Erstellen von Aufträgen und Eingabedaten für Batchendpunkte
Wenn Sie Batchendpunkte in Azure Machine Learning verwenden, können Sie lange Batchvorgänge für große Mengen von Eingabedaten ausführen. Die Daten können sich an verschiedenen Orten befinden, z. B. in unterschiedlichen Regionen. Bestimmte Arten von Batchendpunkten können auch literale Parameter als Eingaben empfangen.
Dieser Artikel beschreibt, wie Sie Parametereingaben für Batchendpunkte festlegen und Bereitstellungsaufträge erstellen. Der Prozess unterstützt das Arbeiten mit Daten aus verschiedenen Quellen, z. B. Datenressourcen, Datenspeicher, Speicherkonten und lokale Dateien.
Voraussetzungen
Sie benötigen einen Batchendpunkt und eine Bereitstellung. Einzelheiten zum Erstellen dieser Ressourcen finden Sie unter Bereitstellen von MLflow-Modellen in Batchbereitstellungen in Azure Machine Learning.
Sie müssen über Berechtigungen zum Ausführen einer Batchendpunktbereitstellung verfügen. Zum Ausführen einer Bereitstellung können Sie die Rollen AzureML – Wissenschaftliche Fachkraft für Daten, Mitwirkender und Besitzer verwenden. Informationen zu den spezifischen Berechtigungen, die für benutzerdefinierte Rollendefinitionen erforderlich sind, finden Sie unter Autorisierung für Batchendpunkte.
Anmeldeinformationen zum Aufrufen eines Endpunkts. Weitere Informationen finden Sie unter Einrichten der Authentifizierung.
Lesezugriff auf die Eingabedaten von dem Computecluster, auf dem der Endpunkt bereitgestellt ist.
Tipp
Bestimmte Situationen erfordern die Verwendung eines Datenspeichers ohne Anmeldeinformationen oder eines externen Azure Storage-Kontos als Dateneingabe. Stellen Sie in diesen Szenarien sicher, dass Sie Computecluster für den Datenzugriff konfigurieren, da die verwaltete Identität des Computeclusters für die Einbindung des Speicherkontos verwendet wird. Sie verfügen weiterhin über eine detaillierte Zugriffssteuerung, da die Identität des Auftrags (Aufrufer) zum Lesen der zugrunde liegenden Daten verwendet wird.
Einrichten der Authentifizierung
Zum Aufrufen eines Endpunkts benötigen Sie ein gültiges Microsoft Entra-Token. Wenn Sie einen Endpunkt aufrufen, erstellt Azure Machine Learning einen Batchbereitstellungsauftrag unter der mit dem Token verbundenen Identität.
- Wenn Sie zum Aufrufen von Endpunkten die Azure Machine Learning-CLI (V2) oder das Azure Machine Learning-SDK für Python (V2) verwenden, müssen Sie das Microsoft Entra-Token nicht manuell abrufen. Bei der Anmeldung authentifiziert das System Ihre Benutzeridentität. Es ruft auch das Token ab und übergibt es für Sie.
- Wenn Sie die REST-API zum Aufrufen von Endpunkten verwenden, müssen Sie das Token manuell abrufen.
Sie können Ihre eigenen Anmeldedaten für den Aufruf verwenden, wie in den folgenden Verfahren beschrieben.
Verwenden Sie die Azure CLI, um sich mit interaktiver oder Gerätecode-Authentifizierung anzumelden:
az login
Weitere Informationen zu verschiedenen Arten von Anmeldeinformationen finden Sie unter Ausführen von Aufträgen mit verschiedenen Arten von Anmeldeinformationen.
Erstellen einfacher Aufträge
Um einen Auftrag von einem Batchendpunkt aus zu erstellen, rufen Sie den Endpunkt auf. Der Aufruf kann über die Azure Machine Learning-CLI, das Azure Machine Learning-SDK für Python oder einen REST-API-Aufruf erfolgen.
Die folgenden Beispiele zeigen die Grundlagen für das Aufrufen eines Batchendpunkts, der einen einzelnen Eingabedatenordner zur Verarbeitung empfängt. Beispiele mit unterschiedlichen Eingaben und Ausgaben finden Sie unter Grundlegendes zu Eingaben und Ausgaben.
Verwenden Sie den invoke-Vorgang unter Batchendpunkten:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Aufrufen einer bestimmten Bereitstellung
Batch-Endpunkte können mehrere Bereitstellungen unter demselben Endpunkt hosten. Der Standardendpunkt wird verwendet, sofern der Benutzer nichts anderes angibt. Sie können die verwendete Bereitstellung mit den folgenden Verfahren ändern.
Verwenden Sie das Argument --deployment-name oder -d, um den Namen der Bereitstellung anzugeben:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Konfigurieren der Jobeigenschaften
Sie können einige Auftragseigenschaften zum Aufrufzeitpunkt konfigurieren.
Hinweis
Auftragseigenschaften können derzeit nur in Batchendpunkten mit Pipelinekomponentenbereitstellungen konfiguriert werden.
Konfigurieren des Experimentnamens
Gehen Sie wie folgt vor, um den Namen Ihres Experiments zu konfigurieren.
Verwenden Sie das Argument --experiment-name, um den Namen des Experiments anzugeben:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Grundlegendes zu Eingaben und Ausgaben
Batchendpunkte bieten eine dauerhafte API, die Consumer zum Erstellen von Batchaufträgen verwenden können. Dieselbe Schnittstelle kann verwendet werden, um Eingaben und Ausgaben anzugeben, die Ihre Bereitstellung erwartet. Verwenden Sie Eingaben, um alle Informationen zu übergeben, die Ihr Endpunkt zum Ausführen des Auftrags benötigt.
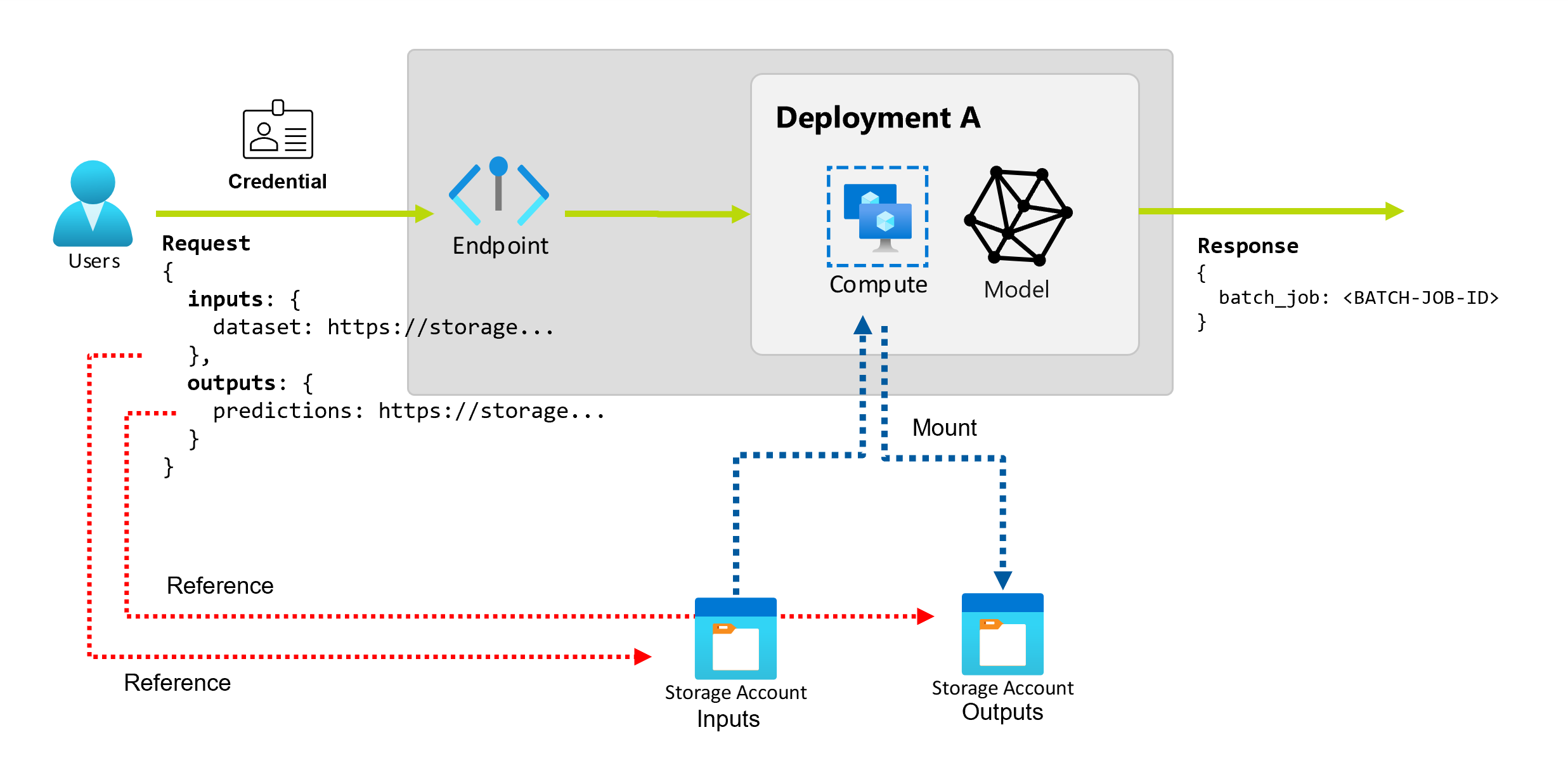
Batch-Endpunkte unterstützen zwei Arten von Eingaben:
- Dateneingaben oder Zeiger auf einen bestimmten Speicherort oder eine Azure Machine Learning-Ressource
- Literaleingaben oder Literalwerte (wie Zahlen oder Zeichenfolgen), die Sie an den Auftrag übergeben möchten
Anzahl und Typ der Eingaben und Ausgaben hängen vom Typ der Batchbereitstellung ab. Modellimplementierungen erfordern immer eine Dateneingabe und erzeugen eine Datenausgabe. Literaleingaben werden in Modellimplementierungen nicht unterstützt. Im Gegensatz dazu bieten Pipelinekomponentenbereitstellungen ein allgemeineres Konstrukt zum Erstellen von Endpunkten. In einer Pipelinekomponentenbereitstellung können Sie eine beliebige Anzahl von Dateneingaben, Literaleingaben und Ausgaben angeben.
In der folgenden Tabelle sind die Eingaben und Ausgaben für Batch-Bereitstellungen zusammengefasst:
| Bereitstellungstyp | Anzahl von Eingaben | Unterstützte Eingabetypen | Anzahl von Ausgaben | Unterstützte Ausgabetypen |
|---|---|---|---|---|
| Modellimplementierung | 1 | Dateneingaben | 1 | Datenausgaben |
| Einsatz von Pipeline-Komponenten | 0-N | Dateneingaben und Literaleingaben | 0-N | Datenausgaben |
Tipp
Eingaben und Ausgaben sind immer benannt. Jeder Name dient als Schlüssel zum Identifizieren der Daten und zum Übergeben des Werts während des Aufrufs. Da Modellimplementierungen immer eine Eingabe und eine Ausgabe erfordern, werden die Namen während des Aufrufs in Modellimplementierungen ignoriert. Sie können einen Namen vergeben, der Ihren Anwendungsfall am besten beschreibt, z. B. sales_estimation.
Näheres zu Dateneingaben
Dateneingaben beziehen sich auf Eingaben, die auf einen Speicherort verweisen, an dem Daten platziert sind. Da Batchendpunkte in der Regel große Datenmengen verbrauchen, können Sie die Eingabedaten nicht als Teil der Aufrufanforderung übergeben. Stattdessen geben Sie den Speicherort an, an dem der Batch-Endpunkt nach den Daten suchen soll. Eingabedaten werden auf der Zielcomputeinstanz eingebunden und gestreamt, um die Leistung zu verbessern.
Batchendpunkte können Dateien lesen, die sich in den folgenden Speichertypen befinden:
-
Azure Machine Learning-Datenressourcen, einschließlich der Ordnertypen (
uri_folder) und Dateitypen (uri_file). - Azure Machine Learning Data Stores, einschließlich Azure Blob Storage, Azure Data Lake Storage Gen1 und Azure Data Lake Storage Gen2.
- Azure Storage-Konten, einschließlich Blob Storage, Data Lake Storage Gen1 und Data Lake Storage Gen2.
- Lokale Datenordner und Datendateien, wenn Sie zum Aufrufen von Endpunkten die Azure Machine Learning-CLI oder das Azure Machine Learning-SDK für Python verwenden. Die lokalen Daten werden aber in den Standarddatenspeicher Ihres Azure Machine Learning-Arbeitsbereichs hochgeladen.
Wichtig
Hinweis zu veralteten Funktionen: Datenressourcen des Typs FileDataset (V1) wurden als veraltet eingestuft und werden in Zukunft eingestellt. Vorhandene Batchendpunkte, die auf dieser Funktionalität basieren, funktionieren weiterhin. Es gibt jedoch keine Unterstützung für V1-Datasets in Batchendpunkten, die mit folgenden Komponenten erstellt werden:
- Versionen der Azure Machine Learning-CLI V2, die allgemein verfügbar sind (2.4.0 und höher).
- Versionen der REST-API, die allgemein verfügbar sind (2022-05-01 und höher).
Näheres zu Literaleingaben
Literaleingaben beziehen sich auf Eingaben, die zur Aufrufzeit dargestellt und aufgelöst werden können, z. B. Zeichenfolgen, Zahlen und boolesche Werte. In der Regel verwenden Sie Literaleingaben, um Parameter als Teil der Bereitstellung einer Pipelinekomponente an Ihren Endpunkt zu übergeben. Batchendpunkte unterstützen die folgenden Literaltypen:
stringbooleanfloatinteger
Wörtliche Eingaben werden nur bei der Bereitstellung von Pipelinekomponenten unterstützt. Einzelheiten zum Angeben von Literalendpunkten finden Sie unter Erstellen von Aufträgen mit Literaleingaben.
Näheres zu Datenausgaben
Datenausgaben beziehen sich auf den Speicherort, an dem die Ergebnisse eines Batchauftrags platziert werden. Jede Ausgabe hat einen identifizierbaren Namen, und Azure Machine Learning weist jeder benannten Ausgabe automatisch einen eindeutigen Pfad zu. Sie können bei Bedarf einen anderen Pfad angeben.
Wichtig
Batchendpunkte unterstützen nur das Schreiben von Ausgaben in Blob Storage-Datenspeicher. Wenn Sie in ein Speicherkonto schreiben müssen, für das hierarchische Namespaces aktiviert sind, wie Data Lake Storage Gen2, können Sie den Speicherdienst als Blob Storage-Datenspeicher registrieren, da die Dienste vollständig kompatibel sind. Auf diese Weise können Sie Ausgaben von Batchendpunkten in Data Lake Storage Gen2 schreiben.
Aufträge mit Dateneingabe erstellen
Die folgenden Beispiele zeigen, wie Aufträge erstellt werden, während Dateneingaben von Datenressourcen, Datenspeichern und Azure Storage-Konten übernommen werden.
Verwenden von Eingabedaten aus einer Datenressource
Azure Machine Learning-Datenressourcen (ehemals als Datasets bezeichnet) werden als Eingaben für Aufträge unterstützt. Führen Sie diese Schritte aus, um einen Batchendpunktauftrag mit Eingabedaten auszuführen, die in einer registrierten Datenressource in Azure Machine Learning gespeichert sind.
Warnung
Datenressourcen des Typs „Tabelle“ (MLTable) werden derzeit nicht unterstützt.
Erstellen Sie dann das Datenobjekt. In diesem Beispiel wird ein Ordner verwendet, der mehrere CSV-Dateien enthält. Sie verwenden Batchendpunkte, um die Dateien parallel zu verarbeiten. Sie können diesen Schritt überspringen, wenn Ihre Daten bereits als Datenressource registriert sind.
Erstellen Sie eine Datenressourcendefinition in einer YAML-Datei namens „heart-data.yml“:
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-data description: An unlabeled data asset for heart classification. type: uri_folder path: dataErstellen Sie dann das Datenobjekt:
az ml data create -f heart-data.yml
Richten Sie die Eingabe ein:
DATA_ASSET_ID=$(az ml data show -n heart-data --label latest | jq -r .id)Die ID der Datenressource hat das Format
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/<data-asset-name>/versions/<data-asset-version>.Führen Sie den Endpunkt aus:
Verwenden Sie das Argument
--set, um die Eingabe anzugeben. Ersetzen Sie zunächst alle Bindestriche im Namen der Datenressource durch Unterstriche. Schlüssel dürfen nur alphanumerische Zeichen und Unterstriche enthalten.az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$DATA_ASSET_IDFür einen Endpunkt, der einer Modellimplementierung dient, können Sie das Argument
--inputverwenden, um die Dateneingabe anzugeben, da für eine Modellimplementierung immer nur eine Dateneingabe erforderlich ist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATA_ASSET_IDDas Argument
--seterzeugt oft lange Befehle, wenn mehrere Eingaben angegeben werden. In solchen Fällen können Sie Ihre Eingaben in einer Datei auflisten und dann beim Aufrufen des Endpunkts auf die Datei verweisen. Sie können beispielsweise eine YAML-Datei namens „inputs.yml“ erstellen, die die folgenden Zeilen enthält:inputs: heart_data: type: uri_folder path: /subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/data/heart-data/versions/1Anschließend können Sie den folgenden Befehl ausführen, der das Argument
--fileverwendet, um die Eingaben anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Verwenden von Eingabedaten aus einem Datenspeicher
Ihre Batchbereitstellungsaufträge können direkt auf Daten verweisen, die sich in Datenspeichern befinden, die bei Azure Machine Learning registriert sind. In diesem Beispiel laden Sie zunächst einige Daten in einen Datenspeicher in Ihrem Azure Machine Learning-Arbeitsbereich hoch. Anschließend führen Sie eine Batchbereitstellung für diese Daten aus.
In diesem Beispiel wird der Standarddatenspeicher verwendet, Sie können aber auch einen anderen Datenspeicher nutzen. In jedem Azure Machine Learning-Arbeitsbereich ist der Name des standardmäßigen Blob-Datenspeichers workspaceblobstore. Wenn Sie in den folgenden Schritten einen anderen Datenspeicher verwenden möchten, ersetzen Sie workspaceblobstore durch den Namen Ihres bevorzugten Datenspeichers.
Laden Sie Beispieldaten in den Datenspeicher hoch. Die Beispieldaten sind im Repository azureml-examples verfügbar. Sie finden die Daten in diesem Repository im Ordner sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/data.
- Öffnen Sie in Azure Machine Learning Studio die Seite mit den Datenressourcen für Ihren standardmäßigen Blob-Datenspeicher, und suchen Sie dann den Namen des Blob-Containers.
- Verwenden Sie ein Tool wie Azure Storage Explorer oder AzCopy, um die Beispieldaten in einen Ordner mit dem Namen „heart-disease-uci-unlabeled“ in diesem Container hochzuladen.
Richten Sie die Eingabeinformationen ein:
Geben Sie den Dateipfad in die Variable
INPUT_PATHein:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="azureml://datastores/workspaceblobstore/paths/$DATA_PATH"Sie sehen, dass der Ordner
pathsTeil des Eingabepfads ist. Dieses Format gibt an, dass der folgende Wert ein Pfad ist.Führen Sie den Endpunkt aus:
Verwenden Sie das
--set-Argument, um die Eingabe anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_PATHFür einen Endpunkt, der einer Modellimplementierung dient, können Sie das Argument
--inputverwenden, um die Dateneingabe anzugeben, da für eine Modellimplementierung immer nur eine Dateneingabe erforderlich ist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderDas Argument
--seterzeugt oft lange Befehle, wenn mehrere Eingaben angegeben werden. In solchen Fällen können Sie Ihre Eingaben in einer Datei auflisten und dann beim Aufrufen des Endpunkts auf die Datei verweisen. Sie können beispielsweise eine YAML-Datei namens „inputs.yml“ erstellen, die die folgenden Zeilen enthält:inputs: heart_data: type: uri_folder path: azureml://datastores/workspaceblobstore/paths/<data-path>Wenn sich Ihre Daten in einer Datei befinden, verwenden Sie stattdessen den Typ
uri_filefür die Eingabe.Anschließend können Sie den folgenden Befehl ausführen, der das Argument
--fileverwendet, um die Eingaben anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Verwenden von Eingabedaten aus einem Azure Storage-Konto
Azure Machine Learning-Batchendpunkte können Daten aus Cloudstandorten in Azure Storage-Konten lesen, sowohl öffentliche als auch private. Führen Sie die folgenden Schritte aus, um einen Batchendpunktauftrag mit Daten in einem Speicherkonto auszuführen.
Weitere Informationen zur zusätzlichen erforderlichen Konfiguration zum Lesen von Daten aus Speicherkonten finden Sie unter Konfigurieren von Computeclustern für den Datenzugriff.
Richten Sie die Eingabe ein:
Legen Sie die Variable
INPUT_DATAfest:INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Wenn sich Ihre Daten in einer Datei befinden, verwenden Sie ein Format, das dem folgenden Format ähnelt, um den Eingabepfad zu definieren:
INPUT_DATA="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Führen Sie den Endpunkt aus:
Verwenden Sie das
--set-Argument, um die Eingabe anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_data.type="uri_folder" inputs.heart_data.path=$INPUT_DATAFür einen Endpunkt, der einer Modellimplementierung dient, können Sie das Argument
--inputverwenden, um die Dateneingabe anzugeben, da für eine Modellimplementierung immer nur eine Dateneingabe erforderlich ist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderDas Argument
--seterzeugt oft lange Befehle, wenn mehrere Eingaben angegeben werden. In solchen Fällen können Sie Ihre Eingaben in einer Datei auflisten und dann beim Aufrufen des Endpunkts auf die Datei verweisen. Sie können beispielsweise eine YAML-Datei namens „inputs.yml“ erstellen, die die folgenden Zeilen enthält:inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataAnschließend können Sie den folgenden Befehl ausführen, der das Argument
--fileverwendet, um die Eingaben anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlWenn sich Ihre Daten in einer Datei befinden, verwenden Sie den Typ
uri_filein der Datei „inputs.yml“ für die Dateneingabe.
Arbeitsplätze mit wörtlichen Eingaben schaffen
Für die Bereitstellung von Pipeline-Komponenten können wörtliche Eingaben verwendet werden. Ein Beispiel für eine Batchbereitstellung, die eine einfache Pipeline enthält, finden Sie unter Bereitstellen von Pipelines mit Batchendpunkten.
Das folgende Beispiel zeigt, wie eine Eingabe namens score_mode, vom Typ string und mit einem Wert von append angegeben wird:
Platzieren Sie Ihre Eingaben in einer YAML-Datei, z. B. in einer Datei mit dem Namen „inputs.yml“:
inputs:
score_mode:
type: string
default: append
Führen Sie den folgenden Befehl aus, der das Argument --file verwendet, um die Eingaben anzugeben.
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Sie können auch das Argument --set verwenden, um den Typ und den Standardwert anzugeben. Bei dieser Vorgehensweise werden aber oft lange Befehle erzeugt, wenn mehrere Eingaben angegeben werden:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Aufträge mit Datenausgaben erstellen
Das folgende Beispiel zeigt, wie Sie den Speicherort einer Ausgabe mit dem Namen score ändern können. Der Vollständigkeit halber wird mit diesem Beispiel auch eine Eingabe mit dem Namen heart_data konfiguriert.
In diesem Beispiel wird der Standarddatenspeicher workspaceblobstore verwendet. Sie können aber auch jeden anderen Datenspeicher in Ihrem Arbeitsbereich verwenden, solange es sich um ein Blob Storage-Konto handelt. Wenn Sie einen anderen Datenspeicher verwenden möchten, ersetzen Sie workspaceblobstore in den folgenden Schritten durch den Namen Ihres bevorzugten Datenspeichers.
Rufen Sie die ID des Datenspeichers ab.
DATA_STORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Die ID des Datenspeichers hat das Format
/subscriptions/<subscription-ID>/resourceGroups/<resource-group-name>/providers/Microsoft.MachineLearningServices/workspaces/<workspace-name>/datastores/workspaceblobstore.Erstellen Sie eine Datenausgabe:
Definieren Sie die Eingabe- und Ausgabewerte in einer Datei mit dem Namen „inputs-and-outputs.yml“. Verwenden Sie die ID des Datenspeichers im Ausgabepfad. Definieren Sie der Vollständigkeit halber auch die Dateneingabe.
inputs: heart_data: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data outputs: score: type: uri_file path: <data-store-ID>/paths/batch-jobs/my-unique-pathHinweis
Sie sehen, dass der Ordner
pathsTeil des Ausgabepfads ist. Dieses Format gibt an, dass der folgende Wert ein Pfad ist.Führen Sie die Bereitstellung aus:
Verwenden Sie das Argument
--file, um die Eingabe- und Ausgabewerte anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs-and-outputs.yml