Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Datenflüsse werden für Power BI Pro, Power BI Premium pro Nutzer (PPU) und Power BI Premium-Nutzer unterstützt. Einige Features sind nur mit einem Power BI Premium-Abonnement verfügbar (d. h. einer Premium-Kapazität oder PPU-Lizenz). In diesem Artikel werden nur die PPU- und Premium-Features und deren Verwendungszwecke beschrieben.
Die folgenden Features sind nur bei Power BI Premium (PPU-Abonnement oder Abonnement mit Premium-Kapazität) verfügbar:
- erweiterte Compute-Engine
- DirectQuery
- berechnete Entitäten
- verknüpfte Entitäten
- Inkrementelle Aktualisierung
In den folgenden Abschnitten werden diese Features ausführlich beschrieben.
Wichtig
Dieser Artikel bezieht sich auf die erste Generation von Datenflüssen (Gen1) und gilt nicht für die zweite Generation (Gen2) von Datenflüssen, die in Microsoft Fabric verfügbar sind. Weitere Informationen finden Sie unter Upgrade von Dataflow Gen1 auf Dataflow Gen2.
Erweiterte Compute-Engine
Die verbesserte Compute-Engine in Power BI ermöglicht Power BI Premium-Abonnenten, ihre Kapazität zum Optimieren der Verwendung von Dataflows zu nutzen. Die Verwendung der erweiterten Compute-Engine bietet folgende Vorteile:
- Reduziert drastisch die Aktualisierungszeit, die für ETL-Schritte (extrahieren, transformieren, laden) mit langer Ausführungszeit über berechnete Entitäten benötigt wird, z. B. die Durchführung von joins, distinct, filters und group by.
- Führt DirectQuery-Abfragen über Entitäten durch.
Hinweis
- Die Validierungs- und Aktualisierungsprozesse informieren die Datenflüsse des Modellschemas. Wenn Sie das Schema der Tabellen selbst festlegen möchten, verwenden Sie den Power Query-Editor, und legen Sie Datentyp fest.
- Dieses Feature ist für alle Power BI-Cluster mit Ausnahme von WABI-INDIA-CENTRAL-A-PRIMARY verfügbar.
Aktivieren der erweiterten Compute-Engine
Wichtig
Die erweiterte Compute-Engine funktioniert nur für A3- und höhere Power BI-Kapazitäten.
In Power BI Premium wird die erweiterte Compute-Engine einzeln für jeden Dataflow festgelegt. Es stehen drei Konfigurationen zur Auswahl:
Deaktiviert
Optimiert (Standard): Die erweiterte Compute-Engine ist deaktiviert. Es wird automatisch aktiviert, wenn eine Tabelle im Dataflow von einer anderen Tabelle referenziert wird oder wenn der Dataflow mit einem anderen Dataflow im selben Arbeitsbereich verbunden ist.
An
Um die Standardeinstellung zu ändern und die erweiterte Compute Engine zu aktivieren, gehen Sie wie folgt vor:
Wählen Sie in Ihrem Arbeitsbereich neben dem Dataflow, für den Sie die Einstellungen ändern möchten, Weitere Optionen aus.
Wählen Sie im Menü Weitere Optionen des Dataflows Einstellungen aus.
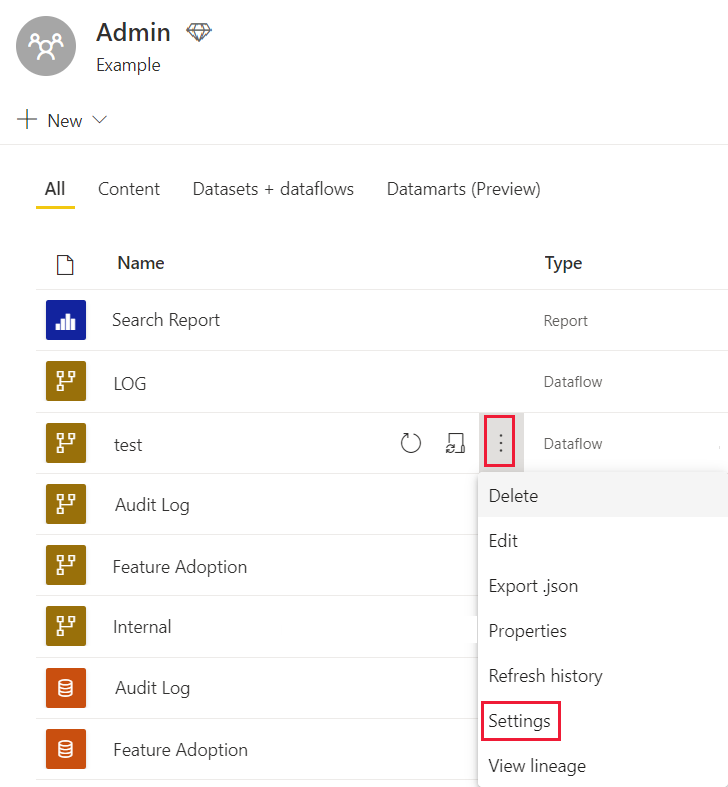
Klappen Sie Erweiterte Einstellungen der Compute-Engine auf.
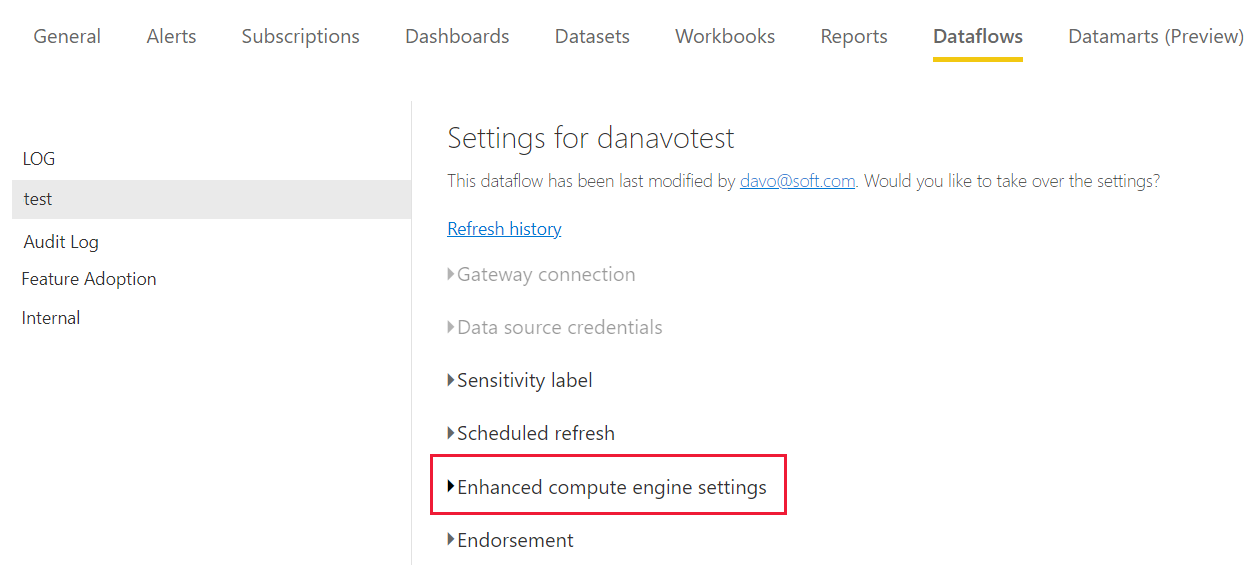
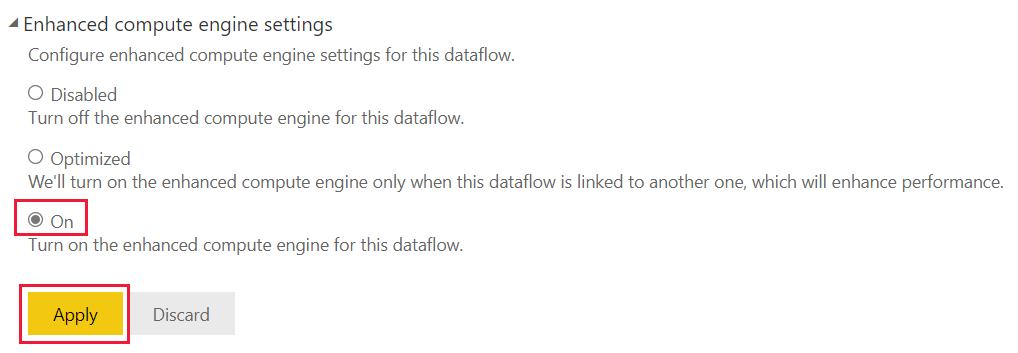
Wählen Sie in den Erweiterten Compute-Engine-EinstellungenEin und anschließend Anwenden aus.
Nutzen Sie die erweiterte Compute Engine
Nachdem Sie die erweiterte Compute Engine aktiviert haben, kehren Sie zu dataflows zurück. Hier sollten Sie eine Leistungsverbesserung in jeder berechneten Tabelle feststellen können, die komplexe Operationen ausführt, z. B. joins- oder group by-Operationen für Dataflows, die aus bestehenden verknüpften Entitäten für dieselbe Kapazität erstellt wurden.
Um die Rechen-Engine optimal zu nutzen, teilen Sie die ETL-Phase in zwei separate Datenflüsse im selben Arbeitsbereich auf:
- Dataflow 1 – Dieser Dataflow sollte nur alle erforderlichen Daten von einer Datenquelle aufnehmen.
- Dataflow 2 – Führen Sie alle ETL-Operationen in diesem zweiten Dataflow durch, aber stellen Sie sicher, dass Sie auf Dataflow 1 verweisen, der dieselbe Kapazität aufweisen sollte. Stellen Sie außerdem zunächst sicher, dass Sie Vorgänge ausführen, die gefaltet werden können: Filtern, Gruppieren nach, Unterscheiden, Verknüpfen. Und führen Sie diese Vorgänge vor allen anderen Vorgängen aus, um sicherzustellen, dass die Compute Engine ausgelastet ist.
Häufig gestellte Fragen und Antworten
Frage: Ich habe die erweiterte Compute-Engine aktiviert, aber meine Aktualisierungen sind langsamer. Warum?
Antwort: Wenn Sie die erweiterte Compute-Engine aktivieren, gibt es zwei mögliche Erklärungen, die zu langsameren Aktualisierungszeiten führen könnten:
Wenn die erweiterte Compute-Engine aktiviert ist, benötigt sie etwas Speicher, um ordnungsgemäß zu funktionieren. Daher wird der für die Durchführung einer Aktualisierung verfügbare Arbeitsspeicher reduziert und somit die Wahrscheinlichkeit erhöht, dass Aktualisierungen in eine Warteschlange gestellt werden. Dieser Anstieg verringert dann die Anzahl der Dataflows, die gleichzeitig aktualisiert werden können. Um dieses Problem zu lösen, sollten Sie bei der Aktivierung des erweiterten Computes Dataflowaktualisierungen über einen längeren Zeitraum verteilen und bewerten, ob Ihre Kapazitätsgröße ausreicht, um sicherzustellen, dass Speicher für gleichzeitige Dataflowaktualisierungen verfügbar ist.
Ein weiterer Grund für möglicherweise langsamere Aktualisierungen kann darin bestehen, dass die Compute-Engine nur auf Grundlage von bereits vorhandenen Entitäten funktioniert. Wenn Ihr Dataflow auf eine Datenquelle verweist, bei der es sich nicht um einen Dataflow handelt, werden Sie keine Verbesserung feststellen. Es gibt keine Leistungssteigerung, da in einigen Big Data-Szenarien das anfängliche Lesen von einer Datenquelle langsamer wäre, da die Daten an die erweiterte Compute-Engine übergeben werden müssen.
Frage: Ich kann den Umschalter der erweiterten Compute Engine nicht sehen. Warum?
Antwort: Die erweiterte Compute Engine wird schrittweise in Regionen auf der ganzen Welt eingeführt, aber ist noch nicht in jeder Region verfügbar.
Frage: Welche Datentypen werden von der Compute-Engine unterstützt?
Antwort: Die erweiterte Compute-Engine und Dataflows unterstützen derzeit die folgenden Datentypen. Wenn Ihr Dataflow nicht einen der folgenden Datentypen verwendet, tritt beim Aktualisieren ein Fehler auf:
- Datum/Uhrzeit
- Dezimalzahl
- Text
- Ganze Zahl
- Datum/Uhrzeit/Zone
- Wahr/Falsch
- Datum
- Zeit
Verwenden von DirectQuery mit Dataflows in Power BI
Sie können DirectQuery verwenden, um eine direkte Verbindung mit Dataflows und daher auch mit Ihrem Dataflow herzustellen, ohne die Daten importieren zu müssen.
Die Verwendung von DirectQuery mit Dataflows ermöglicht die folgenden Verbesserungen an den Power BI- und Dataflowprozessen:
Vermeiden separater Aktualisierungszeitpläne: DirectQuery stellt eine direkte Verbindung mit einem Dataflow her, sodass kein importiertes Semantikmodell erstellt werden muss. Die Verwendung von DirectQuery mit Ihren Dataflows hat zur Folge, dass Sie keine separaten Aktualisierungszeitpläne für den Dataflow und das Semantikmodell benötigen, um sicherzustellen, dass die Daten synchronisiert werden.
Filtern von Daten: DirectQuery ist nützlich für das Arbeiten an einer gefilterten Ansicht von Daten in einem Dataflow. Sie können DirectQuery mit der Compute Engine verwenden, um Dataflowdaten zu filtern und mit der gefilterten Teilmenge zu arbeiten, die Sie benötigen. Durch das Filtern von Daten können Sie mit einer kleineren und besser verwaltbaren Teilmenge der Daten in Ihrem Dataflow arbeiten.
Verwenden von DirectQuery für Dataflows
Die Verwendung von DirectQuery mit Dataflows ist in Power BI Desktop möglich.
Für die Verwendung von DirectQuery mit Dataflows gibt es einige Voraussetzungen:
- Der Dataflow muss sich in einem Arbeitsbereich befinden, der für Power BI Premium aktiviert ist.
- Die Compute-Engine muss aktiviert sein.
Weitere Informationen zu DirectQuery mit Dataflows finden Sie unter Verwendung von DirectQuery mit Dataflows.
Aktivieren von DirectQuery für Dataflows
Die erweiterte Compute-Engine muss sich im optimierten Zustand befinden, um sicherzustellen, dass Ihr Dataflow für den DirectQuery-Zugriff verfügbar ist. Legen Sie die neue Option Erweiterte Compute-Engine-Einstellungen auf Ein fest, um DirectQuery für Dataflows zu aktivieren.

Nachdem Sie diese Einstellung angewendet haben, aktualisieren Sie den Dataflow, damit die Optimierung wirksam wird.
Überlegungen und Einschränkungen zu DirectQuery
Es gibt einige bekannte Einschränkungen im Zusammenhang mit DirectQuery und Dataflows:
Zusammengesetzte/gemischte Modelle, die über Import- und DirectQuery-Datenquellen verfügen, werden derzeit nicht unterstützt.
Bei großen Datenflüssen treten möglicherweise Timeoutprobleme bei Visualisierungen auf. Für große Dataflows, die Timeoutprobleme verursachen, sollte der Importmodus verwendet werden.
In den Datenquelleneinstellungen zeigt der Dataflow Connector ungültige Anmeldeinformationen an, wenn Sie DirectQuery verwenden. Diese Warnung wirkt sich nicht auf das Verhalten aus, und das Semantikmodell funktioniert ordnungsgemäß.
Wenn ein Dataflow über 340 Spalten oder mehr verfügt, führt die Verwendung des Dataflow-Connectors in Power BI Desktop mit der erweiterten Einstellung des Computemoduls dazu, dass die DirectQuery-Option für den Dataflow deaktiviert wird. Wenn Sie DirectQuery in solchen Konfigurationen verwenden möchten, verwenden Sie weniger als 340 Spalten.
berechnete Entitäten
Sie haben die Möglichkeit, Berechnungen im Speicher auszuführen, wenn Sie Dataflows mit einem Power BI Premium-Abonnement verwenden. Mit diesem Feature können Sie Berechnungen mit Ihren vorhandenen Dataflows ausführen und Ergebnisse zurückgeben, mit denen Sie sich auf die Berichtserstellung und Analysen konzentrieren können.
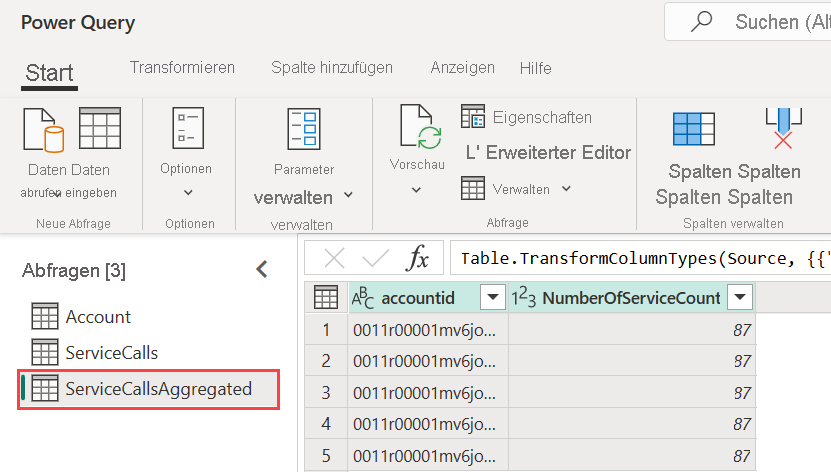
Um Berechnungen im Speicher auszuführen, müssen Sie zunächst den Dataflow erstellen und Daten in diesem Power BI-Dataflowspeicher aufnehmen. Wenn Sie einen Dataflow haben, der Daten enthält, können Sie berechnete Entitäten erstellen. Dabei handelt es sich um Entitäten, die Berechnungen innerhalb des Speichers ausführen.
Überlegungen zu und Einschränkungen von berechneten Entitäten
Wenn Sie mit Dataflows arbeiten, die im Azure Data Lake Storage Gen2-Konto einer Organisation erstellt wurden, funktionieren verknüpfte und berechnete Entitäten nur ordnungsgemäß, wenn sich diese im selben Speicherkonto befinden.
Berechnete Entitäten werden nur innerhalb eines einzelnen Arbeitsbereichs unterstützt.
Es hat sich bei der Berechnung von Daten, die auf lokaler Ebene und in der Cloud verknüpft sind, bewährt, einen neuen Dataflow für jede Quelle zu erstellen (einen für lokale Daten und einen für Clouddaten) und einen dritten Dataflow zu erstellen, um diese beiden Datenquellen zusammenzuführen bzw. Berechnungen für diese durchzuführen.
Verknüpfte Entitäten
Sie können auf vorhandene Datenflüsse im selben Arbeitsbereich verweisen, indem Sie verknüpfte Entitäten mit einem Power BI Premium-Abonnement verwenden, mit dem Sie entweder Berechnungen für diese Entitäten mithilfe berechneter Entitäten durchführen oder eine Tabelle "einzelne Quelle der Wahrheit" erstellen können, die Sie innerhalb mehrerer Datenflüsse wiederverwenden können.
Inkrementelle Aktualisierung
Für Dataflows können inkrementelle Aktualisierungen eingerichtet werden, um zu vermeiden, dass alle Daten bei jeder Aktualisierung abgerufen werden müssen. Wählen Sie hierzu den Dataflow aus, und wählen Sie dann das Symbol für Inkrementelle Aktualisierung aus.

Wenn Sie inkrementelle Aktualisierungen einrichten, werden Parameter zum Dataflow hinzugefügt, um den Datumsbereich festzulegen. Ausführliche Informationen zum Einrichten von inkrementellen Aktualisierungen finden Sie im Artikel Verwenden der inkrementellen Aktualisierung mit Dataflows.
Überlegungen, wann inkrementelles Aktualisieren nicht eingerichtet werden sollte
Legen Sie in den folgenden Situationen keinen inkrementellen Refresh für Datenflüsse fest:
- Für verknüpfte Entitäten sollten keine inkrementellen Aktualisierungen verwendet werden, wenn sie auf einen Dataflow verweisen.
Zugehöriger Inhalt
In den folgenden Artikeln finden Sie weitere Informationen zu Dataflows und Power BI: