Debuggen von Bewertungsskripts mit dem HTTP-Rückschlussserver von Azure Machine Learning
Der HTTP-Rückschlussserver von Azure Machine Learning ist ein Python-Paket, das Ihre Bewertungsfunktion als HTTP-Endpunkt verfügbar macht und den Flask-Servercode und die Abhängigkeiten in ein einzelnes Paket packt. Er ist in den vordefinierten Docker-Images für Rückschlüsse enthalten, die beim Bereitstellen eines Modells mit Azure Machine Learning verwendet werden. Mithilfe des Pakets können Sie das Modell lokal für die Produktion bereitstellen und Ihr Bewertungsskript (Einstiegsskript) auch sehr einfach in einer lokalen Entwicklungsumgebung überprüfen. Wenn ein Problem mit dem Bewertungsskript auftritt, gibt der Server einen Fehler und den Speicherort zurück, an dem der Fehler aufgetreten ist.
Der Server kann auch verwendet werden, um Validierungsgates in einer Pipeline für Continuous Integration und Continuous Deployment zu erstellen. Beispielsweise können Sie den Server mit dem Kandidatenskript starten und die Testsammlung für den lokalen Endpunkt ausführen.
Dieser Artikel richtet sich hauptsächlich an Benutzer*innen, die den Rückschlussserver zum lokalen Debuggen verwenden möchten, er hilft Ihnen aber auch beim Herausfinden, wie Sie den Rückschlussserver mit Onlineendpunkten verwenden.
Lokales Debuggen des Onlineendpunkts
Wenn Sie Endpunkte lokal debuggen, bevor Sie sie in der Cloud bereitstellen, können Sie Fehler in Ihrem Code und Ihrer Konfiguration früher abfangen. Zum lokalen Debuggen von Endpunkten können Sie Folgendes verwenden:
- den HTTP-Rückschlussserver für Azure Machine Learning
- einen lokalen Endpunkt
In diesem Artikel geht es um den HTTP-Rückschlussserver für Azure Machine Learning.
Die folgende Tabelle enthält eine Übersicht über Szenarien, damit Sie die für Sie am besten geeignete Variante auswählen können.
| Szenario | HTTP-Rückschlussserver | Lokaler Endpunkt |
|---|---|---|
| Aktualisieren der lokalen Python-Umgebung ohne Neuerstellung des Docker-Images | Ja | Nein |
| Aktualisieren des Bewertungsskripts | Ja | Ja |
| Aktualisieren von Bereitstellungskonfigurationen (Bereitstellung, Umgebung, Code, Modell) | Nein | Ja |
| Integrieren des VS Code-Debuggers | Ja | Ja |
Indem Sie den HTTP-Rückschlussserver lokal ausführen, können Sie sich auf das Debuggen Ihres Bewertungsskripts konzentrieren, ohne von den Bereitstellungscontainerkonfigurationen betroffen zu sein.
Voraussetzungen
- Erfordert: Python >=3.8
- Anaconda
Tipp
Der HTTP-Rückschlussserver für Azure Machine Learning kann unter Windows- und Linux-basierten Betriebssystemen ausgeführt werden.
Installation
Hinweis
Installieren Sie den Server in einer virtuellen Umgebung, um Paketkonflikte zu vermeiden.
Führen Sie den folgenden Befehl in Ihrer Eingabeaufforderung bzw. in Ihrem Terminal aus, um das azureml-inference-server-http package zu installieren:
python -m pip install azureml-inference-server-http
Lokales Debuggen des Bewertungsskripts
Um Ihr Bewertungsskript lokal zu debuggen, können Sie das Verhalten des Servers mit einem Dummybewertungsskript testen, das Debugging mit dem Paket azureml-inference-server-http in VS Code ausführen oder den Server mit einem echten Bewertungsskript, einer Modelldatei und einer Umgebungsdatei aus unserem Beispielrepository testen.
Testen des Serververhaltens mit einem Dummybewertungsskript
Erstellen Sie ein Verzeichnis zum Speichern Ihrer Dateien:
mkdir server_quickstart cd server_quickstartErstellen Sie eine virtuelle Umgebung, und aktivieren Sie sie, um Paketkonflikte zu vermeiden:
python -m venv myenv source myenv/bin/activateTipp
Führen Sie nach dem Testen
deactivateaus, um die virtuelle Python-Umgebung zu deaktivieren.Installieren Sie das
azureml-inference-server-http-Paket aus dem pypi-Feed:python -m pip install azureml-inference-server-httpErstellen Sie Ihr Einstiegsskript (
score.py). Im folgenden Beispiel wird ein einfaches Einstiegsskript erstellt:echo ' import time def init(): time.sleep(1) def run(input_data): return {"message":"Hello, World!"} ' > score.pyStarten Sie den Server (azmlinfsrv), und legen Sie
score.pyals Einstiegsskript fest:azmlinfsrv --entry_script score.pyHinweis
Der Server wird auf 0.0.0.0 gehostet. Dies bedeutet, dass er auf alle IP-Adressen des Hostcomputers lauscht.
Senden Sie eine Bewertungsanforderung mithilfe von
curlan den Server:curl -p 127.0.0.1:5001/scoreDer Server sollte wie folgt reagieren.
{"message": "Hello, World!"}
Nach dem Testen können Sie Ctrl + C drücken, um den Server zu beenden.
Nun können Sie das Bewertungsskript (score.py) ändern und Ihre Änderungen testen, indem Sie den Server erneut ausführen (azmlinfsrv --entry_script score.py).
Integrieren mit Visual Studio Code
Es gibt zwei Möglichkeiten zum Verwenden von Visual Studio Code (VS Code) und der Python-Erweiterung zum Debuggen mit dem Paket azureml-inference-server-http zu verwenden (Start- und Anfügungsmodus).
Startmodus: Richten Sie
launch.jsonin VS Code ein, und starten Sie den HTTP-Rückschlussserver für Azure Machine Learning in VS Code.Starten Sie VS Code, und öffnen Sie den Ordner mit dem Skript (
score.py).Fügen Sie
launch.jsonfür diesen Arbeitsbereich die folgende Konfiguration in VS Code hinzu:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Debug score.py", "type": "python", "request": "launch", "module": "azureml_inference_server_http.amlserver", "args": [ "--entry_script", "score.py" ] } ] }Starten Sie eine Debugsitzung in VS Code. Wählen Sie „Ausführen“ -> „Debuggen starten“ (oder
F5) aus.
Anfügemodus: Starten Sie den HTTP-Rückschlussserver für Azure Machine Learning über eine Befehlszeile, und verwenden Sie VS Code und die Python-Erweiterung zum Anfügen an den Prozess.
Hinweis
Wenn Sie eine Linux-Umgebung verwenden, installieren Sie zuerst das Paket
gdbdurch Ausführen vonsudo apt-get install -y gdb.Fügen Sie
launch.jsonfür diesen Arbeitsbereich die folgende Konfiguration in VS Code hinzu:launch.json
{ "version": "0.2.0", "configurations": [ { "name": "Python: Attach using Process Id", "type": "python", "request": "attach", "processId": "${command:pickProcess}", "justMyCode": true }, ] }Starten Sie den Rückschlussserver über die Befehlszeilenschnittstelle (
azmlinfsrv --entry_script score.py).Starten Sie eine Debugsitzung in VS Code.
- Wählen Sie in VS Code „Ausführen“ -> „Debuggen starten“ (oder
F5) aus. - Geben Sie die Prozess-ID von
azmlinfsrv(nichtgunicorn) mithilfe der auf der Befehlszeilenschnittstelle angezeigten Protokolle (vom Rückschlussserver) ein.
Hinweis
Wenn die Prozessauswahl nicht angezeigt wird, geben Sie die Prozess-ID manuell in das Feld
processIdvonlaunch.jsonein.- Wählen Sie in VS Code „Ausführen“ -> „Debuggen starten“ (oder
Bei beiden Möglichkeiten können Sie den Breakpoint festlegen und in einzelnen Schritten debuggen.
Vollständiges Beispiel
In diesem Abschnitt wird den Server lokal mit Beispieldateien (Bewertungsskript, Modelldatei und Umgebung) in unserem Beispielrepository ausgeführt. Die Beispieldateien werden auch in unserem Artikel zum Bereitstellen und Bewerten eines Machine Learning-Modells mithilfe eines Onlineendpunkts verwendet.
Klonen Sie das Beispielrepository.
git clone --depth 1 https://github.com/Azure/azureml-examples cd azureml-examples/cli/endpoints/online/model-1/Erstellen Sie eine virtuelle Umgebung mit conda, und aktivieren Sie sie. In diesem Beispiel wird das Paket
azureml-inference-server-httpautomatisch installiert, da es inconda.ymlals abhängige Bibliothek des Paketsazureml-defaultsenthalten ist.# Create the environment from the YAML file conda env create --name model-env -f ./environment/conda.yml # Activate the new environment conda activate model-envÜberprüfen Sie Ihr Bewertungsskript.
onlinescoring/score.py
import os import logging import json import numpy import joblib def init(): """ This function is called when the container is initialized/started, typically after create/update of the deployment. You can write the logic here to perform init operations like caching the model in memory """ global model # AZUREML_MODEL_DIR is an environment variable created during deployment. # It is the path to the model folder (./azureml-models/$MODEL_NAME/$VERSION) # Please provide your model's folder name if there is one model_path = os.path.join( os.getenv("AZUREML_MODEL_DIR"), "model/sklearn_regression_model.pkl" ) # deserialize the model file back into a sklearn model model = joblib.load(model_path) logging.info("Init complete") def run(raw_data): """ This function is called for every invocation of the endpoint to perform the actual scoring/prediction. In the example we extract the data from the json input and call the scikit-learn model's predict() method and return the result back """ logging.info("model 1: request received") data = json.loads(raw_data)["data"] data = numpy.array(data) result = model.predict(data) logging.info("Request processed") return result.tolist()Führen Sie den Rückschlussserver unter Angabe des Bewertungsskripts und der Modelldatei aus. Das angegebene Modellverzeichnis (Parameter
model_dir) wird als die VariableAZUREML_MODEL_DIRdefiniert und im Bewertungsskript abgerufen. In diesem Fall geben Sie das aktuelle Verzeichnis (./) an, da das Unterverzeichnis im Bewertungsskript alsmodel/sklearn_regression_model.pklangegeben ist.azmlinfsrv --entry_script ./onlinescoring/score.py --model_dir ./Das Beispielstartprotokoll wird angezeigt, wenn der Server erfolgreich gestartet und das Bewertungsskript aufgerufen wurde. Andernfalls sind im Protokoll Fehlermeldungen aufgeführt.
Testen Sie das Bewertungsskript mit Beispieldaten. Öffnen Sie ein weiteres Terminal, und wechseln Sie zum selben Arbeitsverzeichnis, um den Befehl auszuführen. Verwenden Sie den Befehl
curl, um eine Beispielanforderung an den Server zu senden und ein Bewertungsergebnis zu erhalten.curl --request POST "127.0.0.1:5001/score" --header "Content-Type:application/json" --data @sample-request.jsonDas Bewertungsergebnis wird zurückgegeben, wenn das Bewertungsskript kein Problem aufweist. Wenn Sie feststellen, dass etwas nicht stimmt, können Sie das Bewertungsskript aktualisieren und den Server erneut starten, um das aktualisierte Skript zu testen.
Serverrouten
Der Server lauscht bei diesen Routen an Port 5001 (standardmäßig).
| Name | Route |
|---|---|
| Livetest | 127.0.0.1:5001/ |
| Score | 127.0.0.1:5001/score |
| OpenAPI (Swagger) | 127.0.0.1:5001/swagger.json |
Serverparameter
Die folgende Tabelle enthält die vom Server akzeptierten Parameter:
| Parameter | Erforderlich | Standard | BESCHREIBUNG |
|---|---|---|---|
| entry_script | True | – | Der relative oder absolute Pfad zum Bewertungsskript. |
| model_dir | False | – | Der relative oder absolute Pfad zum Verzeichnis mit dem Modell, das für Rückschlüsse verwendet wird. |
| port | Falsch | 5001 | Der bereitstellende Port des Servers. |
| worker_count | Falsch | 1 | Die Anzahl von Arbeitsthreads, die gleichzeitige Anforderungen verarbeiten. |
| appinsights_instrumentation_key | False | – | Dies ist der Instrumentierungsschlüssel für Application Insights, wo die Protokolle veröffentlicht werden. |
| access_control_allow_origins | False | – | Aktivieren Sie CORS für die angegebenen Ursprünge. Trennen Sie mehrere Ursprünge durch „,“. Beispiel: „microsoft.com, bing.com“ |
Anforderungsflow
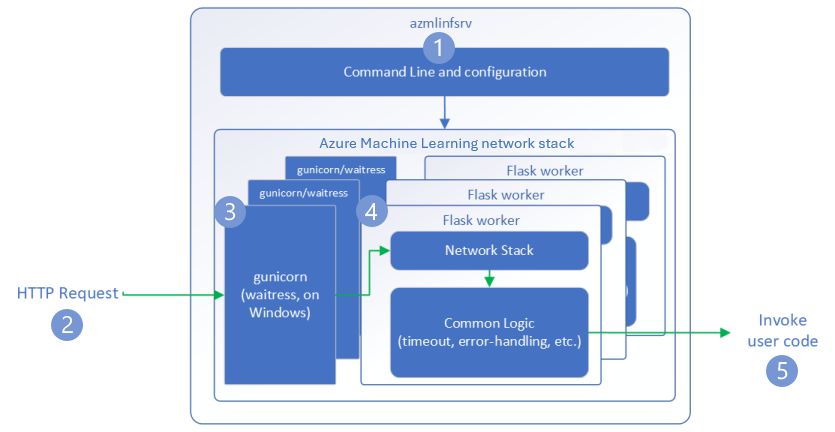
In den folgenden Schritten wird erläutert, wie der HTTP-Rückschlussserver für Azure Machine Learning (azmlinfsrv) eingehende Anforderungen verarbeitet:
- Ein Python CLI-Wrapper umgibt den Netzwerkstapel des Servers und wird zum Starten des Servers verwendet.
- Ein Client sendet eine Anforderung an den Server.
- Wenn eine Anforderung empfangen wird, durchläuft sie den WSGI-Server und wird dann an einen der Worker gesendet.
- Die Anforderungen werden dann von einer Flask-App verarbeitet, die das Einstiegsskript und alle Abhängigkeiten lädt.
- Schließlich wird die Anforderung an Ihr Einstiegsskript gesendet. Das Einstiegsskript sendet dann einen Rückschlussaufruf an das geladene Modell und gibt eine Antwort zurück.
Grundlegendes zu Protokollen
Hier werden Protokolle des HTTP-Rückschlussservers für Azure Machine Learning beschrieben. Sie können das Protokoll abrufen, wenn Sie azureml-inference-server-http lokal ausführen, oder Containerprotokolle abrufen, wenn Sie Onlineendpunkte verwenden.
Hinweis
Das Protokollierungsformat wurde seit Version 0.8.0 geändert. Wenn Ihr Protokoll einen anderen Stil aufweist, aktualisieren Sie das Paket azureml-inference-server-http auf die neueste Version.
Tipp
Wenn Sie Onlineendpunkte verwenden, beginnt das Protokoll vom Rückschlussserver mit Azure Machine Learning Inferencing HTTP server <version>.
Startprotokolle
Beim Starten des Servers werden die Servereinstellungen zuerst in den Protokollen wie folgt angezeigt:
Azure Machine Learning Inferencing HTTP server <version>
Server Settings
---------------
Entry Script Name: <entry_script>
Model Directory: <model_dir>
Worker Count: <worker_count>
Worker Timeout (seconds): None
Server Port: <port>
Application Insights Enabled: false
Application Insights Key: <appinsights_instrumentation_key>
Inferencing HTTP server version: azmlinfsrv/<version>
CORS for the specified origins: <access_control_allow_origins>
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:<port>/
Score: POST 127.0.0.1:<port>/score
<logs>
Beispiel: Starten des Servers entsprechend dem End-to-End-Beispiel:
Azure Machine Learning Inferencing HTTP server v0.8.0
Server Settings
---------------
Entry Script Name: /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
Model Directory: ./
Worker Count: 1
Worker Timeout (seconds): None
Server Port: 5001
Application Insights Enabled: false
Application Insights Key: None
Inferencing HTTP server version: azmlinfsrv/0.8.0
CORS for the specified origins: None
Server Routes
---------------
Liveness Probe: GET 127.0.0.1:5001/
Score: POST 127.0.0.1:5001/score
2022-12-24 07:37:53,318 I [32726] gunicorn.error - Starting gunicorn 20.1.0
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Listening at: http://0.0.0.0:5001 (32726)
2022-12-24 07:37:53,319 I [32726] gunicorn.error - Using worker: sync
2022-12-24 07:37:53,322 I [32756] gunicorn.error - Booting worker with pid: 32756
Initializing logger
2022-12-24 07:37:53,779 I [32756] azmlinfsrv - Starting up app insights client
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Found user script at /home/user-name/azureml-examples/cli/endpoints/online/model-1/onlinescoring/score.py
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - run() is not decorated. Server will invoke it with the input in JSON string.
2022-12-24 07:37:54,518 I [32756] azmlinfsrv.user_script - Invoking user's init function
2022-12-24 07:37:55,974 I [32756] azmlinfsrv.user_script - Users's init has completed successfully
2022-12-24 07:37:55,976 I [32756] azmlinfsrv.swagger - Swaggers are prepared for the following versions: [2, 3, 3.1].
2022-12-24 07:37:55,977 I [32756] azmlinfsrv - AML_FLASK_ONE_COMPATIBILITY is set, but patching is not necessary.
Protokollformat
Die Protokolle vom Rückschlussserver werden im folgenden Format generiert, mit Ausnahme der Startskripts, da diese nicht Teil des Python-Pakets sind:
<UTC Time> | <level> [<pid>] <logger name> - <message>
Hierbei ist <pid> die Prozess-ID und <level> das erste Zeichen der Protokollierungsebene: E für ERROR (Fehler), I für INFO usw.
Es gibt in Python sechs Protokollierungsebenen, wobei Zahlen dem Schweregrad zugeordnet sind:
| Protokolliergrad | Numerischer Wert |
|---|---|
| KRITISCH | 50 |
| ERROR | 40 |
| WARNING | 30 |
| INFO | 20 |
| DEBUG | 10 |
| NOTSET | 0 |
Handbuch zur Problembehandlung
In diesem Abschnitt finden Sie grundlegende Tipps zur Problembehandlung für den HTTP-Rückschlussserver für Azure Machine Learning. Informationen zur Problembehandlung bei Onlineendpunkten finden Sie unter Problembehandlung bei der Bereitstellung von Onlineendpunkten.
Grundlegende Schritte
Die grundlegenden Schritte zur Problembehandlung lauten:
- Sammeln Sie Versionsinformationen Ihrer Python-Umgebung.
- Stellen Sie sicher, dass die in der Umgebungsdatei angegebene Version des Python-Pakets azureml-inference-server-http der Version des HTTP-Rückschlussservers für Azure ML entspricht, die im Startprotokoll angezeigt wird. Manchmal führt der PIP-Abhängigkeitskonfliktlöser zu unerwarteten Versionen der installierten Pakete.
- Wenn Sie Flask (oder Abhängigkeiten davon) in Ihrer Umgebung angegeben haben, entfernen Sie den Eintrag. Zu den Abhängigkeiten gehören
Flask,Jinja2,itsdangerous,Werkzeug,MarkupSafeundclick. Flask wird im Serverpaket als Abhängigkeit aufgeführt, und am besten wird die Installation dem Server überlassen. Auf diese Weise erhalten Sie neue Flask-Versionen automatisch, wenn der Server diese unterstützt.
Serverversion
Das Serverpaket azureml-inference-server-http wird in PyPI veröffentlicht. Unser Änderungsprotokoll sowie alle vorherigen Versionen finden Sie auf unserer PyPI-Seite. Aktualisieren Sie auf die neueste Version, wenn Sie eine frühere verwenden.
- 0.4.x: die Version, die in Trainingsimages bis
20220601und inazureml-defaults>=1.34,<=1.43gebündelt ist. Version0.4.13ist die letzte stabile Version. Wenn Sie den Server vor Version0.4.11verwenden, werden möglicherweise Flask-Abhängigkeitsprobleme angezeigt, z. B. „Der Name ‚Markup‘ kann nicht aus ‚jinja2‘ importiert werden“. Es wird empfohlen, nach Möglichkeit ein Upgrade auf0.4.13oder0.8.x(die neueste Version) durchzuführen. - 0.6.x: die in Rückschlussimages bis 20220516 vorinstallierte Version. Die aktuelle stabile Version ist
0.6.1. - 0.7.x: die erste Version, die Flask 2 unterstützt. Die aktuelle stabile Version ist
0.7.7. - 0.8.x: Das Protokollformat wurde geändert, und die Unterstützung für Python 3.6 wurde eingestellt.
Paketabhängigkeiten
Die wichtigsten Pakete für den Server azureml-inference-server-http sind die folgenden:
- flask
- opencensus-ext-azure
- inference-schema
Wenn Sie in Ihrer Python-Umgebung azureml-defaults angegeben haben, ist das Paket azureml-inference-server-http eine Abhängigkeit und wird automatisch installiert.
Tipp
Wenn Sie das Python SDK v1 verwenden und in Ihrer Python-Umgebung nicht explizit azureml-defaults angeben, fügt das SDK das Paket möglicherweise für Sie hinzu. Es ist dann jedoch an die Version gebunden, in der sich das SDK befindet. Wenn die SDK-Version beispielsweise 1.38.0 lautet, wird den PIP-Anforderungen der Umgebung azureml-defaults==1.38.0 hinzugefügt.
Häufig gestellte Fragen
1. Beim Serverstart ist der folgende Fehler aufgetreten:
TypeError: register() takes 3 positional arguments but 4 were given
File "/var/azureml-server/aml_blueprint.py", line 251, in register
super(AMLBlueprint, self).register(app, options, first_registration)
TypeError: register() takes 3 positional arguments but 4 were given
Sie haben Flask 2 in Ihrer Python-Umgebung installiert, führen jedoch einen Server mit der Version azureml-inference-server-http aus, die Flask 2 nicht unterstützt. Unterstützung für Flask 2 wird in azureml-inference-server-http>=0.7.0, was auch in azureml-defaults>=1.44 enthalten ist.
Wenn Sie dieses Paket nicht in einem AzureML-Docker-Image verwenden, verwenden Sie die neueste Version von
azureml-inference-server-httpoderazureml-defaults.Wenn Sie dieses Paket mit einem AzureML-Docker-Image verwenden, stellen Sie sicher, dass Sie ein Image verwenden, das ab Juli 2022 aufgebaut wurde. Die Imageversion ist in den Containerprotokollen verfügbar. Sie sollten ein ähnliches Protokoll wie dieses finden können:
2022-08-22T17:05:02,147738763+00:00 | gunicorn/run | AzureML Container Runtime Information 2022-08-22T17:05:02,161963207+00:00 | gunicorn/run | ############################################### 2022-08-22T17:05:02,168970479+00:00 | gunicorn/run | 2022-08-22T17:05:02,174364834+00:00 | gunicorn/run | 2022-08-22T17:05:02,187280665+00:00 | gunicorn/run | AzureML image information: openmpi4.1.0-ubuntu20.04, Materializaton Build:20220708.v2 2022-08-22T17:05:02,188930082+00:00 | gunicorn/run | 2022-08-22T17:05:02,190557998+00:00 | gunicorn/run |Das Builddatum des Images wird nach „Materialization Build“, was im obigen Beispiel
20220708oder 8. Juli 2022 ist. Dieses Bild ist mit Flask 2 kompatibel. Wenn in Ihrem Containerprotokoll kein Banner angezeigt wird, ist Ihr Image veraltet und sollte aktualisiert werden. Wenn Sie ein CUDA-Image verwenden und kein neueres Image finden können, überprüfen Sie, ob Ihr Image in Azure ML-Containern veraltet ist. In diesem Fall sollten Sie geeigneten Ersatz finden können.Wenn Sie einen Server mit einem Onlineendpunkt verwenden, finden Sie die Protokolle auch unter „Bereitstellungsprotokolle“ auf der Online-Endpunktseite in Azure Machine Learning Studio. Wenn Sie mit SDK v1 bereitstellen und in Ihrer Bereitstellungskonfiguration kein Image explizit angeben, wird per Standard eine Version von
openmpi4.1.0-ubuntu20.04verwendet, die Ihrem lokalen SDK-Toolset entspricht, was eventuell nicht die aktuellste Version des Images ist. Beispielsweise wird SDK 1.43 standardmäßigopenmpi4.1.0-ubuntu20.04:20220616verwenden, was nicht kompatibel ist. Stellen Sie sicher, dass Sie das neueste SDK für Ihre Bereitstellung verwenden.Wenn Sie aus irgendeinem Grund das Image nicht aktualisieren können, können Sie das Problem vorübergehend vermeiden, indem Sie
azureml-defaults==1.43oderazureml-inference-server-http~=0.4.13anheften. was den Server der älteren Version mitFlask 1.0.xinstalliert.
2. Die Fehler ImportError oder ModuleNotFoundError sind auf den Modulen opencensus, jinja2, MarkupSafe oder click während des Startvorgangs wie folgt aufgetreten:
ImportError: cannot import name 'Markup' from 'jinja2'
Ältere Versionen (<= 0.4.10) des Servers haben die Abhängigkeit von Flask nicht an kompatible Versionen angeheftet. Dies wurde in der neuesten Version des Servers behoben.
Nächste Schritte
- Weitere Informationen zum Erstellen eines Einstiegsskripts und zum Bereitstellen von Modellen finden Sie unter Bereitstellen eines Modells mithilfe von Azure Machine Learning.
- Weitere Informationen unter Vordefinierte Docker-Images für Rückschlüsse (Vorschau)
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für