Diese Schnellstarteinleitung beginnt für die Erstellung eines Singletons im Azure-Portal auf der Azure SQL-Seite.
Navigieren Sie zur Seite SQL-Bereitstellungsoption auswählen.
Behalten Sie unter SQL-Datenbanken für Einzeldatenbank den festgelegten Wert Ressourcentyp bei, und wählen Sie Erstellen aus.

Wählen Sie auf der Registerkarte Grundeinstellungen des Formulars SQL-Datenbank erstellen unter Projektdetails das gewünschte Abonnement für Azure aus.
Wählen Sie bei Ressourcengruppe die Option Neu erstellen aus, geben Sie myResourceGroup ein, und wählen Sie OK aus.
Geben Sie für Datenbankname den Namen mySampleDatabase ein.
Wählen Sie unter Server die Option Neu erstellen aus, und füllen Sie das Formular Neuer Server mit den folgenden Werten aus:
- Servername: Geben Sie mysqlserver ein, und fügen Sie einige weitere Zeichen hinzu, um einen eindeutigen Wert zu erhalten. Wir können keinen exakten Servernamen zur Verwendung angeben, weil Servernamen für alle Server in Azure global eindeutig sein müssen (und nicht nur innerhalb eines Abonnements eindeutig sind). Geben Sie einen Namen wie mysqlserver12345 ein. Das Portal teilt Ihnen mit, ob dieser verfügbar ist.
- Serveradministratoranmeldung: Geben Sie azureuser ein.
- Kennwort: Geben Sie ein geeignetes Kennwort ein, und wiederholen Sie die Eingabe im Feld Kennwort bestätigen.
- Standort: Wählen Sie in der Dropdownliste einen Standort aus.
Klicken Sie auf OK.
Wählen Sie unter Compute + Speicher die Option Datenbank konfigurieren aus.
Mit dieser Schnellstartanleitung wird eine Hyperscale-Datenbank erstellt. Wählen Sie für die Dienstebene die Option Hyperscale aus.

Wählen Sie unter Computehardware die Option Konfiguration ändern aus. Überprüfen Sie die verfügbaren Hardwarekonfigurationen, und wählen Sie die am besten geeignete Konfiguration für Ihre Datenbank aus. In diesem Beispiel wählen Sie die Konfiguration Standard-Serie (Gen5) aus.
Wählen Sie OK aus, um die Hardwaregeneration zu bestätigen.
Optional passen Sie den Schieberegler für virtuelle Kerne an, wenn Sie die Anzahl virtueller Kerne für Ihre Datenbank erhöhen möchten. In diesem Beispiel wählen wir 2 virtuelle Kerne.
Passen Sie den Schieberegler für sekundäre Hochverfügbarkeitsreplikate (High Availability, HA) an, um ein Hochverfügbarkeitsreplikat (High Availability, HA) zu erstellen.
Wählen Sie Übernehmen.
Berücksichtigen Sie beim Erstellen einer Hyperscale-Datenbank sorgfältig die Konfigurationsoption für Sicherungsspeicherredundanz. Die Speicherredundanz kann nur während der Erstellung einer Hyperscale-Datenbank angegeben werden. Sie können lokalredundanten, zonenredundanten oder georedundanten Speicher wählen. Die ausgewählte Speicherredundanzoption wird während der gesamten Lebensdauer der Datenbank sowohl für die Datenspeicherredundanz als auch für die Sicherungsspeicherredundanz verwendet. Vorhandene Datenbanken können mithilfe einer Datenbankkopie oder einer Point-in-Time-Wiederherstellung zu einer anderen Speicherredundanz migriert werden.
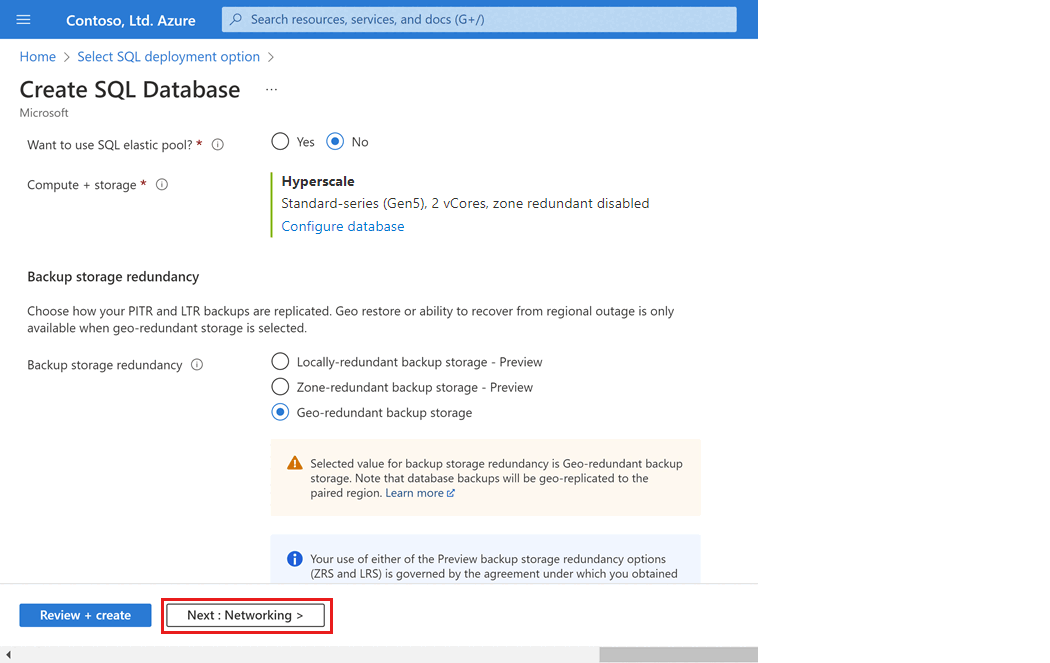
Klicken Sie auf Weiter: Netzwerk aus (im unteren Bereich der Seite).
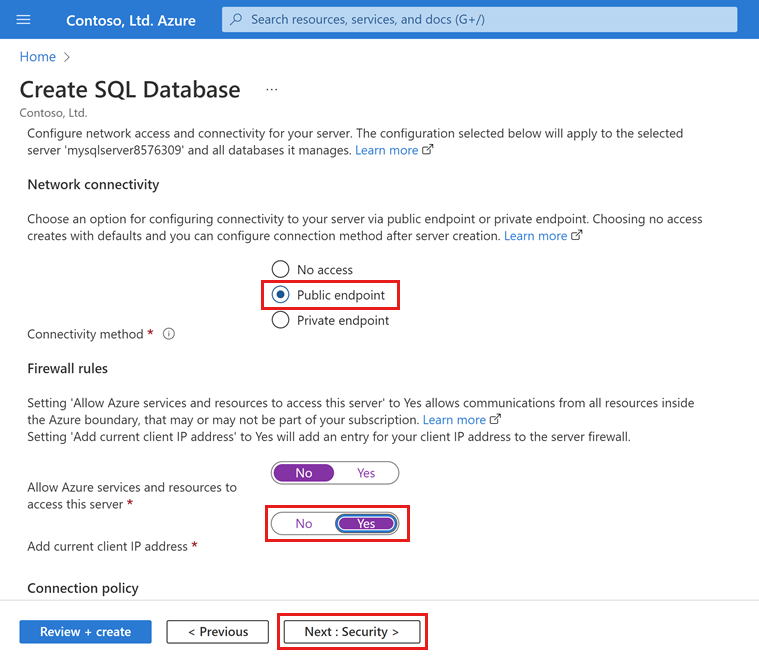
Wählen Sie auf der Registerkarte Netzwerk als Konnektivitätsmethode die Option Öffentlicher Endpunkt aus.
Legen Sie bei Firewallregeln die Option Aktuelle Client-IP-Adresse hinzufügen auf Ja fest. Behalten Sie für Azure-Diensten und -Ressourcen den Zugriff auf diese Servergruppe gestatten den Wert Nein bei.
Wählen Sie Weiter: Sicherheit unten auf der Seite aus.
Aktivieren Sie optional Microsoft Defender für SQL.
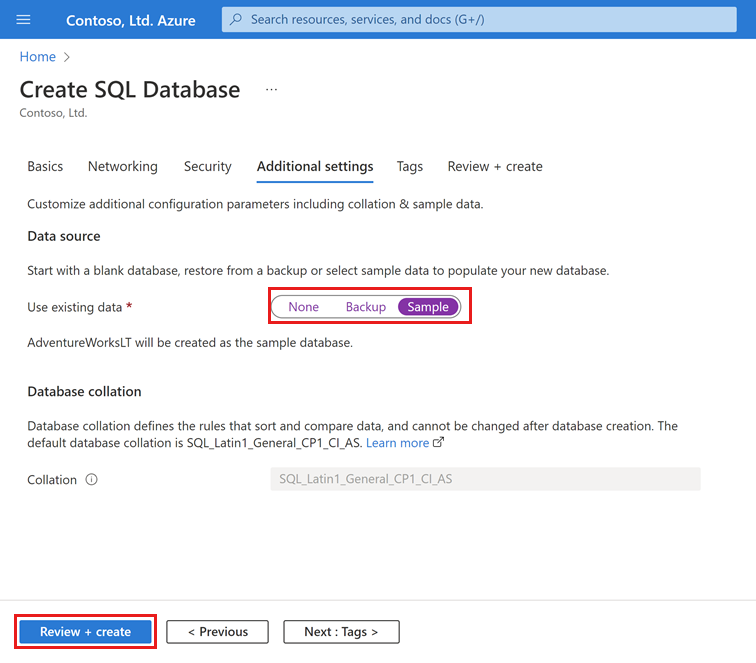
Klicken Sie auf Weiter: Zusätzliche Einstellungen aus (im unteren Bereich der Seite).
Wählen Sie auf der Registerkarte Zusätzliche Einstellungen im Abschnitt Datenquelle unter Vorhandene Daten verwenden die Option Beispiel aus. Dadurch wird eine AdventureWorksLT-Beispieldatenbank erstellt, sodass es einige Tabellen und Daten, die Sie abfragen und mit denen Sie experimentieren können, im Gegensatz zu einer leeren Datenbank gibt.
Wählen Sie unten auf der Seite die Option Überprüfen + erstellen aus:
Wählen Sie nach Überprüfung auf der Seite Überprüfen + erstellen die Option Erstellenaus.
Die Azure CLI-Codeblöcke in diesem Abschnitt erstellen eine Ressourcengruppe, einen Server, eine Einzeldatenbank und eine IP-Firewallregel auf Serverebene für den Zugriff auf den Server. Notieren Sie sich den Namen der generierten Ressourcengruppe und des generierten Servers, um diese Ressourcen später verwalten zu können.
Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein kostenloses Azure-Konto, bevor Sie beginnen.
Vorbereiten der Umgebung für die Azure CLI
Verwenden Sie die Bash-Umgebung in Azure Cloud Shell. Weitere Informationen finden Sie unter Schnellstart für Bash in Azure Cloud Shell.

Wenn Sie CLI-Referenzbefehle lieber lokal ausführen, installieren Sie die Azure CLI. Wenn Sie Windows oder macOS ausführen, sollten Sie die Azure CLI in einem Docker-Container ausführen. Weitere Informationen finden Sie unter Ausführen der Azure CLI in einem Docker-Container.
Wenn Sie eine lokale Installation verwenden, melden Sie sich mithilfe des Befehls az login bei der Azure CLI an. Führen Sie die in Ihrem Terminal angezeigten Schritte aus, um den Authentifizierungsprozess abzuschließen. Informationen zu anderen Anmeldeoptionen finden Sie unter Anmelden mit der Azure CLI.
Installieren Sie die Azure CLI-Erweiterung beim ersten Einsatz, wenn Sie dazu aufgefordert werden. Weitere Informationen zu Erweiterungen finden Sie unter Verwenden von Erweiterungen mit der Azure CLI.
Führen Sie az version aus, um die installierte Version und die abhängigen Bibliotheken zu ermitteln. Führen Sie az upgrade aus, um das Upgrade auf die aktuelle Version durchzuführen.
Starten von Azure Cloud Shell
Azure Cloud Shell ist eine kostenlose interaktive Shell, mit der Sie die Schritte in diesem Artikel durchführen können. Sie verfügt über allgemeine vorinstallierte Tools und ist für die Verwendung mit Ihrem Konto konfiguriert.
Wählen Sie zum Öffnen von Cloud Shell oben rechts in einem Codeblock die Option Ausprobieren aus. Sie können Cloud Shell auch auf einem separaten Browsertab starten, indem Sie zu https://shell.azure.com navigieren.
Überprüfen Sie nach dem Öffnen von Cloud Shell, ob Bash für Ihre Umgebung ausgewählt ist. In nachfolgenden Sitzungen wird die Azure CLI in einer Bash-Umgebung verwendet. Wählen Sie Kopieren aus, um die Blöcke mit dem Code zu kopieren. Fügen Sie ihn anschließend in Cloud Shell ein, und drücken Sie die EINGABETASTE, um ihn auszuführen.
Anmelden bei Azure
Cloud Shell wird automatisch unter dem Konto authentifiziert, mit dem die Anmeldung anfänglich erfolgt ist. Verwenden Sie das folgende Skript, um sich mit einem anderen Abonnement anzumelden, und ersetzen Sie <Subscription ID> durch Ihre Azure-Abonnement-ID. Wenn Sie kein Azure-Abonnement haben, erstellen Sie ein kostenloses Azure-Konto, bevor Sie beginnen.
subscription="<subscriptionId>" # add subscription here
az account set -s $subscription # ...or use 'az login'
Weitere Informationen finden Sie unter Festlegen des aktiven Abonnements oder unter Interaktives Anmelden.
Festlegen von Parameterwerten
Mit den folgenden Werten werden in nachfolgenden Befehlen die Datenbank und die erforderlichen Ressourcen erstellt. Servernamen müssen innerhalb von Azure global eindeutig sein, damit die Funktion „$RANDOM“ zum Erstellen des Servernamens verwendet werden kann.
Bevor Sie den Beispielcode ausführen, ändern Sie die location entsprechend ihrer Umgebung. Ersetzen Sie 0.0.0.0 durch den IP-Adressbereich, der Ihrer spezifischen Umgebung entspricht. Verwenden Sie die öffentliche IP-Adresse Ihres Computers, um den Zugriff auf den Server nur auf Ihre IP-Adresse zu beschränken.
# <FullScript>
# Create a single database and configure a firewall rule
# <SetParameterValues>
# Variable block
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroup="msdocs-azuresql-rg-$randomIdentifier"
tag="create-and-configure-database"
server="msdocs-azuresql-server-$randomIdentifier"
database="msdocsazuresqldb$randomIdentifier"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
let "randomIdentifier=$RANDOM*$RANDOM"
location="East US"
resourceGroupName="myResourceGroup"
tag="create-and-configure-database"
serverName="mysqlserver-$randomIdentifier"
databaseName="mySampleDatabase"
login="azureuser"
password="Pa$$w0rD-$randomIdentifier"
# Specify appropriate IP address values for your environment
# to limit access to the SQL Database server
startIp=0.0.0.0
endIp=0.0.0.0
echo "Using resource group $resourceGroupName with login: $login, password: $password..."
Erstellen einer Ressourcengruppe
Erstellen Sie mithilfe des Befehls az group create eine Ressourcengruppe. Eine Azure-Ressourcengruppe ist ein logischer Container, in dem Azure-Ressourcen bereitgestellt und verwaltet werden. Im folgenden Beispiel wird eine Ressourcengruppe an dem Speicherort erstellt, der für den location-Parameter im vorherigen Schritt angegeben ist:
echo "Creating $resourceGroupName in $location..."
az group create --name $resourceGroupName --location "$location" --tag $tag
Erstellen eines Servers
Erstellen Sie einen logischen Server mit dem Befehl az sql server create.
echo "Creating $serverName in $location..."
az sql server create --name $serverName --resource-group $resourceGroupName --location "$location" --admin-user $login --admin-password $password
Erstellen Sie eine Firewallregel mit dem Befehl az sql server firewall-rule create.
echo "Configuring firewall..."
az sql server firewall-rule create --resource-group $resourceGroupName --server $serverName -n AllowYourIp --start-ip-address $startIp --end-ip-address $endIp
Erstellen einer Einzeldatenbank
Erstellen Sie eine Datenbank in der Hyperscale-Dienstebene mit dem Befehl az sql db create.
Wählen Sie die Einstellung für die backup-storage-redundancy sorgfältig aus, wenn Sie eine Hyperscale-Datenbank erstellen. Die Speicherredundanz kann nur während der Erstellung einer Hyperscale-Datenbank angegeben werden. Sie können lokalredundanten, zonenredundanten oder georedundanten Speicher wählen. Die ausgewählte Speicherredundanzoption wird während der gesamten Lebensdauer der Datenbank sowohl für die Datenspeicherredundanz als auch für die Sicherungsspeicherredundanz verwendet. Vorhandene Datenbanken können mithilfe einer Datenbankkopie oder einer Point-in-Time-Wiederherstellung zu einer anderen Speicherredundanz migriert werden. Zulässige Werte für den backup-storage-redundancy-Parameter sind: Local, Zone und Geo. Sofern nicht anders angegeben, werden Datenbanken für die Verwendung von georedundantem Sicherungsspeicher konfiguriert.
Führen Sie den folgenden Befehl aus, um eine Hyperscale-Datenbank mit AdventureWorksLT-Beispieldaten zu erstellen. Die Datenbank verwendet Hardware der Standard-Serie (Gen5) mit 2 virtuellen Kernen. Für die Datenbank wird georedundanter Sicherungsspeicher verwendet. Der Befehl erstellt auch ein Hochverfügbarkeitsreplikat (High Availability, HA).
az sql db create \
--resource-group $resourceGroupName \
--server $serverName \
--name $databaseName \3
--sample-name AdventureWorksLT \
--edition Hyperscale \
--compute-model Provisioned \
--family Gen5 \
--capacity 2 \
--backup-storage-redundancy Geo \
--ha-replicas 1
Sie können eine Ressourcengruppe, einen Server und eine Einzeldatenbank mithilfe von Azure PowerShell erstellen.
Starten von Azure Cloud Shell
Azure Cloud Shell ist eine kostenlose interaktive Shell, mit der Sie die Schritte in diesem Artikel durchführen können. Sie verfügt über allgemeine vorinstallierte Tools und ist für die Verwendung mit Ihrem Konto konfiguriert.
Wählen Sie zum Öffnen von Cloud Shell oben rechts in einem Codeblock die Option Ausprobieren aus. Sie können Cloud Shell auch auf einem separaten Browsertab starten, indem Sie zu https://shell.azure.com navigieren.
Wenn Cloud Shell geöffnet ist, überprüfen Sie, ob PowerShell für Ihre Umgebung ausgewählt ist. In nachfolgenden Sitzungen wird die Azure-Befehlszeilenschnittstelle in einer PowerShell-Umgebung verwendet. Wählen Sie Kopieren aus, um die Blöcke mit dem Code zu kopieren. Fügen Sie ihn anschließend in Cloud Shell ein, und drücken Sie die EINGABETASTE, um ihn auszuführen.
Festlegen von Parameterwerten
Mit den folgenden Werten werden in nachfolgenden Befehlen die Datenbank und die erforderlichen Ressourcen erstellt. Servernamen müssen innerhalb von Azure global eindeutig sein, damit das Cmdlet „Get-Random“ zum Erstellen des Servernamens verwendet werden kann.
Bevor Sie den Beispielcode ausführen, ändern Sie die location entsprechend ihrer Umgebung. Ersetzen Sie 0.0.0.0 durch den IP-Adressbereich, der Ihrer spezifischen Umgebung entspricht. Verwenden Sie die öffentliche IP-Adresse Ihres Computers, um den Zugriff auf den Server nur auf Ihre IP-Adresse zu beschränken.
# Set variables for your server and database
$resourceGroupName = "myResourceGroup"
$location = "eastus"
$adminLogin = "azureuser"
$password = "Pa$$w0rD-$(Get-Random)"
$serverName = "mysqlserver-$(Get-Random)"
$databaseName = "mySampleDatabase"
# The ip address range that you want to allow to access your server
$startIp = "0.0.0.0"
$endIp = "0.0.0.0"
# Show randomized variables
Write-host "Resource group name is" $resourceGroupName
Write-host "Server name is" $serverName
Write-host "Password is" $password
Ressourcengruppe erstellen
Erstellen Sie mit New-AzResourceGroup eine Azure-Ressourcengruppe. Eine Ressourcengruppe ist ein logischer Container, in dem Azure-Ressourcen bereitgestellt und verwaltet werden.
Write-host "Creating resource group..."
$resourceGroup = New-AzResourceGroup -Name $resourceGroupName -Location $location -Tag @{Owner="SQLDB-Samples"}
$resourceGroup
Erstellen eines Servers
Erstellen Sie einen Server mit dem Cmdlet New-AzSqlServer.
Write-host "Creating primary server..."
$server = New-AzSqlServer -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-Location $location `
-SqlAdministratorCredentials $(New-Object -TypeName System.Management.Automation.PSCredential `
-ArgumentList $adminLogin, $(ConvertTo-SecureString -String $password -AsPlainText -Force))
$server
Erstellen einer Firewallregel
Erstellen Sie eine Serverfirewallregel mit dem Cmdlet New-AzSqlServerFirewallRule.
Write-host "Configuring server firewall rule..."
$serverFirewallRule = New-AzSqlServerFirewallRule -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-FirewallRuleName "AllowedIPs" -StartIpAddress $startIp -EndIpAddress $endIp
$serverFirewallRule
Erstellen einer Einzeldatenbank
Erstellen Sie eine Einzeldatenbank mit dem Cmdlet New-AzSqlDatabase.
Wählen Sie die Einstellung für die BackupStorageRedundancy sorgfältig aus, wenn Sie eine Hyperscale-Datenbank erstellen. Die Speicherredundanz kann nur während der Erstellung einer Hyperscale-Datenbank angegeben werden. Sie können lokalredundanten, zonenredundanten oder georedundanten Speicher wählen. Die ausgewählte Speicherredundanzoption wird während der gesamten Lebensdauer der Datenbank sowohl für die Datenspeicherredundanz als auch für die Sicherungsspeicherredundanz verwendet. Vorhandene Datenbanken können mithilfe einer Datenbankkopie oder einer Point-in-Time-Wiederherstellung zu einer anderen Speicherredundanz migriert werden. Zulässige Werte für den BackupStorageRedundancy-Parameter sind: Local, Zone und Geo. Sofern nicht anders angegeben, werden Datenbanken für die Verwendung von georedundantem Sicherungsspeicher konfiguriert.
Führen Sie den folgenden Befehl aus, um eine Hyperscale-Datenbank mit AdventureWorksLT-Beispieldaten zu erstellen. Die Datenbank verwendet Hardware der Standard-Serie (Gen5) mit 2 virtuellen Kernen. Für die Datenbank wird georedundanter Sicherungsspeicher verwendet. Der Befehl erstellt auch ein Hochverfügbarkeitsreplikat (High Availability, HA).
Write-host "Creating a standard-series (Gen5) 2 vCore Hyperscale database..."
$database = New-AzSqlDatabase -ResourceGroupName $resourceGroupName `
-ServerName $serverName `
-DatabaseName $databaseName `
-Edition Hyperscale `
-ComputeModel Provisioned `
-ComputeGeneration Gen5 `
-VCore 2 `
-MinimumCapacity 2 `
-SampleName "AdventureWorksLT" `
-BackupStorageRedundancy Geo `
-HighAvailabilityReplicaCount 1
$database
Um eine Hyperscale-Datenbank mit Transact-SQL zu erstellen, müssen Sie zuerst in Azure Verbindungsinformationen für einen vorhandenen logischen Server erstellen oder identifizieren.
Erstellen Sie mithilfe von SQL Server Management Studio (SSMS), Azure Data Studio oder einem Client Ihrer Wahl zum Ausführen von Transact-SQL-Befehlen (sqlcmd usw.) eine Verbindung mit der master-Datenbank her.
Wählen Sie die Einstellung für die BACKUP_STORAGE_REDUNDANCY sorgfältig aus, wenn Sie eine Hyperscale-Datenbank erstellen. Die Speicherredundanz kann nur während der Erstellung einer Hyperscale-Datenbank angegeben werden. Sie können lokalredundanten, zonenredundanten oder georedundanten Speicher wählen. Die ausgewählte Speicherredundanzoption wird während der gesamten Lebensdauer der Datenbank sowohl für die Datenspeicherredundanz als auch für die Sicherungsspeicherredundanz verwendet. Vorhandene Datenbanken können mithilfe einer Datenbankkopie oder einer Point-in-Time-Wiederherstellung zu einer anderen Speicherredundanz migriert werden. Zulässige Werte für den BackupStorageRedundancy-Parameter sind: LOCAL, ZONE und GEO. Sofern nicht anders angegeben, werden Datenbanken für die Verwendung von georedundantem Sicherungsspeicher konfiguriert.
Führen Sie den folgenden Transact-SQL-Befehl aus, um eine neue Hyperscale-Datenbank mit Gen 5-Hardware, 2 virtuellen Kernen und georedundantem Sicherungsspeicher zu erstellen. Sie müssen sowohl die Edition als auch das Dienstziel in der CREATE DATABASE-Anweisung angeben. Eine Liste der gültigen Dienstziele finden Sie unter Ressourceneinschränkungen, z. B. HS_Gen5_2.
Mit diesem Beispielcode erstellen Sie eine leere Datenbank. Wenn Sie eine Datenbank mit Beispieldaten erstellen möchten, verwenden Sie die Azure-Portal-, Azure CLI- oder PowerShell-Beispiele in dieser Schnellstartanleitung.
CREATE DATABASE [myHyperscaleDatabase]
(EDITION = 'Hyperscale', SERVICE_OBJECTIVE = 'HS_Gen5_2') WITH BACKUP_STORAGE_REDUNDANCY= 'LOCAL';
GO
Weitere Parameter und Optionen finden Sie unter DATENBANK ERSTELLEN (Transact-SQL).
Um ein oder mehrere Hochverfügbarkeitsreplikate (High Availability, HA) zu Ihrer Datenbank hinzuzufügen, verwenden Sie den Compute- und Speicherbereich für die Datenbank im Azure-Portal, den PowerShell-Befehl Set-AzSqlDatabase oder den Azure CLI-Befehl az sql db update.
Behalten Sie die Ressourcengruppe, den Server und die Einzeldatenbank für die nächsten Schritte bei, und informieren Sie sich darüber, wie Sie für Ihre Datenbank mit unterschiedlichen Methoden die Verbindungsherstellung und Abfragen durchführen.
Wenn Sie die Verwendung dieser Ressourcen beendet haben, können Sie die erstellte Ressourcengruppe löschen. Hierbei werden auch der Server und die darin enthaltene Einzeldatenbank gelöscht.
Weitere Informationen zu Hyperscale-Datenbanken finden Sie in den folgenden Artikeln:






