Ereignisse
Power BI DataViz Weltmeisterschaften
14. Feb., 16 Uhr - 31. März, 16 Uhr
Mit 4 Chancen, ein Konferenzpaket zu gewinnen und es zum LIVE Grand Finale in Las Vegas zu machen
Weitere InformationenDieser Browser wird nicht mehr unterstützt.
Führen Sie ein Upgrade auf Microsoft Edge aus, um die neuesten Funktionen, Sicherheitsupdates und technischen Support zu nutzen.
Inkrementelle Aktualisierung und Echtzeitdaten für semantische Modelle in Power BI bieten effiziente Möglichkeiten, dynamische Daten zu verarbeiten und die Leistung der Modellaktualisierung zu verbessern. Durch die Automatisierung der Partitionserstellung und -verwaltung reduziert die inkrementelle Aktualisierung die Datenmenge, die aktualisiert werden muss, und ermöglicht die Einbeziehung von Echtzeitdaten. In diesem Artikel wird erläutert, wie Sie inkrementelle Aktualisierungsfeatures in Power BI konfigurieren und verwenden, um sich schnell ändernde Daten zu erfassen und die Leistung zu verbessern.
Die inkrementelle Aktualisierung erweitert geplante Aktualisierungsvorgänge, indem sie die automatische Erstellung und Verwaltung von Partitionen für Semantikmodelltabellen ermöglicht, die häufig neue und aktualisierte Daten laden. Die meisten Semantikmodelle umfassen eine oder mehrere Tabellen mit Transaktionsdaten, die sich häufig ändern und exponentiell wachsen können, z. B. eine Faktentabelle in einem relationalen oder Sterndatenbankschema. Eine Richtlinie zur inkrementellen Aktualisierung, durch die eine solche Tabelle partitioniert und nur die neuesten Importpartitionen aktualisiert werden, sowie optional eine weitere DirectQuery-Partition für Echtzeitdaten können die Menge der zu aktualisierenden Daten erheblich reduzieren. Gleichzeitig stellt eine solche Richtlinie sicher, dass die neuesten Änderungen an der Datenquelle in den Abfrageergebnissen berücksichtigt werden.
Inkrementelle Aktualisierung und Echtzeitdaten bieten folgende Vorteile:
Wenn Sie ein Power BI Desktop-Modell im Dienst veröffentlichen, verfügt jede Tabelle im neuen Semantikmodell über eine einzelne Partition. Diese einzelne Partition enthält alle Zeilen für diese Tabelle. Wenn die Tabelle groß ist, z. B. Millionen oder mehr Zeilen enthält, kann eine Aktualisierung für diese Tabelle sehr lange dauern und sehr viele Ressourcen verbrauchen.
Bei der inkrementellen Aktualisierung teilt der Dienst Daten, die häufig aktualisiert werden müssen, dynamisch auf und trennt sie von Daten, die weniger häufig aktualisiert werden können. Tabellendaten werden unter Verwendung von Datums- und Uhrzeitparametern von Power Query, mit den reservierten Namen RangeStart und RangeEnd mit Berücksichtigung von Groß- und Kleinschreibung, gefiltert. Wenn Sie aber in Power BI Desktop die inkrementelle Aktualisierung konfigurieren, wird mithilfe der konfigurierten Parameter ein nur kleiner Datenzeitraum gefiltert, der in das Modell geladen wird. Wenn Power BI Desktop den Bericht im Power BI-Dienst veröffentlicht, erstellt der Dienst entsprechend den Einstellungen der Richtlinie für die inkrementelle Aktualisierung beim ersten Aktualisierungsvorgang Partitionen für die inkrementelle Aktualisierung und die Verlaufsdaten sowie optional eine DirectQuery-Echtzeitpartition. Danach überschreibt der Dienst die Parameterwerte, um die Daten für jede Partition auf Basis der Datums-/Zeitwerte jeder Zeile zu filtern und abzufragen.
Bei allen weiteren Aktualisierungen geben die Abfragefilter nur die Zeilen innerhalb des Aktualisierungszeitraums zurück, der dynamisch durch die Parameter definiert wird. Diese Zeilen mit einem Datum/einer Uhrzeit innerhalb des Aktualisierungszeitraums werden aktualisiert. Zeilen, deren Datum/Zeit nicht mehr innerhalb des Aktualisierungszeitraums liegen, werden dann Teil des Verlaufszeitraums, der nicht aktualisiert wird. Wenn in der Richtlinie für die inkrementelle Aktualisierung eine DirectQuery-Echtzeitpartition definiert ist, wird der zugehörige Filter ebenfalls aktualisiert, sodass auch alle Änderungen berücksichtigt werden, die nach dem Aktualisierungszeitraum aufgetreten sind. Sowohl für die Aktualisierungszeiträume als auch für die Verlaufszeiträume wird ein Rollforward ausgeführt. Bei der Erstellung neuer Partitionen für die inkrementelle Aktualisierung werden Aktualisierungspartitionen, die sich nicht mehr im Aktualisierungszeitraum befinden, zu Verlaufspartitionen. Im Laufe der Zeit werden Verlaufspartitionen weniger präzise, da sie zusammengeführt werden. Wenn sich eine Verlaufspartition nicht mehr im durch die Richtlinie definierten Verlaufszeitraum befindet, wird sie vollständig aus dem Semantikmodell entfernt. Dieser Mechanismus wird als Muster des rollierenden Zeitfensters bezeichnet.
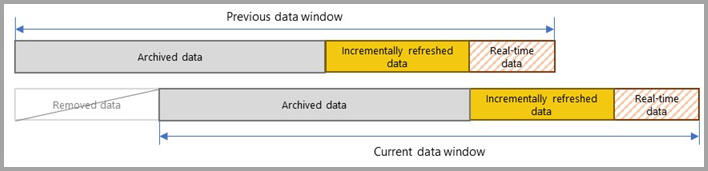
Der Vorteil der inkrementellen Aktualisierung ist, dass der Dienst diese Vorgänge basierend auf den von Ihnen festgelegten Richtlinien für die inkrementelle Aktualisierung automatisch für Sie durchführt. Tatsächlich sind der Prozess und die daraus erstellten Partitionen im Dienst nicht einmal sichtbar. In den meisten Fällen ist lediglich eine klar definierte Richtlinie für die inkrementelle Aktualisierung erforderlich, um die Leistung der Semantikmodellaktualisierung erheblich zu verbessern. Die DirectQuery-Echtzeitpartition wird jedoch nur für Semantikmodelle mit Premium-Kapazitäten unterstützt. Power BI Premium ermöglicht über den XMLA-Endpunkt (XML for Analysis) noch fortschrittlichere Partitions- und Aktualisierungsszenarien.
In den nächsten Abschnitten werden die unterstützten Pläne und Datenquellen beschrieben.
Die inkrementelle Aktualisierung wird für Modelle in Power BI Premium, Premium-Einzelbenutzerlizenz, Power BI Pro und Power BI Embedded unterstützt.
Das Abrufen der neuesten Daten in Echtzeit mit DirectQuery wird nur für Modelle von Power BI Premium, Premium-Einzelbenutzerlizenzen und Power BI Embedded unterstützt.
Die inkrementelle Aktualisierung und Echtzeitdaten funktionieren am besten bei strukturierten, relationalen Datenquellen wie SQL Database und Azure Synapse, können aber auch für andere Datenquellen verwendet werden. In jedem Fall muss Ihre Datenquelle Folgendes unterstützen:
Datumsfilterung: Die Datenquelle muss einen Mechanismus zum Filtern von Daten nach Datum unterstützen. Bei einer relationalen Quelle ist dies in der Regel in der Zieltabelle eine Datumsspalte mit dem Datentyp „Datum/Uhrzeit“ oder „Integer“. Die Parameter RangeStart und RangeEnd, die den Datentyp „Datum/Zeit“ haben müssen, filtern die Tabellendaten basierend auf der Datumsspalte. Für Datumsspalten mit Integer-Ersatzschlüsseln im Format yyyymmdd können Sie eine Funktion erstellen, die den Datums-/Uhrzeitwert in den Parametern „RangeStart“ und „RangeEnd“ so konvertiert, dass er dem Integer-Ersatzschlüssel der Datumsspalte entspricht. Weitere Informationen finden Sie unter Konfigurieren der inkrementellen Aktualisierung und von Echtzeitdaten – Konvertieren von DateTime in Integer.
Bei anderen Datenquellen müssen die Parameter „RangeStart“ und „RangeEnd“ so an die Datenquelle übergeben werden, dass ein Filtern möglich ist. Bei dateibasierten Datenquellen, deren Dateien und Ordner nach Datum organisiert sind, können die Parameter „RangeStart“ und „RangeEnd“ zum Filtern der Dateien und Ordner verwendet werden, um die zu ladenden Dateien auf diese Weise auszuwählen. Bei webbasierten Datenquellen können die Parameter „RangeStart“ und „RangeEnd“ mit der HTTP-Anforderung integriert werden. Beispielsweise kann die folgende Abfrage für die inkrementelle Aktualisierung der Ablaufverfolgungen einer AppInsights-Instanz verwendet werden:
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
Wenn die inkrementelle Aktualisierung konfiguriert ist, wird ein Power Query Ausdruck, der einen Datums-/Uhrzeitfilter basierend auf den Parametern „RangeStart“ und „RangeEnd“ enthält, für die Datenquelle ausgeführt. Wenn der Filter in einem Abfrageschritt nach der ersten Quellabfrage angegeben wird, muss das Query Folding den ersten Abfrageschritt mit den Schritten kombinieren, die auf die Parameter „RangeStart“ und „RangeEnd“ verweisen. Im folgenden Abfrageausdruck wird beispielsweise Table.SelectRows gefaltet, da damit unmittelbar auf den Schritt Sql.Database gefolgt wird und SQL Server das Folding unterstützt:
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
Die Unterstützung des Query Folding durch die finale Abfrage ist nicht erforderlich. Im folgenden Ausdruck wird beispielsweise eine nicht faltbare NativeQuery verwendet, wobei die Parameter „RangeStart“ und „RangeEnd“ direkt mit SQL integriert sind:
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
Wenn die Richtlinie für die inkrementelle Aktualisierung jedoch das Abrufen von Echtzeitdaten mit DirectQuery beinhaltet, können keine Transformationen ohne Faltung verwendet werden. Wenn es sich um eine reine Importmodusrichtlinie ohne Echtzeitdaten handelt, kann die Abfragemashup-Engine dies ggf. ausgleichen und den Filter lokal anwenden. Hierzu müssen allerdings alle Zeilen der Tabelle aus der Datenquelle abgerufen werden. Dies kann dazu führen, dass die inkrementelle Aktualisierung langsam ist und dem Prozess entweder im Power BI-Dienst oder in einem lokalen Datengateway die Ressourcen nicht ausreichen – wodurch der Zweck der inkrementellen Aktualisierung nicht erfüllt ist.
Da die Unterstützung für die Abfragefaltung bei den verschiedenen gängigen Datenquellen nicht identisch gehandhabt wird, sollte überprüft werden, ob die Filterlogik in den Abfragen, die an der Datenquelle ausgeführt werden, enthalten ist. In den meisten Fällen versucht Power BI Desktop, diese Überprüfung für Sie durchzuführen, wenn Sie die Richtlinie für inkrementelle Aktualisierung definieren. Bei SQL-basierten Datenquellen wie SQL Database, Azure Synapse, Oracle und Teradata ist diese Überprüfung zuverlässig. Andere Datenquellen können jedoch möglicherweise nicht verifiziert werden, ohne die Abfragen nachzuverfolgen. Wenn Power BI Desktop die Abfragen nicht bestätigen kann, wird im Konfigurationsdialogfeld der Richtlinie für die inkrementelle Aktualisierung eine Warnung angezeigt.
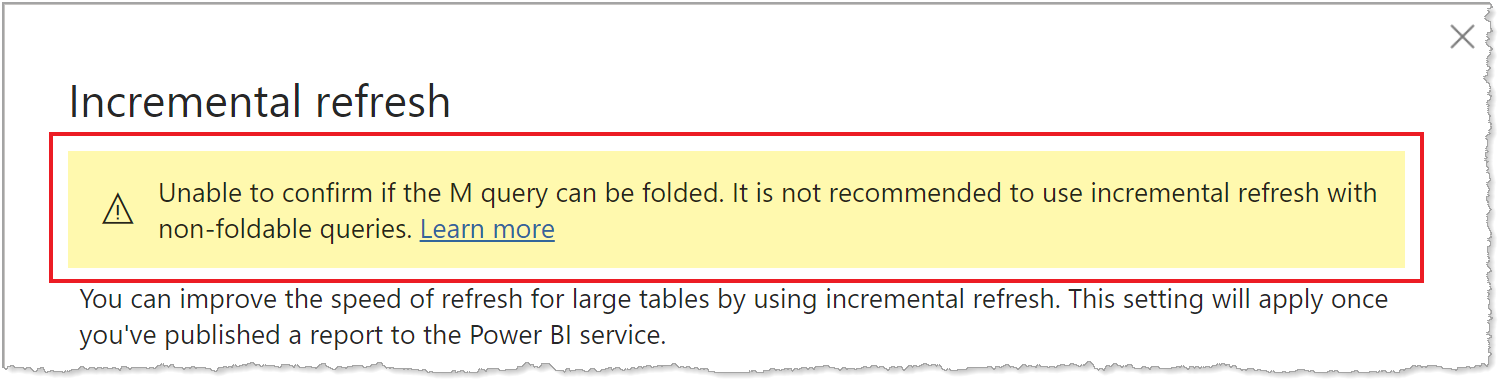
Wenn diese Warnung angezeigt wird, können Sie mit der Diagnosefunktion von Power Query überprüfen, ob die erforderliche Abfragefaltung erfolgt, oder die Abfragen mit einem anderen, von der Datenquelle unterstützten Tool verfolgen (z. B. mit SQL Profiler). Wenn keine Abfragefaltung stattfindet, überprüfen Sie, ob die an die Datenquelle übergebene Abfrage die Filterlogik enthält. Wenn dies nicht der Fehler ist, enthält die Abfrage wahrscheinlich eine Transformation, die ein Folding verhindert.
Bevor Sie Ihre Lösung für die inkrementelle Aktualisierung konfigurieren, sollten Sie die Query Folding-Anleitungen für Power BI Desktop und Query Folding in Power Query gründlich lesen und verstehen. Wenn Sie überprüfen möchten, ob Ihre Datenquelle und Ihre Abfragen die Abfragefaltung unterstützen, sind auch die folgenden Artikel sehr hilfreich.
Wenn Sie die inkrementelle Aktualisierung und Echtzeitdaten mit Power BI Desktop konfigurieren bzw. mit Tabular Model Scripting Language (TMSL) oder Tabular Object Model (TOM) über den XMLA-Endpunkt eine erweiterte Lösung konfigurieren, müssen alle Partitionen – ob Import oder DirectQuery – Daten aus einer einzigen Quelle abfragen.
Bei individuelleren Abfragefunktionen und Abfragelogik kann die inkrementelle Aktualisierung auch mit anderen Datenquellen verwendet werden, wenn die auf RangeStart und RangeEnd basierenden Filter in einer einzigen Abfrage übergeben werden können. Dies ist beispielsweise bei Datenquellen wie in einem Ordner gespeicherten Excel-Arbeitsmappendateien, Dateien in SharePoint und RSS-Feeds der Fall. Dies sind jedoch erweiterte Szenarien, für die weitere Anpassungen und Tests über das hier Beschriebene hinaus erforderlich sind. Wir empfehlen Ihnen sehr, sich in der weiter unten in diesem Artikel genannten Community Informationen zur inkrementellen Aktualisierung in außergewöhnlichen Szenarien zu holen.
Unabhängig von der inkrementellen Aktualisierung gilt für Power BI Pro-Modelle ein Aktualisierungszeitlimit von zwei Stunden, und das Abrufen von Echtzeitdaten mit DirectQuery wird diesen Modellen nicht unterstützt. Für Semantikmodelle in einer Premium-Kapazität beträgt das Zeitlimit fünf Stunden. Aktualisierungsvorgänge sind verarbeitungs- und arbeitsspeicherintensiv. Ein vollständiger Aktualisierungsvorgang kann bis zu doppelt so viel Speicher wie das Semantikmodell selbst benötigen, da der Dienst eine Momentaufnahme des Semantikmodells im Speicher behält, bis der Aktualisierungsvorgang abgeschlossen ist. Aktualisierungsvorgänge können auch verarbeitungsintensiv sein und einen erheblichen Teil der verfügbaren CPU-Ressourcen verbrauchen. Aktualisierungsvorgänge müssen sich auch auf flüchtige Verbindungen zu Datenquellen und die Fähigkeit dieser Datenquellensysteme verlassen, Abfrageausgaben schnell zurückzugeben. Das Zeitlimit ist eine Schutzmaßnahme, um die Überbeanspruchung Ihrer verfügbaren Ressourcen zu begrenzen.
Hinweis
Bei Premium-Kapazitäten gilt für Aktualisierungsvorgänge, die über den XMLA-Endpunkt ausgeführt werden, kein Zeitlimit. Weitere Informationen finden Sie unter Erweiterte inkrementelle Aktualisierung mit dem XMLA-Endpunkt.
Da die inkrementelle Aktualisierung die Aktualisierungsvorgänge auf Partitionsebene im Semantikmodell optimiert, kann der Ressourcenverbrauch erheblich reduziert werden. Gleichzeitig sind Aktualisierungsvorgänge auch bei der inkrementellen Aktualisierung, sofern sie nicht über den XMLA-Endpunkt erfolgen, an dieselben Zeitlimits von zwei bzw. fünf Stunden gebunden. Eine effektive Richtlinie für inkrementelle Aktualisierung reduziert nicht nur die Datenmenge, die bei einem Aktualisierungsvorgang verarbeitet wird, sondern verringert auch die Menge unnötiger Verlaufsdaten, die in Ihrem Semantikmodell gespeichert werden.
Abfragen können auch durch ein standardmäßiges Zeitlimit für die Datenquelle eingeschränkt werden. Bei den meisten relationalen Datenquellen können Zeitlimits im Power Query M-Ausdruck überschrieben werden. Beispielsweise wird im folgenden Ausdruck die SQL Server-Datenzugriffsfunktion verwendet, um „CommandTimeout“ auf zwei Stunden festzulegen. Jeder durch die Richtlinienbereiche definierte Zeitraum sendet eine Abfrage unter Einhaltung der Einstellung für die Befehlszeitüberschreitung:
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
Bei sehr großen Semantikmodellen mit Premium-Kapazitäten, die möglicherweise Milliarden von Zeilen enthalten, kann der anfängliche Aktualisierungsvorgang per Bootstrapping durchgeführt werden. Durch Bootstrapping kann der Dienst Tabellen- und Partitionsobjekte für das Semantikmodell erstellen, aber keine Daten in eine der Partitionen laden und dort verarbeiten. In SQL Server Management Studio können Sie Partitionen so konfigurieren, dass sie einzeln, sequenziell oder parallel verarbeitet werden, wodurch sowohl die in einer einzelnen Abfrage zurückgegebene Datenmenge reduziert als auch das Zeitlimit von fünf Stunden umgangen werden kann. Weitere Informationen finden Sie unter Erweiterte inkrementelle Aktualisierung – Verhindern von Timeouts bei der ersten vollständigen Aktualisierung.
Standardmäßig wird das aktuelle Datum und die aktuelle Uhrzeit basierend auf der koordinierten Weltzeit (UTC) zum Zeitpunkt der Aktualisierung bestimmt. Bei bedarfsgesteuerten und geplanten Aktualisierungen können Sie unter „Aktualisieren“ eine andere Zeitzone konfigurieren, die beim Bestimmen des aktuellen Datums und der aktuellen Uhrzeit berücksichtigt wird. Wenn beispielsweise um 20:00 Uhr in der Zeitzone „Pacific Time“ (USA und Kanada) eine Aktualisierung durchgeführt wird und eine Zeitzone angegeben ist, werden das aktuelle Datum und die Uhrzeit in Pacific Time ermittelt und nicht anhand der koordinierten Weltzeit (UTC), was in diesem Fall der nächste Tag wäre.
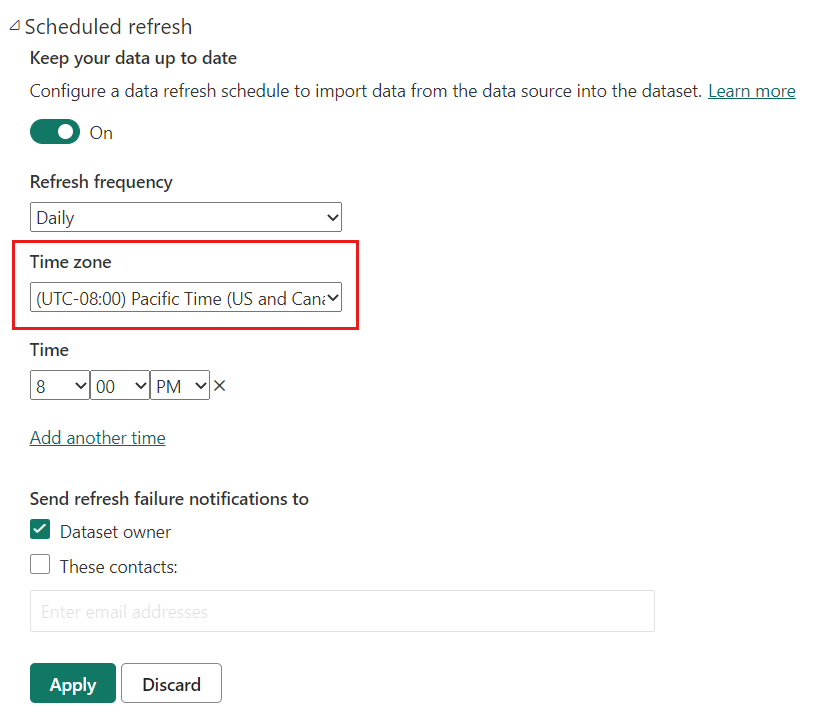
Aktualisierungsvorgänge, die nicht über den Power BI-Dienst aufgerufen werden, wie z. B. der XMLA TMSL-Aktualisierungsbefehl oder die API für erweiterte Aktualisierungen, berücksichtigen die Zeitzone für die geplante Aktualisierung nicht und nutzen standardmäßig die UTC.
In diesem Abschnitt werden wichtige Konzepte der Konfiguration von inkrementellen Aktualisierungen und Echtzeitdaten beschrieben. Eine ausführlichere Schritt-für-Schritt-Anleitung finden Sie unter Konfigurieren von inkrementeller Aktualisierung und Echtzeitdaten.
Das Konfigurieren der inkrementellen Aktualisierung erfolgt in Power BI Desktop. Für die meisten Modelle sind nur wenige Aufgaben erforderlich. Allerdings sollten Sie folgende Punkte beachten:
Zur Konfiguration der inkrementellen Aktualisierung in Power BI Desktop erstellen Sie zunächst im Power Query-Editor im Dialogfeld „Parameter verwalten“ zwei Date/Time-Parameter mit den reservierten Namen RangeStart und RangeEnd (die Groß-/Kleinschreibung muss beachtet werden). Anhand dieser Parameter werden die Daten zunächst gefiltert, so dass nur diejenigen Zeilen in die Power BI Desktop-Modelltabelle geladen werden, die mit dem angegebenen Zeitraum übereinstimmen. RangeStart stellt das älteste oder früheste Datum bzw. die älteste bzw. früheste Uhrzeit dar, und RangeEnd stellt das neueste Datum bzw. die neueste Uhrzeit dar. Nach der Veröffentlichung des Modells im Dienst werden RangeStart und RangeEnd automatisch vom Dienst durch die Einstellungen der Richtlinie für die inkrementelle Aktualisierung überschrieben, damit nur die Daten abgefragt werden, die mit dem Aktualisierungszeitraum der Richtlinie übereinstimmen.
Die Datenquellentabelle „FactInternetSales“ erfasst beispielsweise täglich etwa 10.000 neue Zeilen. Um die Anzahl der anfänglich in das Modell geladenen Zeilen in Power BI Desktop zu begrenzen, empfiehlt es sich, den Zeitraum mit RangeStart und RangeEnd auf zwei Tage festzulegen.
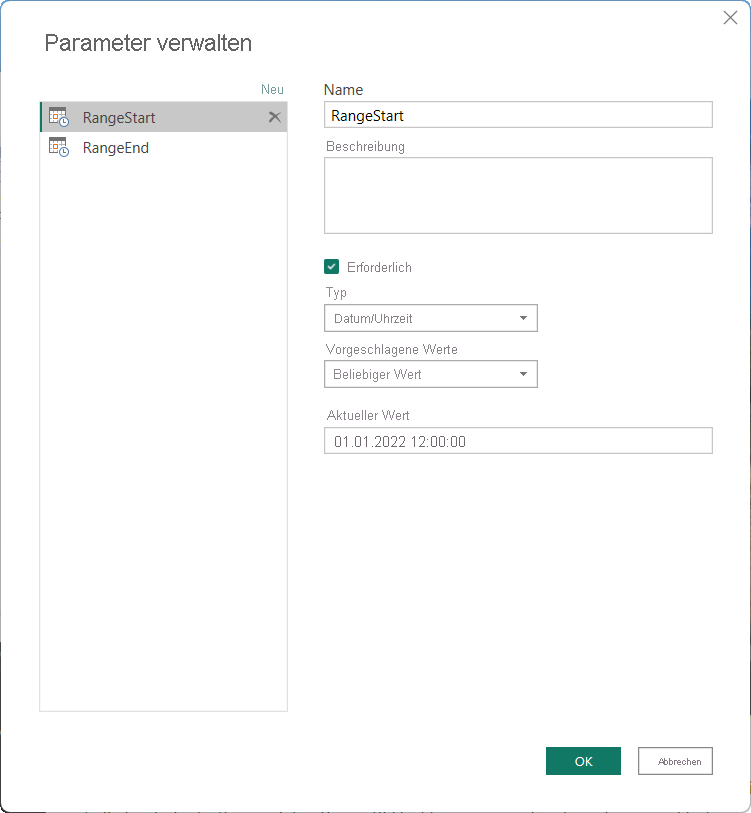
Nachdem die Parameter RangeStart und RangeEnd definiert sind, wenden Sie auf die Datumsspalte Ihrer Tabelle benutzerdefinierte Datumsfilter an. Die angewendeten Filter wählen eine Teilmenge der Daten aus, die nun mit der Schaltfläche Anwenden in das Modell geladen werden.
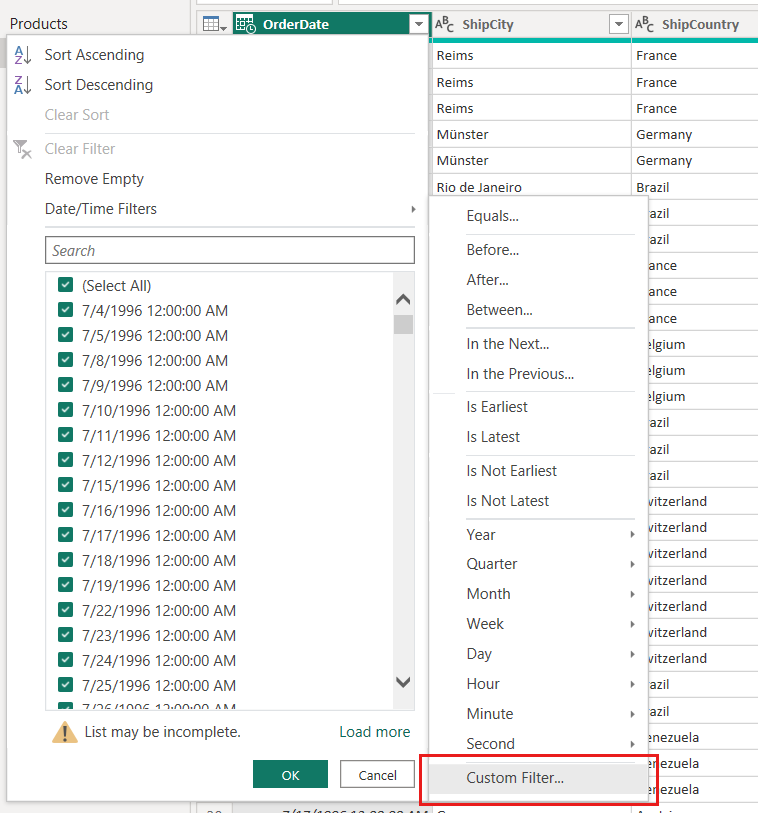
In unserem FactInternetSales-Beispiel werden nach der parameterbasierten Filtererstellung und dem Anwenden von Schritten das Datenvolumen von zwei Tagen (etwa 20.000 Zeilen) in das Modell geladen.
Nach der Anwendung der Filter und dem Laden einer Teilmenge der Daten in das Modell definieren Sie eine inkrementelle Aktualisierungsrichtlinie für die Tabelle. Nachdem das Modell im Dienst veröffentlicht wurde, wird die Richtlinie vom Dienst verwendet, um Tabellenpartitionen zu erstellen und zu verwalten und Aktualisierungsvorgänge auszuführen. Zur Definition der Richtlinie geben Sie im Dialogfeld Inkrementelle Aktualisierung und Echtzeitdaten sowohl die erforderlichen als auch optionale Einstellungen an.

Im Listenfeld Tabelle auswählen ist standardmäßig die in der Datenansicht ausgewählte Tabelle angegeben. Aktivieren Sie die inkrementelle Aktualisierung für die Tabelle mit dem Schieberegler. Wenn der Power Query-Ausdruck für die Tabelle keinen auf den Parametern RangeStart und RangeEnd basierenden Filter enthält, ist der Umschalter nicht verfügbar.
Die Einstellung Daten archivieren beginnend X vor dem Aktualisierungsdatum bestimmt den Verlaufszeitraum, in dem Zeilen mit einem Datum/einer Uhrzeit in diesem Zeitabschnitt in das Modell aufgenommen werden, plus Zeilen für den aktuellen unvollständigen Verlaufszeitraum sowie Zeilen im Aktualisierungszeitraum bis zum aktuellen Datum und zur aktuellen Uhrzeit.
Wenn Sie beispielsweise fünf Jahre angeben, speichert die Tabelle die Verlaufsdaten der letzten fünf Jahre in Jahrespartitionen. Außerdem enthält die Tabelle Zeilen für das aktuelle Jahr in Quartals-, Monats- oder Tagespartitionen bis zum und einschließlich dem Aktualisierungszeitraum.
Für Modelle in Premium-Kapazitäten können Verlaufspartitionen rückwirkend selektiv mit einer von dieser Einstellung festgelegten Granularität aktualisiert werden. Weitere Informationen finden Sie unter Erweiterte inkrementelle Aktualisierung – Partitionen.
Die Einstellung Daten werden inkrementell aktualisiert, beginnend vor dem Aktualisierungsdatum bestimmt den inkrementellen Aktualisierungszeitraum. Alle Zeilen, deren Datum/Uhrzeit mit diesem Zeitraum übereinstimmen, werden in die Aktualisierungspartitionen aufgenommen und bei jedem Aktualisierungsvorgang aktualisiert.
Geben Sie beispielsweise einen Aktualisierungszeitraum von drei Tagen an, so überschreibt der Dienst bei jedem Aktualisierungsvorgang die Parameter RangeStart und RangeEnd und erstellt so jeweils eine aktuelle Abfrage nach allen Zeilen, deren Datum/Uhrzeit innerhalb der letzten drei Tage liegen – denn Beginn und Ende des Zeitraums werden bei jeder Aktualisierung an das aktuelle Datum und die aktuelle Uhrzeit angepasst. Zeilen, deren Datum/Uhrzeit innerhalb der letzten drei Tage bis zum Zeitpunkt des aktuellen Aktualisierungsvorgangs liegen, werden aktualisiert. Bei dieser Richtlinie ist davon auszugehen, dass der Dienst für die Modelltabelle „FactInternetSales“ mit ihren durchschnittlich 10.000 neuen Zeilen pro Tag bei jedem Aktualisierungsvorgang ungefähr 30.000 Zeilen aktualisiert.
Achten Sie bei der Angabe des Zeitraums darauf, dass Ihr Zeitraum nur die Mindestanzahl von Zeilen enthält, die für eine genaue Berichterstellung erforderlich sind. Wenn Sie Richtlinien für mehrere Tabellen definieren, müssen Sie die gleichen RangeStart- und RangeEnd-Parameter verwenden, selbst wenn für die einzelnen Tabellen unterschiedliche Speicher- und Aktualisierungszeiträume definiert sind.
Die Einstellung Abrufen der neuesten Daten in Echtzeit mit DirectQuery (nur Premium) ermöglicht das Abrufen der neuesten Änderungen aus der aktuellen Tabelle in der Datenquelle über den Zeitraum der inkrementellen Aktualisierung hinaus mithilfe von DirectQuery. Alle Zeilen, deren Datum/Uhrzeit nach dem inkrementellen Aktualisierungszeitraum liegt, werden in eine DirectQuery-Partition aufgenommen und mit jeder Modellabfrage aus der Datenquelle abgerufen.
Wenn diese Einstellung aktiviert ist, überschreibt der Dienst auch in diesem Fall bei jedem Aktualisierungsvorgang die Parameter RangeStart und RangeEnd und erstellt so jeweils eine aktuelle Abfrage nach Zeilen, deren Datum/Uhrzeit innerhalb des Aktualisierungszeitraums liegen – auch hier sind Beginn und Ende des Zeitraums vom aktuellen Datum und der aktuellen Uhrzeit abhängig. In die Aktualisierung eingeschlossen sind auch alle Zeilen, deren Datum/Uhrzeit nach dem aktuellen Aktualisierungszeitpunkt liegen. Mit diesem Typ von Richtlinie enthält die Modelltabelle „FactInternetSales“ im Dienst stets die neuesten Datenaktualisierungen.
Die Option Nur vollständige Tage aktualisieren stellt sicher, dass alle Zeilen eines Tags vollständig in den Aktualisierungsvorgang eingeschlossen werden. Diese Einstellung ist optional, sofern nicht die Einstellung Abrufen der neuesten Daten in Echtzeit mit DirectQuery (nur Premium) aktiviert ist. Nehmen wir beispielsweise an, Ihre Aktualisierung ist für 4:00 Uhr morgens geplant. Neue Datenzeilen, die innerhalb der vier Stunden zwischen Mitternacht und 4:00 Uhr morgens in der Datenquellentabelle erscheinen, müssen vermutlich nicht berücksichtigt werden. Bei einigen Geschäftsmetriken, z. B. Barrel pro Tag in der Öl- und Gasindustrie, ist eine Verwendung von Tagesteilen nicht sinnvoll. Oder nehmen wir ein weiteres Beispiel, in dem die Daten eines Finanzsystems aktualisiert bzw. die Daten des Vormonats jeweils am zwölften Kalendertag des Monats freigegeben werden sollen. Sie könnten in diesem Fall den Aktualisierungszeitraum auf einen Monat und die Aktualisierung für den zwölften Tag des Monats festlegen. Wenn diese Option aktiviert ist, werden z. B. die Daten vom Januar am 12. Februar aktualisiert.
Berücksichtigen Sie in diesem Szenario, dass Aktualisierungsvorgänge im Dienst unter UTC-Zeit ausgeführt werden, sofern die geplante Aktualisierung nicht für eine Nicht-UTC-Zeitzone konfiguriert ist. Dies kann das effektive Datum bestimmen und sich auf abgeschlossene Zeiträume auswirken.
Die Einstellung Datenänderungen erkennen ermöglicht eine noch gezieltere Aktualisierung. Sie können eine Datums-/Uhrzeitspalte auswählen, um nur die Tage zu ermitteln und zu aktualisieren, an denen sich die Daten geändert haben. Dieses Szenario setzt voraus, dass eine solche Spalte in der Datenquelle vorhanden ist – was normalerweise zu Prüfzwecken der Fall ist. Es sollte sich hierbei nicht um die gleiche Spalte handeln, die zum Partitionieren der Daten mit den Parametern RangeStart und RangeEnd verwendet wird. Der Maximalwert dieser Spalte wird für jeden der Zeiträume im Inkrementbereich ausgewertet. Wenn sich die Spalte seit der letzten Aktualisierung nicht geändert hat, besteht kein Grund, den Zeitraum zu aktualisieren. Dadurch können sich die Tage, die inkrementell aktualisiert werden müssen, von drei auf einen Tag reduzieren.
Das aktuelle Design erfordert, dass die Spalte zur Erkennung von Datenänderungen beibehalten und im Arbeitsspeicher zwischengespeichert wird. Zum Reduzieren der Kardinalität und des Arbeitsspeicherverbrauchs können die folgenden Techniken verwendet werden:
In einigen Fällen kann die Aktivierung der Option Datenänderungen erkennen weiter verbessert werden. Möglicherweise empfiehlt sich beispielsweise, das Beibehalten der Spalte „Letzte Aktualisierung“ im In-Memory-Cache zu vermeiden oder Szenarien zu ermöglichen, in denen eine Konfigurations-/Anweisungstabelle durch ETL-Prozesse (Extract-Transform-Load) so vorbereitet wird, dass die zu aktualisierenden Partitionen markiert werden. Bei Premium-Kapazitäten können Sie in solchen Fällen das Verhalten der Einstellung „Datenänderungen erkennen“ mit TMSL und/oder TOM überschreiben. Weitere Informationen finden Sie unter Erweiterte inkrementelle Aktualisierung – Benutzerdefinierte Abfragen zum Erkennen von Datenänderungen.
Nachdem Sie die Richtlinie für die inkrementelle Aktualisierung konfiguriert haben, veröffentlichen Sie das Modell im Dienst. Sobald die Veröffentlichung abgeschlossen ist, können Sie den ersten Aktualisierungsvorgang für das Modell ausführen.
Hinweis
Semantikmodell, die über eine Richtlinie für die inkrementelle Aktualisierung verfügen, um mit DirectQuery die neuesten Daten in Echtzeit abzurufen, können nur in einem Premium-Arbeitsbereich veröffentlicht werden.
Wenn davon auszugehen ist, dass ein Modell, das in einem Arbeitsbereich mit Premium-Kapazitäten veröffentlicht wird, auf mehr als 1 GB anwächst, können Sie die Leistung des Aktualisierungsvorgangs verbessern und sicherstellen, dass das Modell die Größenbeschränkungen nicht überschreitet, indem Sie vor Ausführung des ersten Aktualisierungsvorgangs im Dienst das Speicherformat für große semantische Modelle aktivieren. Weitere Informationen finden Sie unter Große Modelle in Power BI Premium.
Wichtig
Nachdem Power BI Desktop das Modell im Dienst veröffentlicht hat, können Sie diese .pbix-Datei nicht mehr zurückladen.
Nach der Veröffentlichung im Dienst führen Sie einen ersten Aktualisierungsvorgang für das Modell aus. Diese Aktualisierung sollte individuell (manuell) erfolgen, damit Sie den Fortschritt überwachen können. Der erste Aktualisierungsvorgang kann einige Zeit in Anspruch nehmen. Partitionen müssen erstellt, Verlaufsdaten geladen, Objekte wie Beziehungen und Hierarchien erstellt bzw. angepasst und berechnete Objekte neu berechnet werden.
Nachfolgende einzelne oder geplante Aktualisierungsvorgänge erfolgen danach wesentlich schneller, da nur die Partitionen der inkrementellen Aktualisierung aktualisiert werden müssen. Andere Verarbeitungsvorgänge, wie das Zusammenführen von Partitionen und die Neuberechnung, müssen zwar immer noch durchgeführt werden, benötigen im Vergleich zur ersten Aktualisierung jedoch wesentlich weniger Zeit.
Für Berichte, die ein Modell mit einer Richtlinie für die inkrementelle Aktualisierung verwenden, um die neuesten Daten in Echtzeit mit DirectQuery abzurufen, empfiehlt es sich, die automatische Seitenaktualisierung in einem festen Intervall oder auf Grundlage der Änderungserkennung zu aktivieren, damit in den Berichten die neuesten Daten ohne Verzögerung dargestellt werden. Weitere Informationen dazu finden Sie unter Automatische Seitenaktualisierung in Power BI.
Wenn Ihr Modell einer Premium-Kapazität mit aktiviertem XMLA-Endpunkt zugewiesen ist, kann die inkrementelle Aktualisierung für erweiterte Szenarien nochmals optimiert werden. Beispielsweise können Sie SQL Server Management Studio verwenden, um Partitionen anzuzeigen und zu verwalten, den anfänglichen Aktualisierungsvorgang per Bootstrap zu starten oder Verlaufspartitionen rückwirkend zu aktualisieren. Weitere Informationen finden Sie unter Erweiterte inkrementelle Aktualisierung mit dem XMLA-Endpunkt.
Power BI wird von einer dynamischen Community unterstützt, in der MVPs, BI-Experten und Peers Fachwissen in Diskussionsgruppen, Videos, Blogs und mehr teilen. Ausführliche Informationen zur inkrementellen Aktualisierung finden Sie auch in den folgenden Ressourcen:
Ereignisse
Power BI DataViz Weltmeisterschaften
14. Feb., 16 Uhr - 31. März, 16 Uhr
Mit 4 Chancen, ein Konferenzpaket zu gewinnen und es zum LIVE Grand Finale in Las Vegas zu machen
Weitere InformationenSchulung
Lernpfad
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization
Zertifizierung
Microsoft Certified: Power BI Data Analyst Associate - Certifications
Erfahren Sie mehr über die Methoden und Best Practices, die den geschäftlichen und technischen Anforderungen für die Modellierung, Visualisierung und Analyse von Daten mit Microsoft Power BI entsprechen.
Dokumentation
Hier erfahren Sie, wie Sie inkrementelle Aktualisierung für Power BI-Semantikmodelle und Echtzeitdaten konfigurieren.
Behandeln von Problemen bei der inkrementellen Aktualisierung und bei Echtzeitdaten - Power BI
Informationen über gängige Problembehandlungsszenarien für die inkrementelle Aktualisierung, die in Konfigurations- und Aktualisierungsvorgänge unterteilt sind.
Informationen zu erweiterten Features bezüglich inkrementeller Aktualisierung und Echtzeitdaten mit dem XMLA-Endpunkt in Power BI.