Unterteilen Sie eine Aufgabe, die komplexe Verarbeitungsvorgänge ausführt, in eine Reihe von wiederverwendbaren separaten Elementen. Dies kann die Leistung, Skalierbarkeit und Wiederverwendbarkeit der ersten Schritte verbessern, indem Taskelemente, die Verarbeitungsvorgänge ausführen, unabhängig voneinander bereitgestellt und skaliert werden können. Das Muster vom Typ „Pipes und Filter“ ermöglicht ein hohes Maß an Modularität.
Kontext und Problem
Sie haben eine Pipeline von sequenziellen Aufgaben, die Sie verarbeiten müssen. Ein einfacher, aber unflexibler Ansatz zur Implementierung dieser Anwendung besteht darin, diese Verarbeitung in einem monolithischen Modul durchzuführen. Dieser Ansatz würde jedoch die Möglichkeiten zur Umgestaltung des Codes, zu seiner Optimierung und Wiederverwendung einschränken, wenn an anderer Stelle in der Anwendung Teile des gleichen Verarbeitungsmechanismus erforderlich sind.
Das folgende Diagramm veranschaulicht eines der Probleme bei der Verarbeitung von Daten unter Verwendung eines monolithischen Ansatzes: die Unfähigkeit, Code über mehrere Pipelines hinweg wiederzuverwenden. In diesem Beispiel empfängt und verarbeitet eine Anwendung Daten aus zwei Quellen. Ein separates Modul verarbeitet die Daten von jeweils einer Quelle und führt dazu eine Reihe von Aufgaben zur Transformation der Daten aus, bevor es das Ergebnis an die Geschäftslogik der Anwendung übergibt.
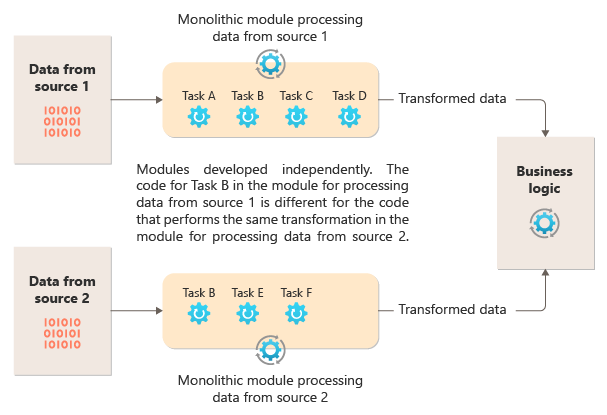
Einige der Aufgaben, die die monolithischen Module ausführen, sind funktionell ähnlich. Der Code muss jedoch in beiden Modulen wiederholt werden und ist wahrscheinlich innerhalb des Moduls eng eingebunden. Abgesehen davon, dass die Logik nicht wiederverwendet werden kann, birgt dieser Ansatz ein Risiko, wenn sich die Anforderungen ändern. Sie müssen daran denken, den Code an beiden Stellen zu aktualisieren.
Es gibt noch weitere Herausforderungen im Zusammenhang mit einer monolithischen Implementierung, die nichts mit mehreren Pipelines oder der Wiederverwendung zu tun haben. Bei einem monolithischen Ansatz haben Sie nicht die Möglichkeit, bestimmte Aufgaben in verschiedenen Umgebungen auszuführen oder unabhängig voneinander zu skalieren. Einige Aufgaben können rechenintensiv sein. In diesem Fall wäre eine Ausführung auf leistungsstarker Hardware oder die parallele Ausführung mehrerer Instanzen von Vorteil. Andere Aufgaben haben möglicherweise nicht dieselben Anforderungen. Darüber hinaus ist es bei einem monolithischen Ansatz schwierig, Aufgaben neu anzuordnen oder neue Aufgaben in die Pipeline einzufügen. Bei solchen Änderungen ist eine erneute Überprüfung der gesamten Pipeline erforderlich.
Lösung
Unterteilen Sie die für jeden Datenstrom erforderliche Verarbeitung in eine Reihe von separaten Komponenten (oder Filtern), die jeweils einen einzelnen Task ausführen. Zusammengesetzte Aufgaben sollten statt eines Filters mehrere Filter verwenden. Die Filter werden zu Pipelines zusammengestellt, indem die Filter mit Pipes verbunden werden. Filter sind unabhängig, eigenständig und normalerweise zustandslos. Filter empfangen Nachrichten aus einer eingehenden Pipe und veröffentlichen Nachrichten in einer anderen ausgehenden Pipe. Filter können die Nachricht transformieren oder anhand eines oder mehrerer Kriterien testen, um bedingte Logik einzuschließen. Pipes nehmen kein Routing vor und führen keine andere Logik aus. Sie verbinden lediglich die Filter und übergeben die Ausgabenachricht von einem Filter als Eingabe an den nächsten.
Filter agieren unabhängig und wissen nichts von anderen Filtern. Sie kennen nur ihre Eingabe- und Ausgabeschemas. Daher können die Filter in beliebiger Reihenfolge angeordnet werden, solange das Eingabeschema für jeden Filter mit dem Ausgabeschema für den vorherigen Filter übereinstimmt. Durch die Verwendung eines standardisierten Schemas für alle Filter ist es besser möglich, Filter neu anzuordnen. Die Architektur vom Typ „Pipe und Filter“ fördert die Wiederverwendung der Komposition.
Die lose Kopplung von Filtern erleichtert Folgendes:
- Erstellen neuer Pipelines, die aus vorhandenen Filtern bestehen
- Aktualisieren oder Ersetzen von Logik in einzelnen Filtern
- Neuanordnung von Filtern bei Bedarf
- Ausführung von Filtern auf unterschiedlicher Hardware, sofern erforderlich
- Parallele Ausführung von Filtern
Dieses Diagramm zeigt eine Lösung, die mit Pipes und Filtern implementiert ist:
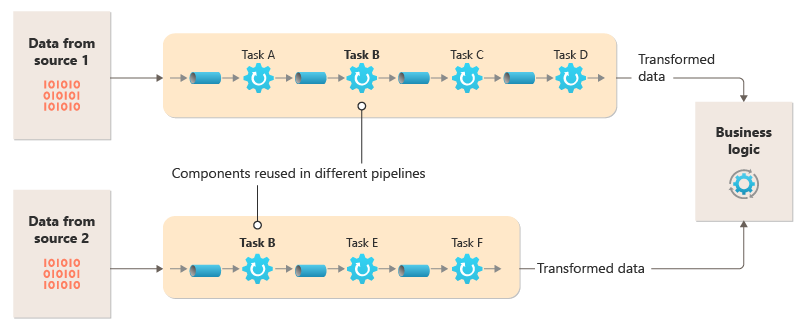
Die Verarbeitungszeit für eine einzelne Anforderung hängt von der Geschwindigkeit des langsamsten Filters in der Pipeline ab. Ein oder mehrere Filter könnten einen Engpass darstellen, insbesondere bei einer großen Anzahl von Anforderungen in einem Datenstrom aus einer bestimmten Datenquelle. Dank der Möglichkeit, parallele Instanzen von langsamen Filtern auszuführen, kann das System die Last verteilen und den Durchsatz verbessern.
Da die Filter auf verschiedenen Compute-Instanzen ausgeführt werden können, können sie unabhängig voneinander skaliert werden und die Elastizität vieler Cloudumgebungen nutzen. Ein rechenintensiver Filter kann auf leistungsstarker Hardware ausgeführt werden, während andere weniger anspruchsvolle Filter auf preiswerterer Standardhardware gehostet werden können. Da sich die Filter nicht einmal in demselben Rechenzentrum oder an demselben geografischen Standort befinden müssen, kann jedes Element in einer Pipeline in einer Umgebung nahe bei den benötigten Ressourcen ausgeführt werden. Diese Maßnahmen erfordern spezifische Entwurfstechniken wie Messaging, Multithreading usw., um die Flexibilität der einzelnen Pipes oder Filter zu maximieren. Dieses Diagramm zeigt ein Beispiel für die Pipeline für die Daten aus Quelle 1
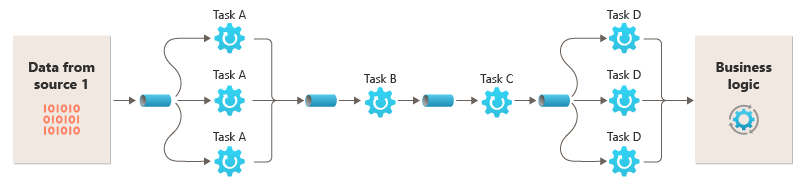
Wenn die Ein- und Ausgabe eines Filters als Datenstrom strukturiert sind, ist es möglich, die Verarbeitung für jeden Filter parallel durchzuführen. Der erste Filter in der Pipeline kann mit der Durchführung der zugehörigen Tasks beginnen und die entsprechenden Ergebnisse ausgeben, die direkt an den nächsten Filter in der Sequenz übergeben werden, bevor der erste Filter seine Tasks abgeschlossen hat.
Die Verwendung des Musters „Pipes und Filter“ in Verbindung mit dem Muster „Kompensierende Transaktion“ ist eine alternative Vorgehensweise zur Implementierung verteilter Transaktionen. Eine verteilte Transaktion kann in einzelne, kompensierbare Tasks zerlegt werden, die mit einem für das Muster „Kompensierende Transaktion“ implementierten Filter implementiert werden können. Die Filter in einer Pipeline können als separate gehostete Tasks implementiert werden, die in der Nähe der Daten, die sie verwalten, ausgeführt werden.
Probleme und Überlegungen
Beachten Sie die folgenden Punkte bei Ihrer Entscheidung, wie dieses Muster implementiert werden soll:
Monolithisch. Dieses Muster wird in der Regel als monolithische Pipeline implementiert. Daher sollte bei jeglichen Änderungen die gesamte Filterkette End-to-End-getestet werden. Außerdem muss die Fehlertoleranz für den gesamten Prozess berücksichtigt werden. Schlägt ein Filter oder eine Pipe fehl, dann schlägt wahrscheinlich die gesamte Pipeline fehl.
Komplexität. Durch die zusätzliche Flexibilität, die dieses Muster bietet, erhöht sich möglicherweise auch die Komplexität, insbesondere wenn die Filter in einer Pipeline auf verschiedenen Server verteilt sind.
Zuverlässigkeit: Verwenden Sie eine Infrastruktur, die sicherstellt, dass die zwischen Filtern in einer Pipe fließenden Daten nicht verloren gehen.
Idempotenz: Wenn ein Filter in einer Pipeline nach dem Empfang einer Nachricht Fehler verursacht und der Task auf einer anderen Instanz des Filters neu geplant wird, kann es sein, dass ein Teil des Tasks bereits abgeschlossen ist. Wenn dieser Task einige Punkte hinsichtlich des globalen Status aktualisiert (z.B. die in einer Datenbank gespeicherten Informationen), kann das Update wiederholt werden. Ein ähnliches Problem kann auftreten, wenn ein Filter fehlschlägt, nachdem er seine Ergebnisse für den nächsten Filter bereitstellt hat, jedoch bevor er angibt, dass die Aufgabe erfolgreich abgeschlossen wurde. In diesen Fällen könnte diese Aufgabe von einer anderen Instanz des Filters wiederholt werden, sodass die gleichen Ergebnisse zweimal bereitgestellt würden. Dies könnte dazu führen, dass nachfolgende Filter in der Pipeline dieselben Daten zweimal verarbeiten. Deshalb sollten Filter in einer Pipeline so entworfen sein, dass sie idempotent sind. Weitere Informationen finden Sie unter Idempotenzmuster im Blog von Jonathan Oliver.
Wiederholte Nachrichten: Wenn ein Filter in einer Pipeline Fehler verursacht, nachdem eine Nachricht für die nächste Phase der Pipeline bereitgestellt wurde, wird möglicherweise eine weitere Instanz des Filters ausgeführt und eine Kopie derselben Nachricht für die Pipeline bereitgestellt. Dies könnte dazu führen, dass zwei Instanzen derselben Nachricht an den nächsten Filter übergeben werden. Um dies zu vermeiden, sollten die Pipeline doppelte Nachrichten erkennen und entfernen.
Hinweis
Wenn Sie die Pipeline mithilfe von Nachrichtenwarteschlangen (z.B. Microsoft Azure Service Bus-Warteschlangen) implementieren, bietet die Message Queuing-Infrastruktur möglicherweise eine Funktion zur automatischen Erkennung und Entfernung doppelter Nachrichten.
Kontext und Status: In einer Pipeline werden die einzelnen Filter im Wesentlichen separat ausgeführt und sollten nicht auf Annahmen zur Art, wie diese aufgerufen wurden, basieren. Das bedeutet, dass jeder Filter für die Durchführung des jeweiligen Tasks mit ausreichendem Kontext versehen werden sollte. Dieser Kontext kann eine große Menge an Statusinformationen beinhalten. Wenn Filter einen externen Zustand verwenden, z. B. Daten in einer Datenbank oder einem externen Speicher, müssen Sie die Auswirkungen auf die Leistung berücksichtigen. Jeder Filter muss diesen Zustand laden, verarbeiten und aufrechterhalten, was einen Mehraufwand gegenüber Lösungen bedeutet, die den externen Zustand nur einmal laden.
Nachrichtentoleranz. Filter müssen tolerant gegenüber Daten in der eingehenden Nachricht sein, die sie nicht bearbeiten. Sie bearbeiten die für sie relevanten Daten und ignorieren andere Daten und übergeben sie unverändert in der Ausgabenachricht.
Fehlerbehandlung – Jeder Filter muss bestimmen, was im Falle eines kritischen Fehlers zu tun ist. Der Filter muss ermitteln, ob die Pipeline fehlschlagen soll oder ob er die Ausnahme weitergibt.
Verwendung dieses Musters
Verwenden Sie dieses Muster in folgenden Fällen:
Die von einer Anwendung benötigten Verarbeitungsschritte können mühelos in eine Reihe von unabhängigen Schritten zerlegt werden.
Die von einer Anwendung ausgeführten Verarbeitungsschritte stellen unterschiedliche Anforderungen an die Skalierbarkeit.
Hinweis
Es ist möglich, Filter zu gruppieren, die im selben Prozess skaliert werden sollen. Weitere Informationen finden Sie unter Muster „Computeressourcenkonsolidierung“.
Sie benötigen die Flexibilität, um das Neuanordnen der Verarbeitungsschritte zu ermöglichen, die die Anwendung ausführt, oder um der Funktion das Hinzufügen und Entfernen von Schritten zu ermöglichen.
Die Systemleistung kann durch die Verteilung der Verarbeitungsschritte auf verschiedene Server verbessert werden.
Es ist eine zuverlässige Lösung erforderlich, die die Auswirkungen von Fehlern in einem Schritt während der Datenverarbeitung minimiert.
Dieses Muster ist in folgenden Fällen möglicherweise nicht geeignet:
Die Anwendung folgt einem Anforderungs-Antwort-Muster.
Die Aufgabenverarbeitung muss im Rahmen einer anfänglichen Anforderung abgeschlossen werden, beispielsweise in einem Anforderungs-/Antwortszenario.
Die von einer Anwendung ausgeführten Verarbeitungsschritte sind nicht unabhängig voneinander oder müssen gemeinsam im Rahmen derselben Transaktion ausgeführt werden.
Die Menge an Kontext- oder Statusinformationen, die für einen Schritt erforderlich sind, macht diese Vorgehensweise ineffizient. Statusinformationen können stattdessen möglicherweise in einer Datenbank gespeichert werden. Verwenden Sie diese Strategie jedoch nicht, wenn die zusätzliche Auslastung der Datenbank zu übermäßigen Konflikten führt.
Workloadentwurf
Ein Architekt sollte evaluieren, wie das Pipes- und Filter-Muster im Design seiner Workloads verwendet werden kann, um die Ziele und Prinzipien zu erreichen, die in den Säulen des Azure Well-Architected Framework behandelt werden. Zum Beispiel:
| Säule | So unterstützt dieses Muster die Säulenziele |
|---|---|
| Zuverlässigkeitsdesignentscheidungen tragen dazu bei, dass Ihre Workload ausfallsicher wird und dass sie nach einem Ausfall wieder in einen voll funktionsfähigen Zustand zurückkehrt. | Die alleinige Zuständigkeit jeder Stufe ermöglicht eine konzentrierte Aufmerksamkeit und vermeidet die Ablenkung durch eine gemischte Datenverarbeitung. - RE:01 Einfachheit - RE:07 Hintergrundaufträge |
Berücksichtigen Sie wie bei jeder Designentscheidung alle Kompromisse im Hinblick auf die Ziele der anderen Säulen, die mit diesem Muster eingeführt werden könnten.
Beispiel
Sie können eine Reihe von Nachrichtenwarteschlangen verwenden, um die für die Implementierung einer Pipeline erforderliche Infrastruktur bereitzustellen. Eine anfängliche Nachrichtenwarteschlange empfängt unverarbeitete Nachrichten, die zum Anfangselement der Pipes und Filtermusterimplementierung werden. Eine als Filteraufgabe implementierte Komponente wartet auf eine Nachricht in dieser Warteschlange, führt ihre Arbeit aus und stellt eine neue oder transformierte Nachricht dann für die nächste Warteschlange in der Sequenz bereit. Eine weitere Filteraufgabe kann Nachrichten in dieser Warteschlange überwachen, sie verarbeiten, die Ergebnisse in einer anderen Warteschlange veröffentlichen usw. bis zum letzten Schritt, der den Pipes- und Filterprozess beendet. Dieses Diagramm veranschaulicht eine Pipeline, die Nachrichtenwarteschlangen verwendet:

Mithilfe dieses Musters könnte eine Bildverarbeitungspipeline implementiert werden. Wenn Ihre Workload ein Bild verwendet, kann das Bild eine Reihe von weitgehend unabhängigen und neu sortierter Filtern durchlaufen, um Aktionen auszuführen, darunter:
- Inhaltsmoderation
- Größenänderung
- Wasserzeichen
- Neuausrichtung
- Entfernen von Exif-Metadaten
- Veröffentlichung des Content Delivery Network (CDN)
In diesem Beispiel können die Filter als einzeln bereitgestellte Azure Functions oder sogar eine einzelne Azure Function-App implementiert werden, die jeden Filter als isolierte Bereitstellung enthält. Die Verwendung von Azure Function-Triggern, Eingabe- und Ausgabebindungen kann den Filtercode vereinfachen und automatisch mit einer warteschlangenbasierten Pipe mithilfe einer Anspruchsprüfung des zu verarbeitenden Bildes funktionieren.

Nachfolgend sehen Sie ein Beispiel dafür, wie ein Filter, der als Azure Function implementiert wurde, aus einer Queue Storage-Pipeline mit einer Anspruchsprüfung für das Bild ausgelöst wird und wie eine neue Anspruchsprüfung in eine andere Queue Storage-Pipeline geschrieben wird. Wir haben die Implementierung aus Platzgründen durch Pseudocode in Kommentaren ersetzt. Weiteren Code wie diesen finden Sie in der Demonstration des Pipes- and Filters-Musters, das auf GitHub verfügbar ist.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Hinweis
Das Spring Integration Framework verfügt über eine Implementierung des Pipes- und Filtermusters.
Nächste Schritte
Möglicherweise finden Sie die folgenden Ressourcen hilfreich, wenn Sie dieses Muster implementieren:
- Eine Demonstration des Pipes- und Filtermusters mithilfe des Bildverarbeitungsszenarios ist auf GitHub verfügbar.
- Idempotency Patterns (Idempotenzmuster) im Blog von Jonathan Oliver.
Zugehörige Ressourcen
Die folgenden Muster sind unter Umständen bei der Implementierung dieses Musters ebenfalls relevant:
- Claim Check-Muster: Eine mithilfe einer Warteschlange implementierte Pipeline enthält möglicherweise nicht das tatsächliche Element, das über die Filter gesendet wird, sondern einen Zeiger auf die zu verarbeitenden Daten. Im Beispiel wird eine Anspruchsprüfung in Azure Queue Storage für Bilder verwendet, die in Azure Blob Storage gespeichert sind.
- Muster „Konkurrierende Consumer“: Eine Pipeline kann mehrere Instanzen eines oder mehrerer Filter enthalten. Dieser Ansatz ist nützlich, um parallele Instanzen von langsamen Filtern auszuführen. Er ermöglicht es dem System, die Last zu verteilen und den Durchsatz zu verbessern. Jede Instanz eines Filters konkurriert mit anderen Instanzen um die Eingabe, wobei zwei Instanzen eines Filters nicht die gleichen Daten verarbeiten können sollten. In diesem Artikel wird der Ansatz erläutert.
- Muster „Computeressourcenkonsolidierung“: Filter, die im selben Prozess skaliert werden sollen, können gruppiert werden. Dieser Artikel enthält weitere Informationen über die Vor- und Nachteile dieser Vorgehensweise.
- Muster „Kompensierende Transaktion“: Ein Filter kann als umkehrbarer Vorgang oder mit einem kompensierenden Vorgang, der im Fehlerfall den Zustand einer früheren Version wiederherstellt, implementiert werden. In diesem Artikel wird erläutert, wie Sie dieses Muster implementieren können, um letztliche Konsistenz zu erhalten oder zu erreichen.
- Pipes and Filters – Enterprise Integration Patterns.