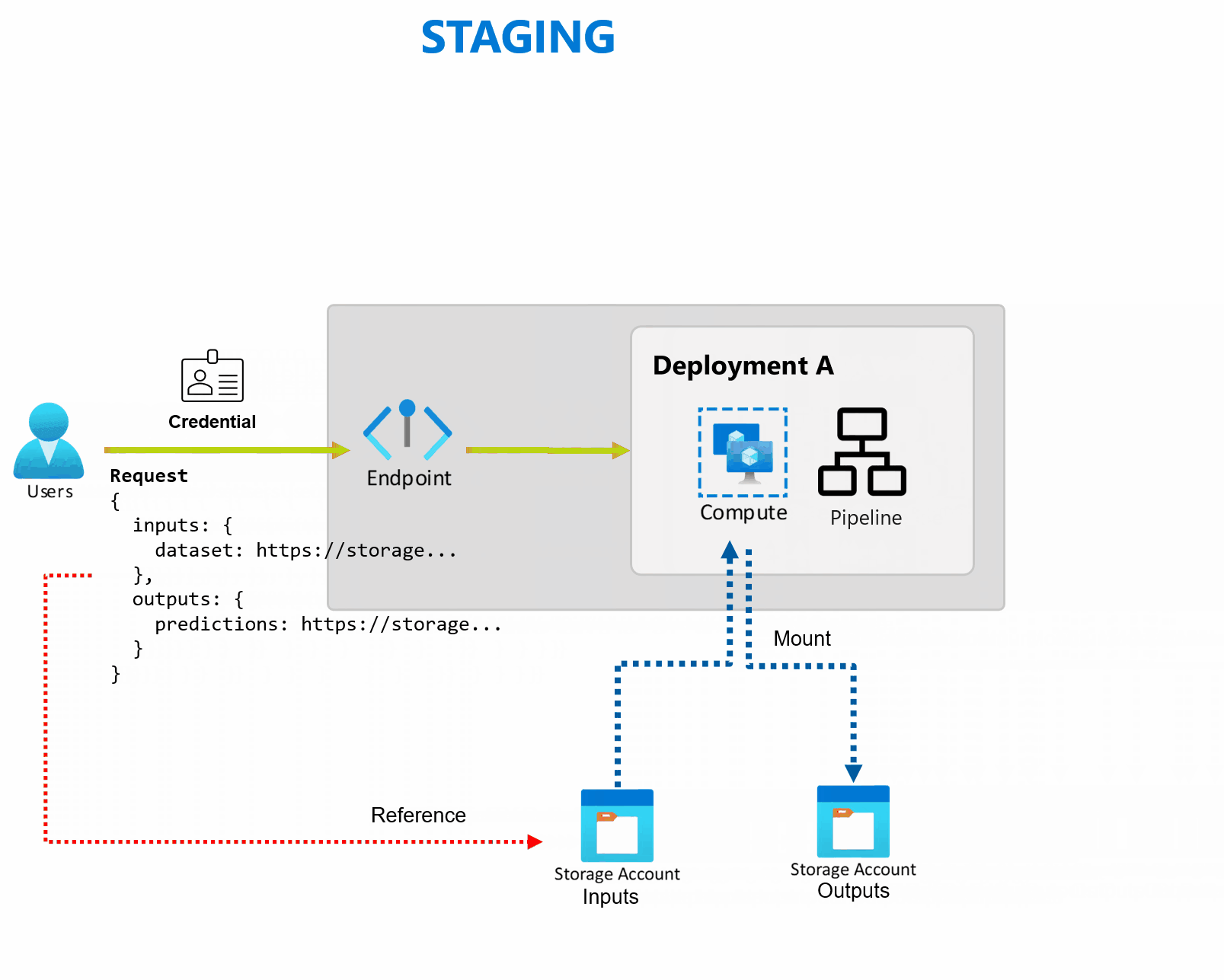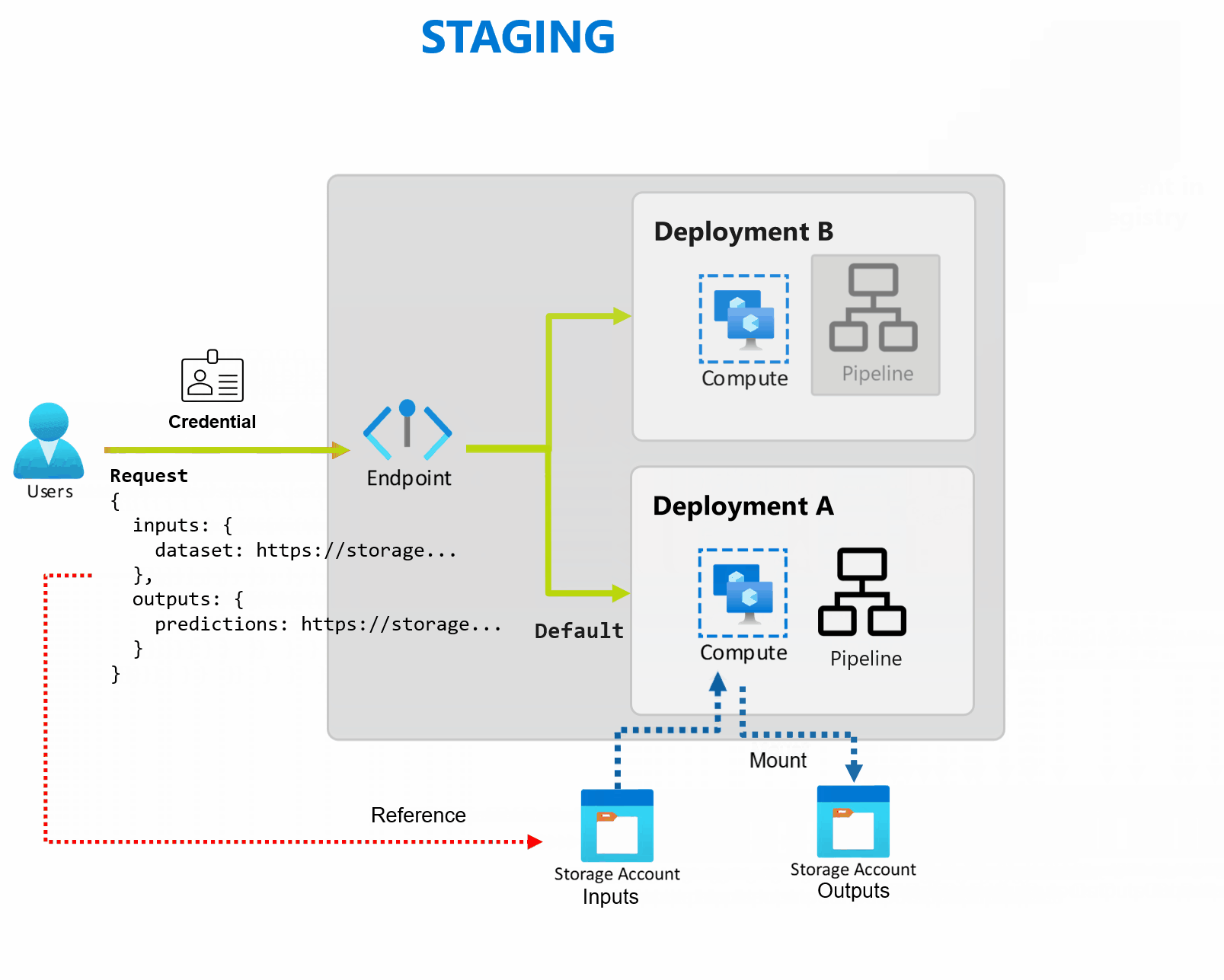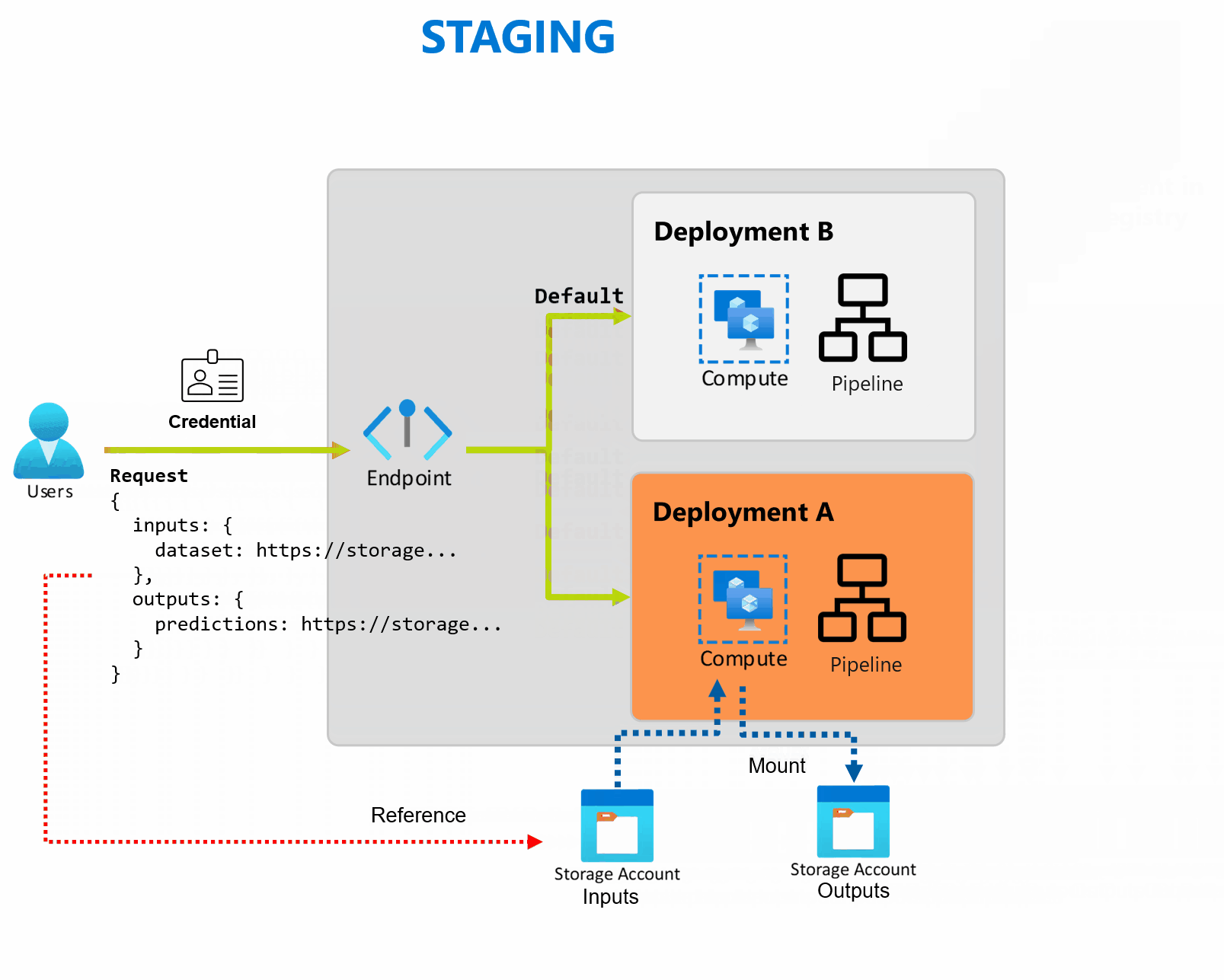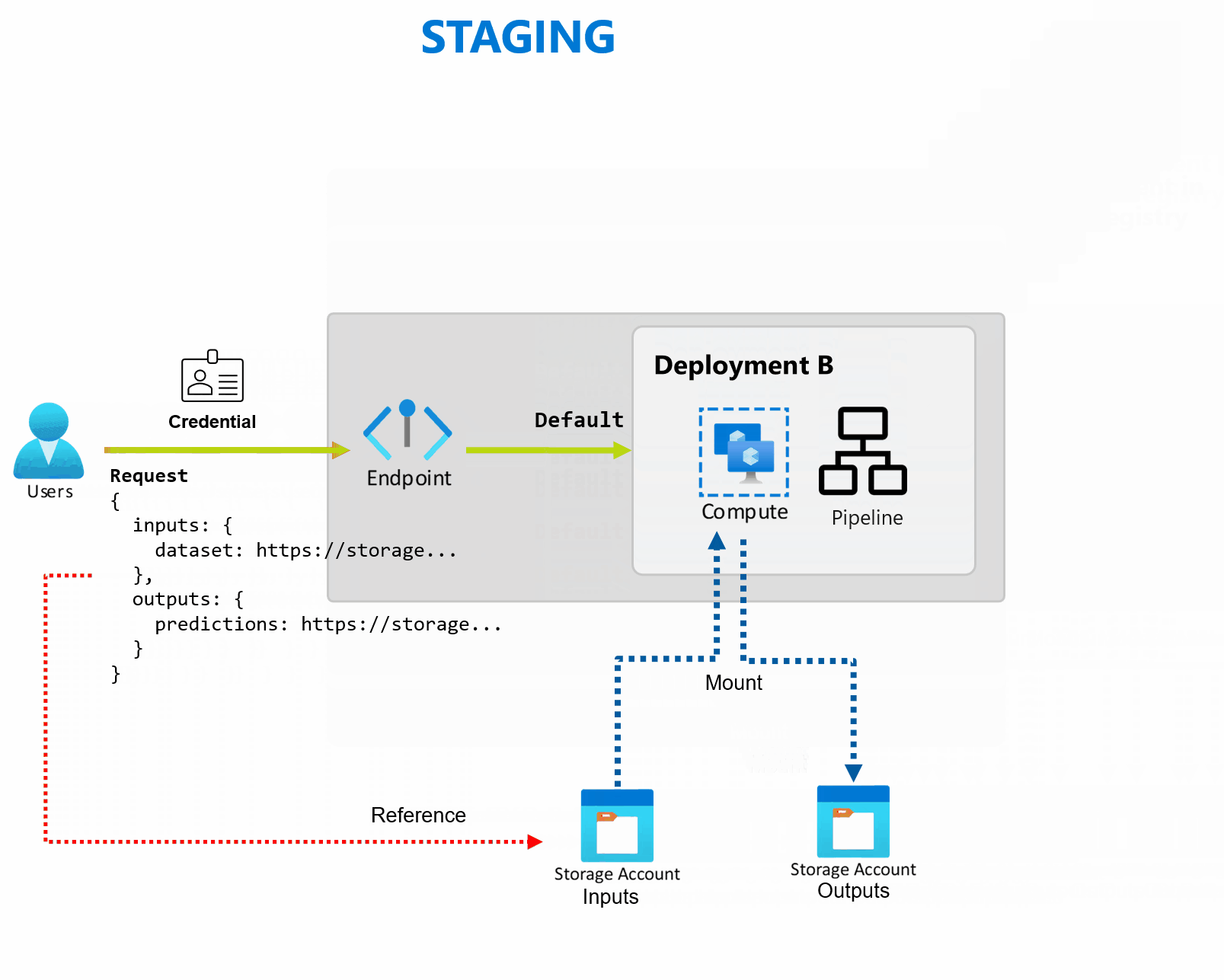
Flexible Datenquellen und flexibler Speicher
Batchendpunkte lesen und schreiben Daten direkt aus dem Speicher. Sie können Azure Machine Learning-Datenspeicher, Azure Machine Learning-Datenressourcen oder Speicherkonten als Eingaben angeben. Weitere Informationen zu unterstützten Eingabeoptionen und deren Angabe finden Sie unter Erstellen von Aufträgen und Eingabedaten für Batchendpunkte.
Sicherheit
Batchendpunkte bieten alle Funktionen, die zum Betrieb von Workloads auf Produktionsebene in einer Unternehmensumgebung erforderlich sind. Sie unterstützen private Netzwerke in geschützten Arbeitsbereichen und die Microsoft Entra Authentifizierung mithilfe eines Benutzerprinzipals (z. B. eines Benutzerkontos) oder eines Dienstprinzipals (z. B. einer verwalteten oder nicht verwalteten Identität). Aufträge, die von einem Batchendpunkt generiert werden, werden unter der Identität des Aufrufs ausgeführt, sodass Sie jedes Szenario flexibel implementieren können. Weitere Informationen zur Autorisierung während der Verwendung von Batchendpunkten finden Sie unter Authentifizierung auf Batch-Endpunkten.