Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
Hinweis
Fabric Runtime 2.0 befindet sich derzeit in einer experimentellen Vorschauphase. Weitere Informationen finden Sie in den Einschränkungen und Hinweisen.
Fabric Runtime bietet eine nahtlose Integration in das Microsoft Fabric-Ökosystem und bietet eine robuste Umgebung für Data Engineering- und Data Science-Projekte, die von Apache Spark unterstützt werden.
In diesem Artikel wird Fabric Runtime 2.0 Experimental (Preview) vorgestellt, die neueste Runtime, die für Big Data-Berechnungen in Microsoft Fabric entwickelt wurde. Es hebt die wichtigsten Features und Komponenten hervor, die diese Version zu einem erheblichen Fortschritt für skalierbare Analysen und erweiterte Workloads machen.
Fabric Runtime 2.0 enthält die folgenden Komponenten und Upgrades, die entwickelt wurden, um Ihre Datenverarbeitungsfunktionen zu verbessern:
- Apache Spark 4.0
- Betriebssystem: Azure Linux 3.0 (Mariner 3.0)
- Java: 21
- Skala: 2.13
- Python: 3.12
- Delta Lake: 4.0
Aktivieren von Runtime 2.0
Sie können Runtime 2.0 entweder auf Arbeitsbereichsebene oder auf Der Umgebungselementebene aktivieren. Verwenden Sie die Arbeitsbereichseinstellung, um Runtime 2.0 als Standard für alle Spark-Workloads in Ihrem Arbeitsbereich anzuwenden. Erstellen Sie alternativ ein Umgebungselement mit Runtime 2.0 für bestimmte Notizbücher oder Spark-Auftragsdefinitionen, welches die Standardeinstellung des Arbeitsbereichs außer Kraft setzt.
Aktivieren von Runtime 2.0 in arbeitsbereichseinstellungen
So legen Sie Runtime 2.0 als Standard für den gesamten Arbeitsbereich fest:
Navigieren Sie im Fabric-Arbeitsbereich zur Registerkarte Arbeitsbereichseinstellungen.
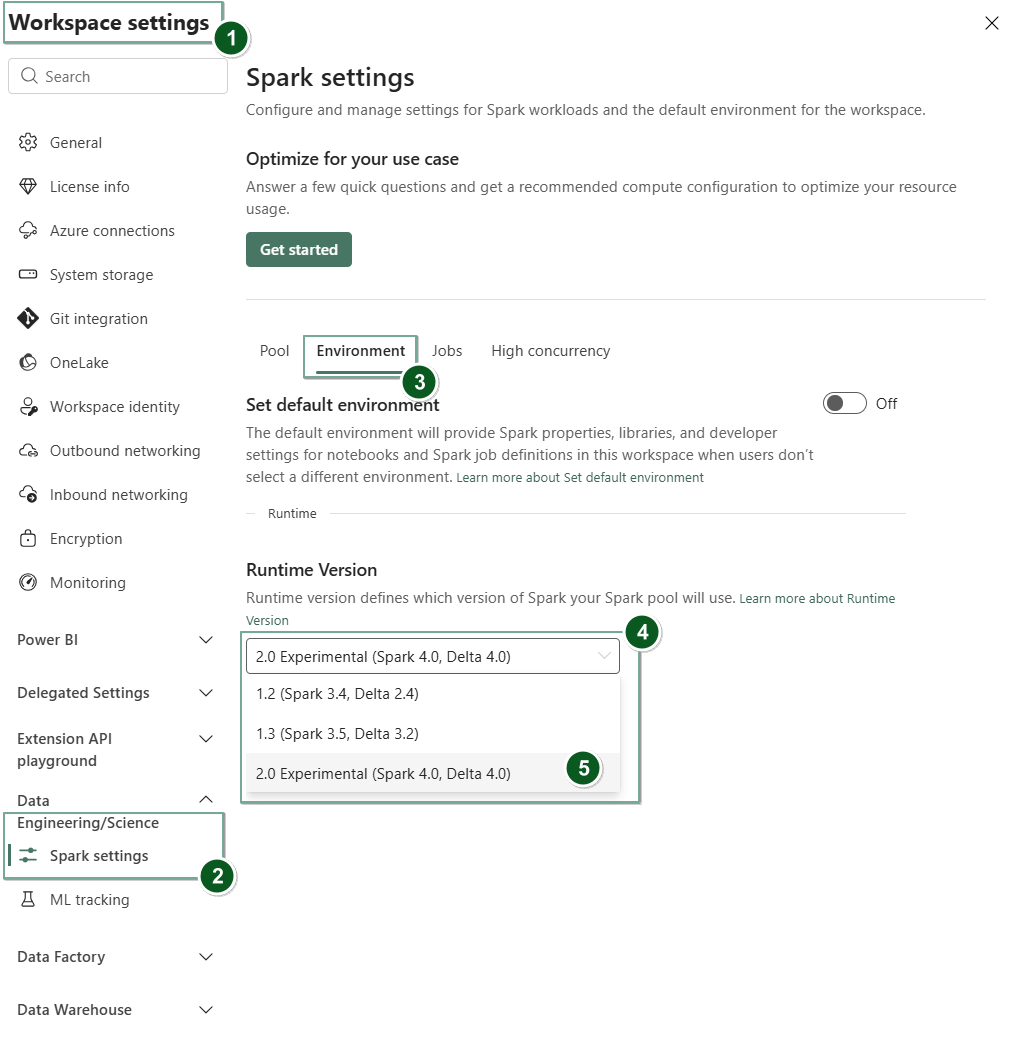
Wechseln Sie zur Registerkarte "Datentechnik/Wissenschaft ", und wählen Sie "Spark"-Einstellungen aus.
Wählen Sie die Registerkarte Umgebung aus.
Wählen Sie unter der Dropdownliste der Laufzeitversion2.0 Experimental (Spark 4.0, Delta 4.0) aus, und speichern Sie Ihre Änderungen. Diese Aktion legt Runtime 2.0 als Standardlaufzeit für Ihren Arbeitsbereich fest.

Aktivieren von Runtime 2.0 in einem Umgebungselement
So verwenden Sie Runtime 2.0 mit bestimmten Notizbüchern oder Spark-Auftragsdefinitionen:
Erstellen Sie ein neues Umgebungselement , oder öffnen Sie ein neues und vorhandenes Element.
Wählen Sie unter der Dropdownliste "Runtime" 2.0 Experimental (Spark 4.0, Delta 4.0)
SaveundPublishIhre Änderungen aus.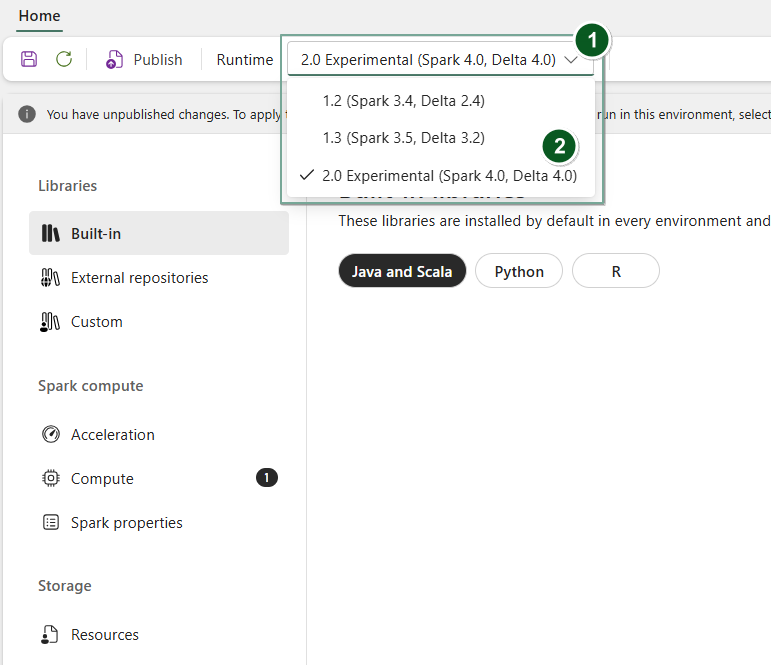
Von Bedeutung
Es kann etwa 2 bis 5 Minuten dauern, bis Spark 2.0-Sitzungen gestartet werden, da Starterpools nicht Teil der frühen experimentellen Veröffentlichung sind.
Als Nächstes können Sie dieses Environment-Element mit Ihrem
NotebookoderSpark Job Definitionverwenden.

Sie können jetzt mit den neuesten Verbesserungen und Funktionen experimentieren, die in Fabric Runtime 2.0 (Spark 4.0 und Delta Lake 4.0) eingeführt wurden.
Experimentelle öffentliche Vorschau
Die experimentelle Vorschauphase von Fabric Runtime 2.0 bietet Ihnen frühzeitigen Zugriff auf neue Features und APIs von Spark 4.0 und Delta Lake 4.0. Mit der Vorschau können Sie die neuesten Spark-basierten Verbesserungen sofort verwenden, um eine reibungslose Bereitschaft und einen reibungslosen Übergang für zukünftige Änderungen wie die neueren Java-, Scala- und Python-Versionen sicherzustellen.
Tipp
Um aktuelle Informationen, eine ausführliche Liste der Änderungen und spezifische Versionshinweise für Fabric-Runtimes zu erhalten, sollten Sie Spark-Runtimes – Versionen und Updates lesen und abonnieren.
Einschränkungen und Hinweise
Fabric Runtime 2.0 befindet sich derzeit in einer experimentellen öffentlichen Vorschauphase, die für Benutzer entwickelt wurde, um die neuesten Features und APIs von Spark und Delta Lake in den Entwicklungs- oder Testumgebungen zu erkunden und zu experimentieren. Während diese Version Zugriff auf Kernfunktionen bietet, gibt es bestimmte Einschränkungen:
Sie können Spark 4.0-Sitzungen verwenden, Code in Notizbüchern schreiben, Spark-Auftragsdefinitionen planen und mit PySpark, Scala und Spark SQL verwenden. R-Sprache wird in dieser frühen Version jedoch nicht unterstützt.
Sie können Bibliotheken direkt in Ihrem Code mit Pip und Conda installieren. Sie können Spark-Einstellungen über die %%configure Optionen in Notizbüchern und Spark Job Definitions (SJDs) festlegen.
Sie können im Lakehouse mit Delta Lake 4.0 lesen und schreiben, aber einige erweiterte Features wie V-Order, native Parquet-Schreiben, AutoCompaction, optimiertes Schreiben, Merge, Schemaentwicklung und Time Travel sind in dieser frühen Version nicht enthalten.
Der Spark Advisor ist zurzeit nicht verfügbar. Überwachungstools wie Spark UI und Protokolle werden jedoch in dieser frühen Version unterstützt.
Funktionen wie Data Science-Integrationen, einschließlich Copilot, sowie Connectors wie Kusto, SQL Analytics, Cosmos DB und MySQL Java Connector werden derzeit in dieser frühen Version nicht unterstützt. Data Science-Bibliotheken werden in PySpark-Umgebungen nicht unterstützt. PySpark funktioniert nur mit einem einfachen Conda-Setup, das PySpark allein ohne zusätzliche Bibliotheken umfasst.
Integrationen mit Umgebungselementen und Visual Studio Code werden in dieser frühen Version nicht unterstützt.
Das Lesen und Schreiben von Daten auf General Purpose v2 (GPv2) Azure Storage-Konten mit WASB- oder ABFS-Protokollen wird nicht unterstützt.
Hinweis
Teilen Sie Ihr Feedback zu Fabric Runtime in der Ideenplattform. Achten Sie darauf, dass Sie die Version und Veröffentlichungsphase erwähnen, auf die Sie verweisen. Wir schätzen Communityfeedback und priorisieren Verbesserungen basierend auf Abstimmungen, um sicherzustellen, dass wir die Benutzeranforderungen erfüllen.
Wichtigste Highlights
Apache Spark 4.0
Apache Spark 4.0 markiert einen bedeutenden Meilenstein als die erste Version der 4.x-Serie, die den kollektiven Aufwand der lebendigen Open-Source-Community verkörpern.
In dieser Version wird Spark SQL erheblich mit leistungsstarken neuen Features erweitert, die zur Steigerung der Ausdrucksfähigkeit und Vielseitigkeit für SQL-Workloads entwickelt wurden, z. B. unterstützung von VARIANT-Datentypen, SQL benutzerdefinierte Funktionen, Sitzungsvariablen, Pipesyntax und Zeichenfolgensortierung. PySpark zeigt kontinuierliche Bemühungen um sowohl die funktionale Vielseitigkeit als auch das gesamte Entwicklererlebnis, indem es eine native Plotting-API, eine neue Python-Datenquellen-API, Unterstützung für Python UDTFs sowie einheitliches Profiling für PySpark UDFs bietet, neben zahlreichen weiteren Verbesserungen. Strukturiertes Streaming entwickelt sich mit wichtigen Ergänzungen, die eine bessere Kontrolle und einfaches Debuggen bieten, insbesondere die Einführung der Willkürlichen Zustands-API v2 für eine flexiblere Zustandsverwaltung und die Zustandsdatenquelle zum einfacheren Debuggen.
Die vollständige Liste und detaillierte Änderungen finden Sie hier: https://spark.apache.org/releases/spark-release-4-0-0.html.
Hinweis
In Spark 4.0 ist SparkR veraltet und kann in einer zukünftigen Version entfernt werden.
Delta Lake 4.0
Delta Lake 4.0 ist ein kollektives Engagement, Delta Lake über Formate hinweg interoperabel zu machen, einfacher zu arbeiten und leistungsfähiger zu sein. Delta 4.0 ist eine Meilensteinversion, die mit leistungsstarken neuen Features, Leistungsoptimierungen und grundlegenden Verbesserungen für die Zukunft offener Datenseehäuser verpackt ist.
Sie können die vollständige Liste und detaillierte Änderungen, die mit Delta Lake 3.3 und 4.0 eingeführt wurden, hier überprüfen: https://github.com/delta-io/delta/releases/tag/v3.3.0. https://github.com/delta-io/delta/releases/tag/v4.0.0.
Von Bedeutung
Delta Lake 4.0-spezifische Features sind experimentell und funktionieren nur an Spark-Erfahrungen, z. B. Notebooks und Spark Job Definitions. Wenn Sie dieselben Delta Lake-Tabellen über mehrere Microsoft Fabric-Workloads hinweg verwenden müssen, aktivieren Sie diese Features nicht. Wenn Sie mehr darüber erfahren möchten, welche Protokollversionen und -features für alle Microsoft Fabric-Umgebungen kompatibel sind, lesen Sie die Interoperabilität des Delta Lake-Tabellenformats.
Verwandte Inhalte
- Apache Spark Runtimes in Fabric – Übersicht, Versionsverwaltung und Unterstützung für mehrere Runtimes
- Anleitung zur Migration von Spark Core
- Anleitung zur Migration von SQL, DataSets und DataFrame
- Anleitung zur Migration von strukturiertem Streaming
- Anleitung zur Migration von MLlib (Maschinelles Lernen)
- Anleitung zur Migration von PySpark (Python in Spark)
- Anleitung zur Migration von SparkR (R in Spark)