Konsistenzebenen in Azure Cosmos DB
GILT FÜR: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Tabelle
Tabelle
Verteilte Datenbanken, die auf Replikation angewiesen sind, um Hochverfügbarkeit, niedrige Latenzzeiten oder beides sicherzustellen, bilden den grundlegenden Kompromiss zwischen Lesekonsistenz, Verfügbarkeit, Latenz sowie Durchsatz, wie in dem PACELC-Theorem definiert. Die Linearisierbarkeit oder das Modell für starke Konsistenz ist der Goldstandard bei der Datenprogrammierbarkeit. Aber die höheren Schreiblatenzen, die dadurch entstehen, dass Daten über große Entfernungen repliziert und übertragen werden müssen, verursachen zusätzliche Kosten. Eine starke Konsistenz kann auch Nachteile durch eine geringere Verfügbarkeit (bei Ausfällen) haben, da die Daten nicht in jeder Region repliziert und committet werden können. Die letztliche Konsistenz führt zu einer höheren Verfügbarkeit und einer besseren Leistung, aber es ist schwieriger, Anwendungen zu programmieren, da die Daten möglicherweise nicht in allen Regionen konsistent sind.
Die meisten kommerziell verfügbaren, verteilten NoSQL-Datenbanken, die heute auf dem Markt erhältlich sind, bieten ausschließlich eine hohe und letztliche Konsistenz. Azure Cosmos DB bietet fünf klar definierte Ebenen. Diese sind (von der stärksten bis zur schwächsten Ebene):
Weitere Informationen zur Standardkonsistenzebene finden Sie unter Konfigurieren der Standardkonsistenzebene oder unter Außerkraftsetzen der Standardkonsistenzebene.
Jede Ebene bietet Verfügbarkeits- und Leistungskompromisse. In der folgenden Abbildung sind die verschiedenen Konsistenzebenen als Spektrum dargestellt.
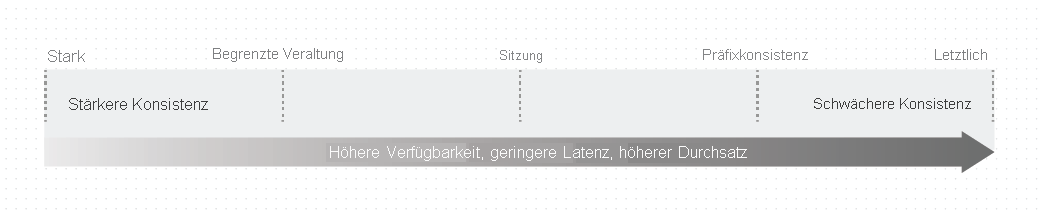
Konsistenzebenen und Azure Cosmos DB-APIs
Azure Cosmos DB bietet für gängige Datenbanken native Unterstützung für Wire Protocol-kompatible APIs. Dazu zählen MongoDB, Apache Cassandra, Apache Gremlin und Azure Table Storage. In der API für Gremlin oder Table wird die im Azure Cosmos DB-Konto konfigurierte Standardkonsistenzebene verwendet. Weitere Informationen zur Konsistenzebenenzuordnung zwischen Apache Cassandra und Azure Cosmos DB finden Sie unter API für Cassandra-Konsistenzzuordnung. Weitere Informationen zur Konsistenzebenenzuordnung zwischen MongoDB und Azure Cosmos DB finden Sie unter API für MongoDB-Konsistenzzuordnung.
Geltungsbereich der Lesekonsistenz
Die Lesekonsistenz gilt für einen einzelnen Lesevorgang innerhalb einer logischen Partition. Der Lesevorgang kann durch einen Remoteclient, eine gespeicherte Prozedur oder einen Auslöser gestartet werden.
Konfigurieren der Standardkonsistenzebene
Sie können die Standardkonsistenzebene für Ihr Azure Cosmos DB-Konto jederzeit konfigurieren. Die für Ihr Konto konfigurierte Standardkonsistenzebene gilt für alle Azure Cosmos DB-Datenbanken und -Container in diesem Konto. Bei allen in einem Container oder einer Datenbank ausgeführten Lesevorgängen und Abfragen wird standardmäßig die angegebene Konsistenzebene verwendet. Stellen Sie beim Ändern der Konsistenz auf Kontoebene Ihre Anwendungen unbedingt erneut bereit, und nehmen Sie alle erforderlichen Codeänderungen vor, um diese Änderungen anzuwenden. Weitere Informationen finden Sie unter Konfigurieren der Standardkonsistenzebene. Sie können auch die Standardkonsistenzebene für eine bestimmte Anforderung außer Kraft setzen. Weitere Informationen hierzu finden Sie im Artikel Außerkraftsetzen der Standardkonsistenzebene.
Tipp
Das Außerkraftsetzen der Standardkonsistenzebene gilt nur für Lesevorgänge innerhalb des SDK-Clients. Ein Konto, das standardmäßig für starke Konsistenz konfiguriert ist, schreibt und repliziert Daten weiterhin synchron in jede Region im Konto. Wenn die SDK-Clientinstanz oder -anforderung dies mit Sitzungskonsistenz oder einer schwächeren Konsistenz überschreibt, werden Lesevorgänge mit einem einzigen Replikat ausgeführt. Weitere Informationen finden Sie unter Konsistenzebenen und Durchsatz.
Wichtig
Nach dem Ändern der Standardkonsinstenzebene müssen alle SDK-Instanzen neu erstellt werden. Dies kann durch einen Neustart der Anwendung erreicht werden. Dadurch wird sichergestellt, dass das SDK die neue Standardkonsistenzebene verwendet.
Garantien in Zusammenhang mit Konsistenzebenen
Azure Cosmos DB garantiert, dass 100 Prozent aller Leseanforderungen die Konsistenzgarantie für jede ausgewählte Konsistenzebene erfüllen. Die genauen Definitionen der fünf Konsistenzebenen in Azure Cosmos DB – unter Verwendung der TLA+-Spezifikationssprache – finden Sie im GitHub-Repository azure-cosmos-tla.
In den folgenden Abschnitten wird die Semantik der fünf Konsistenzebenen beschrieben.
Starke Konsistenz
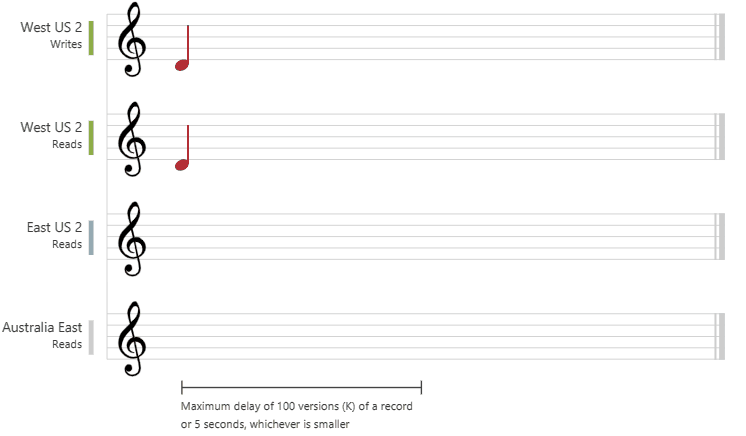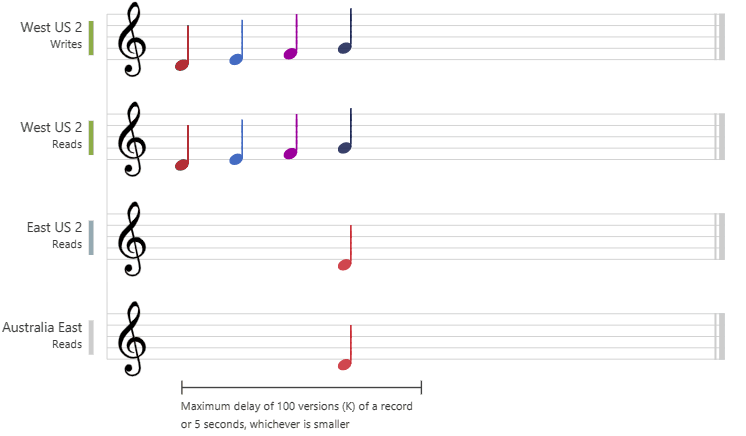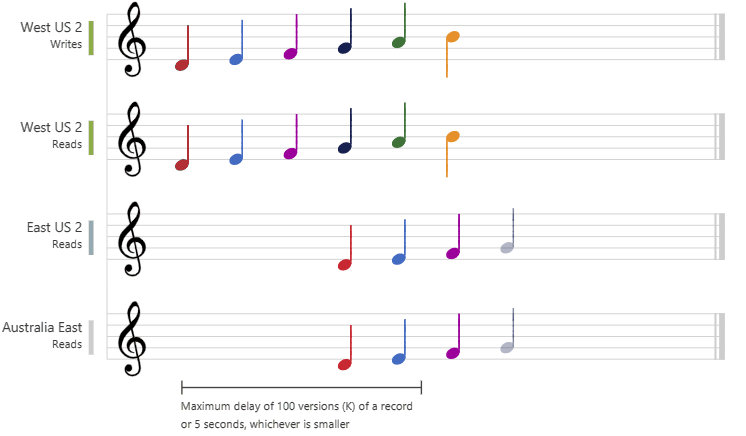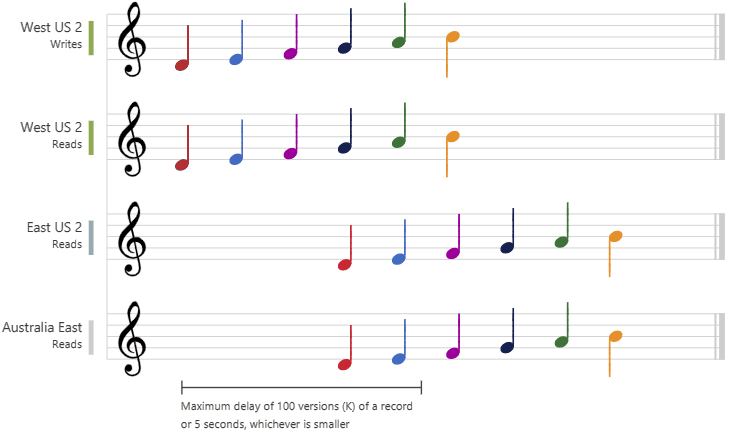
Starke Konsistenz bietet garantierte Linearisierbarkeit. Linearisierbarkeit bedeutet die gleichzeitige Verarbeitung von Anforderungen. Die Lesevorgänge geben garantiert die neueste Version eines Elements zurück, für die ein Commit ausgeführt wurde. Einem Client wird nie ein partieller Schreibvorgang bzw. ein Schreibvorgang, für den kein Commit ausgeführt wurde, angezeigt. Benutzer haben immer die Garantie, dass sie den neuesten Schreibvorgang lesen, für den ein Commit ausgeführt wurde.
In der folgenden Grafik wird die starke Konsistenz anhand von Noten veranschaulicht. Nachdem die Daten in die Region „USA, Westen 2“ geschrieben wurden, erhalten Sie beim Lesen der Daten aus anderen Regionen den neuesten Wert:

Dynamisches Quorum
Unter normalen Umständen gilt für ein Konto mit starker Konsistenz ein Schreibvorgang als committet, wenn alle Regionen bestätigen, dass der Datensatz dort repliziert wurde. Bei Konten mit 3 oder mehr Regionen (einschließlich der Schreibregion) kann das System das Quorum der Regionen jedoch auf eine globale Mehrheit „herabsetzen“, wenn einige Regionen entweder nicht reagieren oder langsam reagieren. Zu diesem Zeitpunkt werden nicht reagierende Regionen aus dem Quorumsatz der Regionen entfernt, um eine starke Konsistenz zu gewährleisten. Sie werden nur dann wieder hinzugefügt, wenn sie mit anderen Regionen konsistent sind und wie erwartet funktionieren. Die Anzahl der Regionen, die möglicherweise aus dem Quorumsatz genommen werden können, hängt von der Gesamtzahl der Regionen ab. In einem Konto mit 3 oder 4 Regionen beträgt die Mehrheit beispielsweise 2 bzw. 3 Regionen, sodass in beiden Fällen nur 1 Region entfernt werden kann. Bei einem Konto mit 5 Regionen beträgt die Mehrheit 3, sodass bis zu 2 nicht reagierende Regionen entfernt werden können. Diese Funktion wird als „dynamisches Quorum“ bezeichnet und kann sowohl die Schreibverfügbarkeit als auch die Replikationswartezeit für Konten mit 3 oder mehr Regionen verbessern.
Hinweis
Wenn Regionen im Zusammenhang mit dem dynamischen Quorum aus dem Quorumsatz entfernt werden, können diese Regionen erst wieder Schreibvorgänge bereitstellen, wenn sie dem Quorum erneut hinzugefügt wurden.
Konsistenzebene „Begrenzte Veraltung“
Bei Konten mit Schreibzugriff auf eine einzelne Region mit zwei oder mehr Regionen werden Daten aus der primären Region in allen sekundären (schreibgeschützten) Regionen repliziert. Bei Konten mit Schreibzugriff auf mehrere Regionen mit zwei oder mehr Regionen werden Daten aus der Region, in die sie ursprünglich geschrieben wurden, in allen anderen Schreibregionen repliziert. In beiden Szenarien kann es gelegentlich zu einer Verzögerung bei der Replikation von einer Region in einer anderen kommen. Dies ist jedoch nicht üblich.
Bei der Konsistenz der begrenzten Veraltung liegt die Verzögerung von Daten zwischen zwei beliebigen Regionen immer unter einem angegebenen Wert. Der Wert kann „K“ Versionen (Updates) eines Elements oder „T“ Zeitintervalle betragen (je nachdem, was zuerst erreicht wird). Wenn Sie also die begrenzte Veraltung auswählen, kann die maximale Veraltung der Daten in jeder Region auf zwei Arten konfiguriert werden:
- Anhand der Anzahl von Versionen (K) des Elements
- Das Zeitintervall (T) kann hinter den Schreibvorgängen liegen.
Begrenzte Veraltung ist in erster Linie für Konten mit Schreibzugriff auf eine einzelne Region mit zwei oder mehr Regionen von Vorteil. Wenn die Datenverzögerung in einer Region (ermittelt pro physischer Partition) den konfigurierten Veraltungswert übersteigt, werden Schreibvorgänge für diese Partition gedrosselt, bis die Veraltung wieder innerhalb der konfigurierten Obergrenze liegt.
Für ein Konto mit einer einzelnen Region bietet die begrenzte Veraltung die gleichen Schreibkonsistenzgarantien wie Sitzungskonsistenz und letztliche Konsistenz. Bei der begrenzten Veraltung werden Daten in einer lokalen Mehrheit (drei von vier Replikaten) innerhalb der einzelnen Region repliziert.
Wichtig
Bei der Konsistenzebene „Begrenzte Veraltung“ werden Veraltungsprüfungen nur regionsübergreifend und nicht innerhalb einer Region durchgeführt. Innerhalb einer bestimmten Region werden Daten unabhängig von der Konsistenzebene immer in einer lokalen Mehrheit repliziert (drei Replikate in einem Satz von vier Replikaten).
Bei Verwendung der begrenzten Veraltung geben Lesevorgänge die neuesten in dieser Region verfügbaren Daten zurück, indem sie aus zwei verfügbaren Replikaten in dieser Region lesen. Da Schreibvorgänge innerhalb einer Region immer in einer lokalen Mehrheit (drei von vier Replikaten) repliziert werden, werden durch die Abfrage von zwei Replikaten die neuesten Daten zurückgegeben, die in dieser Region verfügbar sind.
Wichtig
Bei der Konsistenzebene „Begrenzte Veraltung“ geben für eine nicht primäre Region ausgegebene Lesevorgänge möglicherweise nicht unbedingt die neueste Version der Daten global zurück. Es wird jedoch garantiert, dass die neueste Version der Daten in dieser Region zurückgegeben wird, die sich global innerhalb der maximalen Veraltungsgrenze befindet.
Die begrenzte Veraltung eignet sich am besten für global verteilte Anwendungen, die Konten mit Schreibzugriff auf eine einzelne Region mit zwei oder mehr Regionen verwenden und für die eine Konsistenzebene nahezu vom Typ „Stark“ zwischen Regionen gewünscht ist. Bei Konten mit Schreibzugriff auf mehrere Regionen mit zwei oder mehr Regionen sollten Anwendungsserver Lese- und Schreibvorgänge an dieselbe Region weiterleiten, in der auch die Anwendungsserver gehostet werden. Begrenzte Veraltung in einem Konto mit mehreren Schreibvorgängen ist ein Antimuster. Für diese Ebene wäre eine Abhängigkeit von der Replikationsverzögerung zwischen Regionen erforderlich, was keine Rolle spielen sollte, wenn Daten aus der gleichen Region gelesen werden, in die sie geschrieben wurden.
In der folgenden Grafik wird die begrenzte Veraltung anhand von Noten veranschaulicht. Nachdem die Daten in die Region „USA, Westen 2“ geschrieben wurden, wird der geschriebene Wert in den Regionen „USA, Osten 2“ und „Australien, Osten“ basierend auf der konfigurierten maximalen Verzögerung oder den maximalen Vorgängen gelesen:
Sitzungskonsistenz
Bei der Sitzungskonsistenz berücksichtigen Lesevorgänge innerhalb einer einzelnen Clientsitzung immer die folgenden Garantien: Lesen der eigenen Schreibvorgänge und Schreibvorgänge folgen Lesevorgängen. Bei dieser Garantie wird von einer einzelnen Writer-Sitzung oder von der gemeinsamen Nutzung des Sitzungstokens für mehrere Writer ausgegangen.
Wie alle Konsistenzebenen, die schwächer als „Strong“ sind, werden Schreibvorgänge in mindestens drei Replikaten (in einer Gruppe von vier Replikaten) in der lokalen Region repliziert, wobei die asynchrone Replikation in alle anderen Regionen erfolgt.
Nach jedem Schreibvorgang empfängt der Client ein aktualisiertes Sitzungstoken vom Server. Der Client speichert die Token zwischen und sendet sie für Lesevorgänge in einer angegebenen Region an den Server. Wenn das Replikat, für das der Lesevorgang ausgestellt wird, Daten für das angegebene Token (oder ein neueres Token) enthält, werden die angeforderten Daten zurückgegeben. Wenn das Replikat keine Daten für diese Sitzung enthält, wiederholt der Client die Anforderung für ein anderes Replikat in der Region. Bei Bedarf wiederholt der Client den Lesevorgang in weiteren verfügbaren Regionen, bis Daten für das angegebene Sitzungstoken abgerufen werden.
Wichtig
In der Sitzungskonsistenz garantiert die Verwendung eines Sitzungstokens durch den Client, dass Daten, die einer älteren Sitzung entsprechen, nie gelesen werden. Wenn der Client jedoch ein älteres Sitzungstoken verwendet und neuere Updates an der Datenbank vorgenommen wurden, wird die neuere Version der Daten zurückgegeben, obwohl ein älteres Sitzungstoken verwendet wird. Das Sitzungstoken wird als Mindestversionsbarriere verwendet, aber nicht als spezifische (möglicherweise historische) Version der Daten, die aus der Datenbank abgerufen werden sollen.
Sitzungstoken in Azure Cosmos DB sind partitionsgebunden, d. h. sie sind ausschließlich einer Partition zugeordnet. Um sicherzustellen, dass Sie Ihre Schreibvorgänge lesen können, verwenden Sie das Sitzungstoken, das zuletzt für die relevanten Elemente generiert wurde.
Wenn der Client keinen Schreibvorgang in einer physischen Partition initiiert hat, enthält der Cache des Clients kein Sitzungstoken, und Lesevorgänge in dieser physischen Partition verhalten sich wie Lesevorgänge mit letztlicher Konsistenz. Wenn der Client neu erstellt wird, wird auch der Sitzungstokencache neu erstellt. Auch hier folgen Lesevorgänge dem gleichen Verhalten wie letztliche Konsistenz, bis der Sitzungstokencache des Clients durch nachfolgende Schreibvorgänge neu erstellt wird.
Wichtig
Wenn Sitzungstoken von einer Clientinstanz an eine andere übergeben werden, sollte der Inhalt des Tokens nicht geändert werden.
Die Sitzungskonsistenz ist die gängigste Konsistenzebene für Anwendungen in einer einzelnen Region sowie für weltweit verteilte Anwendungen. Sie bietet Schreibwartezeiten, Verfügbarkeit und Lesedurchsatz, die mit der letztlichen Konsistenz vergleichbar sind. Darüber hinaus bietet Sitzungskonsistenz Konsistenzgarantien für Anwendungen, die für den Einsatz im Benutzerkontext geschrieben wurden. In der folgenden Grafik wird die Sitzungskonsistenz anhand von Noten veranschaulicht. Für „USA, Westen 2“ (Schreiben) und „USA, Osten 2“ (Lesen) wird dieselbe Sitzung (Sitzung A) verwendet, sodass beide dieselben Daten zur selben Zeit lesen. Die Region „Australien, Osten“ dagegen verwendet „Sitzung B“ und empfängt Daten somit später, aber weiterhin in der Reihenfolge der Schreibvorgänge.

Präfixkonsistenz
Wie alle Konsistenzebenen, die schwächer als „Strong“ sind, werden Schreibvorgänge in mindestens drei Replikaten (in einer Gruppe von vier Replikaten) in der lokalen Region repliziert, wobei die asynchrone Replikation in alle anderen Regionen erfolgt.
Bei einem konsistenten Präfix sind die Aktualisierungen, die als einzelne Dokumentschreibvorgänge durchgeführt werden, letztendlich konsistent.
Als Batch innerhalb einer Transaktion vorgenommene Aktualisierungen werden konsistent zu der Transaktion zurückgegeben, in der sie committet wurden. Schreibvorgänge innerhalb einer Transaktion mehrerer Dokumente sind immer zusammen sichtbar.
Angenommen, zwei Schreibvorgänge werden transaktional („Alles oder Nichts“-Vorgänge) für Dokument Doc1 gefolgt von Dokument Doc2 in den Transaktionen T1 und T2 ausgeführt. Wenn der Client ein Replikat liest, sieht der Benutzer entweder „Doc1 v1 und Doc2 v1“, „Doc1 v2 und Doc2 v2“ oder keines der Dokumente, wenn beim Replikat eine Verzögerung auftritt, aber niemals „Doc1 v1 und Doc2 v2“ oder „Doc1 v2 und Doc2 v1“ für den gleichen Lese- oder Abfragevorgang.
In der folgenden Grafik wird die Präfixkonsistenz anhand von Noten veranschaulicht. In allen Regionen sehen die Lesevorgänge Schreibvorgänge für einen Transaktionsbatch mit Schreibvorgängen immer in der richtigen Reihenfolge:

Letztliche Konsistenz
Wie alle Konsistenzebenen, die schwächer als „Strong“ sind, werden Schreibvorgänge in mindestens drei Replikaten (in einer Gruppe von vier Replikaten) in der lokalen Region repliziert, wobei die asynchrone Replikation in alle anderen Regionen erfolgt.
Bei letztlicher Konsistenz sendet der Client Leseanforderungen an ein beliebiges der vier Replikate in der angegebenen Region. Dieses Replikat ist möglicherweise verzögert und könnte veraltete oder keine Daten zurückgeben.
Die letztliche Konsistenz stellt die schwächste Form der Konsistenz dar, da ein Client unter Umständen Werte liest, die älter sind als die in der Vergangenheit gelesenen Werte. Letztliche Konsistenz ist ideal, wenn die Anwendung keine die Reihenfolge betreffenden Garantien erfordert. Ein Beispiel wäre etwa das Zählen von Retweets, „Gefällt mir“-Markierungen oder Kommentaren ohne Thread. In der folgenden Grafik wird die letztliche Konsistenz anhand von Noten veranschaulicht:

Konsistenzgarantien in der Praxis
In der Praxis erhalten Sie häufig stärkere Konsistenzgarantien. Die Konsistenzgarantien für einen Lesevorgang entsprechen der Aktualität und der Sortierung des Zustands der angeforderten Datenbank. Die Lesekonsistenz ist an die Sortierung und Verbreitung der Schreib-/Aktualisierungsvorgänge gebunden.
Wenn keine Schreibvorgänge für die Datenbank ausgeführt werden, liefert ein Lesevorgang mit der Konsistenzebene letztliche Konsistenz, Sitzungskonsistenz oder Präfixkonsistenz wahrscheinlich die gleichen Ergebnisse wie ein Lesevorgang mit starker Konsistenzebene.
Wenn Ihr Konto mit einer anderen Konsistenzebene als der starken Konsistenz konfiguriert ist, können Sie ermitteln, wie hoch die Wahrscheinlichkeit dafür ist, dass Ihre Clients starke und konsistente Lesevorgänge für Ihre Workloads erzielen. Hierzu können Sie sich die PBS-Metrik (Probabilistic Bounded Staleness) ansehen. Diese Metrik wird im Azure-Portal verfügbar gemacht. Weitere Informationen finden Sie unter Überwachen der PBS-Metrik (Probabilistically Bounded Staleness).
PBS (Probabilistically Bounded Staleness) zeigt, wie letztendlich Ihre letztliche Konsistenz ist. Diese Metrik gibt Aufschluss darüber, wie oft Sie eine stärkere Konsistenz erreichen können als die Konsistenzebene, die Sie aktuell in Ihrem Azure Cosmos DB-Konto konfiguriert haben. Das heißt, Sie sehen die Wahrscheinlichkeit (gemessen in Millisekunden), dass konsistente Lesevorgänge in Regionen mit Schreib- und Lesevorgängen auftreten.
Konsistenzebenen und Latenz
Für alle Konsistenzebenen wird eine Leselatenz garantiert, die jederzeit unter 10 Millisekunden im 99. Perzentil liegt. Die durchschnittliche Leselatenz (im 50. Perzentil) beträgt typischerweise 4 Millisekunden oder weniger.
Für alle Konsistenzebenen wird eine Schreiblatenz garantiert, die jederzeit unter 10 Millisekunden im 99. Perzentil liegt. Die durchschnittliche Schreiblatenz (im 50. Perzentil) beträgt üblicherweise 5 Millisekunden oder weniger. Eine Ausnahme bei dieser Garantie bilden Azure Cosmos DB-Konten, die sich über mehrere Regionen erstrecken und mit starker Konsistenz konfiguriert sind.
Schreiblatenz und starke Konsistenz
Für Azure Cosmos DB-Konten, die mit starker Konsistenz mit mehreren Regionen konfiguriert sind, beträgt die Schreiblatenz der doppelten Roundtripzeit (Round-Trip Time, RTT) zwischen den beiden am weitesten entfernten Regionen plus 10 Millisekunden im 99. Perzentil. Eine hohe Netzwerk-RTT zwischen den Regionen führt zu einer höheren Latenz für Azure Cosmos DB-Anforderungen, da ein Vorgang bei starker Konsistenz erst abgeschlossen wird, nachdem sichergestellt wurde, dass er in allen Regionen innerhalb eines Kontos committet wurde.
Die exakte RTT-Latenz richtet sich nach der physischen Entfernung und der Azure-Netzwerktopologie. Azure-Netzwerke bieten keine Wartezeit-SLAs für die RTT zwischen zwei Azure-Regionen, aber Sie veröffentlichen Roundtrip-Latenzstatistiken von Azure-Netzwerken. Die Replikationslatenzzeiten für Ihr Azure Cosmos DB-Konto werden im Azure-Portal angezeigt. Sie können im Azure-Portal zum Abschnitt „Metriken“ navigieren und dann die Option „Konsistenz“ auswählen. Im Azure-Portal können Sie die Replikationswartezeiten zwischen verschiedenen Regionen überwachen, die Ihrem Azure Cosmos DB-Konto zugeordnet sind.
Wichtig
Starke Konsistenz wird für Konten mit Regionen, die mehr als 5.000 Meilen (8.000 Kilometer) umfassen, standardmäßig aufgrund der hohen Schreiblatenz blockiert. Wenden Sie sich an den Support, um diese Funktion zu aktivieren.
Konsistenzebenen und Durchsatz
Für starke und begrenzte Veraltung werden Lesevorgänge für zwei Replikate in einer Gruppe mit vier Replikaten (Minderheitsquorum) durchgeführt, um die Konsistenz zu garantieren. Die Lesevorgänge werden in der Reihenfolge „Sitzung“, „Präfixkonsistenz“ und „Letztlich“ durchgeführt. Im Ergebnis ist der Lesedurchsatz für die gleiche Anzahl von Anforderungseinheiten für starke und begrenzte Veraltung halb so hoch wie bei anderen Konsistenzebenen.
Für bestimmte Schreibvorgänge (z.B. Einfügen, Ersetzen, Upsert, Löschen) ist der Schreibdurchsatz für RUs für alle Konsistenzebenen identisch. Für starke Konsistenz müssen Änderungen in jeder Region übertragen werden (globale Mehrheit), während für alle anderen Konsistenzstufen die lokale Mehrheit (drei Replikate in einem Satz von vier Replikaten) verwendet wird.
| Konsistenzebene | Quorumlesevorgänge | Quorumschreibvorgänge |
|---|---|---|
| Starke Konsistenz | Lokale Minderheit | Globale Mehrheit |
| Begrenzte Veraltung | Lokale Minderheit | Lokale Mehrheit |
| Sitzungskonsistenz | Einzelnes Replikat (mit Sitzungstoken) | Lokale Mehrheit |
| Präfixkonsistenz | Einzelnes Replikat | Lokale Mehrheit |
| Letztliche Konsistenz | Einzelnes Replikat | Lokale Mehrheit |
Hinweis
Die RU-Kosten für die Lesevorgänge von lokalen Minderheiten sind doppelt so hoch wie bei niedrigeren Konsistenzebenen, da die Lesevorgänge aus zwei Replikaten erstellt werden, um Konsistenzgarantien für die Konsistenzebenen „Stark“ und „Begrenzte Veraltung“ zu bieten.
Konsistenzebenen und Datendauerhaftigkeit
In einer global verteilten Datenbankumgebung besteht ein direkter Zusammenhang zwischen der Konsistenzebene und der Dauerhaftigkeit der Daten bei einem regionsweiten Ausfall. Bei der Entwicklung Ihres Business-Continuity-Plans müssen Sie sich darüber im Klaren sein, über welchen Zeitraum kürzlich durchgeführte Datenupdates maximal verloren gehen dürfen, wenn die Anwendung nach einer Störung wiederhergestellt wird. Der Zeitraum der Updates, der verloren gehen darf, wird als RPO (Recovery Point Objective) bezeichnet.
In dieser Tabelle wird die Beziehung zwischen dem Konsistenzmodell und der Datendauerhaftigkeit bei einem regionsweiten Ausfall definiert.
| Region(en) | Replikationsmodus | Konsistenzebene | RPO |
|---|---|---|---|
| 1 | Eine oder mehrere Schreibregionen | Jede Konsistenzebene | < 240 Minuten |
| >1 | Eine Schreibregion | Sitzung, Präfixkonsistenz, Letztlich | < 15 Minuten |
| >1 | Eine Schreibregion | Begrenzte Veraltung (Bounded staleness) | K & T |
| >1 | Eine Schreibregion | STARK (Strong) | 0 |
| >1 | Mehrere Schreibregionen | Sitzung, Präfixkonsistenz, Letztlich | < 15 Minuten |
| >1 | Mehrere Schreibregionen | Begrenzte Veraltung (Bounded staleness) | K & T |
K = Anzahl von K Versionen (Updates) eines Elements.
T = Zeitintervall „T“ seit dem letzten Update.
Bei einem Konto mit einer einzelnen Region ist der Mindestwert von K und T 10 Schreibvorgänge oder 5 Sekunden. Bei Konten mit mehreren Regionen ist der Mindestwert von K und T 100.000 Schreibvorgänge oder 300 Sekunden. Dieser Wert definiert die minimale RPO für Daten bei Verwendung von begrenzter Veraltung.
Hohe Konsistenz und mehrere Schreibregionen
Mit mehreren Schreibregionen konfigurierte Azure Cosmos DB-Konten können nicht für starke Konsistenz konfiguriert werden, da es für ein verteiltes System nicht möglich ist, einen RPO-Wert von Null und einen RTO-Wert von Null zu erreichen. Außerdem gibt es keine Vorteile hinsichtlich der Schreiblatenz bei Verwendung von hoher Konsistenz mit mehreren Schreibregionen, da ein Schreibvorgang für eine beliebige Region repliziert und in allen konfigurierten Regionen innerhalb des Kontos committet werden muss. Dieses Szenario führt zur gleichen Schreibwartezeit wie bei einem Konto mit nur einer Schreibregion.
Weitere Informationen
In folgenden Ressourcen erfahren Sie mehr über Konsistenzkonzepte:
- High-level TLA+ specifications for the five consistency levels offered by Azure Cosmos DB (Allgemeine TLA+-Spezifikationen für die fünf von Azure Cosmos DB angebotenen Konsistenzebenen)
- Erläuterung der Konsistenz replizierter Daten anhand von Baseball (Video) von Doug Terry
- Erläuterung der Konsistenz replizierter Daten anhand von Baseball (Whitepaper) von Doug Terry
- Sitzungsgarantien für schwach konsistente replizierte Daten
- Konsistenzkompromisse im Design moderner verteilter Datenbanksysteme: CAP ist nur ein Teil der Wahrheit
- Probabilistic Bounded Staleness (PBS) for Practical Partial Quorums
- Eventually Consistent – Revisited (Letztliche Konsistenz – Neuauflage)