Nachverfolgen von ML-Experimenten und -Modellen mit MLflow
In diesem Artikel erfahren Sie, wie Sie MLflow zum Nachverfolgen Ihrer Experimente und Ausführungen in Azure Machine Learning-Arbeitsbereichen verwenden.
Nachverfolgung ist der Prozess des Speicherns relevanter Informationen über Experimente, die Sie ausführen. Die gespeicherten Informationen (Metadaten) variieren je nach Projekt und können Folgendes umfassen:
- Code
- Umgebungsdetails (z. B. Betriebssystemversion, Python-Pakete)
- Eingabedaten
- Parameterkonfigurationen
- Modelle
- Auswertungsmetriken
- Auswertungsvisualisierungen (z. B. Konfusionsmatrizen, Wichtigkeitsplots)
- Auswertungsergebnisse (einschließlich einiger Auswertungsvorhersagen)
Wenn Sie mit Aufträgen in Azure Machine Learning arbeiten, verfolgt Azure Machine Learning automatisch einige Informationen über Ihre Experimente nach, z. B. Code, Umgebung und Eingabe- und Ausgabedaten. Für andere Modelle, Parameter und Metriken muss der Modell-Generator jedoch ihre Nachverfolgung konfigurieren, da sie für das jeweilige Szenario spezifisch sind.
Hinweis
Wenn Sie Experimente nachverfolgen möchten, die auf Azure Databricks ausgeführt werden, lesen Sie Nachverfolgen von Azure Databricks ML-Experimenten mit MLflow und Azure Machine Learning. Informationen zum Nachverfolgen von Experimenten, die in Azure Synapse Analytics ausgeführt werden, finden Sie unter Nachverfolgen von Azure Synapse Analytics ML-Experimenten mit MLflow und Azure Machine Learning.
Vorteile bei der Nachverfolgung von Experimenten
Es wird dringend empfohlen, dass Anwender des maschinellen Lernens Experimente nachzuverfolgen, unabhängig davon, ob Sie mit Aufträgen in Azure Machine Learning oder interaktiv in Notebooks trainieren. Das Nachverfolgen von Experimenten ermöglicht Ihnen Folgendes:
- Organisieren aller Ihrer Experimente des maschinellen Lernens an einem zentralen Ort. Anschließend können Sie Experimente durchsuchen und filtern und einen Drilldown ausführen, um Details zu den zuvor ausgeführten Experimenten anzuzeigen.
- Vergleichen Sie Experimente, analysieren Sie Ergebnisse und debuggen Sie Modelltraining mit wenig zusätzlichem Aufwand.
- Reproduzieren oder erneutes Ausführen von Experimenten, um die Ergebnisse zu überprüfen.
- Verbessern Sie die Zusammenarbeit, da Sie sehen können was andere Teammitglieder tun, Experimentergebnisse freigeben und programmgesteuert auf Experimentdaten zugreifen können.
Warum sollte MLflow für die Nachverfolgung von Experimenten verwendet werden?
Azure Machine Learning-Arbeitsbereiche sind MLflow-kompatibel, was bedeutet, dass Sie MLflow verwenden können, um Ausführungen, Metriken, Parameter und Artefakte innerhalb Ihrer Azure Machine Learning-Arbeitsbereiche nachzuverfolgen. Ein wesentlicher Vorteil der Verwendung von MLflow für die Nachverfolgung besteht darin, dass Sie Ihre Trainingsroutinen nicht ändern müssen, um mit Azure Machine Learning zu arbeiten, und dass Sie keine cloudspezifische Syntax einfügen müssen.
Weitere Informationen über alle unterstützten MLflow- und Azure Machine Learning-Funktionen finden Sie unter MLflow und Azure Machine Learning.
Begrenzungen
Einige Methoden, die in der MLflow-API verfügbar sind, sind bei einer Verbindung mit Azure Machine Learning möglicherweise nicht verfügbar. Details zu unterstützten und nicht unterstützten Vorgängen finden Sie unter Unterstützungsmatrix zum Abfragen von Ausführungen und Experimenten.
Voraussetzungen
- Ein Azure-Abonnement. Wenn Sie nicht über ein Azure-Abonnement verfügen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen. Probieren Sie die kostenlose oder kostenpflichtige Version von Azure Machine Learning aus.
Installieren Sie das MLflow SDK-Paket
mlflowund das Azure Machine Learning-Plug-Inazureml-mlflowfür MLflow:pip install mlflow azureml-mlflowTipp
Sie können auch das Paket
mlflow-skinnyverwenden. Dabei handelt es sich um ein abgespecktes MLflow-Paket ohne SQL-Speicher, Server, Benutzeroberfläche oder Data Science-Abhängigkeiten.mlflow-skinnywird für diejenigen empfohlen, die in erster Linie die Funktionen für Nachverfolgung und Protokollierung benötigen und nicht sämtliche Features von MLflow (einschließlich Bereitstellungen) importieren möchten.Ein Azure Machine Learning-Arbeitsbereich. Informationen zum Erstellen eines Arbeitsbereichs finden Sie unter Tutorial: Erstellen von Ressourcen für maschinelles Lernen. Überprüfen Sie, welche Zugriffsberechtigungen Sie benötigen, um Ihre MLflow-Vorgänge in Ihrem Arbeitsbereich auszuführen.
Wenn Sie eine Remotenachverfolgung durchführen, d. h. eine Nachverfolgung von Experimenten, die außerhalb von Azure Machine Learning ausgeführt werden, konfigurieren Sie MLflow so, dass auf den Nachverfolgungs-URI Ihres Azure Machine Learning-Arbeitsbereichs verwiesen wird. Weitere Informationen zum Herstellen einer Verbindung zwischen MLflow und dem Arbeitsbereich finden Sie unter Konfigurieren von MLflow für Azure Machine Learning.
Konfigurieren des Experiments
MLflow organisiert die Informationen in Experimenten und Ausführungen (in Azure Machine Learning werden Ausführungen als Aufträge bezeichnet). Standardmäßig werden Ausführungen mit einem Experiment namens Standard protokolliert, das automatisch für Sie erstellt wird. Sie können das Experiment konfigurieren, in dem die Nachverfolgung stattfindet.
Verwenden Sie für interaktives Training, z. B. in einem Jupyter Notebook, den MLflow-Befehl mlflow.set_experiment(). Der folgende Codeschnipsel konfiguriert beispielsweise ein Experiment:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Konfigurieren der Ausführung
Azure Machine Learning verfolgt jeden Trainingsauftrag in MLflow als Ausführung nach. Verwenden Sie Ausführungen, um die gesamte Verarbeitung zu erfassen, die Ihr Auftrag ausführt.
Wenn Sie interaktiv arbeiten, beginnt MLflow mit der Nachverfolgung Ihrer Trainingsroutine, sobald Sie versuchen, Informationen zu protokollieren, die eine aktive Ausführung erfordern. Beispielsweise beginnt die MLflow-Nachverfolgung, wenn Sie eine Metrik oder einen Parameter protokollieren oder einen Trainingszyklus starten und die Funktion für die automatische Protokollierung von MLflow aktiviert ist. In der Regel ist es jedoch hilfreich, die Ausführung explizit zu starten, insbesondere, wenn Sie die Gesamtzeit Ihres Experiments im Feld Dauer erfassen möchten. Um die Ausführung explizit zu starten, verwenden Sie mlflow.start_run().
Unabhängig davon, ob Sie die Ausführung manuell starten oder nicht, müssen Sie die Ausführung schließlich beenden, damit MLflow weiß, dass Ihre Experimentausführung abgeschlossen ist und den Status der Ausführung als Abgeschlossen markieren kann. Verwenden Sie mlflow.end_run(), um eine Ausführung zu beenden.
Es wird dringend empfohlen, Ausführungen manuell zu starten, damit Sie nicht vergessen, sie zu beenden, wenn Sie in Notebooks arbeiten.
So starten Sie eine Ausführung manuell und beenden sie, wenn Sie mit der Arbeit im Notizbuch fertig sind:
mlflow.start_run() # Your code mlflow.end_run()Normalerweise ist es hilfreich, das Paradigma des Kontextmanagers zu verwenden, um sich daran zu erinnern, die Ausführung zu beenden:
with mlflow.start_run() as run: # Your codeWenn Sie eine neue Ausführung mit
mlflow.start_run()starten, kann es hilfreich sein, den Parameterrun_nameanzugeben, der später in den Namen der Ausführung in der Azure Machine Learning-Benutzeroberfläche übersetzt wird und Ihnen hilft, die Ausführung schneller zu identifizieren:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Aktivieren Sie die automatische MLflow-Protokollierung
Sie können Metriken, Parameter und Dateien mit MLflow manuell protokollieren. Sie können sich jedoch auch auf die automatische Protokollierungsfunktion von MLflow verlassen. Jedes von MLflow unterstützte Machine Learning-Framework entscheidet automatisch, was für Sie nachverfolgt werden soll.
Um die automatische Protokollierung zu aktivieren, fügen Sie den folgenden Code vor Ihrem Trainingscode ein:
mlflow.autolog()
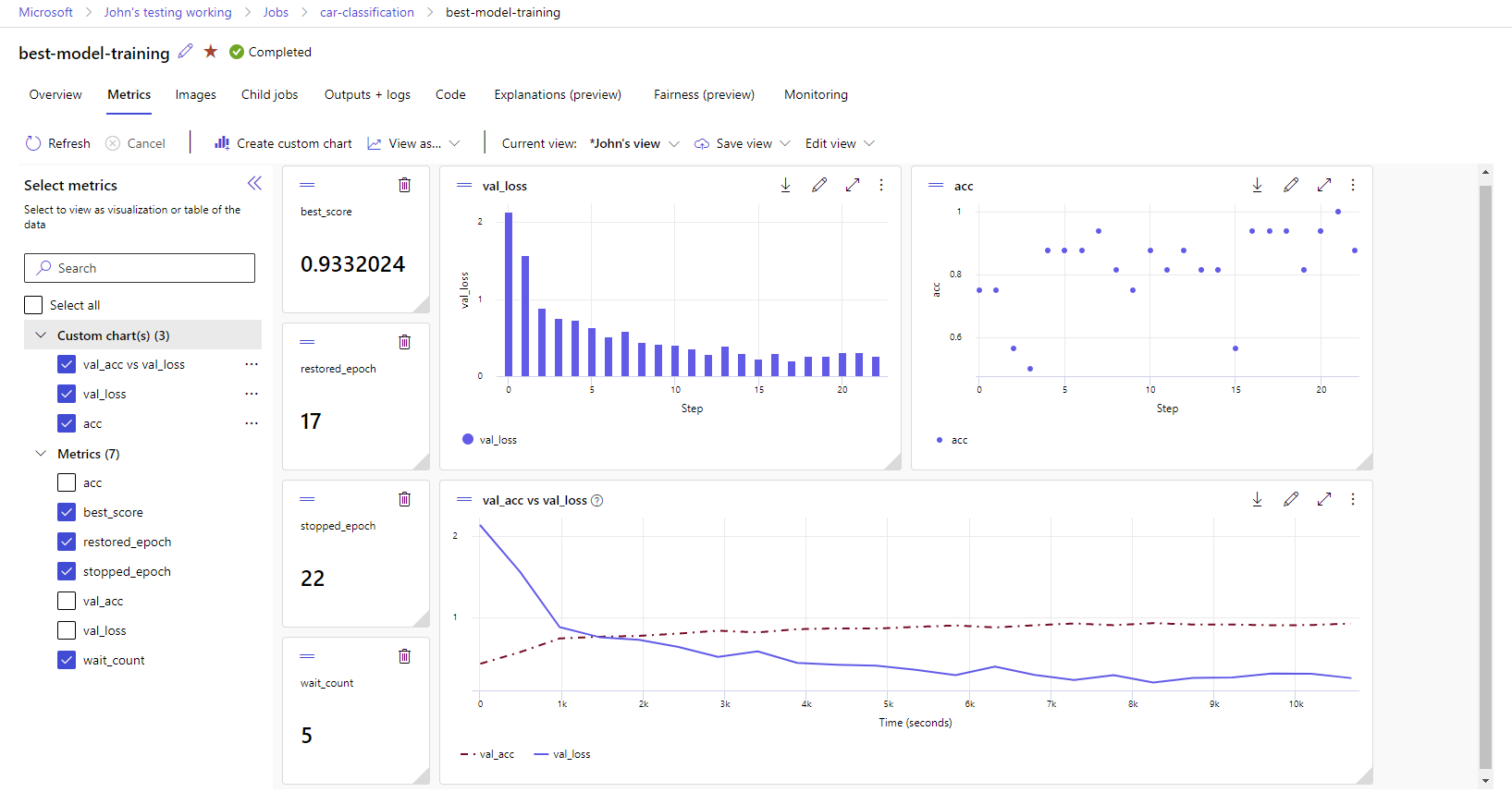
Anzeigen von Metriken und Artefakten in Ihrem Arbeitsbereich
Die Metriken und Artefakte aus dem MLflow-Protokoll werden in Ihrem Arbeitsbereich nachverfolgt. Sie können sie jederzeit im Studio anzeigen und darauf zugreifen oder programmgesteuert über das MLflow-SDK darauf zugreifen.
So zeigen Sie Metriken und Artefakten im Studio an:
Navigieren Sie zu Azure Machine Learning Studio.
Navigieren Sie zu Ihrem Arbeitsbereich.
Suchen Sie das Experiment in Ihrem Arbeitsbereich nach Namen.
Wählen Sie die protokollierten Metriken aus, um Diagramme auf der rechten Seite zu erstellen. Sie können Diagramme anpassen, indem Sie eine Glättung anwenden, die Farbe ändern oder mehrere Metriken in einem einzelnen Graphen zeichnen. Sie können auch die Größe und Anordnung des Layouts nach Belieben ändern.
Nachdem Sie Ihre gewünschte Ansicht erstellt haben, können Sie diese für die zukünftige Verwendung speichern und über einen direkten Link mit Ihren Teamkollegen teilen.

Um programmgesteuert über das MLflow-SDK auf Metriken, Parameter und Artefakte zugreifen oder diese abfragen, verwenden Sie mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Tipp
Bei Metriken gibt der vorherige Beispielcode nur den letzten Wert einer bestimmten Metrik zurück. Wenn Sie alle Werte einer bestimmten Metrik abrufen möchten, verwenden Sie die mlflow.get_metric_history-Methode. Weitere Informationen zum Abrufen von Werten einer Metrik finden Sie unter Abrufen von Parametern und Metriken aus einer Ausführung.
Um von Ihnen protokollierte Artefakte wie z. B. Dateien und Modelle herunterzuladen, verwenden Sie mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Weitere Informationen zum Abrufen oder Vergleichen von Informationen aus Experimenten und Ausführungen in Azure Machine Learning mithilfe von MLflow finden Sie unter Abfragen und Vergleichen von Experimenten und Ausführungen mit MLflow.