Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Tip
Microsoft Fabric Data Warehouse ist ein relationales Enterprise-Warehouse auf einem Data Lake-Fundament mit zukunftsfähiger Architektur, integrierter KI und neuen Features. Wenn Sie mit Data Warehouse noch nicht vertraut sind, beginnen Sie mit Fabric Data Warehouse. Vorhandene dedizierte SQL-Pool-Workloads können auf Fabric aktualisieren, um neue Funktionen in den Bereichen Data Science, Echtzeitanalyse und Berichterstellung zu nutzen.
In diesem Tutorial erfahren Sie, wie Sie explorative Datenanalysen mit vorhandenen offenen Datasets durchführen, ohne dass eine Speichereinrichtung erforderlich ist. Sie kombinieren verschiedene Azure Open Datasets-Instanzen über einen serverlosen SQL-Pool. Anschließend visualisieren Sie die Ergebnisse in Synapse Studio für Azure Synapse Analytics.
In diesem Tutorial:
- Zugreifen auf den integrierten serverlose SQL-Pool
- Zugreifen auf Azure Open Datasets zur Verwendung von Tutorialdaten
- Durchführen einer einfachen Datenanalyse mit SQL
Zugreifen auf den serverlosen SQL-Pool
Jeder Arbeitsbereich wird mit einem vorkonfigurierten serverlosen SQL-Pool namens Built-in bereitgestellt. So greifen Sie darauf zu
- Öffnen Sie Ihren Arbeitsbereich, und wählen Sie den Hub Entwicklung aus.
- Wählen Sie die Schaltfläche +Neue Ressource hinzufügen aus.
- Wählen Sie SQL-Skript aus.
Sie können dieses Skript verwenden, um Ihre Daten zu untersuchen, ohne SQL-Kapazität reservieren zu müssen.
Wenn Sie kein Azure-Abonnement besitzen, können Sie ein kostenloses Konto erstellen, bevor Sie beginnen.
Zugreifen auf die Tutorialdaten
Alle in diesem Tutorial verwendeten Daten befinden sich im Speicherkonto azureopendatastorage, das Azure Open Datasets zur freien Verwendung in Tutorials wie diesem enthält. Sie können alle Skripts direkt und unverändert aus Ihrem Arbeitsbereich ausführen, sofern Ihr Arbeitsbereich Zugriff auf ein öffentliches Netzwerk hat.
In diesem Tutorial wird ein Dataset über New York City (NYC) Taxi verwendet:
- Abhol- und Bringzeiten und -daten
- Abhol- und Rückgabeorte
- Fahrtentfernungen
- Einzeltarife
- Tarifarten
- Zahlungsarten
- Vom Fahrer gemeldete Fahrgastzahlen
Die OPENROWSET(BULK...)-Funktion ermöglicht den Zugriff auf Dateien in Azure Storage. Die [OPENROWSET](develop-openrowset.md)-Funktion liest den Inhalt einer Remotedatenquelle (z. B. einer Datei) und gibt den Inhalt als eine Reihe von Zeilen zurück.
Führen Sie zunächst die folgende Abfrage aus, um sich mit den Daten von NYC Taxi vertraut zu machen:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
Andere verfügbare Datasets
Analog dazu können Sie mithilfe der folgenden Abfrage das Dataset für gesetzliche Feiertage abfragen:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
Mithilfe der folgenden Abfrage können Sie auch das Dataset mit den Wetterdaten abfragen:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
Weitere Informationen zur Bedeutung der einzelnen Spalten finden Sie in den Beschreibungen der Datasets:
Automatische Schemaableitung
Da die Daten im Parquet-Dateiformat vorliegen, kann das Schema automatisch abgeleitet werden. Die Daten können somit abgefragt werden, ohne die Datentypen aller Spalten in den Dateien aufzulisten. Außerdem können Sie den Mechanismus für virtuelle Spalten sowie die filepath-Funktion verwenden, um eine Teilmenge der Dateien herauszufiltern.
Hinweis
Die Standardsortierung ist SQL_Latin1_General_CP1_CI_ASIf. Bei einer nicht standardmäßigen Sortierung berücksichtigen Sie die Groß-/Kleinschreibung.
Wenn Sie eine Datenbank mit einer Sortierung erstellen, bei der die Groß-/Kleinschreibung beachtet wird, sollten Sie beim Angeben von Spalten sicherstellen, dass Sie den richtigen Namen der Spalte verwenden.
Der Spaltenname tpepPickupDateTime wäre korrekt, während tpeppickupdatetime in einer nicht standardmäßigen Sortierung nicht funktionieren würde.
Zeitreihen, Saisonalität und Ausreißeranalyse
Mit der folgenden Abfrage können Sie ganz einfach die jährliche Anzahl von Taxifahrten zusammenfassen:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
Der folgende Ausschnitt zeigt das Ergebnis für die jährliche Anzahl von Taxifahrten:
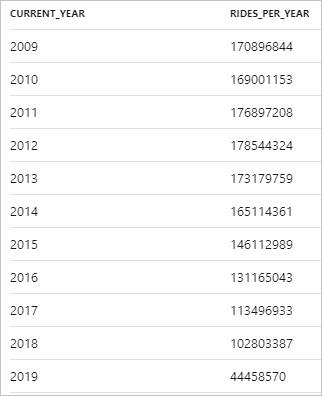
Die Daten können in Synapse Studio visualisiert werden. Wechseln Sie hierzu von der Tabellenansicht zur Diagrammansicht. Sie können zwischen verschiedenen Diagrammtypen (Flächendiagramm, Balkendiagramm, Säulendiagramm, Liniendiagramm, Kreisdiagramm oder Punktdiagramm) wählen. Erstellen Sie in diesem Fall ein Säulendiagramm, und legen Sie die Kategoriespalte auf current_year fest:
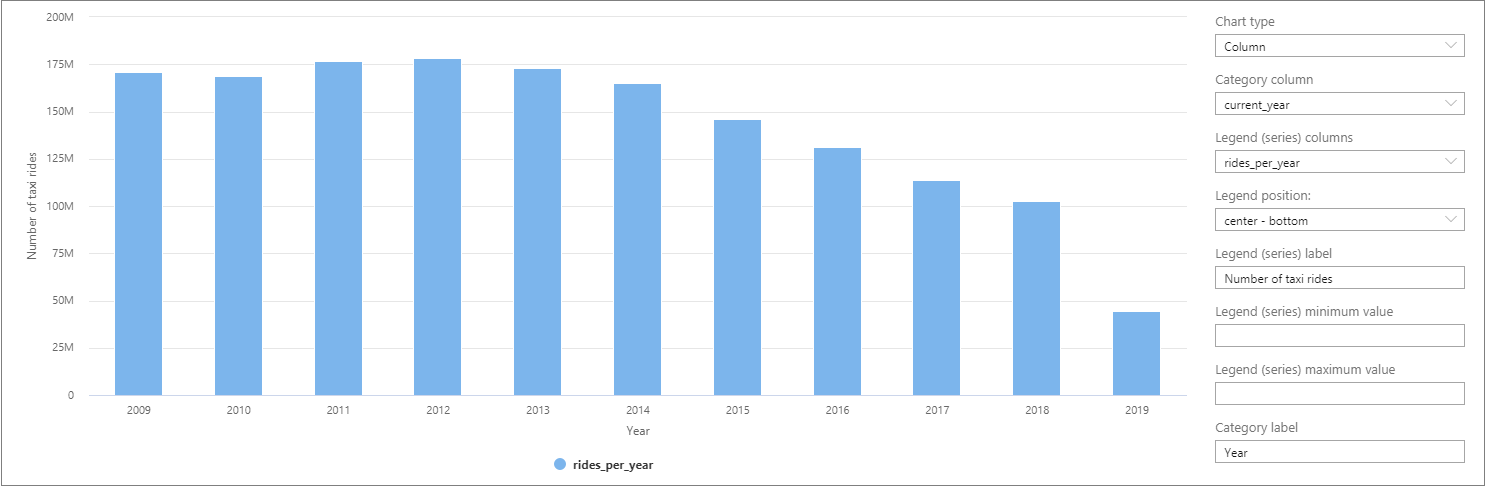
In dieser Visualisierung können Sie sehen, dass die Anzahl der Fahrten im Lauf der Jahre zurückgegangen ist. Dieser Rückgang ist vermutlich auf die zunehmende Beliebtheit von Carsharing-Unternehmen zurückzuführen.
Hinweis
Zum Zeitpunkt der Erstellung dieses Tutorials liegen für 2019 nur unvollständige Daten vor. Dies hat einen signifikanten Rückgang bei der Anzahl von Fahrten für dieses Jahr zur Folge.
Als Nächstes konzentrieren wir uns bei der Analyse auf ein einzelnes Jahr, beispielsweise 2016. Die folgende Abfrage gibt die tägliche Anzahl von Fahrten in jenem Jahr zurück.
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
Der folgende Ausschnitt zeigt das Ergebnis für diese Abfrage:
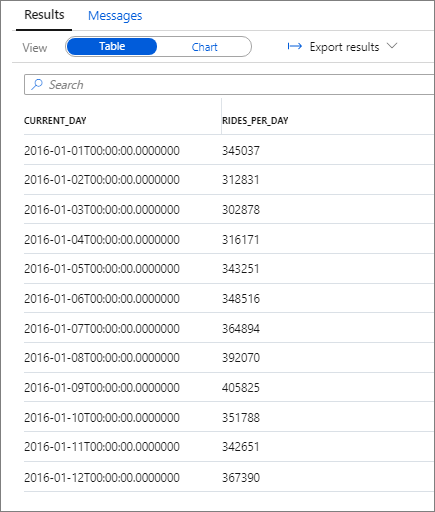
Auch diese Daten können ganz einfach in einem Säulendiagramm visualisiert werden, indem die Spalte Kategorie auf current_day und die Spalte Legende (Reihen) auf rides_per_day festgelegt wird.
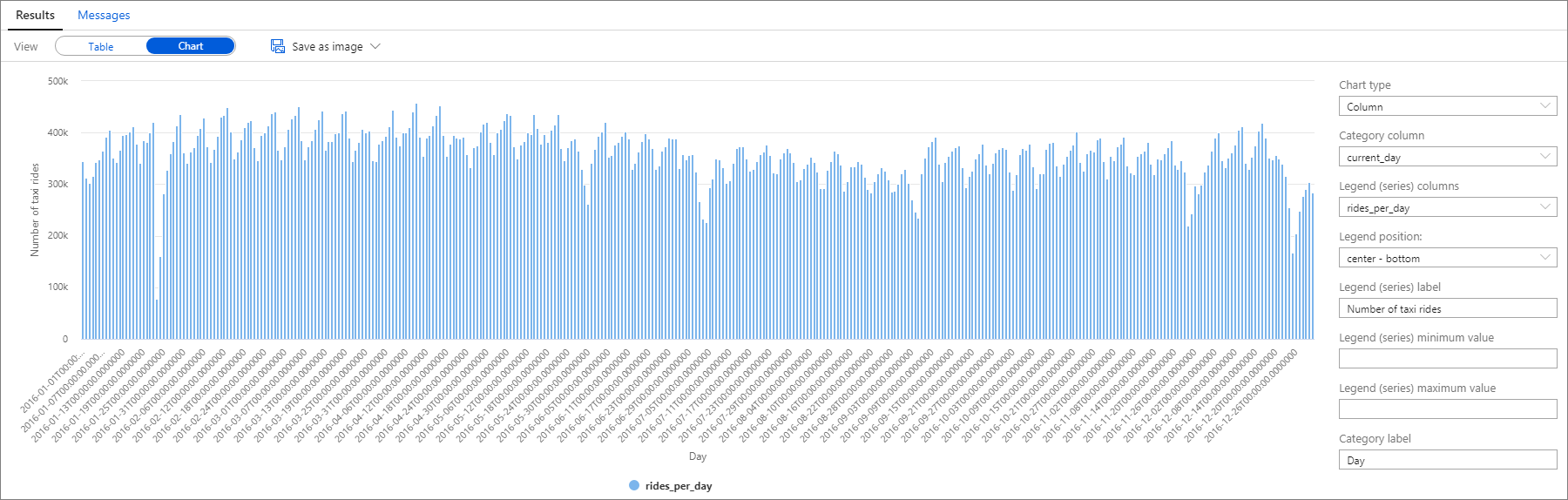
Im ausgegebenen Diagramm ist zu sehen, dass es ein wöchentliches Muster gibt, wobei der jeweilige Samstag der Spitzentag ist. In den Sommermonaten werden urlaubsbedingt weniger Taxifahrten durchgeführt. Sie können außerdem einige signifikante Einbrüche bei der Anzahl von Taxifahrten sehen, ohne dass ein klares Muster für den Zeitpunkt und den Grund dieser Rückgänge erkennbar wäre.
Im nächsten Schritt soll geprüft werden, ob der Rückgang der Fahrten mit Feiertagen korreliert. Um sehen zu können, ob es eine Korrelation gibt, wird das Dataset der NYC-Taxifahrten mit dem Dataset der gesetzlichen Feiertage verknüpft:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
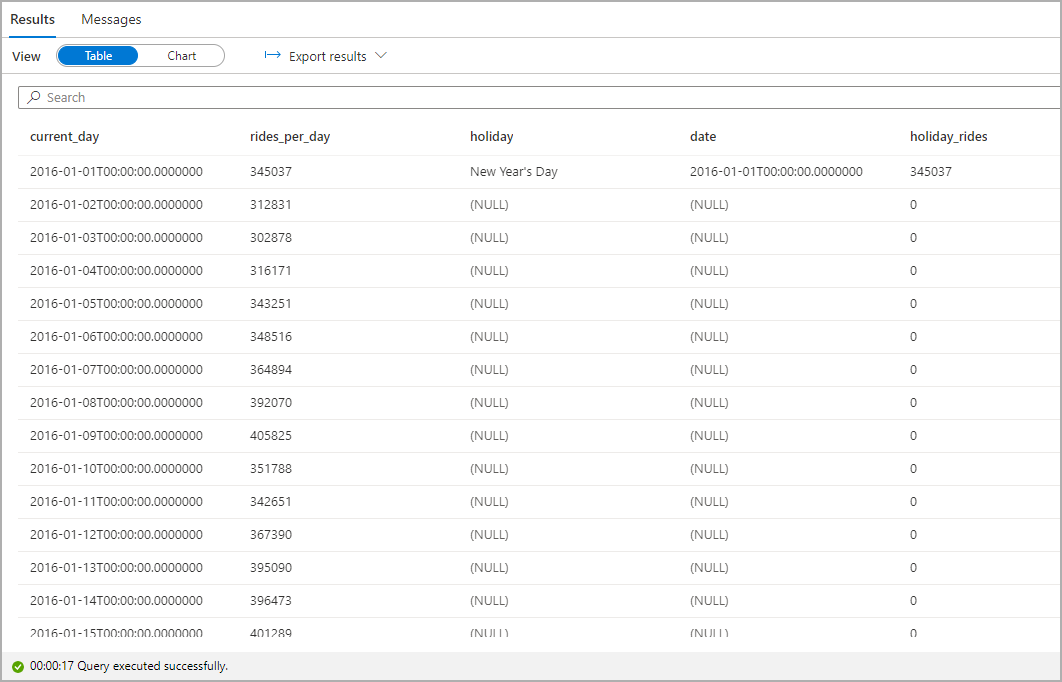
Heben Sie die Anzahl der Taxifahrten an gesetzlichen Feiertagen hervor. Zu diesem Zweck wählen Sie current_day für die Spalte Kategorie und rides_per_day und holiday_rides als die Spalte Legende (Reihen) aus.
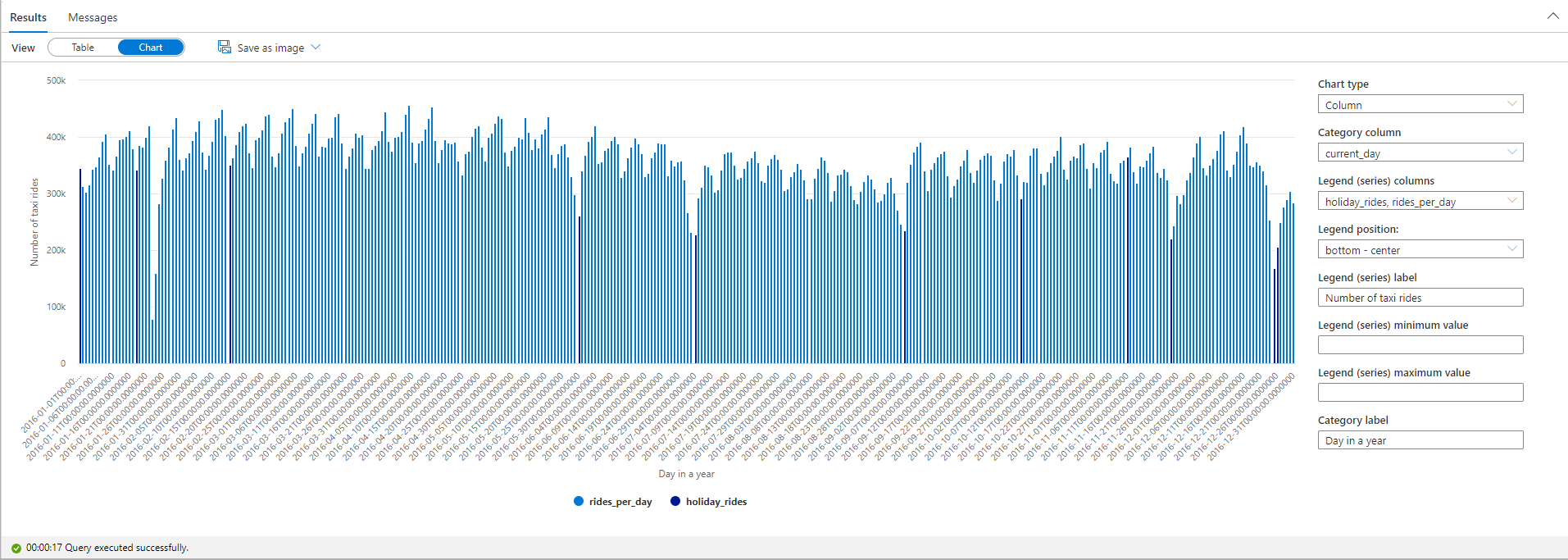
Wie Sie dem Diagramm entnehmen können, ist die Anzahl von Taxifahrten an gesetzlichen Feiertagen geringer. Es gibt immer noch einen unerklärlichen deutlichen Einbruch am 23. Januar. Daher fragen wir als Nächstes das Dataset mit den Wetterdaten ab, um das Wetter in NYC an diesem Tag zu überprüfen:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

Die Ergebnisse der Abfrage zeigen, dass der Einbruch bei der Anzahl von Taxifahren auf Folgendes zurückzuführen ist:
- An diesem Tag gab es in NYC einen Schneesturm mit starkem Schneefall (~ 30 cm).
- Es war kalt (Temperatur unter Null Grad Celsius).
- Es war windig (~ 10 m/s).
Dieses Tutorial hat gezeigt, wie ein Datenanalyst schnell eine explorative Datenanalyse durchführen kann. Sie können verschiedene Datasets kombinieren, indem Sie einen serverlosen SQL-Pool verwenden und die Ergebnisse mithilfe von Azure Synapse Studio visualisieren.
Zugehöriger Inhalt
Im Tutorial Verwenden eines serverlosen SQL-Pools mit Power BI Desktop und Erstellen eines Berichts erfahren Sie, wie Sie einen serverlosen SQL-Pool mit Power BI Desktop verbinden und Berichte erstellen.
Informationen dazu, wie externe Tabellen in einem serverlosen SQL-Pool verwendet werden, finden Sie unter Verwenden externer Tabellen mit Synapse SQL.