Hochverfügbarkeitskonzepte in Azure Database for MySQL – Flexibler Server
GILT FÜR:  Azure Database for MySQL – Flexibler Server
Azure Database for MySQL – Flexibler Server
Die Azure Datenbank für MySQL-flexible Server ermöglicht das Konfigurieren der Hochverfügbarkeit mit automatischem Failover. Die Hochverfügbarkeitslösung ist so konzipiert, dass committete Daten nie aufgrund von Fehlern verloren gehen und die Datenbank keinen Single Point of Failure (SPOF) in der Softwarearchitektur darstellt. Beim Konfigurieren von Hochverfügbarkeit stellt Flexible Server automatisch ein Standbyreplikat bereit und verwaltet dieses. Ihnen werden die bereitgestellte Compute und der bereitstellte Speicher sowohl für das primäre als auch für das sekundäre Replikat in Rechnung gestellt. Es gibt zwei Architekturmodelle für Hochverfügbarkeit:
Zonenredundante Hochverfügbarkeit: Diese Option wird für die vollständige Isolation und Redundanz der Infrastruktur für mehrere Verfügbarkeitszonen bevorzugt. Sie bietet den höchsten Verfügbarkeitsgrad, erfordert aber eine zonenübergreifende Konfiguration der Anwendungsredundanz. Zonenredundante Hochverfügbarkeit wird bevorzugt, wenn bei jedem Infrastrukturausfall in der Verfügbarkeitszone die bestmögliche Verfügbarkeit erzielt werden soll und die Latenz in der Verfügbarkeitszone akzeptabel ist. Sie kann nur während der Erstellung des Servers aktiviert werden. Die zonenredundante Hochverfügbarkeit ist nur in Azure-Regionen verfügbar, die mehrere Verfügbarkeitszonen und zonenredundante Premium-Dateifreigaben unterstützen.
Hochverfügbarkeit in gleicher Zone: Diese Option wird für Infrastrukturredundanz mit geringerer Netzwerklatenz bevorzugt, da sich sowohl der primäre Server als auch der Standbyserver in derselben Verfügbarkeitszone befinden. Sie bietet Hochverfügbarkeit, ohne dass eine zonenübergreifende Konfiguration der Anwendungsredundanz erforderlich ist. Die Option für Hochverfügbarkeit in gleicher Zone wird bevorzugt, wenn Sie die bestmögliche Verfügbarkeit innerhalb einer einzelnen Verfügbarkeitszone mit der geringstmöglichen Netzwerklatenz erzielen möchten. Hochverfügbarkeit in derselben Zone steht in allen Azure-Regionen zur Verfügung, in denen Sie Azure Database for MySQL – Flexibler Server verwenden können.
Architektur für zonenredundante Hochverfügbarkeit
Wenn Sie einen Server mit zonenredundanter Hochverfügbarkeit bereitstellen, werden zwei Server erstellt:
- Ein primärer Server in einer Verfügbarkeitszone.
- Ein Standbyreplikatserver mit derselben Konfiguration wie der primäre Server (Computeebene, Computegröße, Speichergröße und Netzwerkkonfiguration) in einer anderen Verfügbarkeitszone derselben Azure-Region.
Sie können die Verfügbarkeitszone für das primäre Replikat und das Standbyreplikat auswählen. Wenn Sie die Datenbankserver für das Standbyreplikat und die Standbyanwendungen in derselben Zone platzieren, reduzieren Sie die Latenz. Darüber hinaus können Sie sich besser auf Notfallwiederherstellungssituationen und Szenarien mit „Zonenausfällen“ vorbereiten.
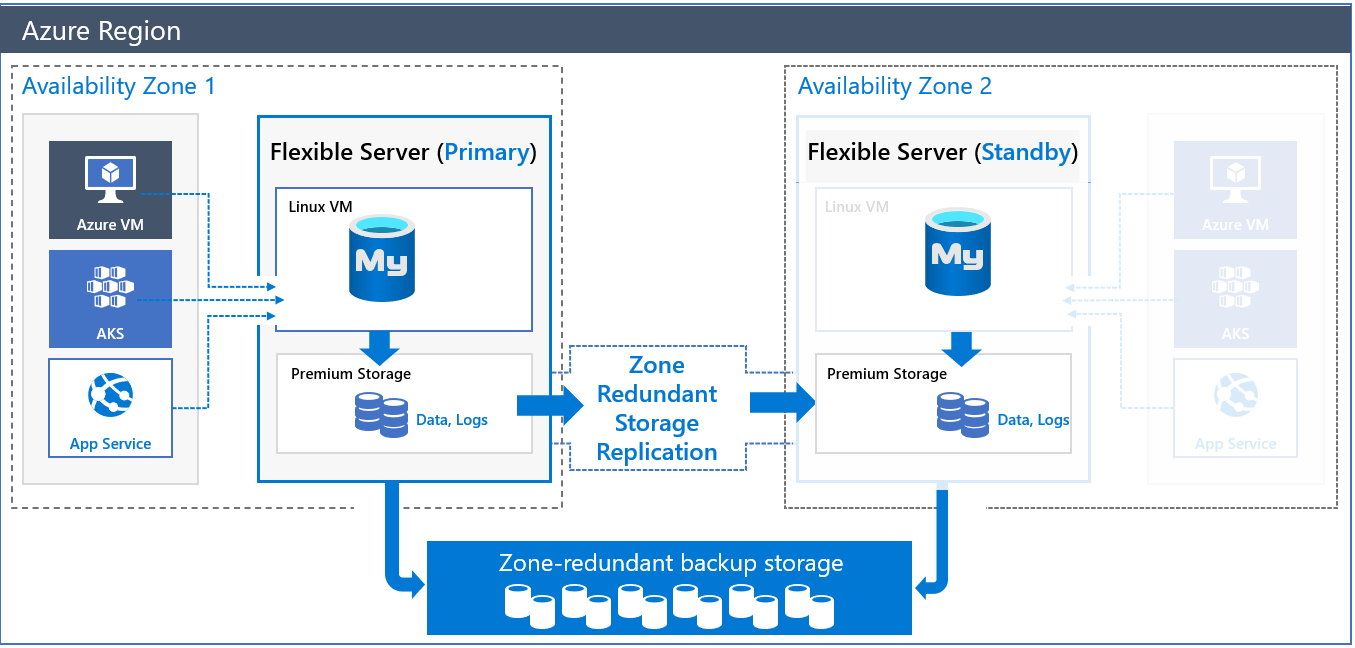
Die Daten- und Protokolldateien werden in zonenredundantem Speicher (ZRS) gehostet. Der Standbyserver liest die Protokolldateien kontinuierlich aus dem Speicherkonto des primären Servers, das durch die Replikation auf Speicherebene geschützt ist, und übergibt sie.
Bei einem Failover:
- Das Standbyreplikat wird aktiviert.
- Die binären Protokolldateien des primären Servers gelten weiterhin für den Standbyserver, der mit der letzten committeten Transaktion auf dem primären Server online geschaltet wird.
Auf Protokolle im ZRS kann auch dann zugegriffen werden, wenn der primäre Server nicht verfügbar ist. Durch diese Verfügbarkeit wird sichergestellt, dass keine Daten verloren gehen. Nachdem das Standbyreplikat aktiviert und die binären Protokolle angewandt wurden, übernimmt der aktuelle Standbyreplikatserver die Rolle des primären Servers. Das DNS wird aktualisiert, sodass Clientverbindungen an den neuen primären Server umgeleitet werden, wenn der Client erneut eine Verbindung herstellt. Das Failover ist für die Clientanwendung vollständig transparent und benötigt keinerlei Aktionen von Ihrer Seite. Die Hochverfügbarkeitslösung schaltet dann nach Möglichkeit den alten primären Server wieder online und legt ihn als Standbyserver fest.
Anwendungen werden über den Datenbankservernamen mit dem primären Server verbunden. Die Informationen des Standbyreplikats werden nicht für den Direktzugriff verfügbar gemacht. Commits und Schreibvorgänge werden bestätigt, nachdem die Protokolldateien im ZRS des primären Servers geleert wurden. Aufgrund der bei ZRS verwendeten synchronen Replikationstechnologie müssen Sie mit einer um 5–10 % höheren Latenz bei Schreibvorgängen und Commits durch die Anwendung rechnen.
Automatische Sicherungen (sowohl Momentaufnahmen als auch Protokollsicherungen) werden in zonenredundantem Speicher auf dem primären Datenbankserver durchgeführt.
Architektur mit Hochverfügbarkeit in gleicher Zone
Wenn Sie einen Server mit Hochverfügbarkeit in gleicher Zone bereitstellen, werden zwei Server in derselben Zone erstellt:
- Ein primärer Server
- Ein Standbyreplikatserver mit derselben Konfiguration wie der primäre Server (Computeebene, Computegröße, Speichergröße und Netzwerkkonfiguration)
Der Standbyserver bietet Infrastrukturredundanz mit einer separaten VM (Compute). Durch diese Redundanz werden die Failoverzeit und die Netzwerklatenz zwischen der Anwendung und dem Datenbankserver aufgrund der Colocation reduziert.
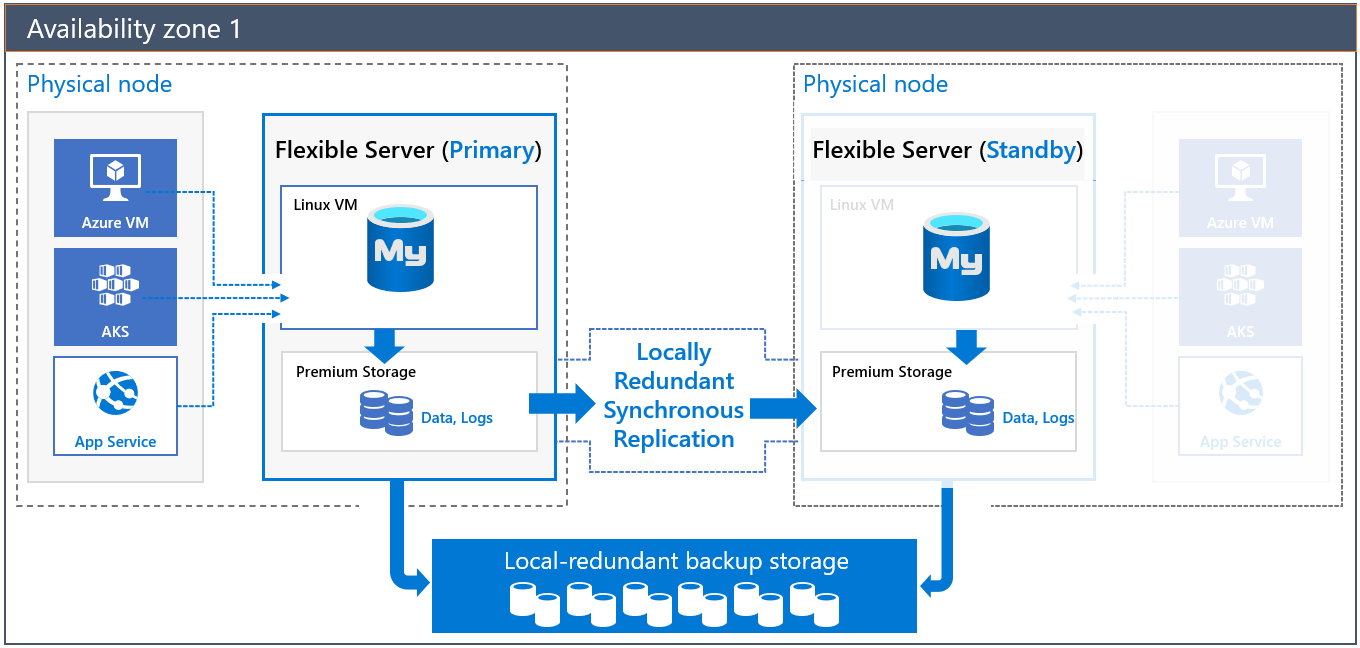
Die Daten- und Protokolldateien werden in lokal redundantem Speicher (LRS) gehostet. Der Standbyserver liest die Protokolldateien kontinuierlich aus dem Speicherkonto des primären Servers, das durch die Replikation auf Speicherebene geschützt ist, und übergibt sie.
Bei einem Failover:
- Das Standbyreplikat wird aktiviert.
- Die binären Protokolldateien des primären Servers gelten weiterhin für den Standbyserver, der mit der letzten committeten Transaktion auf dem primären Server online geschaltet wird.
Auf Protokolle im LRS kann auch dann zugegriffen werden, wenn der primäre Server nicht verfügbar ist. Durch diese Verfügbarkeit wird sichergestellt, dass keine Daten verloren gehen. Nachdem das Standbyreplikat aktiviert und die binären Protokolle angewandt wurden, übernimmt das aktuelle Standbyreplikat die Rolle des primären Servers. Das DNS wird aktualisiert, um Verbindungen an den neuen primären Server umzuleiten, wenn der Client erneut eine Verbindung herstellt. Das Failover ist für die Clientanwendung vollständig transparent und benötigt keinerlei Aktionen von Ihrer Seite. Die Hochverfügbarkeitslösung schaltet dann nach Möglichkeit den alten primären Server wieder online und legt ihn als Standbyserver fest.
Anwendungen werden über den Datenbankservernamen mit dem primären Server verbunden. Die Informationen des Standbyreplikats werden nicht für den Direktzugriff verfügbar gemacht. Commits und Schreibvorgänge werden bestätigt, nachdem die Protokolldateien im LRS des primären Servers geleert wurden. Da sich das primäre Replikat und das Standbyreplikat in derselben Zone befinden, gibt es weniger Verzögerung bei der Replikation und eine geringere Latenz zwischen dem Anwendungsserver und dem Datenbankserver. Das Setup in derselben Zone bietet keine Hochverfügbarkeit, wenn abhängige Infrastrukturen für die spezifische Verfügbarkeitszone ausfallen. Es kommt zu einer Downtime, bis alle abhängigen Dienste für diese Verfügbarkeitszone wieder online sind.
Automatische Sicherungen (sowohl Momentaufnahmen als auch Protokollsicherungen) werden in lokal redundantem Speicher des primären Datenbankservers durchgeführt.
Hinweis
Sowohl für zonenredundante Hochverfügbarkeit als auch für Hochverfügbarkeit in gleicher Zone gilt Folgendes:
- Bei einem Fehler hängt die Zeit, die für das Standbyreplikat erforderlich ist, um die Rolle des primären Replikats zu übernehmen, von der Zeit ab, die zum Übergeben des Binärprotokolls vom primären Speicherkonto an den Standbyserver benötigt wird. Es wird daher empfohlen, Primärschlüssel für alle Tabellen zu verwenden, um die Zeit für das Failover zu verringern. Die Dauer für Failover liegt in der Regel zwischen 60 und 120 Sekunden.
- Der Standbyserver ist nicht für Lese- oder Schreibvorgänge verfügbar. Er dient als passiver Standbyserver, der ein schnelles Failover ermöglichen soll.
- Verwenden Sie immer den vollqualifizierten Domänennamen (Fully Qualified Domain Name, FQDN) für Verbindungen mit dem primären Server. Vermeiden Sie die Verwendung einer IP-Adresse zum Herstellen einer Verbindung. Im Fall eines Failovers kann sich nach dem Wechsel der Rollen für den primären und den Standbyserver ein A-Datensatz im DNS ändern. Aufgrund dieser Änderung kann die Anwendung keine Verbindung mit dem neuen primären Server herstellen, wenn in der Verbindungszeichenfolge die IP-Adresse verwendet wird.
Failoverprozess
Geplant: erzwungenes Failover
Mit dem erzwungenen Failover von Azure Database for MySQL – Flexibler Server können Sie ein Failover manuell erzwingen. So können Sie die Funktionalität in Ihren Anwendungsszenarien testen und sie auf Ausfälle vorbereiten.
Beim erzwungenen Failover wird ein Failover ausgelöst. Dabei wird das Standbyreplikat aktiviert und als Primärserver mit demselben Datenbankservernamen festgelegt, indem der DNS-Eintrag aktualisiert wird. Der ursprüngliche primäre Server wird neu gestartet und auf das Standbyreplikat umgeschaltet. Clientverbindungen werden getrennt und müssen erneut verbunden werden, um ihre Vorgänge fortsetzen zu können.
Die gesamte Dauer des Failovers hängt von der aktuellen Workload und dem letzten Prüfpunkt ab. Im Allgemeinen dauert der Vorgang zwischen 60 und 120 Sekunden.
Hinweis
Das Azure Resource Health-Ereignis wird im Fall eines geplanten Failovers generiert und repräsentiert die Failoverdauer, während der der Server nicht verfügbar war. Die ausgelösten Ereignisse werden angezeigt, wenn Sie im linken Bereich auf „Resource Health“ klicken. Ein vom Benutzer initiiertes/manuelles Failover wird durch den Status „Nicht verfügbar“ dargestellt und als „Geplant“ gekennzeichnet. Beispiel: „Ein Failovervorgang wurde von einem autorisierten Benutzer ausgelöst (Geplant)“. Wenn Ihre Ressource für einen längeren Zeitraum in diesem Zustand verbleibt, öffnen Sie ein Supportticket, und wir helfen Ihnen.
Ungeplant: automatisches Failover
Ungeplante Dienstdowntime kann durch Softwarefehler oder Infrastrukturfehler wie Compute-, Netzwerk- oder Speicherfehler oder Stromausfälle verursacht werden, die sich auf die Verfügbarkeit der Datenbank auswirken. Falls eine Datenbank nicht verfügbar ist, wird die Replikation auf das Standbyreplikat abgebrochen, und das Standbyreplikat wird als primäre Datenbank aktiviert. Das DNS wird aktualisiert, und die Clients stellen eine neue Verbindung mit dem Datenbankserver her und setzen ihre Vorgänge fort.
Die Failovergesamtdauer beträgt erfahrungsgemäß zwischen 60 und 120 Sekunden. Abhängig von der Aktivität auf dem primären Datenbankserver zum Zeitpunkt des Failovers (z. B. umfangreiche Transaktionen und Wiederherstellungszeit) kann das Failover jedoch länger dauern.
Hinweis
Das Azure Resource Health-Ereignis wird im Fall eines ungeplanten Failovers generiert und repräsentiert die Failoverdauer, während der der Server nicht verfügbar war. Die ausgelösten Ereignisse werden angezeigt, wenn Sie im linken Bereich auf „Resource Health“ klicken. Das automatische Failover wird durch den Status „Nicht verfügbar“ dargestellt und als „Ungeplant“ gekennzeichnet. Beispiel: „Nicht verfügbar: Ein Failovervorgang wurde automatisch ausgelöst (Ungeplant)“. Wenn Ihre Ressource für einen längeren Zeitraum in diesem Zustand verbleibt, öffnen Sie ein Supportticket, und wir helfen Ihnen.
Funktionsweise der automatischen Failovererkennung auf Servern mit aktivierter Hochverfügbarkeit
Der primäre Server und der sekundäre Server verfügen über zwei Netzwerkendpunkte:
- Kundenendpunkt: Über diesen Endpunkt stellt der Kunde die Verbindung her und führt Abfragen an die Instanz aus.
- Verwaltungsendpunkt: Dieser Endpunkt wird intern für die Dienstkommunikation mit Verwaltungskomponenten und zum Herstellen einer Verbindung mit Back-End-Speicher verwendet.
Die Integritätsüberwachungskomponente führt kontinuierlich die folgenden Prüfungen durch:
- Die Überwachung pingt den Netzwerkendpunkt für die Verwaltung der Knoten an. Wenn diese Überprüfung zweimal hintereinander fehlschlägt, wird ein automatischer Failovervorgang ausgelöst. Durch diese Integritätsprüfung werden Szenarien, wie z. B. ein nicht verfügbarer/nicht reagierender Knoten aufgrund eines Betriebssystemproblems, ein Netzwerkproblem zwischen Verwaltungskomponenten und Knoten usw., abgedeckt.
- Die Überwachung führt auch eine einfache Abfrage an die Instanz aus. Wenn die Abfragen fehlschlagen, wird ein automatischer Failover ausgelöst. Durch diese Integritätsprüfung werden Szenarien, wie z. B. ein abgestürzter, beendeter oder hängen gebliebener MySQL-Dämon, Back-End-Speicherproblem usw., abgedeckt.
Hinweis
Bei einem Netzwerkproblem zwischen der Anwendung und dem Kundennetzwerkendpunkt (privater/öffentlicher Zugriff) im Netzwerkpfad bzw. auf dem Endpunkt oder bei DNS-Problemen auf der Clientseite, wird dieses Szenarios von der Integritätsprüfung nicht überwacht. Wenn Sie privaten Zugriff verwenden, dürfen die NSG-Regeln für das VNet die Kommunikation an den Kundennetzwerkendpunkt der Instanz auf Port 3306 nicht blockieren. Bei öffentlichem Zugriff müssen Firewallregeln festgelegt und der Netzwerkdatenverkehr auf Port 3306 zulässig sein (wenn der Netzwerkpfad andere Firewalls umfasst). Die DNS-Auflösung auf der Clientanwendungsseite muss ebenfalls beachtet werden.
Überwachen der Hochverfügbarkeit
Über deb Hochverfügbarkeitsstatus im Bereich Hochverfügbarkeit des Servers im Portal können Sie den Hochverfügbarkeits-Konfigurationsstatus des Servers ermitteln.
| Status | Beschreibung |
|---|---|
| NotEnabled | Hochverfügbarkeit ist nicht aktiviert. |
| ReplicatingData | Der Standbyserver wird zum Zeitpunkt der Serverbereitstellung mit Hochverfügbarkeit oder beim Aktivieren der Hochverfügbarkeitsoption mit dem primären Server synchronisiert. |
| FailingOver | Der Datenbankserver führt ein Failover vom primären Server auf das Standbyreplikat durch. |
| Healthy | Die Hochverfügbarkeitsoption ist aktiviert. |
| RemovingStandby | Wenn die Hochverfügbarkeitsoption deaktiviert ist und der Löschvorgang ausgeführt wird. |
Sie können auch die folgenden Metriken verwenden, um die Integrität des Hochverfügbarkeitsservers zu überwachen.
| Anzeigename der Metrik | Metrik | Einheit | Beschreibung |
|---|---|---|---|
| E/A-Status für HA | ha_io_running | State | „E/A-Status für HA“ gibt den Status der Hochverfügbarkeitsreplikation an. Der Metrikwert lautet 1, wenn der E/A-Thread ausgeführt wird, und 0, wenn er nicht ausgeführt wird. |
| SQL-Status für HA | ha_sql_running | State | „SQL-Status für HA“ gibt den Status der Hochverfügbarkeitsreplikation an. Der Metrikwert lautet 1, wenn der SQL-Thread ausgeführt wird, und 0, wenn er nicht ausgeführt wird. |
| Verzögerung bei der Hochverfügbarkeitsreplikation | replication_lag | Sekunden | Die Replikationsverzögerung ist die Anzahl der Sekunden, die der Standbyserver bei der Übergabe der Transaktionen zurück liegt, die am primären Server empfangen wurden. |
Begrenzungen
Folgende Überlegungen sollten die Sie bei der Nutzung von Hochverfügbarkeit beachten:
- Zonenredundante Hochverfügbarkeit kann nur während der Erstellung des flexiblen Servers festgelegt werden.
- Hochverfügbarkeit wird auf der burstfähigen Computeebene nicht unterstützt.
- Ein Neustart des primären Datenbankservers zur Übernahme von Änderungen an statischen Parametern führt auch zu einem Neustart des Standbyreplikats.
- Der GTID-Modus wird aktiviert, da die Hochverfügbarkeitslösung GTID verwendet. Überprüfen Sie, ob für Ihre Workload Einschränkungen für die Replikation mit GTID gelten.
Hinweis
Wenn Sie nach der Servererstellung die Hochverfügbarkeit für dieselbe Zone aktivieren, müssen Sie sicherstellen, dass die Serverparameter „enforce_gtid_consistency“ und „gtid_mode“ auf EIN festgelegt sind, bevor Sie die Hochverfügbarkeit aktivieren.
Hinweis
Die automatische Speichervergrößerung ist standardmäßig für einen Server mit konfigurierter Hochverfügbarkeit aktiviert und kann nicht deaktiviert werden.
Häufig gestellte Fragen (FAQ)
Was sind die SLAs für einen flexiblen Server mit aktiviertem Hochverfügbarkeitsstatus mit derselben Zone im Vergleich zu einem mit zonenredundanter Hochverfügbarkeit?
SLA-Informationen für Azure Database for MySQL – Flexibler Server finden Sie unter SLA für Azure Database for MySQL.
Wie werden hochverfügbare Server (HA) in Rechnung gestellt? Server, für die die Hochverfügbarkeit aktiviert ist, verfügen über ein primäres und ein sekundäres Replikat. Sekundäre Replikate können sich in derselben Zone befinden oder zonenredundant sein. Ihnen werden die bereitgestellte Compute und der bereitstellte Speicher sowohl für das primäre als auch für das sekundäre Replikat in Rechnung gestellt. Wenn Sie beispielsweise über ein primäres Replikat mit 4 virtuellen Kernen Compute und 512 GB bereitgestelltem Speicher verfügen, verfügt Ihr sekundäres Replikat auch über 4 virtuelle Kerne und 512 GB bereitgestellten Speicher. Für Ihren zonenredundanten Hochverfügbarkeitsserver werden 8 virtuelle Kerne und 1.024 GB Speicher berechnet. Abhängig von Ihrem Sicherungsspeichervolume wird Ihnen möglicherweise auch der Sicherungsspeicher in Rechnung gestellt.
Kann ich das Standbyreplikat für Lese- oder Schreibvorgänge verwenden?
Der Standbyserver ist nicht für Lese- oder Schreibvorgänge verfügbar. Er dient als passiver Standbyserver, der ein schnelles Failover ermöglichen soll.Kommt es bei einem Failover zu Datenverlusten?
Auf Protokolle im ZRS kann auch dann zugegriffen werden, wenn der primäre Server nicht verfügbar ist. Durch diese Verfügbarkeit wird sichergestellt, dass keine Daten verloren gehen. Nachdem das Standbyreplikat aktiviert und die binären Protokolle angewandt wurden, übernimmt das Standbyreplikat die Funktionen des primären Servers.Muss ich nach einem Failover Maßnahmen ergreifen?
Die Ausfallsicherung ist für die Client-Anwendung völlig transparent. Sie müssen keine Maßnahmen ergreifen. Die Anwendungen sollten lediglich die Wiederholungslogik für ihre Verbindungen nutzen.Was geschieht, wenn ich keine spezifische Zone für mein Standbyreplikat auswähle? Kann ich die Zone später ändern?
Wenn Sie keine Zone auswählen, wird nach dem Zufallsprinzip eine Zone ausgewählt. Es handelt sich um diejenige, die für den primären Server verwendet wird. Um die Zone später zu ändern, können Sie Hochverfügbarkeit im Fenster Hochverfügbarkeit auf Deaktiviert setzen und dann wieder auf Zone redundant setzen und eine Zone wählen.Erfolgt die Replikation zwischen dem primären Replikat und den Standbyreplikaten synchron?
Die Replikation zwischen dem primären und dem Standby-Server entspricht dem semisynchronen Modus in MySQL. Wenn eine Transaktion committet wird, erfolgt nicht unbedingt ein Commit auf den Standbyserver. Wenn das primäre Replikat jedoch nicht verfügbar ist, repliziert der Standbyserver alle Datenänderungen aus dem primären Replikat, um sicherzustellen, dass keine Datenverluste auftreten.Wird bei allen ungeplanten Ausfällen ein Failover auf das Standbyreplikat durchgeführt?
Bei einem Datenbankabsturz oder Knotenausfall wird der Flexible Server-Virtuelle-Computer auf demselben Knoten neu gestartet. Gleichzeitig wird ein automatisches Failover ausgelöst. Wenn die Flexible Server-VM vor Abschluss des Failovers erfolgreich neu gestartet wurde, wird der Failovervorgang abgebrochen. Welcher Server als primäres Replikat festgelegt wird, hängt vom Prozess ab, der zuerst abgeschlossen wird.Hat die Verwendung von Hochverfügbarkeit Auswirkungen auf die Leistung?
Bei zonenredundanter Hochverfügbarkeit gibt es zwar keine größeren Leistungseinbußen bei Lese-Workloads in Verfügbarkeitszonen, aber die Latenz beim Schreiben von Abfragen kann um bis zu 40 Prozent sinken. Der Anstieg der Schreiblatenz ist auf die synchrone Replikation in der Verfügbarkeitszone zurückzuführen. Die Einbußen bei der Schreiblatenz sind bei zonenredundanter Hochverfügbarkeit in der Regel doppelt so hoch im Vergleich zur Hochverfügbarkeit in gleicher Zone. Da sich bei Hochverfügbarkeit in gleichen Zonen das primäre Replikat und das Standbyreplikat in derselben Zone befinden, ist die Replikationswartezeit und folglich auch die synchrone Schreiblatenz geringer. Zusammenfassung: Wenn Ihnen die Schreiblatenz wichtiger ist als die Verfügbarkeit, sollten Sie sich für Hochverfügbarkeit in gleicher Zone entscheiden. Wenn Ihnen jedoch die Verfügbarkeit und Resilienz Ihrer Daten wichtiger ist als die Reduzierung der Schreiblatenz, sollten Sie sich für zonenredundante Hochverfügbarkeit entscheiden. Um die genauen Leistungseinbußen eines Latenzabfalls bei der Einrichtung von Hochverfügbarkeit zu messen, empfehlen wir Ihnen, Leistungstests für Ihre Workloads durchzuführen, um eine fundierte Entscheidung zu treffen.Wie wird mein Hochverfügbarkeitsserver gewartet?
Geplante Ereignisse wie die Skalierung von Rechenleistung und kleinere Versions-Upgrades werden zuerst auf der ursprünglichen Standbyinstanz durchgeführt, dann wird ein geplanter Failovervorgang ausgelöst und anschließend auf der ursprünglichen primären Instanz ausgeführt. Sie können das Zeitfenster für geplante Wartungen für Hochverfügbarkeitsserver genauso wie für flexible Server festlegen. Die Downtime entspricht der Downtime der Instanz von Azure Database for MySQL – Flexibler Server, wenn Hochverfügbarkeit deaktiviert ist.Kann ich eine Zeitpunktwiederherstellung (Point-in-Time Restore, PITR) für meinen Hochverfügbarkeitsserver durchführen?
Sie können eine Zeitpunktwiederherstellung (PITR) der Instanz von Azure Database for MySQL – Flexibler Server mit aktivierter Hochverfügbarkeit auf eine neue Instanz von Azure Database for MySQL – Flexibler Server mit deaktivierter Hochverfügbarkeit durchführen. Wenn der Quellserver mit zonenredundanter Hochverfügbarkeit erstellt wurde, können Sie später die zonenredundante Hochverfügbarkeit oder Hochverfügbarkeit in gleicher Zone für den wiederhergestellten Server aktivieren. Wenn der Quellserver mit Hochverfügbarkeit in gleicher Zone erstellt wurde, können Sie für den wiederhergestellten Server nur Hochverfügbarkeit in gleicher Zone aktivieren.Kann ich Hochverfügbarkeit auf einem Server aktivieren, nachdem der Server erstellt wurde?
Die zonenredundante Hochverfügbarkeit muss während der Erstellung des Servers aktiviert werden. Nach dem Erstellen des Servers können Sie die Hochverfügbarkeit in gleicher Zone aktivieren. Bevor Sie die Hochverfügbarkeit für dieselbe Zone aktivieren, stellen Sie sicher, dass die Serverparameter „enforce_gtid_consistency“ und "gtid_mode" auf ON
gesetzt istKann ich die Hochverfügbarkeit für einen Server deaktivieren, nachdem dieser erstellt wurde?
Sie können die Hochverfügbarkeit für einen Server deaktivieren, nachdem dieser erstellt wurde. Die Abrechnung wird sofort beendet.Wie kann ich die Downtime verkürzen?
Wenn Sie die Hochverfügbarkeit nicht nutzen, müssen Sie dennoch in der Lage sein, die Downtime für Ihre Anwendung zu minimieren. Dienstdowntime, z. B. durch geplante Patches, Nebenversionsupgrades oder von der Kundschaft initiierte Vorgänge wie die Computeskalierung, können während geplanter Wartungsfenster ausgeführt werden. Sie können von Azure initiierte Wartungstasks an Wochentagen und zu Uhrzeiten planen, die sich am wenigsten auf die Anwendung auswirken, um die Beeinträchtigungen möglichst gering zu halten.Kann ich ein Lesereplikat für einen Server verwenden, für den Hochverfügbarkeit aktiviert ist?
Ja, Lesereplikate werden für Hochverfügbarkeitsserver unterstützt.Kann ich die Datenreplikation für Hochverfügbarkeitsserver nutzen?
Der Support für die Replikation eingehender Daten für Hochverfügbarkeits-fähige Server (HA) ist nur über die GTID-basierte Replikation verfügbar. Die gespeicherte Prozedur für die Replikation mit GTID ist auf allen HA-fähigen Servern unter dem Namenmysql.az_replication_with_gtidverfügbar.Kann ich während eines Serverneustarts oder beim Hoch- bzw. Herunterskalieren ein Failover auf den Standbyserver durchführen, um die Downtime zu verringern?
Derzeit nutzt Azure Database for MySQL – Flexibler Server geplante Failover zum Optimieren von Hochverfügbarkeitsvorgängen (einschließlich Hoch- und Herunterskalieren) und geplante Wartungen zum Reduzieren der Downtime. Wenn solche Vorgänge gestartet werden, wird zuerst die ursprüngliche Standbyinstanz verarbeitet, dann ein geplanter Failovervorgang ausgelöst und schließlich die ursprüngliche primäre Instanz verarbeitet.Kann man den Verfügbarkeitsmodus (zonenredundante Hochverfügbarkeit/gleiche Zone) des Servers ändern
Wenn Sie den Server mit aktiviertem zonenredundantem Hochverfügbarkeitsmodus erstellen, können Sie von zonenredundanter Hochverfügbarkeit zu gleicher Zone wechseln und umgekehrt. Um den Verfügbarkeitsmodus zu ändern, können Sie Hochverfügbarkeit im Fenster Hochverfügbarkeit auf Deaktiviert setzen und dann wieder auf Zone redundant oder gleiche Zone setzen und Hochverfügbarkeitsmodus wählen.
Nächste Schritte
- Weitere Informationen zur Geschäftskontinuität
- Weitere Informationen zur zonenredundanten Hochverfügbarkeit
- Weitere Informationen zu Sicherung und Wiederherstellung