Erstellen von Aufträgen und Eingabedaten für Batchendpunkte
Mit Batchendpunkten können Sie lange Batchvorgänge mit großen Datenmengen durchführen. Die Daten können sich an verschiedenen Orten befinden, z. B. in verstreuten Regionen. Bestimmte Arten von Batchendpunkten können auch literale Parameter als Eingaben empfangen.
Dieser Artikel beschreibt, wie Sie Parametereingaben für Batchendpunkte festlegen und Bereitstellungsaufträge erstellen. Der Prozess unterstützt die Arbeit mit verschiedenen Arten von Daten. Einige Beispiele finden Sie unter Grundlegendes zu Eingaben und Ausgaben.
Voraussetzungen
Um einen Batchendpunkt erfolgreich aufzurufen und Aufträge zu erstellen, müssen Sie die folgenden Voraussetzungen erfüllen:
Sie benötigen einen Batchendpunkt und eine Bereitstellung. Wenn Sie nicht über diese Ressourcen verfügen, lesen Sie den Abschnitt Bereitstellen von Modellen für das Scoring in Batchendpunkten, um eine Bereitstellung zu erstellen.
Sie müssen über Berechtigungen zum Ausführen einer Batchendpunktbereitstellung verfügen. Für die Ausführung einer Bereitstellung können die Rollen AzureML – Wissenschaftliche Fachkraft für Daten, Mitwirkender und Besitzer verwendet werden. Für benutzerdefinierte Rollendefinitionen lesen Sie bitte den Abschnitt Autorisierung auf Batchendpunkten, um die spezifischen erforderlichen Berechtigungen zu überprüfen.
Sie müssen über ein gültiges Microsoft Entra ID-Token verfügen, das einen Sicherheitsprinzipal darstellt, um den Endpunkt aufzurufen. Dieser Prinzipal kann ein Benutzerprinzipal oder ein Dienstprinzipal sein. Nachdem Sie einen Endpunkt aufgerufen haben, erstellt Azure Machine Learning einen Auftrag zur Bereitstellung unter der mit dem Token verbundenen Identität. Sie können Ihre eigenen Anmeldedaten für den Aufruf verwenden, wie in den folgenden Verfahren beschrieben.
Verwenden Sie die Azure CLI, um sich mit interaktiver oder Gerätecode-Authentifizierung anzumelden:
az loginWeitere Informationen zum Starten von Batchbereitstellungsaufträgen unter Verwendung verschiedener Arten von Anmeldeinformationen finden Sie unter So führen Sie Aufträge unter Verwendung verschiedener Arten von Anmeldeinformationen aus.
Der Rechencluster, auf dem der Endpunkt eingerichtet ist, hat Zugriff auf die Eingabedaten.
Tipp
Wenn Sie einen Datenspeicher ohne Anmeldeinformationen oder ein externes Azure Storage-Konto als Dateneingabe verwenden, stellen Sie sicher, dass Sie Compute-Cluster für den Datenzugriff konfigurieren. Die verwaltete Identität des Rechenclusters wird für die Einbindung des Speicherkontos verwendet. Die Identität des Auftrags (Aufrufer) wird weiterhin verwendet, um die zugrunde liegenden Daten zu lesen, wodurch Sie eine granulare Zugriffskontrolle erreichen können.
Grundlagen zum Erstellen von Aufträgen
Um einen Auftrag von einem Batchendpunkt aus zu erstellen, rufen Sie den Endpunkt auf. Der Aufruf kann über die Azure CLI, das Azure Machine Learning SDK für Python oder einen REST API-Aufruf erfolgen. Die folgenden Beispiele zeigen die Grundlagen des Aufrufs für einen Batchendpunkt, der einen einzelnen Eingabedatenordner zur Verarbeitung empfängt. Beispiele mit unterschiedlichen Eingaben und Ausgaben finden Sie unter Grundlegendes zu Eingaben und Ausgaben.
Verwenden Sie den invoke-Vorgang unter Batchendpunkten:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Aufrufen einer bestimmten Bereitstellung
Batch-Endpunkte können mehrere Bereitstellungen unter demselben Endpunkt hosten. Der Standardendpunkt wird verwendet, sofern der Benutzer nichts anderes angibt. Sie können die zu verwendende Bereitstellung mit den folgenden Verfahren ändern.
Verwenden Sie das Argument --deployment-name oder -d, um den Namen der Bereitstellung anzugeben:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--deployment-name $DEPLOYMENT_NAME \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Konfigurieren der Jobeigenschaften
Sie können einige der Eigenschaften im erstellten Auftrag zum Aufruf konfigurieren.
Hinweis
Die Möglichkeit, Auftragseigenschaften zu konfigurieren, ist derzeit nur in Batchendpunkten mit Pipeline-Komponentenbereitstellungen verfügbar.
Konfigurieren des Experimentnamens
Gehen Sie wie folgt vor, um den Namen des Experiments zu konfigurieren.
Verwenden Sie das Argument --experiment-name, um den Namen des Experiments anzugeben:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--experiment-name "my-batch-job-experiment" \
--input https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data
Grundlegendes zu Eingaben und Ausgaben
Batchendpunkte bieten eine dauerhafte API, die Consumer zum Erstellen von Batchaufträgen verwenden können. Dieselbe Schnittstelle kann verwendet werden, um Eingaben und Ausgaben anzugeben, die Ihre Bereitstellung erwartet. Verwenden Sie Eingaben, um alle Informationen zu übergeben, die Ihr Endpunkt zum Ausführen des Auftrags benötigt.
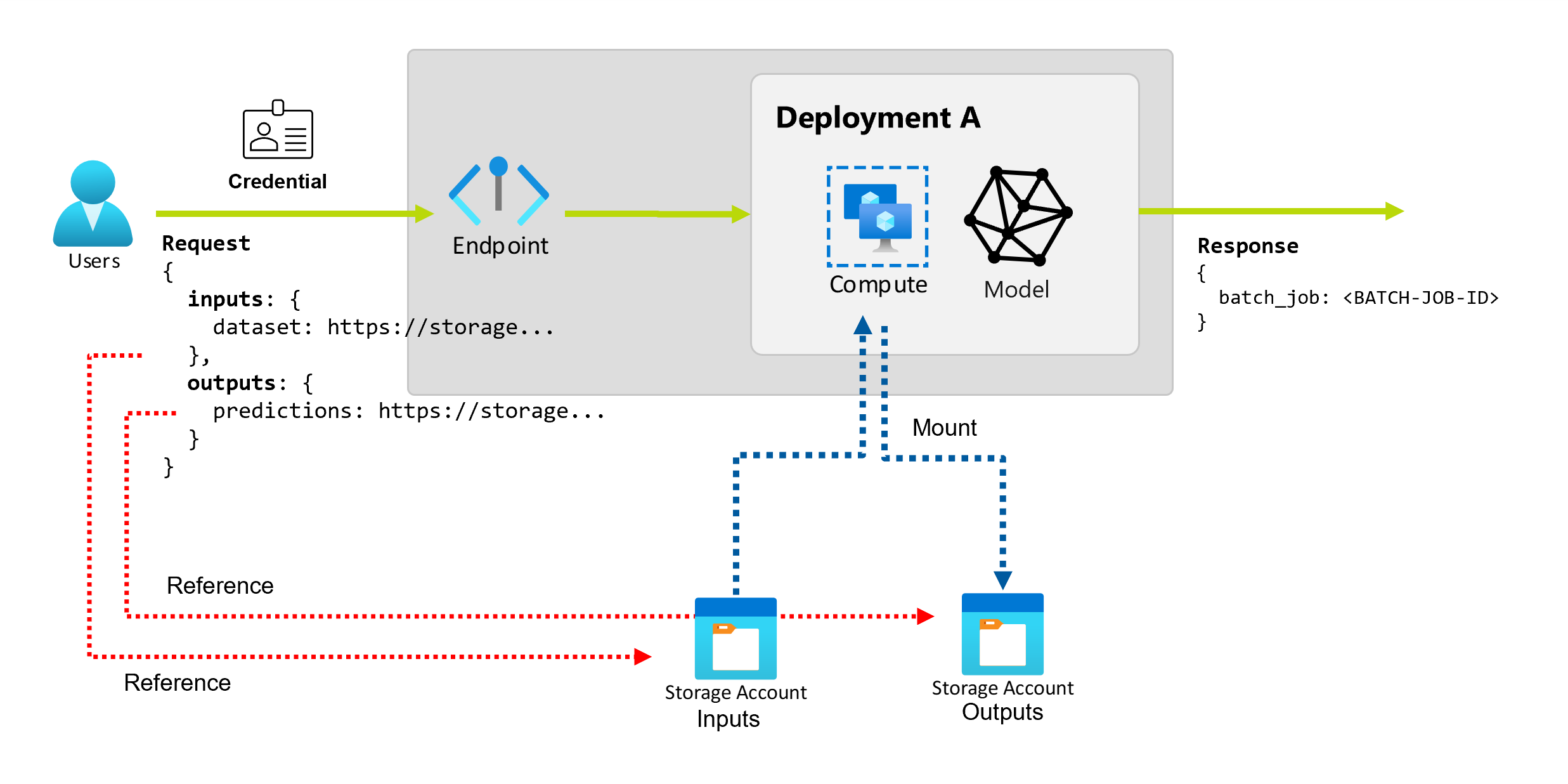
Batch-Endpunkte unterstützen zwei Arten von Eingaben:
- Dateneingaben: Zeiger auf einen bestimmten Speicherort oder ein Azure Machine Learning-Asset.
- Literale Eingaben Literal-Werte (wie Zahlen oder Zeichenketten), die Sie an den Auftrag übergeben wollen.
Anzahl und Typ der Eingaben und Ausgaben hängen vom Typ der Batchbereitstellung ab. Modellimplementierungen erfordern immer eine Dateneingabe und erzeugen eine Datenausgabe. Literaleingaben werden nicht unterstützt. Die Bereitstellung von Pipelinekomponenten bietet jedoch ein allgemeineres Konstrukt zum Erstellen von Endpunkten und ermöglichen es Ihnen, eine beliebige Anzahl von Eingaben (Daten und Literal) und Ausgaben anzugeben.
In der folgenden Tabelle sind die Eingaben und Ausgaben für Batch-Bereitstellungen zusammengefasst:
| Bereitstellungstyp | Anzahl von Eingaben | Unterstützte Eingabetypen | Anzahl von Ausgaben | Unterstützte Ausgabetypen |
|---|---|---|---|---|
| Modellimplementierung | 1 | Dateneingaben | 1 | Datenausgaben |
| Einsatz von Pipeline-Komponenten | [0..N] | Dateneingaben und Literaleingaben | [0..N] | Datenausgaben |
Tipp
Eingaben und Ausgaben sind immer benannt. Die Namen dienen als Schlüssel, um die Daten zu identifizieren und den tatsächlichen Wert während des Aufrufs zu übergeben. Da bei Modellimplementierungen immer eine Eingabe und eine Ausgabe erforderlich sind, wird der Name während des Aufrufs ignoriert. Sie können einen Namen vergeben, der Ihren Anwendungsfall am besten beschreibt, z. B. „sales_estimation“.
Näheres zu Dateneingaben
Dateneingaben beziehen sich auf Eingaben, die auf einen Speicherort verweisen, an dem Daten platziert sind. Da Batchendpunkte in der Regel große Datenmengen verbrauchen, können Sie die Eingabedaten nicht als Teil der Aufrufanforderung übergeben. Stattdessen geben Sie den Speicherort an, an dem der Batch-Endpunkt nach den Daten suchen soll. Eingabedaten werden eingebunden und auf der Zielcompute gestreamt, um die Leistung zu verbessern.
Batchendpunkte unterstützen das Lesen von Dateien in den folgenden Speicheroptionen:
- Azure Machine Learning Data Assets, einschließlich Ordner (
uri_folder) und Datei (uri_file). - Azure Machine Learning Data Stores, einschließlich Azure Blob Storage, Azure Data Lake Storage Gen1 und Azure Data Lake Storage Gen2.
- Azure Storage Accounts, einschließlich Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 und Azure Blob Storage.
- Lokale Datenordner/Dateien (Azure Machine Learning CLI oder Azure Machine Learning SDK für Python). Dieser Vorgang führt jedoch dazu, dass die lokalen Daten in den standardmäßigen Azure Machine Learning-Datenspeicher des Arbeitsbereichs hochgeladen werden, an dem Sie gerade arbeiten.
Wichtig
Hinweis zu veralteten Funktionen: Datasets des Typs FileDataset (V1) wurden als veraltet eingestuft und werden in Zukunft eingestellt. Vorhandene Batchendpunkte, die auf dieser Funktionalität basieren, funktionieren weiterhin. Batchendpunkte, die mit GA CLIv2 (2.4.0 und neuer) oder GA REST-API (2022-05-01 und neuer) erstellt wurden, unterstützen kein V1-Dataset.
Näheres zu Literaleingaben
Literaleingaben beziehen sich auf Eingaben, die zur Aufrufzeit dargestellt und aufgelöst werden können, z. B. Zeichenfolgen, Zahlen und boolesche Werte. In der Regel verwenden Sie Literaleingaben, um Parameter als Teil der Bereitstellung einer Pipelinekomponente an Ihren Endpunkt zu übergeben. Batchendpunkte unterstützen die folgenden Literaltypen:
stringbooleanfloatinteger
Wörtliche Eingaben werden nur bei der Bereitstellung von Pipelinekomponenten unterstützt. Siehe Erstellen von Aufträgen mit literalen Eingaben, um zu erfahren, wie man sie angibt.
Näheres zu Datenausgaben
Datenausgaben beziehen sich auf den Speicherort, an dem die Ergebnisse eines Batchauftrags platziert werden sollen. Jede Ausgabe hat einen identifizierbaren Namen, und Azure Machine Learning weist jeder benannten Ausgabe automatisch einen eindeutigen Pfad zu. Sie können bei Bedarf einen anderen Pfad angeben.
Wichtig
Batchendpunkte unterstützen nur das Schreiben von Ausgaben in Azure Blob Storage-Datenspeichern. Wenn Sie in ein Speicherkonto schreiben müssen, für das hierarchische Namespaces aktiviert sind (auch als Azure Datalake Gen2 oder ADLS Gen2 bezeichnet), können Sie diesen Speicherdienst als Azure Blob Storage-Datenspeicher registrieren, da die Dienste vollständig kompatibel sind. Auf diese Weise können Sie Ausgaben von Batchendpunkten in ADLS Gen2 schreiben.
Aufträge mit Dateneingabe erstellen
Die folgenden Beispiele zeigen, wie Aufträge erstellt werden, die Dateneingaben von Datenbeständen, Datenspeichern und Azure Storage Accounts übernehmen.
Verwenden von Eingangsdaten aus einer Datenressource
Azure Machine Learning-Datenressourcen (ehemals als Datasets bezeichnet) werden als Eingaben für Aufträge unterstützt. Führen Sie die folgenden Schritte aus, um einen Batchendpunktauftrag mit Daten auszuführen, die in einer registrierten Datenressource in Azure Machine Learning gespeichert sind.
Warnung
Datenressourcen des Typs „Tabelle“ (MLTable) werden derzeit nicht unterstützt.
Erstellen Sie zunächst die Datenressource: Diese Datenressource besteht aus einem Ordner mit mehreren CSV-Dateien, die Sie mithilfe von Batch-Endpunkten parallel verarbeiten werden. Sie können diesen Schritt überspringen, wenn Ihre Daten bereits als Datenressource registriert sind.
Erstellen Sie eine Datenressourcendefinition in
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: heart-classifier-mlflow/dataErstellen Sie dann die Datenressource:
az ml data create -f heart-dataset-unlabeled.ymlErstellen Sie die Eingabe oder Anfrage:
DATASET_ID=$(az ml data show -n heart-dataset-unlabeled --label latest | jq -r .id)Führen Sie den Endpunkt aus:
Verwenden Sie das
--set-Argument, um die Eingabe anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$DATASET_IDFür einen Endpunkt, der einer Modellbereitstellung dient, können Sie das
--input-Argument verwenden, um die Dateneingabe anzugeben, da für eine Modellbereitstellung immer nur eine Dateneingabe erforderlich ist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $DATASET_IDDas Argument
--setneigt dazu, lange Befehle zu erzeugen, wenn mehrere Eingaben angegeben werden. Platzieren Sie in solchen Fällen Ihre Eingaben in einerYAML-Datei und verwenden Sie das Argument--file, um die Eingaben anzugeben, die Sie für Ihren Endpunktaufruf benötigen.inputs.yml
inputs: heart_dataset: azureml:/<datasset_name>@latestFühren Sie den folgenden Befehl aus:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Verwenden von Eingangsdaten aus Datenspeichern
Sie können auf Daten aus in Azure Machine Learning registrierten Datenspeichern direkt von Batchbereitstellungsaufträgen verweisen. In diesem Beispiel laden Sie zunächst einige Daten in den Standarddatenspeicher im Azure Machine Learning-Arbeitsbereich hoch und führen dann eine Batch-Bereitstellung für diese Daten aus. Führen Sie die folgenden Schritte aus, um einen Batch-Endpunktauftrag mithilfe von Daten auszuführen, die in einem Datenspeicher gespeichert sind.
Greifen Sie auf den Standard-Datenspeicher im Azure Machine Learning-Arbeitsbereich zu. Wenn sich Ihre Daten in einem anderen Speicher befinden, können Sie stattdessen diesen Speicher verwenden. Sie müssen den Standarddatenspeicher nicht verwenden.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Die Datenspeicher-ID sieht so ähnlich aus wie
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Tipp
Der standardmäßige Blobdatenspeicher in einem Arbeitsbereich lautet workspaceblobstore. Sie können diesen Schritt überspringen, wenn Sie die Ressourcen-ID des Standarddatenspeichers in Ihrem Arbeitsbereich bereits kennen.
Laden Sie einige Beispieldaten in den Datenspeicher hoch.
In diesem Beispiel wird davon ausgegangen, dass Sie die Beispieldaten aus dem Repository im Ordner
sdk/python/endpoints/batch/deploy-models/heart-classifier-mlflow/datain den Ordnerheart-disease-uci-unlabeledim Blob-Speicherkonto hochgeladen haben. Schließen Sie diesen Schritt unbedingt ab, bevor Sie fortfahren.Erstellen Sie die Eingabe oder Anfrage:
Geben Sie den Dateipfad in die Variable
INPUT_PATHein:DATA_PATH="heart-disease-uci-unlabeled" INPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Beachten Sie, wie die Variable
pathsfür den Pfad an die Ressourcen-ID des Datenspeichers angefügt wird. Dieses Format gibt an, dass der folgende Wert ein Pfad ist.Tipp
Sie können auch das Format
azureml://datastores/<data-store>/paths/<data-path>zur Angabe der Eingabe verwenden.Führen Sie den Endpunkt aus:
Verwenden Sie das
--set-Argument, um die Eingabe anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_PATHFür einen Endpunkt, der einer Modellbereitstellung dient, können Sie das
--input-Argument verwenden, um die Dateneingabe anzugeben, da für eine Modellbereitstellung immer nur eine Dateneingabe erforderlich ist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_PATH --input-type uri_folderDas Argument
--setneigt dazu, lange Befehle zu erzeugen, wenn mehrere Eingaben angegeben werden. Platzieren Sie in solchen Fällen Ihre Eingaben in einerYAML-Datei und verwenden Sie das Argument--file, um die Eingaben anzugeben, die Sie für Ihren Endpunktaufruf benötigen.inputs.yml
inputs: heart_dataset: type: uri_folder path: azureml://datastores/<data-store>/paths/<data-path>Führen Sie den folgenden Befehl aus:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlWenn es sich bei Ihren Daten um eine Datei handelt, verwenden Sie stattdessen den Typ
uri_filefür die Eingabe.
Verwenden von Eingangsdaten aus Azure Storage-Konten
Azure Machine Learning-Batchendpunkte können Daten aus Cloudstandorten in Azure Storage-Konten lesen, sowohl öffentliche als auch private. Führen Sie die folgenden Schritte aus, um einen Batchendpunktauftrag mit Daten auszuführen, die in einem Speicherkonto gespeichert sind:
Weitere Informationen zur zusätzlichen erforderlichen Konfiguration zum Lesen von Daten aus Speicherkonten finden Sie unter Konfigurieren von Computeclustern für den Datenzugriff.
Erstellen Sie die Eingabe oder Anfrage:
Legen Sie die Variable
INPUT_DATAfest:INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Wenn es sich bei Ihren Daten um eine Datei handelt, legen Sie die Variable mit dem folgenden Format fest:
INPUT_DATA = "https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data/heart.csv"Führen Sie den Endpunkt aus:
Verwenden Sie das
--set-Argument, um die Eingabe anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.type="uri_folder" inputs.heart_dataset.path=$INPUT_DATAFür einen Endpunkt, der einer Modellbereitstellung dient, können Sie das
--input-Argument verwenden, um die Dateneingabe anzugeben, da für eine Modellbereitstellung immer nur eine Dateneingabe erforderlich ist.az ml batch-endpoint invoke --name $ENDPOINT_NAME --input $INPUT_DATA --input-type uri_folderDas Argument
--setneigt dazu, lange Befehle zu erzeugen, wenn mehrere Eingaben angegeben werden. Platzieren Sie in solchen Fällen Ihre Eingaben in einerYAML-Datei und verwenden Sie das Argument--file, um die Eingaben anzugeben, die Sie für Ihren Endpunktaufruf benötigen.inputs.yml
inputs: heart_dataset: type: uri_folder path: https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/dataFühren Sie den folgenden Befehl aus:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.ymlWenn es sich bei Ihren Daten um eine Datei handelt, verwenden Sie stattdessen den Typ
uri_filefür die Eingabe.
Arbeitsplätze mit wörtlichen Eingaben schaffen
Für die Bereitstellung von Pipeline-Komponenten können wörtliche Eingaben verwendet werden. Das folgende Beispiel zeigt, wie eine Eingabe namens score_mode, vom Typ string und mit einem Wert von append angegeben wird:
Platzieren Sie Ihre Eingaben in einer YAML-Datei, und verwenden Sie --file, um die Eingaben zu spezifizieren, die Sie für Ihren Endpunktaufruf benötigen.
inputs.yml
inputs:
score_mode:
type: string
default: append
Führen Sie den folgenden Befehl aus:
az ml batch-endpoint invoke --name $ENDPOINT_NAME --file inputs.yml
Sie können das Argument --set auch verwenden, um den Wert anzugeben. Allerdings neigt dieser Ansatz dazu, lange Befehle zu erzeugen, wenn mehrere Eingaben gemacht werden:
az ml batch-endpoint invoke --name $ENDPOINT_NAME \
--set inputs.score_mode.type="string" inputs.score_mode.default="append"
Aufträge mit Datenausgaben erstellen
Das folgende Beispiel zeigt, wie Sie den Speicherort für eine Ausgabe mit dem Namen score ändern können. Der Vollständigkeit halber konfigurieren diese Beispiele auch eine Eingabe mit dem Namen heart_dataset.
Speichern Sie die Ausgabe mit dem Standarddatenspeicher im Azure Machine Learning-Arbeitsbereich. Sie können jeden anderen Datenspeicher in Ihrem Arbeitsbereich verwenden, solange es sich um ein Blobspeicherkonto handelt.
DATASTORE_ID=$(az ml datastore show -n workspaceblobstore | jq -r '.id')Die Datenspeicher-ID sieht so ähnlich aus wie
/subscriptions/<subscription>/resourceGroups/<resource-group>/providers/Microsoft.MachineLearningServices/workspaces/<workspace>/datastores/<data-store>.Erstellen Sie eine Datenausgabe:
Legen Sie die Variable
OUTPUT_PATHfest:DATA_PATH="batch-jobs/my-unique-path" OUTPUT_PATH="$DATASTORE_ID/paths/$DATA_PATH"Erstellen Sie der Vollständigkeit halber auch eine Dateneingabe:
INPUT_PATH="https://azuremlexampledata.blob.core.windows.net/data/heart-disease-uci/data"Hinweis
Beachten Sie, wie die Variable
pathsfür den Pfad an die Ressourcen-ID des Datenspeichers angefügt wird. Dieses Format gibt an, dass der folgende Wert ein Pfad ist.Führen Sie die Bereitstellung aus:
Verwenden Sie das
--set-Argument, um die Eingabe anzugeben:az ml batch-endpoint invoke --name $ENDPOINT_NAME \ --set inputs.heart_dataset.path=$INPUT_PATH \ --set outputs.score.path=$OUTPUT_PATH