Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Gilt für: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp
Data Factory in Microsoft Fabric ist die nächste Generation von Azure Data Factory mit einer einfacheren Architektur, integrierter KI und neuen Features. Wenn Sie mit der Datenintegration noch nicht vertraut sind, beginnen Sie mit Fabric Data Factory. Vorhandene ADF-Workloads können auf Fabric aktualisiert werden, um auf neue Funktionen in der Datenwissenschaft, Echtzeitanalysen und Berichterstellung zuzugreifen.
Die Spark-Aktivität in einer Data Factory und Synapse Pipelines führt ein Spark-Programm auf ihrem eigenen oder On-Demand-HDInsight-Cluster aus. Dieser Artikel baut auf dem Artikel zu Datentransformationsaktivitäten auf, der eine allgemeine Übersicht über die Datentransformation und die unterstützten Transformationsaktivitäten bietet. Wenn Sie einen mit Spark verknüpften On-Demand-Dienst verwenden, erstellt der Dienst automatisch einen Spark-Cluster für Sie, um die Daten just-in-time zu verarbeiten, und löscht den Cluster, sobald die Verarbeitung abgeschlossen ist.
Hinzufügen einer Spark-Aktivität zu einer Pipeline mit Benutzeroberfläche
Führen Sie die folgenden Schritte aus, um eine Spark-Aktivität in einer Pipeline zu verwenden:
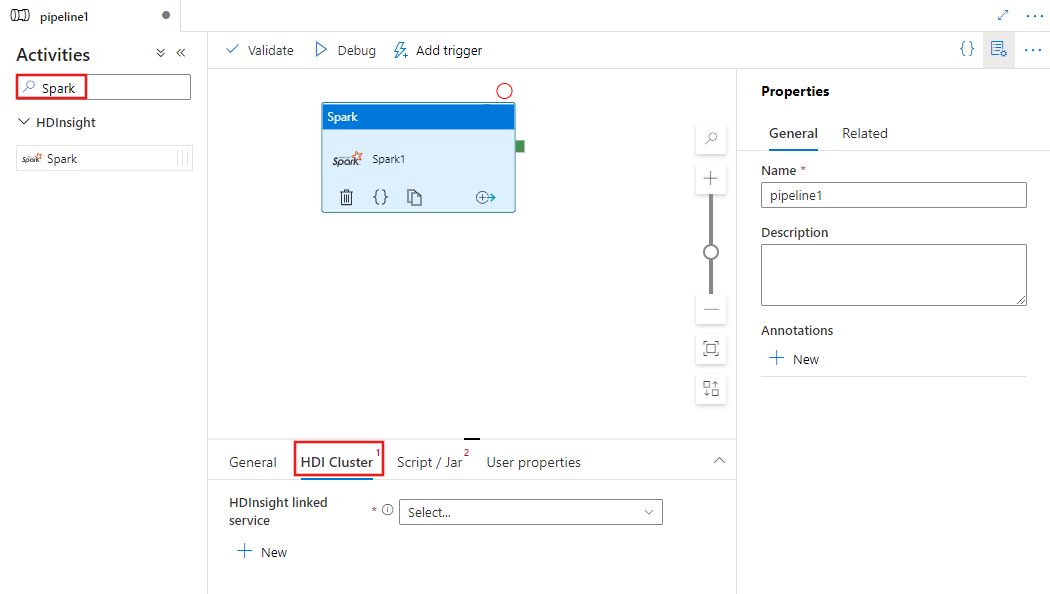
Suchen Sie im Bereich mit den Pipelineaktivitäten nach Spark, und ziehen Sie eine Spark-Aktivität in den Pipelinebereich.
Wählen Sie die neue Spark-Aktivität im Canvas aus, wenn sie noch nicht ausgewählt ist.
Wählen Sie die Registerkarte HDI-Cluster aus, um einen neuen verknüpften Dienst für einen HDInsight-Cluster auszuwählen oder zu erstellen, der zum Ausführen der Spark-Aktivität verwendet wird.
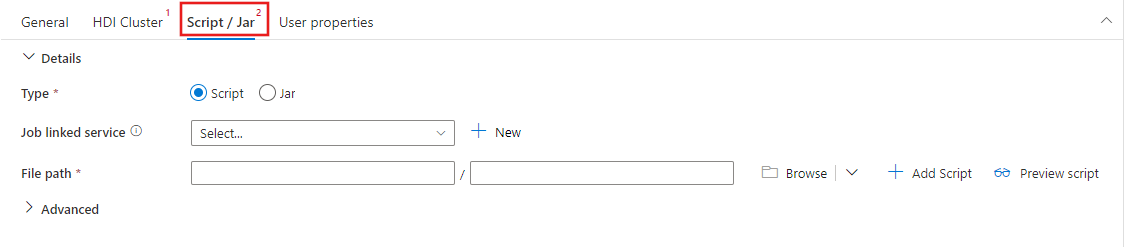
Wählen Sie die Registerkarte Script /Jar aus, um einen neuen, mit einem Azure Storage Konto verknüpften Dienst auszuwählen oder zu erstellen, das Ihr Skript hosten soll. Geben Sie einen Pfad zu der Datei an, die dort ausgeführt werden soll. Sie können auch erweiterte Details konfigurieren, z. B. einen Proxybenutzer, eine Debugkonfiguration sowie Argumente und Spark-Konfigurationsparameter, die an das Skript übergeben werden sollen.
Eigenschaften von Spark-Aktivitäten
Dies ist die JSON-Beispieldefinition einer Spark-Aktivität:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
Die folgende Tabelle beschreibt die JSON-Eigenschaften, die in der JSON-Definition verwendet werden:
| Eigenschaft | Beschreibung | Erforderlich |
|---|---|---|
| name | Der Name der Aktivität in der Pipeline. | Ja |
| Beschreibung | Ein Text, der beschreibt, was mit der Aktivität ausgeführt wird. | Nein |
| Typ | Für die Spark-Aktivität ist der Aktivitätstyp „HDInsightSpark“. | Ja |
| linkedServiceName | Name des mit HDInsight Spark verknüpften Diensts, in dem das Spark-Programm ausgeführt wird. Weitere Informationen zu diesem verknüpften Dienst finden Sie im Artikel Compute verknüpfte Dienste. | Ja |
| SparkJobLinkedService | Der verknüpfte Azure Storage Dienst, der die Spark-Auftragsdatei, Abhängigkeiten und Protokolle enthält. Hier werden nur Azure Blob Storage und ADLS Gen2 verknüpften Dienste unterstützt. Wenn Sie für diese Eigenschaft keinen Wert angeben, wird der Speicher verwendet, der dem HDInsight-Cluster zugeordnet ist. Der Wert dieser Eigenschaft kann nur ein Azure Storage verknüpfter Dienst sein. | Nein |
| Wurzelpfad | Der Azure BLOB-Container und -Ordner, der die Spark-Datei enthält. Der Dateiname ist groß-/kleinschreibungssensitiv. Details zur Struktur dieses Ordners finden Sie im Abschnitt „Ordnerstruktur“ (nächster Abschnitt). | Ja |
| entryFilePath | Der relative Pfad zum Stammordner des Spark-Codes bzw. -Pakets. Die Eintragsdatei muss entweder eine Python Datei oder eine .jar Datei sein. | Ja |
| className | Java/Spark-Hauptklasse der Anwendung | Nein |
| Argumente | Eine Liste der Befehlszeilenargumente für das Spark-Programm. | Nein |
| proxyUser | Das Benutzerkonto, dessen Identität angenommen werden soll, um das Spark-Programm auszuführen. | Nein |
| sparkConfig-Konfiguration | Geben Sie Werte für die Spark-Konfigurationseigenschaften an, die im Thema Spark-Konfiguration – Anwendungseigenschaften aufgeführt sind. | Nein |
| getDebugInfo | Gibt an, ob die Spark-Protokolldateien in den Azure-Speicher kopiert werden, der vom HDInsight-Cluster verwendet (oder) von sparkJobLinkedService angegeben wird. Zulässige Werte: „None“, „Always“ oder „Failure“. Standardwert: Keine. | Nein |
Ordnerstruktur
Spark-Aufträge lassen sich besser erweitern als Pig- oder Hive-Aufträge. Bei Spark-Aufträgen können Sie mehrere Abhängigkeiten wie Jar-Pakete (platziert in der Java CLASSPATH), Python Dateien (auf pythonpath platziert) und alle anderen Dateien bereitstellen.
Erstellen Sie die folgende Ordnerstruktur im Azure Blob-Speicher, auf den der HDInsight-verbundene Dienst verweist. Laden Sie dann abhängige Dateien in die entsprechenden Unterordner in dem Stammordner hoch, der von entryFilePath repräsentiert wird. Laden Sie z. B. Python Dateien in den PyFiles-Unterordner und jar-Dateien in den Jars-Unterordner des Stammordners hoch. Zur Laufzeit erwartet der Dienst die folgende Ordnerstruktur im Azure Blob-Speicher:
| Pfad | Beschreibung | Erforderlich | Typ |
|---|---|---|---|
. (Stamm) |
Der Stammpfad des Spark-Auftrags im verknüpften Speicherdienst. | Ja | Ordner |
| <benutzerdefiniert> | Der Pfad, der auf die Eingabedatei des Spark-Auftrags zeigt. | Ja | Datei |
| ./jars | Alle Dateien unter diesem Ordner werden hochgeladen und auf dem Java Klassenpfad des Clusters platziert. | Nein | Ordner |
| ./pyFiles | Alle Dateien in diesem Ordner werden hochgeladen und im PYTHONPATH des Clusters platziert. | Nein | Ordner |
| ./files | Alle Dateien in diesem Ordner werden hochgeladen und im Executor-Arbeitsverzeichnis platziert. | Nein | Ordner |
| ./archives | Alle Dateien in diesem Ordner sind nicht komprimiert. | Nein | Ordner |
| ./logs | Der Ordner, der die Protokolle aus dem Spark-Cluster enthält. | Nein | Ordner |
Hier ist ein Beispiel für einen Speicher, der zwei Spark-Auftragsdateien in der Azure Blob Storage enthält, auf die vom HDInsight-verknüpften Dienst verwiesen wird.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Zugehöriger Inhalt
In den folgenden Artikeln erfahren Sie, wie Daten auf andere Weisen transformiert werden: