API-gesteuerte eingehende Bereitstellung mit Azure Logic Apps
In diesem Tutorial wird beschrieben, wie Sie den Azure Logic Apps-Workflow verwenden, um die API-gesteuerte eingehende Bereitstellung von Microsoft Entra ID zu implementieren. Mit den Schritten in diesem Tutorial können Sie eine CSV-Datei mit Personaldaten in eine Massenanforderungspayload konvertieren und diese an den Microsoft Entra-API-Endpunkt /bulkUpload für die Bereitstellung senden. Der Artikel enthält auch Anweisungen dazu, wie dasselbe Integrationsmuster mit jedem Datensatzsystem verwendet werden kann.
Integrationsszenario
Geschäftsanforderung
Ihr Datensatzsystem generiert in regelmäßigen Abständen CSV-Dateiexporte mit Workerdaten. Sie möchten eine Integration implementieren, die Daten aus der CSV-Datei liest und automatisch Benutzerkonten in Ihrem Zielverzeichnis bereitstellt (lokales Active Directory für Hybridbenutzer*innen und Microsoft Entra ID für reine Cloudbenutzer*innen).
Implementierungsanforderung
Aus Sicht der Implementierung:
- Sie möchten einen Azure Logic Apps-Workflow verwenden, um Daten aus den CSV-Dateiexporten zu lesen, die in einer Azure-Dateifreigabe verfügbar sind, und sie an den API-Endpunkt für die eingehende Bereitstellung zu senden.
- In Ihrem Azure Logic Apps-Workflow möchten Sie nicht die komplexe Logik zum Vergleichen von Identitätsdaten zwischen Ihrem Datensatzsystem und dem Zielverzeichnis implementieren.
- Sie möchten den Microsoft Entra-Bereitstellungsdienst verwenden, um Ihre von der IT verwalteten Bereitstellungsregeln anzuwenden, um Konten im Zielverzeichnis automatisch zu erstellen/zu aktualisieren/zu aktivieren/zu deaktivieren (lokales Active Directory oder Microsoft Entra-ID).

Variationen des Integrationsszenarios
Während in diesem Tutorial eine CSV-Datei als Datensatzsystem verwendet wird, können Sie den Azure Logic Apps-Beispielworkflow anpassen, um Daten aus einem beliebigen Datensatzsystem zu lesen. Azure Logic Apps bietet eine Vielzahl von integrierten Connectors und verwalteten Connectors mit vordefinierten Triggern und Aktionen, die Sie in Ihrem Integrationsworkflow verwenden können.
Im Folgenden finden Sie eine Liste der Variationen von Unternehmensintegrationsszenarien, bei denen die API-gesteuerte eingehende Bereitstellung mit einem Logic Apps-Workflow implementiert werden kann.
| # | Datensatzsystem | Integrationsleitfaden zur Verwendung von Logic Apps zum Lesen von Quelldaten |
|---|---|---|
| 1 | Dateien, die auf dem SFTP-Server gespeichert sind | Verwenden Sie entweder den integrierten SFTP-Connector oder den verwalteten SFTP-SSH-Connector, um Daten aus Dateien zu lesen, die auf dem SFTP-Server gespeichert sind. |
| 2 | Datenbanktabelle | Wenn Sie einen Azure SQL-Server oder eine lokale SQL Server-Instanz verwenden, nutzen Sie den SQL Server-Connector, um Ihre Tabellendaten zu lesen. Wenn Sie eine Oracle-Datenbank nutzen, verwenden Sie den Connector für Oracle-Datenbank, um Ihre Tabellendaten zu lesen. |
| 3 | Lokale und in der Cloud gehostete Instanz von SAP S/4 HANA oder klassische lokale SAP-Systeme wie R/3 und ECC |
Verwenden Sie den SAP-Connector, um Identitätsdaten aus Ihrem SAP-System abzurufen. Beispiele zum Konfigurieren dieses Connectors finden Sie in den gängigen SAP-Integrationsszenarien mit Azure Logic Apps und dem SAP-Connector. |
| 4 | IBM MQ | Verwenden Sie den IBM MQ-Connector, um Bereitstellungsnachrichten aus der Warteschlange zu empfangen. |
| 5 | Dynamics 365 Human Resources | Verwenden Sie den Dataverse-Connector, um Daten aus Dataverse-Tabellen zu lesen, die von Microsoft Dynamics 365 Human Resources verwendet werden. |
| 6 | Alle Systeme, die REST-APIs verfügbar machen | Wenn Sie in der Logic Apps-Connectorbibliothek keinen Connector für Ihr Datensatzsystem finden, können Sie einen eigenen benutzerdefinierten Connector erstellen, um Daten aus Ihrem Datensatzsystem zu lesen. |
Wenden Sie nach dem Lesen der Quelldaten Ihre Vorverarbeitungsregeln an, und konvertieren Sie die Ausgabe Ihres Datensatzsystems in eine Massenanforderung, die an den Microsoft Entra-API-Endpunkt bulkUpload für die Bereitstellung gesendet werden kann.
Wichtig
Wenn Sie Ihren API-gesteuerten Workflow für eingehende Bereitstellung und Logic Apps-Integration für die Community freigeben möchten, erstellen Sie eine Logik-App-Vorlage, dokumentieren Sie die Schritte zur Verwendung, und übermitteln Sie einen Pull Request zur Aufnahme in das GitHub-Repositoryentra-id-inbound-provisioning.
Zur Verwendung dieses Lernprogramms
Die Logic Apps-Bereitstellungsvorlage, die im GitHub-Repository für die eingehende Bereitstellung von Microsoft Entra veröffentlicht wurde, automatisiert verschiedene Aufgaben. Sie enthält außerdem Logik für die Verarbeitung großer CSV-Dateien und das Aufteilen der Massenanforderung, sodass pro Anforderung 50 Datensätze gesendet werden. Hier erfahren Sie, wie Sie sie testen und an Ihre Integrationsanforderungen anpassen können.
Hinweis
Der Azure Logic Apps-Beispielworkflow wird als Implementierungsreferenz unverändert bereitgestellt. Wenn Sie Fragen dazu haben oder den Workflow erweitern möchten, verwenden Sie das GitHub-Projektrepository.
| # | Automatisierungstask | Implementierungsleitfaden | Erweiterte Anpassung |
|---|---|---|---|
| 1 | Liest Workerdaten aus der CSV-Datei. | Der Logic Apps-Workflow verwendet eine Azure-Funktion, um die in einer Azure-Dateifreigabe gespeicherte CSV-Datei zu lesen. Die Azure-Funktion konvertiert CSV-Daten in das JSON-Format. Wenn das CSV-Dateiformat abweicht, aktualisieren Sie die Workflowschritte „JSON analysieren“ und „SCIMUser erstellen“. | Wenn Sie ein anderes Datensatzsystem verwenden, lesen Sie die Anleitungen zum Anpassen des Logic Apps-Workflows im Abschnitt Variationen des Integrationsszenarios. |
| 2 | Vorverarbeiten und Konvertieren von Daten in das SCIM-Format. | Standardmäßig konvertiert der Logic Apps-Workflow jeden Datensatz in der CSV-Datei in eine SCIM Core User- und Enterprise User-Darstellung. Wenn Sie benutzerdefinierte SCIM-Schemaerweiterungen verwenden möchten, aktualisieren Sie den Schritt „SCIMUser erstellen“, um Ihre benutzerdefinierten SCIM-Schemaerweiterungen einzuschließen. | Wenn Sie C#-Code für erweiterte Formatierung und Datenüberprüfung ausführen möchten, verwenden Sie benutzerdefinierte Azure Functions-Instanzen. |
| 3 | Verwenden der richtigen Authentifizierungsmethode | Sie können entweder einen Dienstprinzipal oder eine verwaltete Identität verwenden, um auf die API für die eingehende Bereitstellung zuzugreifen. Aktualisieren Sie den Schritt „SCIMBulkPayload an API-Endpunkt senden“ mit der richtigen Authentifizierungsmethode. | - |
| 4 | Bereitstellen von Konten in einer lokalen Active Directory-Instanz oder Microsoft Entra ID. | Konfigurieren der API-gesteuerten eingehenden Bereitstellungs-App. Dadurch wird ein eindeutiger /bulkUpload-API-Endpunkt generiert. Aktualisieren Sie den Schritt „SCIMBulkPayload an API-Endpunkt senden“, um den richtigen bulkUpload-API-Endpunkt zu verwenden. | Wenn Sie Massenanforderungen mit benutzerdefiniertem SCIM-Schema verwenden möchten, erweitern Sie das Schema der Bereitstellungs-App, um Ihre benutzerdefinierten SCIM-Schemaattribute einzubeziehen. |
| 5 | Überprüfen Sie die Bereitstellungsprotokolle, und wiederholen Sie die Bereitstellung für fehlerhafte Datensätze. | Diese Automatisierung ist im Logic Apps-Beispielworkflow noch nicht implementiert. Informationen zur Implementierung finden Sie in den Bereitstellungsprotokollen der Graph-API. | - |
| 6 | Stellen Sie Ihre Logic Apps-basierte Automatisierung in der Produktion bereit. | Nachdem Sie Ihren API-gesteuerten Bereitstellungsflow überprüft und den Logic Apps-Workflow an Ihre Anforderungen angepasst haben, stellen Sie die Automatisierung in Ihrer Umgebung bereit. | - |
Schritt 1: Erstellen eines Azure Storage-Kontos zum Hosten der CSV-Datei
Die in diesem Abschnitt beschriebenen Schritte sind optional. Wenn Sie bereits über ein vorhandenes Speicherkonto verfügen oder die CSV-Datei aus einer anderen Quelle wie z. B. einer SharePoint-Website oder einer Blob Storage-Instanz lesen möchten, aktualisieren Sie die Logic App-Instanz, sodass sie den Connector Ihrer Wahl verwendet.
- Melden Sie sich beim Azure-Portal mindestens als Anwendungsadministrator an.
- Suchen Sie nach „Speicherkonten“, und erstellen Sie ein neues Speicherkonto.

- Weisen Sie eine Ressourcengruppe zu, und benennen Sie diese.

- Wenn das Speicherkonto erstellt wurde, wechseln Sie zu der Ressource.
- Klicken Sie auf die Menüoption „Dateifreigabe“, und erstellen Sie eine neue Dateifreigabe.

- Vergewissern Sie sich, dass die Erstellung der Dateifreigabe erfolgreich war.

- Laden Sie mithilfe der Uploadoption eine CSV-Beispieldatei in die Dateifreigabe hoch.
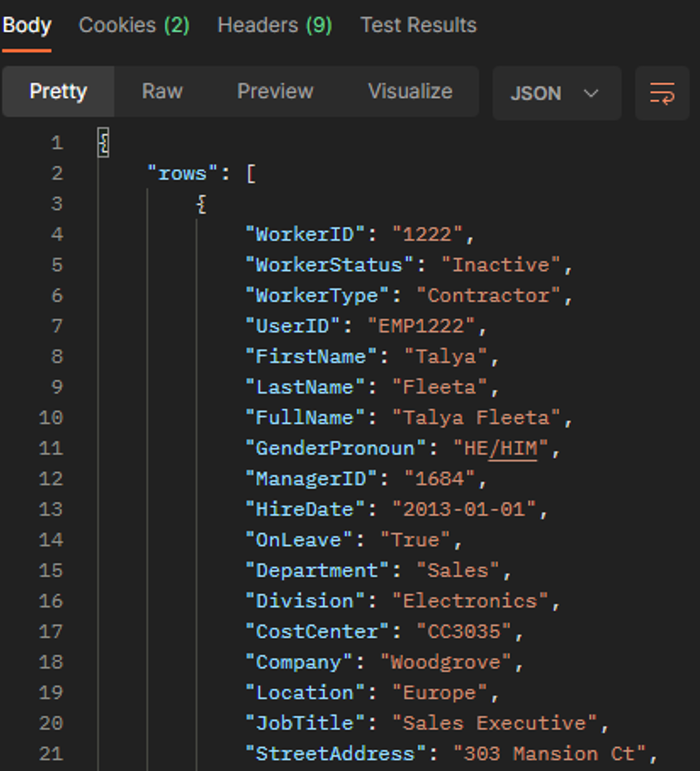
- Hier sehen Sie einen Screenshot der Spalten in der CSV-Datei.






Schritt 2: Konfigurieren des CSV2JSON-Konverters für eine Azure-Funktion
Öffnen Sie die URL zum GitHub-Repository in dem Browser, der mit Ihrem Azure-Portal verknüpft ist: https://github.com/joelbyford/CSVtoJSONcore.
Klicken Sie auf den Link „In Azure bereitstellen“, um diese Azure-Funktion in Ihrem Azure-Mandanten bereitzustellen.

Geben Sie die Ressourcengruppe an, in der diese Azure-Funktion bereitgestellt werden soll.

Wenn der Fehler „Diese Region verfügt über ein Kontingent von 0 Instanzen“ angezeigt wird, wählen Sie eine andere Region aus.
Stellen Sie sicher, dass die Bereitstellung der Azure-Funktion als App Service erfolgreich ist.
Wechseln Sie zur Ressourcengruppe, und öffnen Sie die WebApp-Konfiguration. Stellen Sie sicher, dass sie sich im Zustand „Wird ausgeführt“ befindet. Kopieren Sie den Standarddomänennamen, der der Web-App zugeordnet ist.

Öffnen Sie den Postman-Client, um zu testen, ob der CSVtoJSON-Endpunkt wie erwartet funktioniert. Fügen Sie den Domänennamen ein, den Sie im vorherigen Schritt kopiert haben. Verwenden Sie „text/csv“ als Inhaltstyp, und senden Sie eine CSV-Beispieldatei im Anforderungstext an den Endpunkt:
https://[your-domain-name]/csvtojson
Wenn die Bereitstellung der Azure-Funktion erfolgreich ist, erhalten Sie in der Antwort eine JSON-Version der CSV-Datei mit dem Statuscode „200 OK“.
Damit Logic Apps diese Azure-Funktion aufrufen kann, geben Sie in der CORS-Einstellung für die WebApp ein Sternchen (*) ein, und speichern Sie die Konfiguration.







Schritt 3: Konfigurieren der API-gesteuerten eingehenden Benutzerbereitstellung
- Konfigurieren Sie die API-gesteuerte eingehende Benutzerbereitstellung.
Schritt 4: Konfigurieren Ihres Azure Logic Apps-Workflows
Klicken Sie auf die Schaltfläche unten, um die Azure Resource Manager-Vorlage für den Logic Apps-Workflow „CSV2SCIMBulkUpload“ bereitzustellen.
Aktualisieren Sie in den Details der Instanz die hervorgehobenen Elemente, und kopieren Sie dabei die Werte aus den vorherigen Schritten.

Um den Wert für den Parameter
Azurefile_access Keyzu erhalten, öffnen Sie Ihr Azure Files-Speicherkonto, und kopieren Sie den Zugriffsschlüssel, den Sie unter „Sicherheit und Netzwerk“ finden.

Klicken Sie auf „Überprüfen und erstellen“, um die Bereitstellung zu starten.
Wenn die Bereitstellung abgeschlossen ist, wird folgende Meldung angezeigt.




Schritt 5: Konfigurieren der systemseitig zugewiesenen verwalteten Identität
- Öffnen Sie das Blatt „Identität“ in den Einstellungen Ihres Logic Apps-Workflows.
- Aktivieren Sie die systemseitig zugewiesene verwaltete Identität.

- Sie werden aufgefordert, die Verwendung der verwalteten Identität zu bestätigen. Klicken Sie auf Ja.
- Gewähren Sie der verwalteten Identität Berechtigungen zum Ausführen von Massenuploads.

Schritt 6: Überprüfen und Anpassen der Workflowschritte
Öffnen Sie die Logik-App in der Designeransicht.
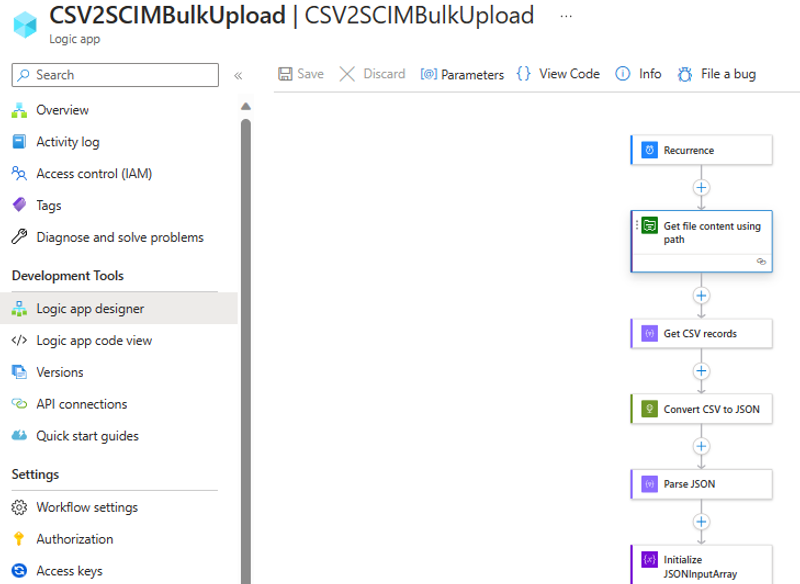
Überprüfen Sie die Konfiguration jedes Schritts im Workflow, um sicherzustellen, dass sie richtig ist.
Öffnen Sie den Schritt „Dateiinhalt anhand des Pfads abrufen“, und ändern Sie ihn so, dass er zur Azure File Storage-Instanz führt.

Aktualisieren Sie die Verbindung bei Bedarf.
Stellen Sie sicher, dass Ihr Schritt „CSV in JSON konvertieren“ auf die richtige Web App-Instanz für die Azure-Funktion zeigt.

Wenn die Inhalte oder Header Ihrer CSV-Datei anders lauten, aktualisieren Sie den Schritt „JSON analysieren“ mit der JSON-Ausgabe, die Sie aus dem API-Aufruf der Azure-Funktion abrufen können. Verwenden Sie die Postman-Ausgabe aus Schritt 2.

Stellen Sie im Schritt „SCIMUser erstellen“ sicher, dass die CSV-Felder den SCIM-Attributen, die für die Verarbeitung verwendet werden, richtig zugeordnet wurden.

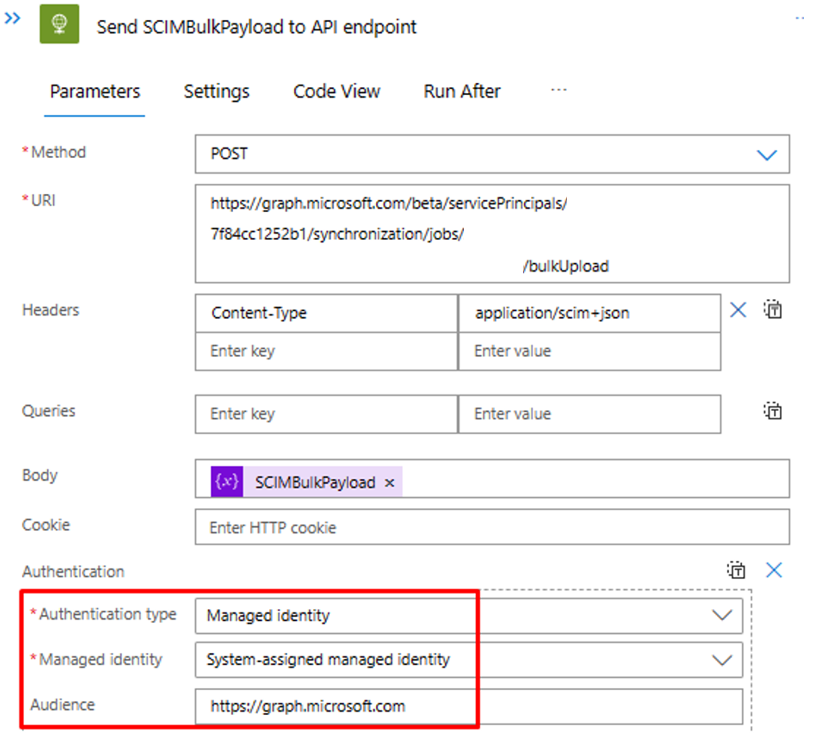
Stellen Sie im Schritt „SCIMBulkPayload an API-Endpunkt senden“ sicher, dass Sie den richtigen API-Endpunkt und den richtigen Authentifizierungsmechanismus verwenden.






Schritt 7: Ausführen des Triggers und Testen des Logic Apps-Workflows
- Klicken Sie in der Version „Allgemein verfügbar“ des Logic Apps-Designers auf „Trigger ausführen“, um den Workflow manuell auszuführen.

- Überprüfen Sie nach Abschluss der Ausführung, welche Aktion Logic Apps in jeder Iteration ausgeführt hat.
- In der letzten Iteration sollten Sie sehen, dass Logic Apps Daten in den API-Endpunkt für die eingehende Bereitstellung hochlädt. Suchen Sie nach dem Statuscode
202 Accept. Sie können die Massenuploadanforderung kopieren, einfügen und überprüfen.


Nächste Schritte
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für