Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Aggregationen in Power BI können die Abfrageleistung über große DirectQuery-Semantikmodelle verbessern. Mithilfe von Aggregationen speichern Sie Daten auf aggregierter Ebene im Arbeitsspeicher zwischen. Aggregationen in Power BI können manuell im Datenmodell konfiguriert werden, wie in diesem Artikel beschrieben. Bei Premium-Abonnements wird automatisch das Feature "Automatische Aggregationen " in den Modelleinstellungen aktiviert.
Erstellen von Aggregationstabellen
Je nach Datenquellentyp kann eine Aggregationstabelle in der Datenquelle als Tabelle oder Ansicht, systemeigene Abfrage erstellt werden. Erstellen Sie für die größte Leistung eine Aggregationstabelle als importtabelle, die in Power Query erstellt wurde. Anschließend verwenden Sie das Dialogfeld "Aggregationen verwalten" in Power BI Desktop, um Aggregationen für Aggregationsspalten mit Zusammenfassungs-, Detailtabellen- und Detailspalteneigenschaften zu definieren.
Dimensionale Datenquellen wie Data Warehouses und Data Marts können beziehungsbasierte Aggregationen verwenden. Große Hadoop-Datenquellen aggregieren häufig auf Grundlage von GroupBy-Spalten. In diesem Artikel werden typische Unterschiede bei der Power BI-Datenmodellierung für jeden Datenquellentyp beschrieben.
Verwalten von Aggregationen
Klicken Sie im Datenbereich einer beliebigen Power BI Desktop-Ansicht mit der rechten Maustaste auf die Aggregationstabelle, und wählen Sie dann " Aggregationen verwalten" aus.
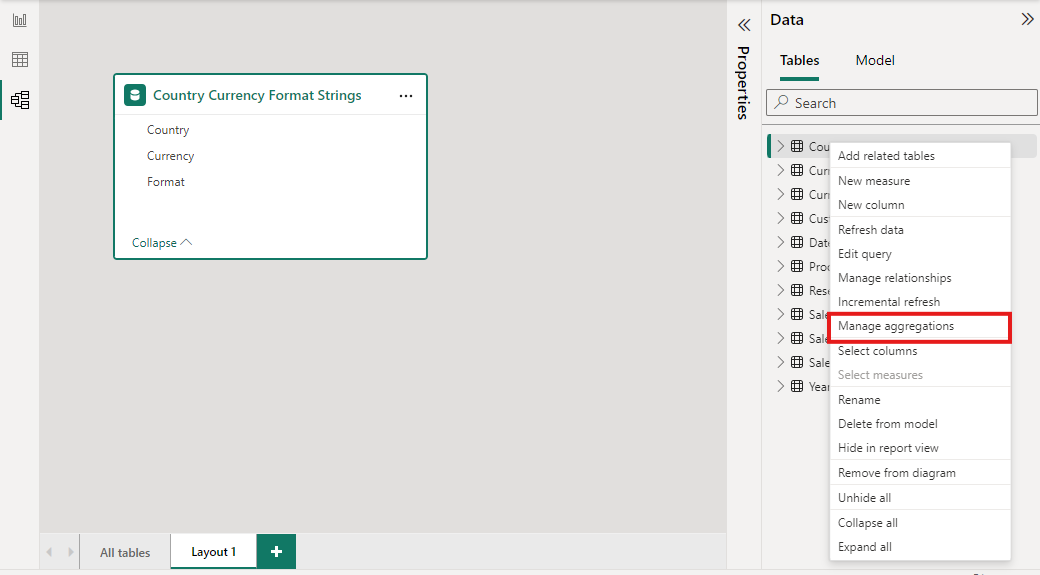
Im Dialogfeld " Aggregationen verwalten " wird eine Zeile für jede Spalte in der Tabelle angezeigt, in der Sie das Aggregationsverhalten angeben können. Im folgenden Beispiel werden Abfragen zur Tabelle " Verkaufsdetails " intern an die Aggregationstabelle " Sales Agg " umgeleitet.
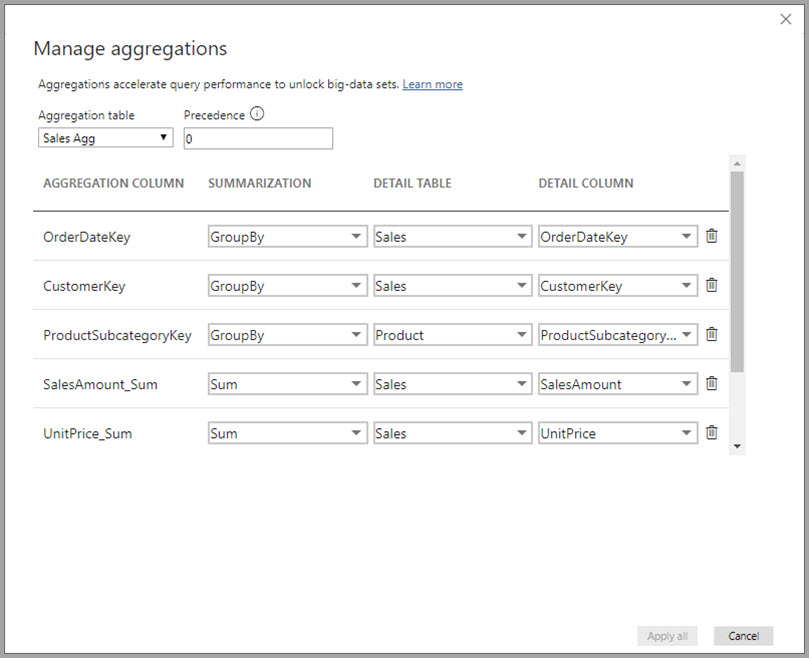
In diesem beziehungsbasierten Aggregationsbeispiel sind die GroupBy-Einträge optional. Mit Ausnahme von DISTINCTCOUNT wirken sie sich nicht auf das Aggregationsverhalten aus und dienen in erster Linie der Lesbarkeit. Ohne die GroupBy-Einträge würden die Aggregationen aufgrund der Beziehungen dennoch berücksichtigt werden. Dies unterscheidet sich vom Beispiel für Big Data weiter unten in diesem Artikel, in dem die GroupBy-Einträge erforderlich sind.
Bestätigungen
Im Dialogfeld " Aggregationen verwalten " werden Validierungen erzwungen:
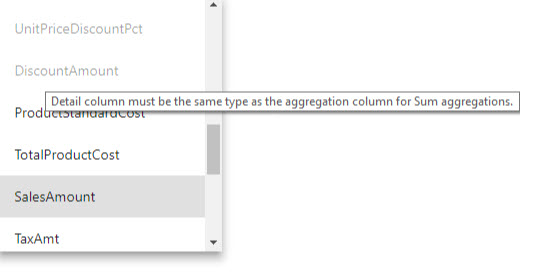
- Die Detailspalte muss denselben Datentyp wie die Aggregationsspalte aufweisen, außer bei den Zusammenfassungsfunktionen "Anzahl" und den Tabellenzeilen für "Anzahl". Die Zeilen "Anzahl" und "Anzahl" sind nur für ganzzahlige Aggregationsspalten verfügbar und erfordern keinen übereinstimmenden Datentyp.
- Verkettete Aggregationen, die drei oder mehr Tabellen abdecken, sind nicht zulässig. Beispielsweise können Aggregationen in Tabelle A nicht auf eine Tabelle B verweisen, die Aggregationen enthält, die auf eine Tabelle C verweisen.
- Doppelte Aggregationen, bei denen zwei Einträge dieselbe Zusammenfassungsfunktion verwenden und auf dieselbe Detailtabelle und Detailspalte verweisen, sind nicht zulässig.
- Die Detailtabelle muss den DirectQuery-Speichermodus verwenden, nicht importieren.
- Das Gruppieren nach einer Fremdschlüsselspalte, die von einer inaktiven Beziehung verwendet wird, und die Verwendung der USERELATIONSHIP-Funktion für Aggregationsberechnungen wird nicht unterstützt.
- Aggregationen, die auf GroupBy-Spalten basieren, können Beziehungen zwischen Aggregationstabellen verwenden, aber das Erstellen von Beziehungen zwischen Aggregationstabellen wird in Power BI Desktop nicht unterstützt. Bei Bedarf können Sie Beziehungen zwischen Aggregationstabellen mithilfe eines Drittanbietertools oder einer Skriptlösung über XML for Analysis (XMLA)-Endpunkte erstellen.
Die meisten Überprüfungen werden durchgesetzt, indem Dropdown-Werte deaktiviert und erläuternder Text im Tooltip angezeigt wird.
Aggregationstabellen sind ausgeblendet
Benutzer mit schreibgeschütztem Zugriff auf das Modell können keine Aggregationstabellen abfragen. Schreibgeschützter Zugriff vermeidet Sicherheitsprobleme bei Verwendung mit zeilenbezogener Sicherheit (RLS). Verbraucher und Abfragen beziehen sich auf die Detailtabelle, nicht auf die Aggregationstabelle, und brauchen nichts von der Aggregationstabelle zu wissen.
Aus diesem Grund werden Aggregationstabellen in der Berichtsansicht ausgeblendet. Wenn die Tabelle noch nicht ausgeblendet ist, wird sie im Dialogfeld " Aggregationen verwalten" ausgeblendet, wenn Sie "Alle übernehmen" auswählen.
Speichermodi
Das Aggregationsfeature interagiert mit Speichermodi auf Tabellenebene. Power BI-Tabellen können DirectQuery-, Import- oder Dual-Speichermodi verwenden. DirectQuery fragt das Back-End direkt ab, während "Importieren" Daten im Arbeitsspeicher zwischenspeichert und Abfragen an die zwischengespeicherten Daten sendet. Alle Power BI-Import- und nicht mehrdimensionalen DirectQuery-Datenquellen können mit Aggregationen arbeiten.
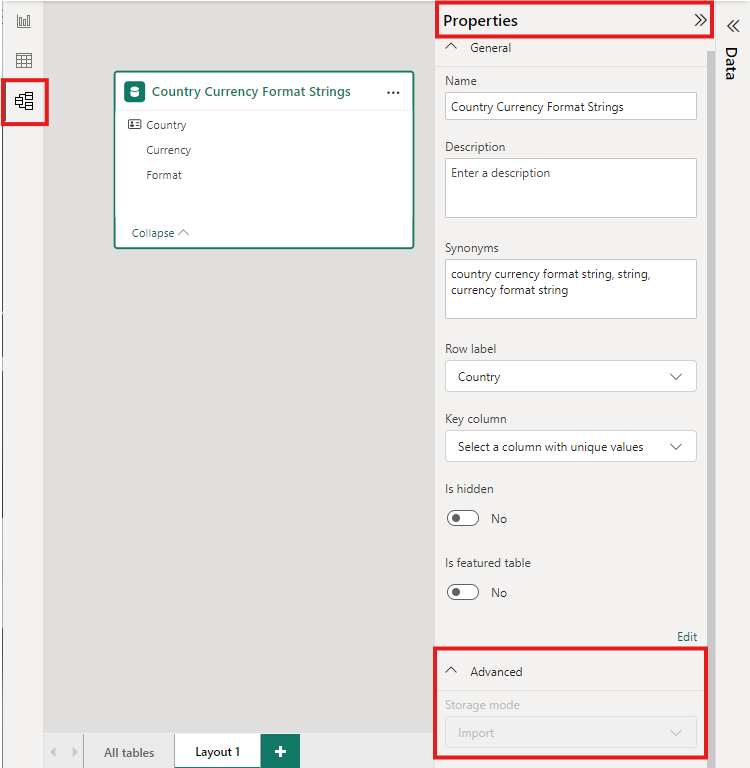
Wenn Sie den Speichermodus einer aggregierten Tabelle auf "Importieren" festlegen möchten, um Abfragen zu beschleunigen, wählen Sie die aggregierte Tabelle in der Power BI-Desktopmodellansicht aus. Erweitern Sie im Eigenschaftenbereich das Menü Erweitert, klappen Sie die Auswahl unter Speichermodus auf, und wählen Sie Importieren aus. Das Ändern des Imports ist unumkehrbar.
Weitere Informationen zu Tabellenspeichermodi finden Sie unter "Verwalten des Speichermodus" in Power BI Desktop.
RLS für Aggregationen
Um ordnungsgemäß für Aggregationen zu funktionieren, sollten RLS-Ausdrücke die Aggregationstabelle und die Detailtabelle filtern.
Im folgenden Beispiel funktioniert der RLS-Ausdruck in der Tabelle "Geography " für Aggregationen, da "Geography" sich auf der Filterseite der Beziehungen zur Tabelle " Sales " und der Tabelle " Sales Agg " befindet. Abfragen, die auf die Aggregationstabelle und Abfragen treffen, für die keine RLS erfolgreich angewendet wurden.
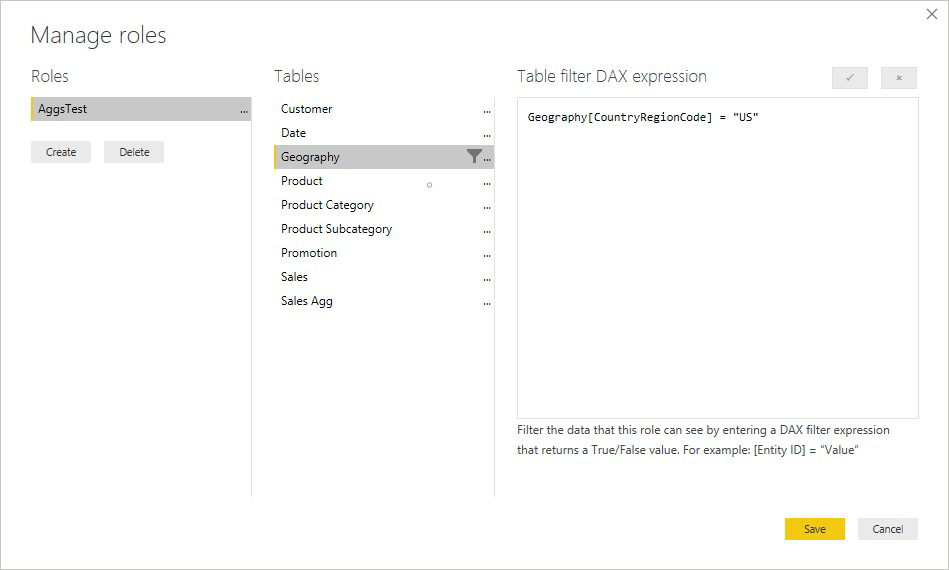
Ein RLS-Ausdruck in der Tabelle "Product " filtert nur die Detailtabelle "Sales " und nicht die aggregierte Tabelle " Sales Agg ". Da die Aggregationstabelle eine weitere Darstellung der Daten in der Detailtabelle ist, wäre es unsicher, Abfragen aus der Aggregationstabelle zu beantworten, wenn der RLS-Filter nicht angewendet werden kann. Das Filtern nur der Detailtabelle wird nicht empfohlen, da Benutzerabfragen aus dieser Rolle nicht von Aggregationstreffern profitieren.
Ein RLS-Ausdruck, der nur die Aggregationstabelle " Sales Agg " und nicht die Tabelle " Verkaufsdetails " filtert, ist nicht zulässig.
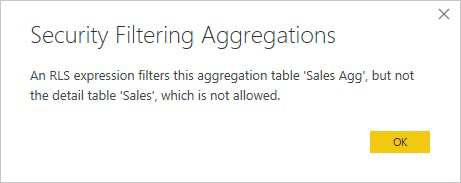
Für Aggregationen, die auf GroupBy-Spalten basieren, kann ein auf die Detailtabelle angewendeter RLS-Ausdruck verwendet werden, um die Aggregationstabelle zu filtern, da alle GroupBy-Spalten in der Aggregationstabelle von der Detailtabelle abgedeckt werden. Andererseits kann ein RLS-Filter in der Aggregationstabelle nicht auf die Detailtabelle angewendet werden. Dies ist daher unzulässig.
Aggregation basierend auf Beziehungen
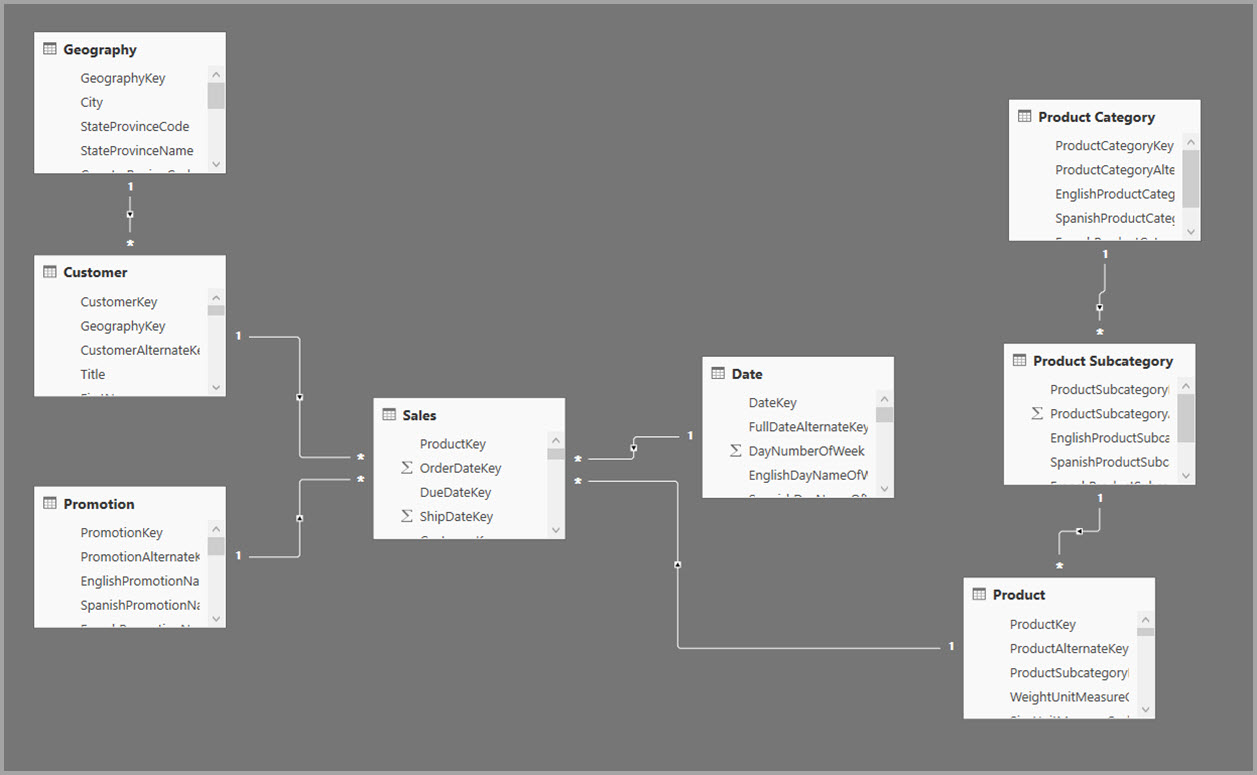
Dimensionale Modelle verwenden in der Regel Aggregationen basierend auf Beziehungen. Power BI-Modelle aus Data Warehouses und Data Marts ähneln Stern-/Schneeflakeschemas mit Beziehungen zwischen Dimensionstabellen und Faktentabellen.
Im folgenden Beispiel ruft das Modell Daten aus einer einzelnen Datenquelle ab. Tabellen verwenden den DirectQuery-Speichermodus. Die Tabelle " Sales fact" enthält Milliarden von Zeilen. Das Festlegen des Speichermodus von Vertrieb auf "Import" für die Zwischenspeicherung würde erheblichen Speicher- und Ressourcenaufwand beanspruchen.
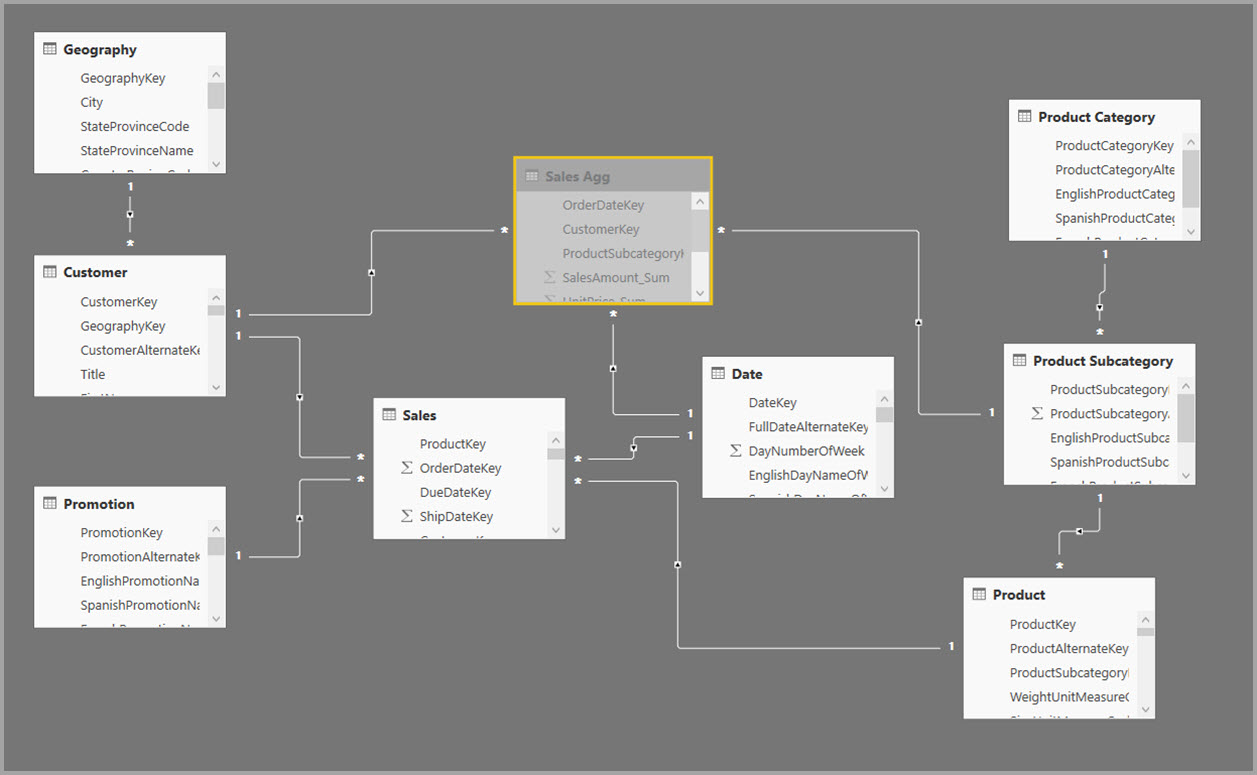
Erstellen Sie stattdessen die Aggregationstabelle "Sales Agg ". In der Tabelle Sales Agg entspricht die Anzahl der Zeilen der Summe von SalesAmount, gruppiert nach CustomerKey, DateKey und ProductSubcategoryKey. Die Tabelle "Sales Agg " weist eine höhere Granularität auf als "Umsatz", sodass sie anstelle von Milliarden Millionen von Zeilen enthalten kann, die einfacher zu verwalten sind.
Wenn die folgenden Dimensionstabellen am häufigsten für Abfragen mit hohem Geschäftswert verwendet werden, können sie Sales Agg mithilfe von 1:n- oder n:1-Beziehungen filtern.
- Geografie
- Kunde
- Datum
- Produktunterkategorie
- Produktkategorie
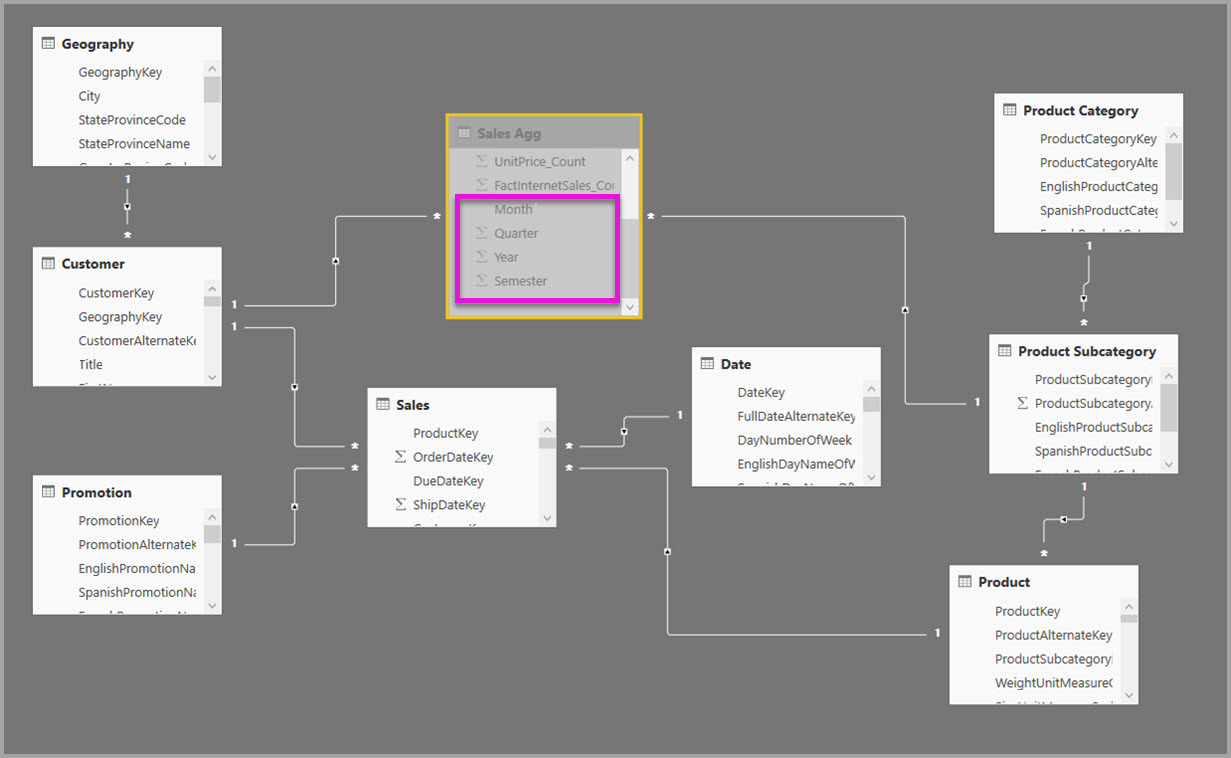
Die folgende Abbildung zeigt dieses Modell.
In der folgenden Tabelle sind die Aggregationen für die Tabelle " Sales Agg " aufgeführt.
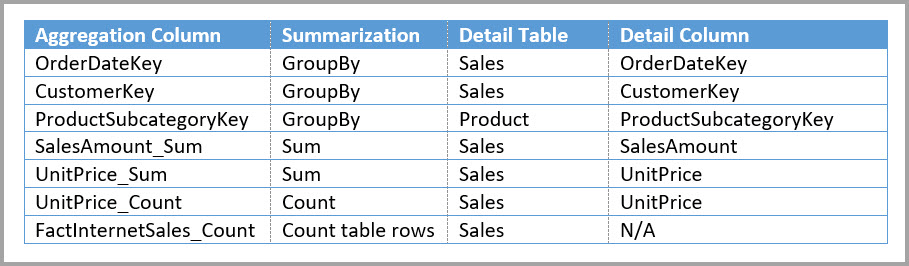
Hinweis
Die Tabelle "Sales Agg " hat wie jede Tabelle die Flexibilität, auf verschiedene Weise geladen zu werden. Die Aggregation kann in der Quelldatenbank mithilfe von ETL/ELT-Prozessen oder durch den M-Ausdruck für die Tabelle ausgeführt werden. Die aggregierte Tabelle kann den Importspeichermodus mit oder ohne inkrementelle Aktualisierung für semantische Modelle verwenden oder DirectQuery verwenden und für schnelle Abfragen mithilfe von Columnstore-Indizes optimiert werden. Diese Flexibilität ermöglicht ausgewogene Architekturen, die das Laden von Abfragen verteilen können, um Engpässe zu vermeiden.
Wenn Sie den Speichermodus der aggregierten Tabelle "Sales Agg " in "Importieren " ändern, wird ein Dialogfeld geöffnet, das besagt, dass die zugehörigen Dimensionstabellen auf den Speichermodus "Dual" festgelegt werden können.
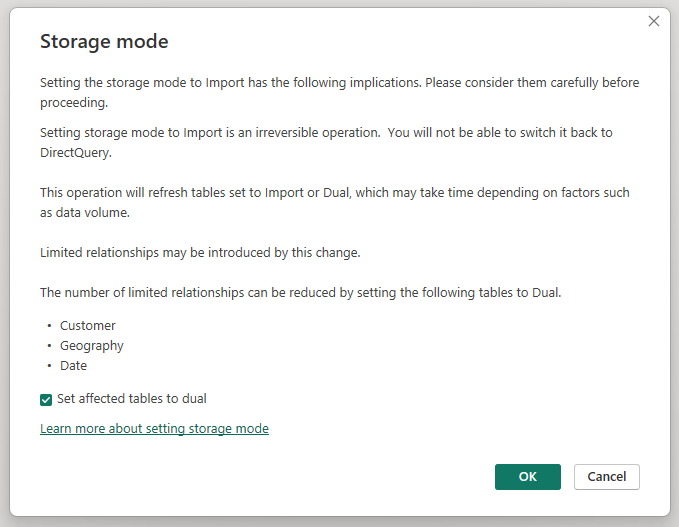
Wenn Sie die zugehörigen Dimensionstabellen auf "Dual" festlegen, können sie je nach Unterabfrage als Import oder DirectQuery fungieren. Im Beispiel:
- Abfragen, die Metriken aus der Tabelle "Sales Agg" im Importmodus zusammenfassen und nach Attribut(en) aus den zugehörigen Dual-Tabellen gruppieren, können aus dem Arbeitsspeicher-Cache zurückgegeben werden.
- Abfragen, die Metriken aus der DirectQuery Sales-Tabelle aggregieren und nach Attribut(en) aus den verwandten dualen Tabellen gruppieren, können im DirectQuery-Modus zurückgegeben werden. Die Abfragelogik, einschließlich des GroupBy-Vorgangs, wird an die Quelldatenbank übergeben.
Weitere Informationen zum Dual-Speichermodus finden Sie unter "Verwalten des Speichermodus" in Power BI Desktop.
Regelmäßige und eingeschränkte Beziehungen
Aggregationstreffer, die auf Beziehungen basieren, erfordern normale Beziehungen.
Normale Beziehungen umfassen die folgenden Kombinationen im Speichermodus, bei denen beide Tabellen aus einer einzigen Quelle stammen:
| Tisch auf den verschiedenen Seiten | Tabelle auf der 1 Seite |
|---|---|
| Doppelt | Dual |
| Importieren | Import oder Doppelt |
| Direktabfrage | DirectQuery oder Dual |
Der einzige Fall, bei dem eine quellübergreifende Beziehung als normal betrachtet wird, besteht darin, dass beide Tabellen auf "Importieren" festgelegt sind. Viele-zu-viele-Beziehungen werden immer als eingeschränkt angesehen.
Informationen zu quellübergreifenden Aggregationstreffern, die nicht von Beziehungen abhängen, finden Sie unter Aggregationen basierend auf GroupBy-Spalten.
Beispiele für beziehungsbasierte Aggregationsabfragen
Die folgende Abfrage greift auf die Aggregation zu, da Spalten in der Datumstabelle die Granularität haben, die für die Aggregation geeignet ist. Die Spalte "SalesAmount " verwendet die Summenaggregation .

Die folgende Abfrage trifft nicht auf die Aggregation. Obwohl die Summe von SalesAmount angefordert wird, führt die Abfrage einen GroupBy-Vorgang für eine Spalte in der Tabelle "Produkt " aus, die nicht an der Granularität liegt, die die Aggregation erreichen kann. Wenn Sie die Beziehungen im Modell beobachten, kann eine Produktunterkategorie mehrere Produktzeilen aufweisen. Die Abfrage kann nicht bestimmen, mit welchem Produkt aggregiert werden soll. In diesem Fall wird die Abfrage auf DirectQuery zurückgesetzt und sendet eine SQL-Abfrage an die Datenquelle.

Aggregationen sind nicht nur für einfache Berechnungen vorgesehen, die eine einfache Summe ausführen. Komplexe Berechnungen können ebenfalls profitieren. Konzeptionell wird eine komplexe Berechnung in Unterabfragen für jede SUMME, MIN, MAX und ANZAHL unterteilt. Jede Unterabfrage wird ausgewertet, um festzustellen, ob sie auf die Aggregation treffen kann. Diese Logik gilt nicht in allen Fällen aufgrund der Abfrageplanoptimierung, aber im Allgemeinen sollte sie angewendet werden. Das folgende Beispiel trifft auf die Aggregation.

Die Funktion COUNTROWS kann von Aggregationen profitieren. Die folgende Abfrage trifft auf die Aggregation, da für die Tabelle "Sales" eine Aggregation von "Anzahl"-Tabellenzeilen definiert ist.

Die MITTELWERT-Funktion kann von Aggregationen profitieren. Die folgende Abfrage wird aggregiert, da der MITTELWERT intern in eine SUMME, geteilt durch eine ANZAHL, umgewandelt wird. Da die Spalte UnitPrice Aggregationen für SUM und COUNT definiert hat, wird die Aggregation ausgelöst.

In einigen Fällen kann die DISTINCTCOUNT-Funktion von Aggregationen profitieren. Die folgende Abfrage trifft auf die Aggregation, da es einen GroupBy-Eintrag für CustomerKey gibt, der die Eindeutigkeit von CustomerKey in der Aggregationstabelle aufrecht erhält. Diese Technik kann dennoch den Leistungsschwellenwert erreichen, bei dem sich mehr als zwei bis fünf Millionen unterschiedliche Werte auf die Abfrageleistung auswirken können. Es kann jedoch in Szenarien hilfreich sein, in denen es Milliarden von Zeilen in der Detailtabelle gibt, aber zwei bis fünf Millionen unterschiedliche Werte in der Spalte. In diesem Fall kann DISTINCTCOUNT schneller durchgeführt werden als das Scannen der Tabelle mit Milliarden von Zeilen, selbst wenn sie im Arbeitsspeicher zwischengespeichert wäre.

DAX-Funktionen (Data Analysis Expressions) für Zeitintelligenz sind aggregationssensibel. Die folgende Abfrage trifft auf die Aggregation, da die DATESYTD-Funktion eine Tabelle mit CalendarDay-Werten generiert, und die Aggregationstabelle verfügt über eine Granularität, die die Gruppierkriterien in der Datumstabelle abdeckt. Dies ist ein Beispiel für einen Tabellenwertfilter für die CALCULATE-Funktion, der mit Aggregationen verwendet werden kann.

Aggregation basierend auf GroupBy-Spalten
Hadoop-basierte Big Data-Modelle weisen unterschiedliche Eigenschaften als dimensionale Modelle auf. Um Verknüpfungen zwischen großen Tabellen zu vermeiden, verwenden Big Data-Modelle häufig keine Beziehungen, sondern denormalieren Sie Dimensionsattribute für Faktentabellen. Sie können solche Big Data-Modelle für interaktive Analysen entsperren, indem Sie Aggregationen basierend auf GroupBy-Spalten verwenden.
Die folgende Tabelle enthält die zu aggregierende numerische Spalte "Movement ". Alle anderen Spalten sind Attribute, nach denen gruppiert werden soll. Die Tabelle enthält IoT-Daten und eine massive Anzahl von Zeilen. Der Speichermodus ist DirectQuery. Anfragen an die Datenquelle sind aufgrund der schieren Menge langsam, da sie das gesamte Modell abdecken.
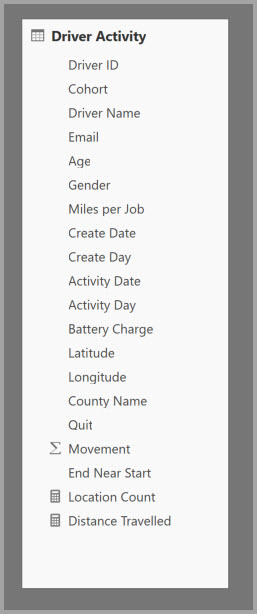
Um die interaktive Analyse für dieses Modell zu aktivieren, können Sie eine Aggregationstabelle hinzufügen, die nach den meisten Attributen gruppiert wird, schließt jedoch die Attribute mit hoher Kardinalität wie Längengrad und Breitengrad aus. Dadurch wird die Anzahl der Zeilen erheblich reduziert und ist klein genug, um bequem in einen Speichercache einzupassen.
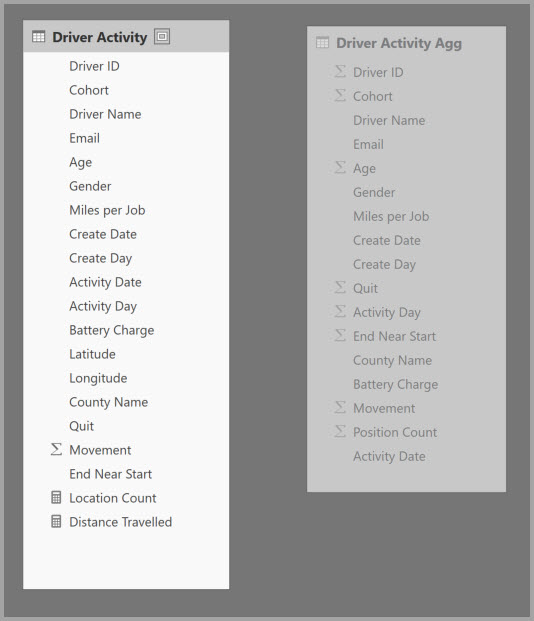
Sie definieren die Aggregationszuordnungen für die Tabelle " Treiberaktivität Agg " im Dialogfeld " Aggregationen verwalten ".
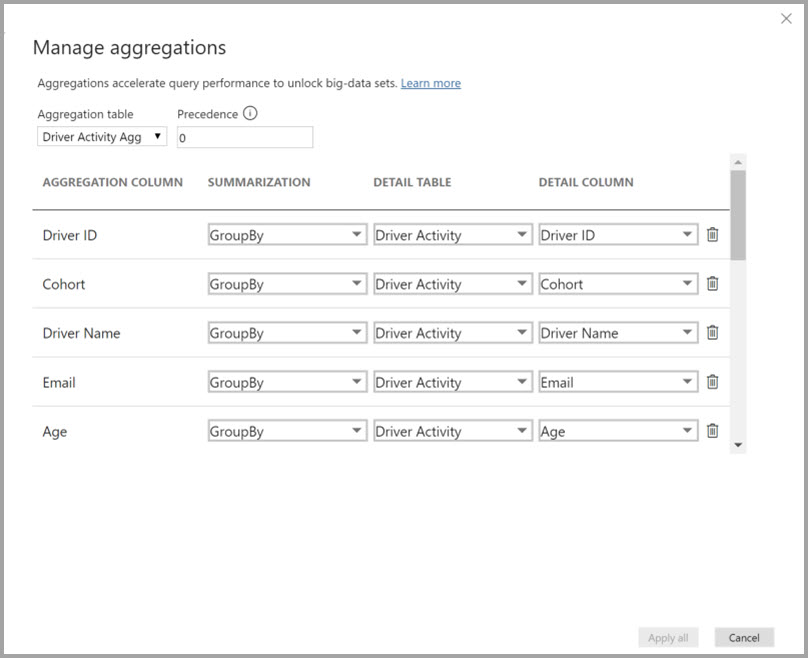
In Aggregationen, die auf GroupBy-Spalten basieren, sind die GroupBy-Einträge nicht optional. Ohne sie werden die Aggregationen nicht getroffen. Dies unterscheidet sich von der Verwendung von Aggregationen basierend auf Beziehungen, bei denen die GroupBy-Einträge optional sind.
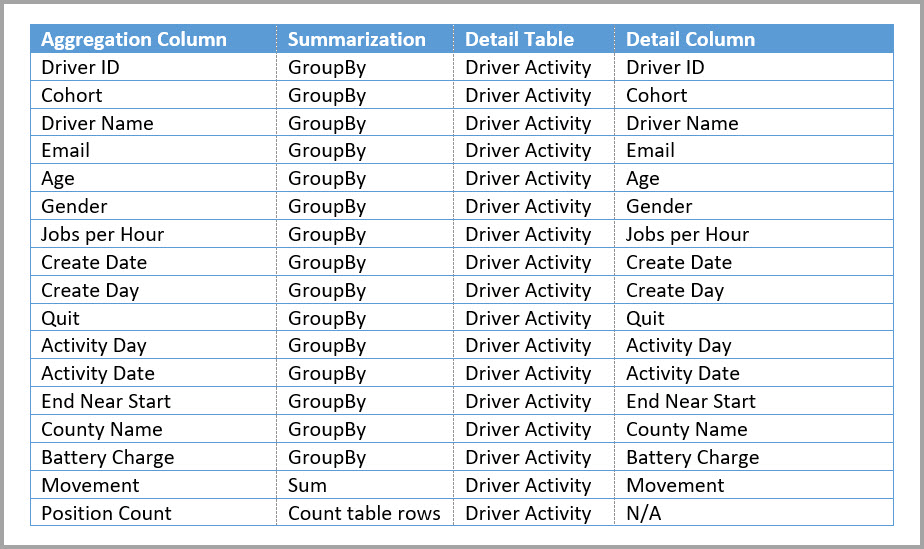
In der folgenden Tabelle sind die Aggregationen für die Tabelle " Driver Activity Agg " aufgeführt.
Sie können den Speichermodus der aggregierten Tabelle " Treiberaktivität Agg " auf "Importieren" festlegen.
GroupBy-Aggregationsabfrage (Beispiel)
Die folgende Abfrage trifft auf die Aggregation, da die Spalte " Aktivitätsdatum " von der Aggregationstabelle abgedeckt wird. Die Funktion COUNTROWS verwendet die Aggregation "gezählte Tabellenzeilen".

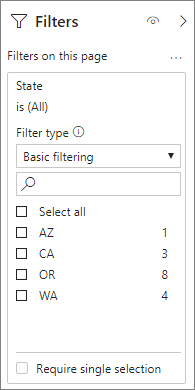
Insbesondere für Modelle, die Filterattribute in Faktentabellen enthalten, empfiehlt es sich, Zeilenanzahl-Aggregationen zu verwenden. Power BI kann Abfragen mithilfe von COUNTROWS an das Modell senden, wenn sie vom Benutzer nicht explizit angefordert wird. Das Filterdialogfeld zeigt beispielsweise die Anzahl der Zeilen für jeden Wert an.
Kombinierte Aggregationstechniken
Sie können die Beziehungen und GroupBy-Spaltentechniken für Aggregationen kombinieren. Aggregationen, die auf Beziehungen basieren, können erfordern, dass die denormalisierten Dimensionstabellen in mehrere Tabellen aufgeteilt werden. Wenn dies für bestimmte Dimensionstabellen kostspielig oder unpraktisch ist, können Sie die erforderlichen Attribute in der Aggregationstabelle für diese Dimensionen replizieren und Beziehungen für andere verwenden.
Das folgende Modell repliziert beispielsweise Monat, Quartal, Semester und Jahr in der Tabelle " Sales Agg ". Es gibt keine Beziehung zwischen Sales Agg und der Tabelle "Datum ", aber es gibt Beziehungen zu Kunden - und Produktunterkategorie. Der Speichermodus von Sales Agg ist Import.
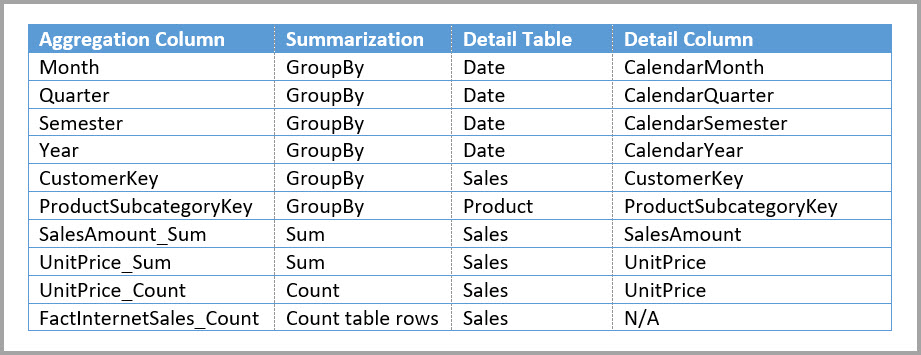
In der folgenden Tabelle sind die Einträge aufgeführt, die im Dialogfeld "Aggregationen verwalten " für die Tabelle "Sales Agg " festgelegt sind. Die GroupBy-Einträge, bei denen "Date" die Detailtabelle ist, sind obligatorisch, um Aggregationen für Abfragen zu treffen, die nach den Date-Attributen gruppiert werden. Wie im vorherigen Beispiel wirken sich die GroupBy-Einträge für CustomerKey und ProductSubcategoryKey nicht auf Aggregationstreffer aus, mit Ausnahme von DISTINCTCOUNT, aufgrund des Vorhandenseins von Beziehungen.
Kombinierte Aggregationsabfragebeispiele
Die folgende Abfrage ist relevant für die Aggregation, da die Aggregationstabelle CalendarMonth abdeckt und CategoryName über eins-zu-viele Beziehungen zugänglich ist. SalesAmount verwendet die SUMME-Aggregation .

Die folgende Abfrage trifft nicht auf die Aggregation, da die Aggregationstabelle " CalendarDay" nicht abdeckt.

Die folgende Zeitintelligenzabfrage trifft nicht auf die Aggregation, da die DATESYTD-Funktion eine Tabelle mit CalendarDay-Werten generiert, und die Aggregationstabelle deckt CalendarDay nicht ab.

Aggregationsrangfolge
Mithilfe der Aggregationsrangfolge können mehrere Aggregationstabellen von einer einzelnen Unterabfrage berücksichtigt werden.
Das folgende Beispiel ist ein zusammengesetztes Modell mit mehreren Quellen:
- Die Tabelle "Driver Activity DirectQuery" enthält mehr als eine Billion Zeilen von IoT-Daten, die aus einem großen Datensystem stammen. Es ermöglicht Drillthrough-Abfragen zur Anzeige einzelner IoT-Daten in vordefinierten Filterkontexten.
- Die Tabelle "Driver Activity Agg " ist eine zwischengeschaltete Aggregationstabelle im DirectQuery-Modus. Sie enthält mehr als eine Milliarde Zeilen in Azure Synapse Analytics (ehemals SQL Data Warehouse) und ist an der Quelle mithilfe von Columnstore-Indizes optimiert.
- Die Driver Activity Agg2 Import-Tabelle weist eine hohe Granularität auf, da es nur wenige Gruppierungsattribute mit geringer Kardinalität gibt. Die Anzahl der Zeilen kann so niedrig wie Tausende sein, sodass sie problemlos in einen Speichercache passen kann. Diese Attribute werden von einem hochrangigen Managerdashboard verwendet, sodass Abfragen, die darauf verweisen, so schnell wie möglich sein sollten.
Hinweis
DirectQuery-Aggregationstabellen, die eine andere Datenquelle aus der Detailtabelle verwenden, werden nur unterstützt, wenn die Aggregationstabelle aus einer SQL Server-, Azure SQL- oder Azure Synapse Analytics (früher SQL Data Warehouse)-Quelle stammt.
Der Speicherbedarf dieses Modells ist relativ klein, aber es entsperrt ein riesiges Modell. Sie stellt eine ausgewogene Architektur dar, da sie die Abfragelast über Komponenten der Architektur verteilt, wobei sie basierend auf ihren Stärken genutzt werden.
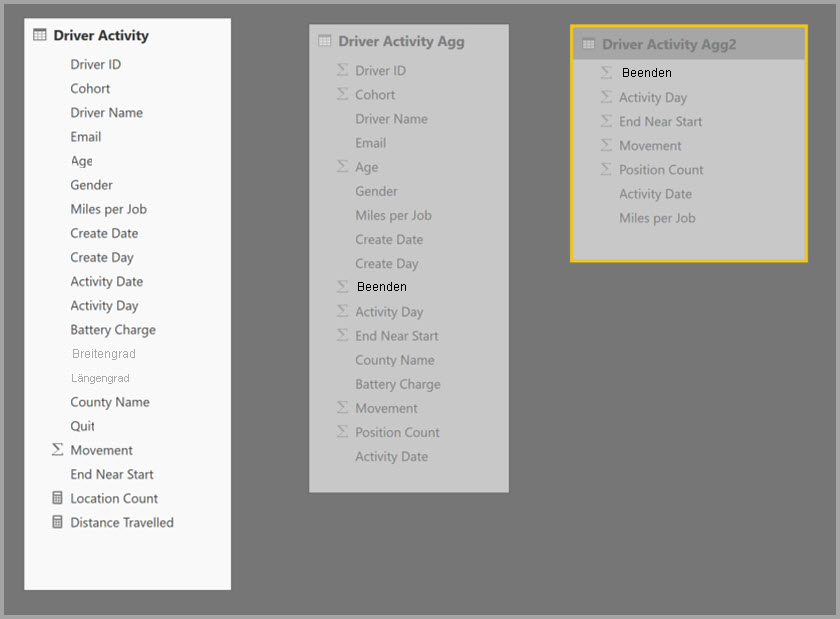
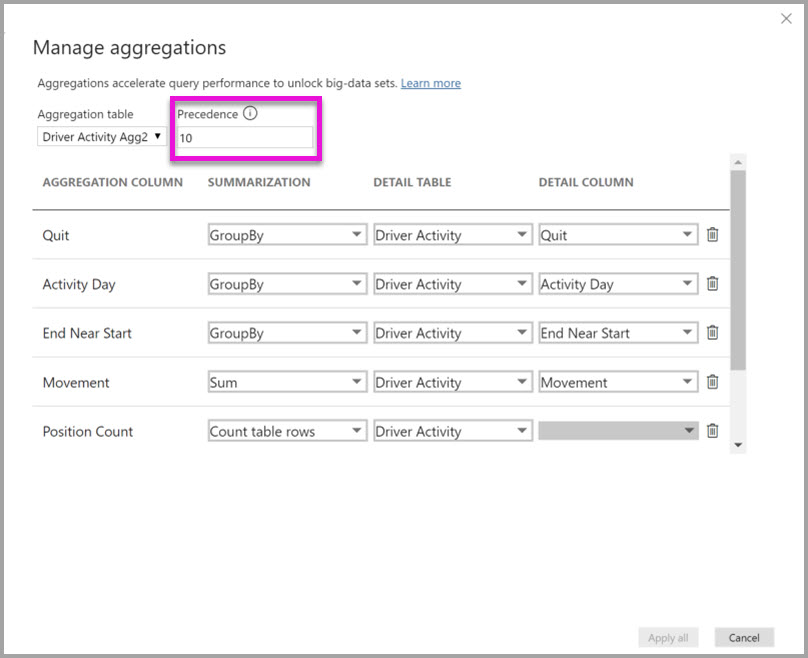
Das Dialogfeld Verwaltete Aggregationen für Treiberaktivität Agg2 setzt das Feld Precedence auf 10, das höher ist als bei Treiberaktivität Agg. Die höhere Rangfolgeneinstellung bedeutet, dass Abfragen, die Aggregationen verwenden, zuerst "Driver Activity Agg2 " in Betracht ziehen. Unterabfragen, die nicht der Granularität entsprechen, die von Treiberaktivität Agg2 beantwortet werden können, können stattdessen die Treiberaktivität Agg verwenden. Detailabfragen, die nicht von einer Aggregationstabelle beantwortet werden können, können zur Treiberaktivität geleitet werden.
Die in der Spalte " Detailtabelle " angegebene Tabelle ist "Treiberaktivität" und nicht "Driver Activity Agg", da verkettete Aggregationen nicht zulässig sind.
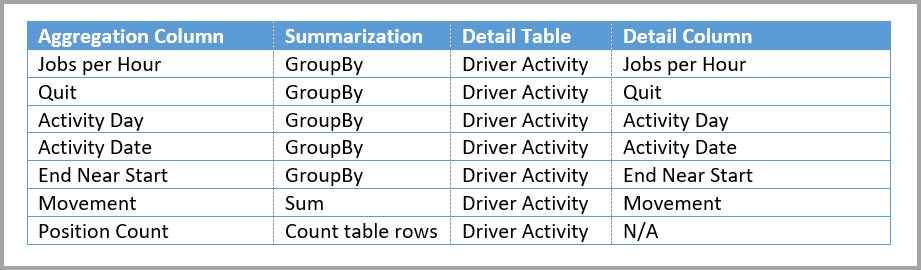
Die folgende Tabelle zeigt die Aggregationen für die Tabelle "Driver Activity Agg2 ".
Ermitteln, ob Abfragen Aggregationen treffen oder verfehlen
SQL Profiler kann erkennen, ob Abfragen vom Speichermodul für den Cache im Arbeitsspeicher zurückgegeben oder von DirectQuery an die Datenquelle übertragen werden. Sie können denselben Prozess verwenden, um zu erkennen, ob Aggregationen getroffen werden. Weitere Informationen finden Sie unter Abfragen, die den Cache treffen oder verpassen.
SQL Profiler stellt auch das Query Processing\Aggregate Table Rewrite Query erweiterte Ereignis bereit.
Der folgende JSON-Codeausschnitt zeigt ein Beispiel für die Ausgabe des Ereignisses, wenn eine Aggregation verwendet wird.
- matchingResult zeigt, dass die Unterabfrage eine Aggregation verwendet hat.
- dataRequest zeigt die GroupBy-Spalten und aggregierten Spalten an, die die Unterabfrage verwendet.
- die Zuordnung zeigt die Spalten in der Aggregationstabelle an, die zugeordnet wurden.

Caches synchron halten
Aggregationen, die DirectQuery-, Import- und/oder Dualspeichermodi kombinieren, können unterschiedliche Daten zurückgeben, es sei denn, der Speichercache wird mit den Quelldaten synchronisiert. Die Abfrageausführung versucht beispielsweise nicht, Datenprobleme zu maskieren, indem DirectQuery-Ergebnisse gefiltert werden, um zwischengespeicherte Werte abzugleichen. Es gibt etablierte Techniken zur Behandlung solcher Probleme an der Quelle, falls erforderlich. Leistungsoptimierungen sollten nur auf Arten verwendet werden, die Ihre Fähigkeit zur Erfüllung geschäftlicher Anforderungen nicht gefährden. Es liegt in Ihrer Verantwortung, Ihre Datenflüsse zu kennen und entsprechend zu entwerfen.
Überlegungen und Einschränkungen
Aggregationen unterstützen keine dynamischen M-Abfrageparameter.
Ab August 2022 ignoriert Power BI aufgrund von Änderungen der Funktionalität Aggregationstabellen im Importmodus mit SSO(Single Sign-On) aktivierten Datenquellen aufgrund potenzieller Sicherheitsrisiken. Um eine optimale Abfrageleistung mit Aggregationen sicherzustellen, empfiehlt es sich, SSO für diese Datenquellen zu deaktivieren.
Gemeinschaft
Power BI verfügt über eine lebendige Community, in der MVPs, BI-Experten und Peers Expertise in Diskussionsgruppen, Videos, Blogs und mehr teilen. Wenn Sie mehr über Aggregationen erfahren, sollten Sie sich diese zusätzlichen Ressourcen ansehen: