Verwenden von Pipelineparametern zum erneuten Trainieren von Modellen im Designer
In dieser Anleitung erfahren Sie, wie Sie Azure Machine Learning-Designer zum erneuten Trainieren eines Machine Learning-Modells mithilfe von Pipelineparametern verwenden. Sie werden veröffentlichte Pipelines verwenden, um Ihren Workflow zu automatisieren und Parameter festzulegen, um Ihr Modell anhand neuer Daten zu trainieren. Mithilfe von Pipelineparametern können Sie vorhandene Pipelines für verschiedene Aufträge wiederverwenden.
In diesem Artikel werden folgende Vorgehensweisen behandelt:
- Trainieren eines Machine Learning-Modells
- Erstellen eines Pipelineparameters
- Veröffentlichen Ihrer Trainingspipeline
- Trainieren Sie Ihr Modell mit neuen Parametern erneut.
Voraussetzungen
- Ein Azure Machine Learning-Arbeitsbereich
- Schließen Sie den ersten Teil dieser Anleitungsreihe Transformieren von Daten im Designer ab.
Wichtig
Falls die in diesem Dokument erwähnten grafischen Elemente bei Ihnen nicht angezeigt werden, z. B. Schaltflächen in Studio oder Designer, verfügen Sie unter Umständen nicht über die richtige Berechtigungsebene. Wenden Sie sich an Ihren Azure-Abonnementadministrator, um sich zu vergewissern, dass Ihnen die richtige Zugriffsebene gewährt wurde. Weitere Informationen finden Sie unter Verwalten von Benutzern und Rollen.
In diesem Artikel wird auch davon ausgegangen, dass Sie Kenntnisse zur Erstellung einer einfachen Pipeline im Designer haben. Als Einführung können Sie das Tutorial durchführen.
Beispiel-Pipeline
Die in diesem Artikel verwendete Pipeline ist eine geänderte Version einer Einkommensvorhersage einer Beispielpipeline auf der Designer-Homepage. Die Pipeline verwendet die Komponente Daten importieren anstelle des Beispieldatasets, um Ihnen zu zeigen, wie Sie Modelle mit Ihren eigenen Daten trainieren können.

Erstellen eines Pipelineparameters
Pipelineparameter dienen zum Erstellen vielseitiger Pipelines, die später mit variierenden Parameterwerten erneut übermittelt werden können. Einige typische Szenarien sind die Aktualisierung von Datasets oder einiger Hyperparameter für das erneute Training. Erstellen Sie Pipelineparameter, um Variablen zur Laufzeit dynamisch festzulegen.
Pipelineparameter können in einer Pipeline Datenquellen- oder Komponentenparametern hinzugefügt werden. Wenn die Pipeline erneut übermittelt wird, können die Werte dieser Parameter angegeben werden.
In diesem Beispiel werden Sie den Trainingsdatenpfad von einem festen Wert in einen Parameter ändern, sodass Sie Ihr Modell anhand anderer Daten neu trainieren können. Sie können auch je nach Anwendungsfall weitere Komponentenparameter als Pipelineparameter hinzufügen.
Wählen Sie das Modul Daten importieren aus.
Hinweis
In diesem Beispiel wird die Komponente „Daten importieren“ verwendet, um auf Daten in einem registrierten Datenspeicher zuzugreifen. Sie können jedoch ähnliche Schritte durchführen, wenn Sie alternative Datenzugriffsmuster verwenden.
Wählen Sie im Komponentendetailbereich rechts neben der Canvas Ihre Datenquelle aus.
Geben Sie den Pfad zu Ihren Daten ein. Sie können auch Pfad durchsuchen auswählen, um durch Ihre Dateistruktur zu navigieren.
Bewegen Sie den Mauszeiger über das Feld Pfad, und wählen Sie die Auslassungspunkte über dem Feld Pfad aus, die angezeigt werden.
Wählen Sie Zu Pipelineparameter hinzufügen aus.
Geben Sie einen Parameternamen und einen Standardwert an.
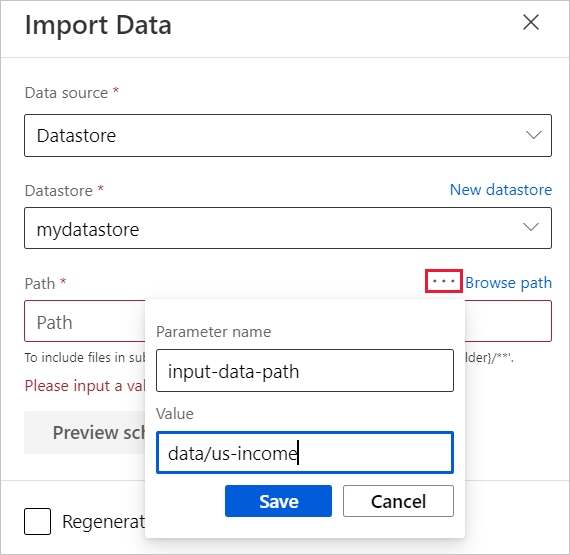
Wählen Sie Speichern aus.
Hinweis
Sie können auch im Bereich mit den Komponentendetails (vergleichbar mit dem Hinzufügen von Pipelineparametern) einen Komponentenparameter von einem Pipelineparameter trennen.
Über das Zahnradsymbol Einstellungen neben dem Titel Ihres Pipelineentwurfs können Sie die Pipelineparameter überprüfen und bearbeiten.
- Nach dem Trennen können Sie den Pipelineparameter im Bereich Einstellungen löschen.
- Sie können auch einen Pipelineparameter im Bereich Einstellungen hinzufügen und ihn dann auf einen Komponentenparameter anwenden.
Übermitteln des Pipelineauftrags
Veröffentlichen einer Trainingspipeline
Veröffentlichen Sie eine Pipeline an einem Pipelineendpunkt, um Ihre Pipelines in Zukunft einfach wiederverwenden zu können. Ein Pipelineendpunkt erstellt einen REST-Endpunkt, um die Pipeline zukünftig aufzurufen. In diesem Beispiel können Sie mit Ihrem Pipelineendpunkt Ihre Pipeline wiederverwenden, um ein Modell anhand anderer Daten neu zu trainieren.
Wählen Sie Veröffentlichen über der Designer-Canvas aus.
Wählen Sie einen Pipelineendpunkt aus, oder erstellen Sie ihn.
Hinweis
Sie können mehrere Pipelines für einen einzelnen Endpunkt veröffentlichen. Jede Pipeline in einem bestimmten Endpunkt erhält eine Versionsnummer, die Sie beim Aufruf des Pipelineendpunkts angeben können.
Wählen Sie Veröffentlichen.
Erneutes Trainieren Ihres Modells
Nachdem Sie nun eine Trainingspipeline veröffentlicht haben, können Sie diese verwenden, um Ihr Modell anhand neuer Daten neu zu trainieren. Sie können Aufträge von einem Pipelineendpunkt aus dem Studio-Arbeitsbereich oder programmgesteuert übermitteln.
Übermitteln von Aufträgen mit dem Studio-Portal
Verwenden Sie die folgenden Schritte, um den Auftrag eines parametrisierten Pipelineendpunkts über das Studio-Portal zu übermitteln:
- Rufen Sie die Seite Endpunkte in Ihrem Studio-Arbeitsbereich auf.
- Wählen Sie die Registerkarte Pipelineendpunkte aus. Wählen Sie dann Ihren Pipelineendpunkt aus.
- Wählen Sie die Registerkarte Veröffentlichte Pipelines aus. Wählen Sie dann die Pipelineversion aus, die Sie ausführen möchten.
- Klicken Sie auf Submit (Senden).
- Im Dialogfeld für die Einrichtung können Sie die Parameterwerte für den Auftrag angeben. Aktualisieren Sie in diesem Beispiel den Dateipfad, um das Modell mit einem Nicht-US-Dataset zu trainieren.

Übermitteln von Aufträgen mithilfe von Code
Den REST-Endpunkt einer veröffentlichten Pipeline finden Sie im Übersichtsbereich. Durch den Aufruf des Endpunkts können Sie die veröffentlichte Pipeline neu trainieren.
Sie benötigen einen OAuth 2.0-Authentifizierungsheader vom Typ Bearer, um einen REST-Aufruf auszuführen. Informationen zum Einrichten der Authentifizierung für Ihren Arbeitsbereich und zum Ausführen eines parametrisierten REST-Aufrufs finden Sie unter Verwenden von REST zum Verwalten von Ressourcen.
Nächste Schritte
In diesem Artikel haben Sie erfahren, wie Sie mit dem Designer einen parametrisierten Trainingspipelineendpunkt erstellen können.
Eine vollständige exemplarische Vorgehensweise, wie Sie ein Modell bereitstellen können, um Vorhersagen zu treffen, finden Sie im Designer-Tutorial zum Trainieren und Bereitstellen eines Regressionsmodells.
Informationen zum Veröffentlichen und Übermitteln eines Auftrags an einen Pipelineendpunkt mithilfe des SDK v1 finden Sie unter Veröffentlichen von Pipelines.