Anmerkung
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen, dich anzumelden oder die Verzeichnisse zu wechseln.
Der Zugriff auf diese Seite erfordert eine Genehmigung. Du kannst versuchen , die Verzeichnisse zu wechseln.
In diesem Artikel wird erläutert, wie Git-Integrations- und Bereitstellungspipelinen für gespiegelte Datenbanken in Microsoft Fabric funktionieren. Erfahren Sie, wie Sie eine Verbindung mit Ihrem Repository einrichten, Ihre gespiegelten Datenbanken über Git verwalten und in verschiedenen Umgebungen bereitstellen.
Git-Integration für gespiegelte Datenbanken
Über Ihre Arbeitsbereichseinstellungen können Sie ganz einfach eine Verbindung mit Ihrem Repository einrichten, um Änderungen zu übernehmen und zu synchronisieren. Informationen zum Einrichten der Verbindung finden Sie im Artikel "Erste Schritte mit Git-Integration" .
Nachdem Sie eine Verbindung hergestellt haben, zeigt der Arbeitsbereich Informationen zur Quellcodeverwaltung an, mit der Sie die verbundene Verzweigung, den Status der einzelnen Elemente in der Verzweigung und die Uhrzeit der letzten Synchronisierung anzeigen können.
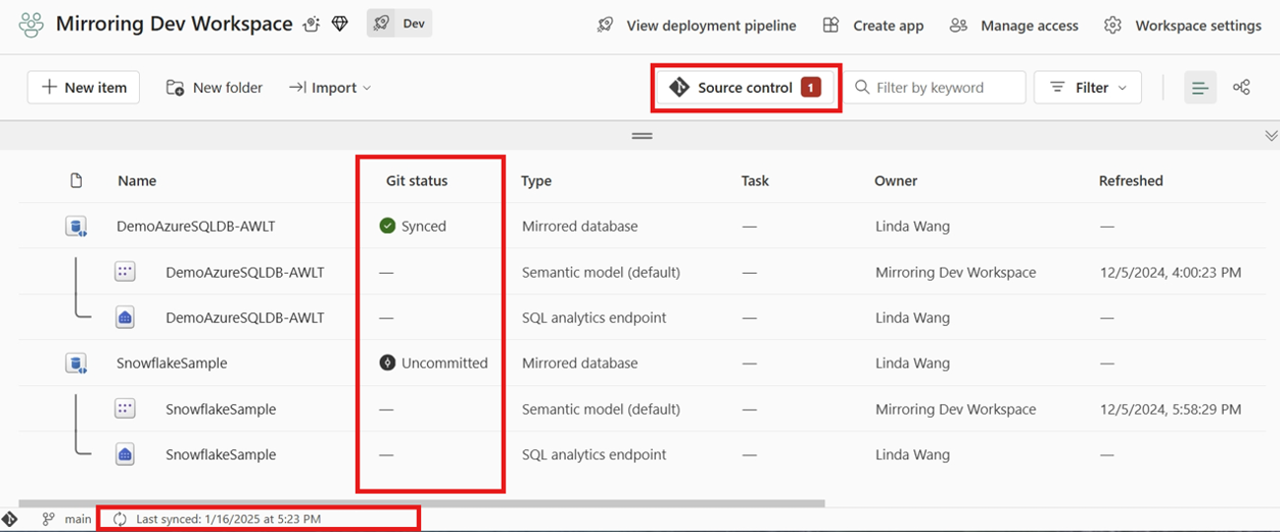
Sie können die gespiegelten Datenbankänderungen auf Git übernehmen oder den Arbeitsbereich von Git aktualisieren, indem Sie auf das Quellcodeverwaltungssteuerelement klicken.
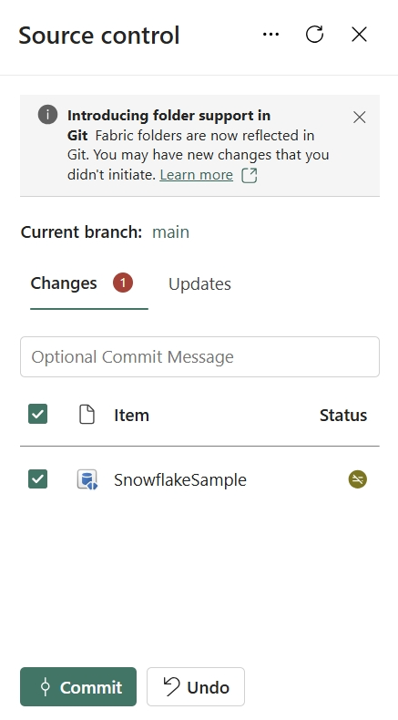
Spiegelung des Datenbankabbildes in Git
Wenn Sie das gespiegelte Datenbankelement in das Git-Repository übernehmen, wird für jedes Element ein Ordner erstellt und mit {display name}.MirroredDatabase benannt. Sie enthält zwei Dateien:
-
mirroring.jsonDatei, die die Definition der gespiegelten Datenbank ist. Weitere Informationen zur Definition von gespiegelten Datenbankelementen -
.platformdatei, die automatisch vom System generiert wird. Erfahren Sie mehr über die Systemdatei.
Hinweis
Nur das gespiegelte Datenbankelement wird in Git nachverfolgt. Der SQL-Analyseendpunkt, Ansichten und andere untergeordnete Elemente werden nicht nachverfolgt.
Gespiegelte Datenbank in Bereitstellungspipelines
Sie können die Fabric-Bereitstellungspipeline verwenden, um Ihre gespiegelte Datenbank in verschiedenen Umgebungen bereitzustellen, z. B. Entwicklung, Test und Produktion. Außerdem können Sie Bereitstellungsregeln verwenden, um die Quelldatenbanken so anzupassen, dass sie gespiegelt werden.
Führen Sie die folgenden Schritte aus, um Ihre gespiegelte Datenbank mithilfe der Bereitstellungspipeline bereitzustellen:
Erstellen Sie eine Bereitstellungspipeline, siehe Erste Schritte mit Bereitstellungspipelines.
Weisen Sie Arbeitsbereiche entsprechend Ihren Bereitstellungszielen verschiedenen Phasen zu.
Elemente auswählen, anzeigen und vergleichen, einschließlich gespiegelter Datenbank zwischen verschiedenen Stufen.
Wählen Sie "Bereitstellen" aus, um Ihre gespiegelte Datenbank über die Stufen hinweg bereitzustellen. Möglicherweise sehen Sie eine Warnung, dass das Element (SQL-Analyseendpunkt) nicht unterstützt wird – ignorieren Sie diese und fahren Sie fort.
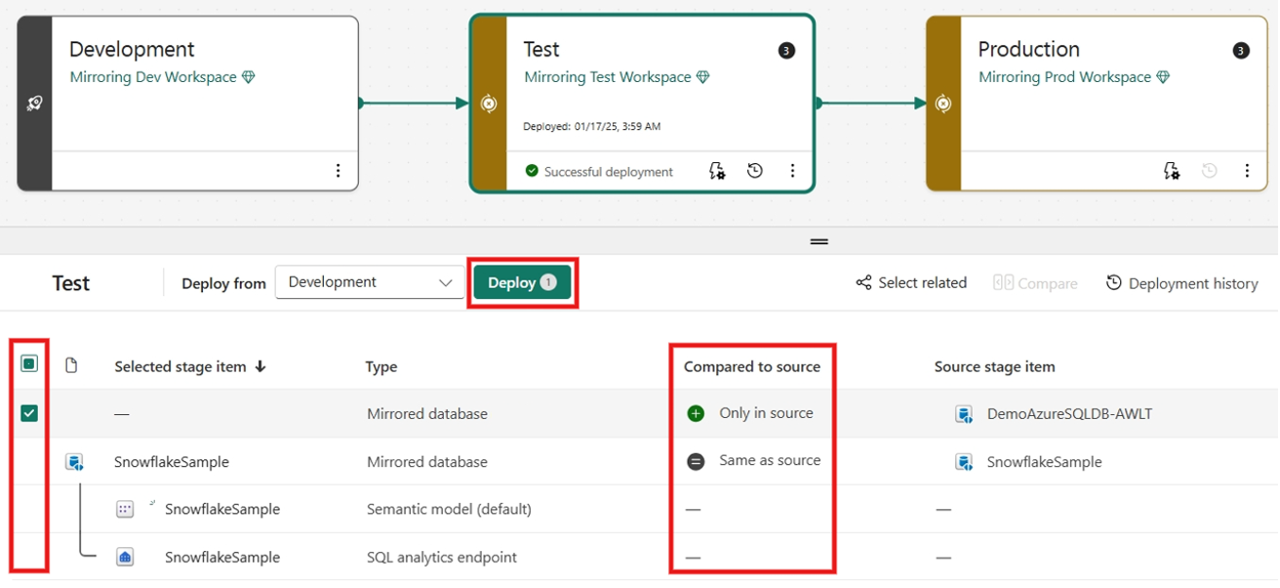
(Optional) Wenn Sie eine andere Quelldatenbank aus der vorherigen Phase spiegeln möchten, wählen Sie Bereitstellungsregeln aus, um Bereitstellungsregeln für einen Bereitstellungsprozess zu erstellen. Der Eintrag von Bereitstellungsregeln befindet sich in der Zielstufe für einen Bereitstellungsprozess.

Fabric unterstützt die Parametrisierung der Quelldatenbank für jedes gespiegelte Datenbankelement bei der Bereitstellung mit Bereitstellungsregeln. Wählen Sie die entsprechende gespiegelte Datenbank -> Datenquellenregeln -> + Regel hinzufügen, geben Sie die Zielverbindungs-ID ein und optional die Datenbank, falls zutreffend für den Quelldatenbanktyp. Die Verbindungs-ID finden Sie unter "Verbindungen und Gateways verwalten" –> suchen Sie die erstellte Verbindung aus der Liste - Einstellungen ->> Feld "Verbindungs-ID".
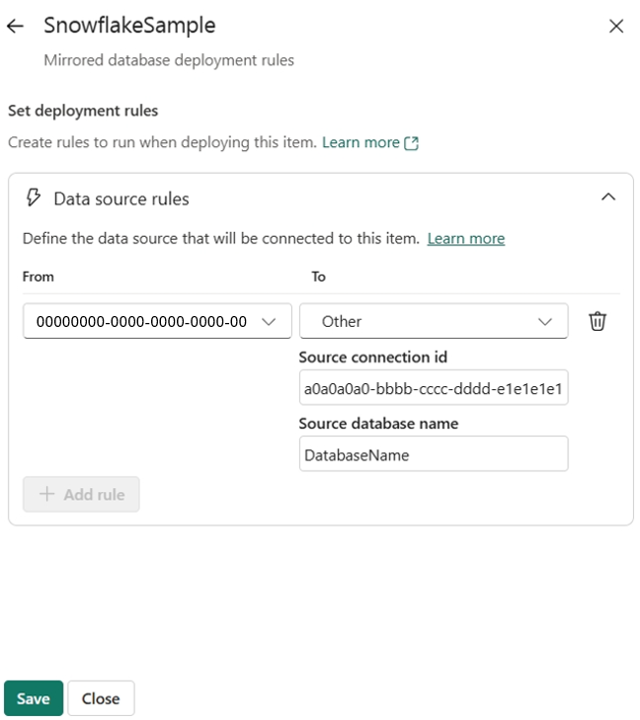
Nachdem Sie die Bereitstellungsregeln erstellt haben, stellen Sie die gespiegelten Datenbanken mit den neu erstellten Regeln aus der Quellstufe bis zur Zielstufe bereit, in der die Regeln erstellt wurden. Ihre Regeln werden erst wirksam, wenn Sie die gespiegelte Datenbank von der Quelle in die Zielumgebung bereitstellen.
Überwachen Sie den Bereitstellungsstatus über den Bereitstellungsverlauf.
Von Bedeutung
Die gespiegelte Datenbank wird nach der Bereitstellung nicht gestartet. Sie müssen sie manuell oder über DIE API starten.
Von Bedeutung
Um Daten aus Azure SQL-Datenbank, azure SQL Managed Instance, Azure Database for PostgreSQL oder SQL Server 2025 zu spiegeln, müssen Sie auch die folgenden Schritte ausführen, bevor Sie mit der Spiegelung beginnen:
- Aktivieren Sie die verwaltete Identität Ihres logischen Azure SQL-Servers, azure SQL Managed Instance, Azure Database for PostgreSQL oder SQL Server.
- Erteilen Sie der verwalteten Identität Lese- und Schreibberechtigung für die gespiegelte Datenbank. Derzeit müssen Sie dies im Fabric-Portal tun. Alternativ können Sie die verwaltete Identitäts-Arbeitsbereichrolle mit der API zur Hinzufügung von Arbeitsbereichsrollen gewähren.
Hinweis
Derzeit werden untergeordnete Elemente wie erstellte Ansichten nicht zwischen den Phasen bereitgestellt.