BI-Lösungsarchitektur im Kompetenzzentrum
Dieser Artikel richtet sich an IT-Experten und -Manager. Sie erhalten Informationen über die BI-Lösungsarchitektur im Kompetenzzentrum und die verschiedenen eingesetzten Technologien, z. B. Azure, Power BI und Excel. Diese Technologien können gemeinsam genutzt werden, um eine skalierbare, datengesteuerte BI-Cloudplattform zu erstellen.
Das Entwerfen einer stabilen BI-Plattform ähnelt dem Bau einer Brücke: eine Brücke, die transformierte und angereicherte Quelldaten mit den Datenconsumern verbindet. Für das Entwerfen von dieser Art von komplexen Strukturen müssen Sie sehr technisch denken, obwohl auch viel Kreativität gefragt ist. Möglicherweise erstellen Sie sogar die bedeutendste IT-Architektur Ihrer Karriere. In einer großen Organisation kann eine BI-Lösungsarchitektur Folgendes umfassen:
- Datenquellen
- Datenerfassung
- Big Data-/Datenaufbereitung
- Data Warehouse
- BI-Semantikmodelle
- Berichte
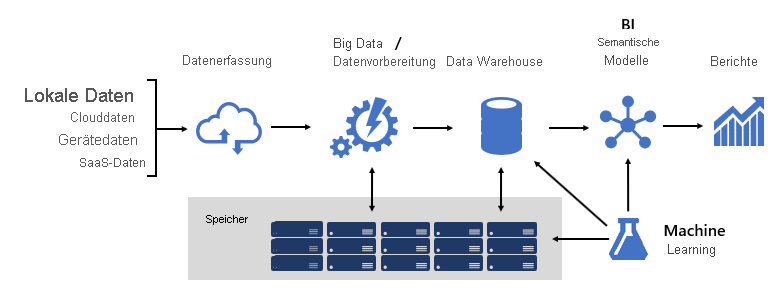
Die Plattform muss bestimmte Anforderungen erfüllen. Insbesondere muss sie die Erwartungen von Unternehmensdiensten und Datenconsumern erfüllen. Gleichzeitig muss sie von Grund auf sicher sein. Außerdem muss sie so resilient sein, dass sie sich an Änderungen anpasst, denn mit der Zeit müssen mit Sicherheit neue Daten und Themenbereiche online gestellt werden.
Frameworks
Wir bei Microsoft haben von Anfang an einen systemähnlichen Ansatz verwendet, indem wir kontinuierlich in die Frameworkentwicklung investiert haben. Frameworks für technische und geschäftliche Prozess ermöglichen es, dass die Entwürfe und Logik wiederverwendet werden können und die Ergebnisse einheitlich sind. Außerdem bieten sie Flexibilität im Hinblick auf die Architektur, weil verschiedene Technologien verwendet werden, und sie optimieren und reduzieren den Engineeringaufwand, weil sich die Prozesse wiederholen.
Wir haben festgestellt, dass gut strukturierte Frameworks die Sichtbarkeit in Bezug auf Datenherkunft, Auswirkungsanalysen, die Verwaltung der Geschäftslogik und der Taxonomie sowie die Governanceoptimierung erhöhen. Außerdem führten sie zu optimierter Entwicklung und die Zusammenarbeit zwischen mehreren großen Teams wurde optimiert und effektiver.
In diesem Artikel gehen wir auf einige unserer Frameworks genauer ein.
Datenmodelle
Mithilfe von Datenmodellen können Sie steuern, wie Daten strukturiert und aufgerufen werden. Für Unternehmensdienste und Datenconsumer stellen Datenmodelle die Schnittstelle mit der BI-Plattform dar.
Eine BI-Plattform kann drei verschiedene Modelltypen bereitstellen:
- Unternehmensmodelle
- BI-Semantikmodelle
- Machine Learning-Modelle
Unternehmensmodelle
Unternehmensmodelle werden von IT-Architekten erstellt und verwaltet. Sie werden mitunter auch als dimensionale Modelle oder Data Marts bezeichnet. Daten werden in der Regel im relationalen Format als Dimensions- und Faktentabellen gespeichert. Diese Tabellen enthalten bereinigte und angereicherte Daten, die von vielen Systemen konsolidiert werden und eine autoritative Quelle für die Berichterstellung und Analyse darstellen.
Unternehmensmodelle bieten eine konsistente und einzelne Datenquelle für die Berichterstellung und BI. Sie werden einmalig erstellt und als Unternehmensstandard freigegeben. Governancerichtlinien gewährleisten, dass die Daten sicher sind, sodass der Zugriff auf sensible Datasets, z. B. Kundeninformationen oder Finanzdaten, je nach Bedarf eingeschränkt ist. Sie übernehmen Namenskonventionen, um die Konsistenz sicherzustellen und so die Glaubwürdigkeit von Daten und die Qualität zu erhöhen.
Bei einer BI-Cloudplattform können Unternehmensmodelle in einem Synapse SQL-Pool in Azure Synapse bereitgestellt werden. Der Synapse SQL-Pool wird dann für das Unternehmen zur einzigen Quelle für schnelle und aussagekräftige Erkenntnisse.
BI-Semantikmodelle
BI-Semantikmodelle stellen eine semantische Ebene für Unternehmensmodelle dar. Sie werden von BI-Entwicklern und Geschäftskunden erstellt und verwaltet. BI-Entwickler erstellen BI-Kernsemantikmodelle, die Daten aus Unternehmensmodellen entnehmen. Geschäftskunden können kleinere, unabhängige Modelle erstellen oder BI-Kernsemantikmodelle mit abteilungsinternen oder externen Quellen erweitern. BI-Semantikmodelle konzentrieren sich üblicherweise auf einen einzelnen Themenbereich, auf den viele Benutzer Zugriff haben.
Geschäftsfunktionen werden nicht allein durch Daten angetrieben, sondern von BI-Semantikmodellen, die Konzepte, Beziehungen, Regeln und Standards beschreiben. Dadurch stellen sie intuitive, leicht verständliche Strukturen dar, die Datenbeziehungen definieren und Unternehmensregeln als Berechnungen zusammenfassen. Sie können auch differenzierte Datenberechtigungen erzwingen, um sicherzustellen, dass die jeweils richtigen Benutzer auf die Daten zugreifen können. Insbesondere ist hervorzuheben, dass sie die Abfrageleistung beschleunigen und so besonders dynamische interaktive Analysen bereitstellen – sogar für mehrere Terabyte von Daten. Genauso wie Unternehmensmodelle übernehmen BI-Semantikmodelle Namenskonventionen, um die Konsistenz zu gewährleisten.
Auf einer BI-Cloudplattform können BI-Entwickler BI-Semantikmodelle für Azure Analysis Services oder Power BI Premium-Funktionen bereitstellen. Wenn die Plattform als Ebene für die Berichterstellung und für Analysen verwendet wird, sollten Sie die Bereitstellung in Power BI in Erwägung ziehen. Diese Produkte unterstützen verschiedene Speichermodi, sodass Ihre Daten in Datenmodelltabellen zwischengespeichert werden können oder der Modus DirectQuery verwendet werden kann. Hierbei handelt es sich um eine Technologie, die Abfragen an die zugrunde liegende Datenquelle übergibt. DirectQuery eignet sich ideal als Speichermodus, wenn Modelltabellen große Datenvolumen darstellen oder wenn nahezu in Echtzeit Ergebnisse benötigt werden. Die beiden Speichermodi können kombiniert werden: Zusammengesetzte Modelle kombinieren Tabellen, die unterschiedliche Speichermodi in einem einzelnen Modell verwenden.
Bei Modellen, an die sehr viele Abfragen gesendet werden, kann Azure Load Balancer verwendet werden, um die Abfragelast gleichmäßig auf Modellreplikate zu verteilen. Außerdem können Sie Ihre Anwendungen skalieren und hochverfügbare BI-Semantikmodelle erstellen.
Machine Learning-Modelle
Machine Learning-Modelle (ML) werden von Data Scientists erstellt und verwaltet. Sie werden größtenteils aus Rohdatequellen im Data Lake entwickelt.
Trainierte ML-Modelle können Muster innerhalb Ihrer Daten offenlegen. In vielen Fällen können diese Muster verwendet werden, um Vorhersagen zu treffen, die zum Anreichern von Daten verwendet werden können. Beispielsweise können anhand des Kaufverhaltens die Kundenabwanderung oder Kunden in einzelne Bereiche unterteilt werden. Die Vorhersageergebnisse können zu Unternehmensmodellen hinzugefügt werden, um Analysen für einzelne Kundenbereiche zuzulassen.
In einer BI-Cloudplattform können Sie mit Azure Machine Learning ML-Modelle trainieren, bereitstellen, automatisieren, verwalten und nachverfolgen.
Data Warehouse
Das Herzstück einer BI-Plattform ist das Data Warehouse, das Ihre Unternehmensmodelle hostet. Hierbei handelt es sich um eine Quelle für sanktionierte Daten (als System of Record und als Hub), die Unternehmensmodelle für die Berichterstellung, BI und Data Science bereitstellt.
Viele Unternehmensdienste, einschließlich Branchenanwendungen, nutzen das Data Warehouse als autoritative und kontrollierte Quelle für Unternehmensinformationen.
Unser Data Warehouse bei Microsoft wird von Azure Data Lake Storage Gen2 (ADLS Gen2) und Azure Synapse Analytics gehostet.
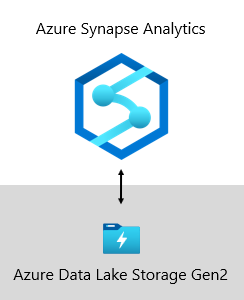
- Mit ADLS Gen2 wird Azure Storage zur Basis für das Erstellen von unternehmensweiten Data Lakes in Azure. Diese SKU ist darauf ausgelegt, mehrere Petabyte an Informationen bereitzustellen und gleichzeitig Hunderte von Gigabyte an Durchsatz zu unterstützen. Außerdem bietet sie kostengünstige Speicherkapazität und -transaktionen. Darüber hinaus unterstützt sie den mit Hadoop kompatiblen Zugriff, wodurch ein mit einem Hadoop Distributed File System (HDFS) vergleichbarer Zugriff auf Daten und deren Verwaltung ermöglicht wird. Tatsächlich können Azure HDInsight, Azure Databricks und Azure Synapse Analytics auf in ADLS Gen2 gespeicherte Daten zugreifen. Daher bietet es sich an, auf einer BI-Plattform Rohquelldaten, teilweise verarbeitete oder bereitgestellte Daten sowie produktionsfertige Daten zu speichern. Wir verwenden sie zum Speichern aller Unternehmensdaten.
- Azure Synapse Analytics ist ein Analysedienst, der Data Warehousing für Unternehmen mit Big Data-Analysen vereint. Er ermöglicht flexible Datenabfragen nach Ihren Vorstellungen, indem serverlose On-Demand-Ressourcen oder bereitgestellten Ressourcen im gewünschten Umfang verwendet werden. Synapse SQL, eine Komponente von Azure Synapse Analytics, unterstützt alle T-SQL-basierte Analysen. Daher eignet sich dieses System ideal zum Hosten von Unternehmensmodellen, die aus Ihren Dimensions- und Faktentabellen bestehen. Tabellen können mithilfe einfacher Polybase T-SQL-Abfragen effizient aus ADLS Gen2 geladen werden. Dann stehen Ihnen die Funktionen von MPP zur Verfügung, um Hochleistungsanalysen auszuführen.
Geschäftsregel-Engine-Framework
Wir haben ein Geschäftsregel-Engine-Framework (Business Rule Engine, BRE) entwickelt, um Geschäftslogik zu katalogisieren, die in die Data Warehouse-Ebene implementiert werden kann. Eine BRE kann viele Funktionen haben, aber im Kontext eines Data Warehouse ist sie nützlich für das Erstellen von berechneten Spalten in relationalen Tabellen. Diese berechneten Spalten werden in der Regel mithilfe von Bedingungsanweisungen als mathematische Berechnungen oder Ausdrücke dargestellt.
Ziel ist es, Unternehmenslogik vom BI-Kerncode abzutrennen. Üblicherweise sind Geschäftsregeln in gespeicherten SQL-Prozeduren hartcodiert, sodass die Verwaltung häufig sehr aufwendig sein kann, wenn sich die Unternehmensanforderungen ändern. In einem BRE werden Geschäftsregeln einmalig definiert und mehrmals verwendet, wenn sie auf verschiedene Data Warehouse-Entitäten angewendet werden. Wenn die Berechnungslogik geändert werden muss, muss sie nur an einem Ort und nicht in zahlreichen gespeicherten Prozeduren aktualisiert werden. Außerdem gibt es einen weiteren kleinen Vorteil: Ein BRE-Framework steigert die Sichtbarkeit und Transparenz von implementierter Geschäftslogik. Dies zeigt sich in Form von Berichten, die als Dokumentation verwendet werden können, die automatisch aktualisiert wird.
Datenquellen
Mit einem Data Warehouse können Daten aus praktisch jeder beliebigen Datenquelle konsolidiert werden. Es basiert größtenteils auf Datenquellen für Branchenanwendungen, bei denen es sich häufig um relationale Datenbanken handelt, in denen themenspezifische Daten für z. B. die Vertriebs-, Marketing- oder Finanzabteilung gespeichert werden. Diese Datenbanken können in der Cloud gehostet oder lokal gespeichert werden. Andere Datenquellen können dateibasiert sein, insbesondere Webprotokolle oder IoT-Daten, die von Geräten bezogen werden. Darüber hinaus können Daten von SaaS-Anbietern (Software-as-a-Service) verwendet werden.
Bei Microsoft werden einige Betriebsdaten, die von unseren internen Systemen ausgegeben werden, unter Verwendung von Dateiformaten für Rohdaten an ADLS Gen2 weitergegeben. Neben unserem Data Lake bestehen auch andere Quellsysteme aus relationalen Branchenanwendungen, Excel-Arbeitsmappen, anderen dateibasierten Quellen sowie aus Repositorys für die Masterdatenverwaltung (Master Data Management, MDM) und benutzerdefinierte Daten. Mithilfe von MDM-Repositorys können wir unsere Masterdaten so verwalten, dass autoritative, standardisierte und validierte Datenversionen sichergestellt sind.
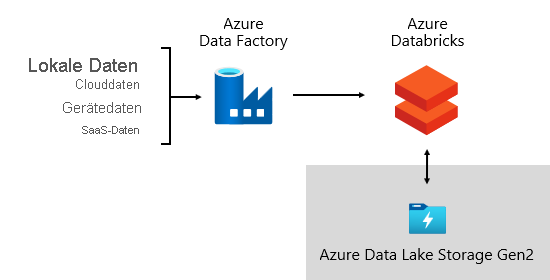
Datenerfassung
In regelmäßigen Abständen, die sich nach den Vorgaben des jeweiligen Unternehmens richten, werden Daten aus Quellsystemen erfasst und in das Data Warehouse geladen. Dies kann zum Beispiel einmal am Tag oder häufiger sein. Bei der Datenerfassung werden Daten extrahiert, transformiert und geladen. Dies kann in beliebiger Reihenfolge geschehen. Unterschiede gibt es allein bei der Transformation. Diese wird angewendet, um Daten zu bereinigen, anzupassen, zu integrieren und zu standardisieren. Weitere Informationen finden Sie unter Extrahieren, Transformieren und Laden (ETL).
Letztendlich besteht das Ziel darin, die richtigen Daten so schnell und effizient wie möglich in das Unternehmensmodell zu laden.
Wir bei Microsoft verwenden Azure Data Factory (ADF). Dieser Dienste wird verwendet, um Datenvalidierungen, Transformationen und Massenladevorgänge von externen Quellsystemen in unseren Data Lake zu planen und zu orchestrieren. Dies wird von benutzerdefinierten Frameworks verwaltet, damit große Mengen an Daten parallel verarbeitet werden können. Außerdem wird eine umfassende Protokollierung durchgeführt, um die Problembehandlung und die Leistungsüberwachung zu unterstützen sowie um Warnungen auszulösen, wenn bestimmte Bedingungen erfüllt sind.
In der Zwischenzeit führt Azure Databricks, eine Apache Spark-basierte Analyseplattform, die für die Azure Cloud Services-Plattform optimiert ist, speziell für den Data-Science-Bereich Transformationen durch. Außerdem werden ML-Modelle mithilfe von Python-Notebooks erstellt und ausgeführt. Die Ergebnisse dieser ML-Modelle werden in das Data Warehouse geladen, um Vorhersagen in Unternehmensanwendungen und -berichte zu integrieren. Da Azure Databricks direkt auf die Data Lake-Dateien zugreift, ist es nicht mehr oder nur noch teilweise notwendig, Daten zu kopieren oder abzurufen.
Datenerfassungsframework
Wir haben ein Datenerfassungsframework entwickelt, das aus Konfigurationstabellen und -prozeduren besteht. Es unterstützt einen datengesteuerten Ansatz zum schnellen Abrufen großer Datenmengen mit möglichst wenig Code. Kurz gesagt, dieses Framework vereinfacht den Prozess der Datenerfassung zum Laden des Data Warehouse.
Das Framework ist abhängig von Konfigurationstabellen, in denen Informationen zu Datenquellen und -zielen gespeichert werden, z. B. Quelltyp, Server, Datenbank, Schema und tabellenbezogene Details. Bei diesem Entwurfsansatz müssen wir keine ADF-Pipelines oder SQL Server Integration Services-Pakete (SSIS) erstellen. Stattdessen werden die Prozeduren in einer beliebigen Sprache geschrieben, um ADF-Pipelines zu erstellen, die zur Laufzeit dynamisch erstellt und ausgeführt werden. Dadurch wird die Datenerfassung zu einer Konfigurationsaufgabe, die problemlos operationalisiert werden kann. In der Regel benötigen Sie umfassende Entwicklungsressourcen, um hartcodierte ADF-Pipelines oder SSIS-Pakete zu erstellen.
Das Datenerfassungsframework wurde entwickelt, um den Prozess der Verarbeitung von Änderungen des Upstreamquellschemas zu vereinfachen. Konfigurationsdaten können problemlos manuell oder automatisch aktualisiert werden, wenn Schemaänderungen erkannt werden, um neu hinzugefügte Attribute im Quellsystem abzurufen.
Orchestrierungsframework
Wir haben ein Orchestrierungsframework entwickelt, um unsere Datenpipelines zu operationalisieren und zu orchestrieren. Es wird ein datengesteuerter Entwurf verwendet, der von einer Reihe von Konfigurationstabellen abhängig ist. Diese Tabellen speichern Metadaten, die Pipelineabhängigkeiten beschreiben und Informationen zum Zuordnen von Quelldaten an Zieldatenstrukturen enthalten. Die Investitionen in die Entwicklung dieses adaptiven Frameworks haben sich gelohnt: Es ist damit nicht mehr notwendig, jede einzelne Datenverschiebung hartzucodieren.
Datenspeicherung
Ein Data Lake kann große Mengen von Rohdaten für die spätere Verwendung zusammen mit Transformationen von Stagingdaten speichern.
Wir bei Microsoft verwenden ADLS Gen2 als Single Source of Truth. Diese SKU speichert Rohdaten sowie bereitgestellte und produktionsfertige Daten. Sie bietet eine hochgradig skalierbare und kostengünstige Data Lake-Lösung für Big-Data-Analysen. Dank des hochleistungsfähigen Dateisystems, kombiniert mit einem hohen Maß an Skalierbarkeit, ist diese SKU für Datenanalyseworkloads optimiert, mit denen schneller Erkenntnisse bereitgestellt werden.
ADLS Gen2 bietet das Beste aus zwei unterschiedlichen Bereichen: Es handelt sich sowohl um einen Blobspeicher als auch um einen hochleistungsfähigen Dateisystemnamespace, der mit optimierten Zugriffsberechtigungen konfiguriert werden kann.
Die optimierten Daten werden dann in einer relationalen Datenbank gespeichert, um einen hochleistungsfähigen, hochgradig skalierbaren Datenspeicher für Unternehmensmodelle mit Sicherheit, Governance und Verwaltbarkeit bereitzustellen. Themenspezifische Data Marts, die durch Azure Databricks oder Polybase T-SQL-Abfragen geladen werden, werden in Azure Synapse Analytics gespeichert.
Nutzung der Daten
Auf der Berichtsebene nutzen Unternehmensdienste Unternehmensdaten, die aus dem Data Warehouse stammen. Außerdem greifen sie direkt auf Daten im Data Lake zu, um Ad-hoc-Analysen oder Data Science-Tasks auszuführen.
Differenzierte Berechtigungen werden auf allen Ebenen erzwungen: in Data Lake-, Unternehmens- und in BI-Semantikmodellen. Durch die Berechtigungen wird sichergestellt, dass Datenconsumer nur die Daten sehen können, für die sie Zugriffsrechte besitzen.
Wir bei Microsoft verwenden Power BI-Berichte und -Dashboards sowie paginierte Power BI-Berichte. Einige Berichte und Ad-hoc-Analysen werden in Excel erstellt – insbesondere im Bereich Finanzen.
Wir bieten Datenwörterbücher an, die Referenzinformationen zu unseren Datenmodellen enthalten. Diese stellen wir unseren Benutzern zur Verfügung, damit diese sich über unsere BI-Plattform informieren können. In den Wörterbüchern werden Modellentwürfe dokumentiert sowie Beschreibungen zu Entitäten, Formaten, Strukturen, Datenherkunft, Beziehungen und Berechnungen bereitgestellt. Wir verwenden Azure Data Catalog, um die Datenquellen leicht erkennbar und verständlich zu machen.
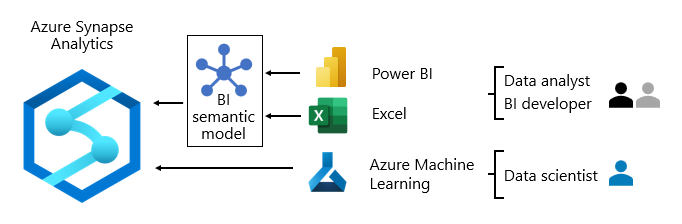
In der Regel unterscheiden sich die Datenverbrauchsmuster je nach Rolle:
- Data Analysts verbinden sich direkt mit BI-Kernsemantikmodellen. Wenn die BI-Kernsemantikmodelle alle benötigten Daten und Logikkomponenten enthalten, verwenden sie Liveverbindungen, um Power BI-Berichte und -Dashboards zu erstellen. Wenn sie die Modelle mit Abteilungsdaten erweitern müssen, erstellen sie zusammengesetzten Power BI-Modelle. Wenn Berichte im Tabellenformat benötigt werden, verwenden sie Excel, um basierend auf BI-Kernsemantikmodellen oder BI-Abteilungssemantikmodellen Berichte zu erstellen.
- BI-Entwickler und Autoren von Unternehmensberichten verbinden sich direkt mit Unternehmensmodellen. Sie verwenden Power BI Desktop, um Berichte zu Liveverbindungsanalysen zu erstellen. Sie können auch BI-Unternehmensberichte als paginierte Power BI-Berichte erstellen, indem sie native SQL-Abfragen schreiben, um über die Azure Synapse Analytics-Unternehmensmodelle mithilfe von T-SQL oder Power BI-Semantikmodellen auf Daten zuzugreifen. Dabei kommt entweder DAX oder MDX zum Einsatz.
- Data Scientists verbinden sich direkt mit Daten im Data Lake. Sie verwenden Azure Databricks und Python-Notebooks zum Entwickeln von ML-Modellen, die häufig experimentell sind und spezielle Kenntnisse zur Verwendung in der Produktionsumgebung erfordern.
Zugehöriger Inhalt
Weitere Informationen zu diesem Artikel finden Sie in den folgenden Ressourcen:
- Roadmap für die Einführung von Fabric: Center of Excellence
- Enterprise BI in Azure mit Azure Synapse Analytics
- Haben Sie Fragen? Stellen Sie Ihre Frage in der Power BI-Community.
- Vorschläge? Einbringen von Ideen zur Verbesserung von Power BI
Dienstleistungsunternehmen
Zertifizierte Power BI-Partner können Ihr Unternehmen beim erfolgreichen Einrichten eines Kompetenzzentrums unterstützen. Sie können kostengünstige Schulungen bereitstellen oder eine Überprüfung Ihrer Daten durchführen. Wenn Sie einen Power BI-Partner hinzuziehen möchten, besuchen Sie das Power BI-Partnerportal.
Darüber hinaus können Sie mit erfahrenen Beratungspartnern in Kontakt treten. Diese können Sie bei der Bewertung, Auswertung oder Implementierung von Power BI unterstützen.
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für