Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Hier erfahren Sie, wie ein Objekterkennungsmodell mit ML.NET Model Builder und Azure Machine Learning erstellt wird, um Stoppschilder in Bildern zu erkennen und zu lokalisieren.
In diesem Tutorial lernen Sie, wie die folgenden Aufgaben ausgeführt werden:
- Vorbereiten und Verstehen der Daten
- Erstellen einer Model Builder-Konfigurationsdatei
- Auswählen des Szenarios
- Auswählen der Trainingsumgebung
- Laden der Daten
- Trainieren des Modells
- Evaluieren des Modells
- Verwenden des Modells für Vorhersagen
Voraussetzungen
Eine Liste der Voraussetzungen und Installationsanweisungen finden Sie in der Installationsanleitung für den Modell-Generator.
Model Builder-Objekterkennung: Überblick
Objekterkennung ist ein Problem des maschinellen Sehens. Obwohl die Objekterkennung eng mit der Bildklassifizierung verwandt ist, führt sie die Bildklassifizierung auf einer detaillierteren Ebene durch. Die Objekterkennung ermittelt und kategorisiert Entitäten in Bildern. Objekterkennungsmodelle werden häufig mit Deep Learning und neuronalen Netzwerken trainiert. Weitere Informationen finden Sie unter Deep Learning im Vergleich zu maschinellem Lernen.
Verwenden Sie die Objekterkennung, wenn Bilder mehrere Objekte verschiedener Typen enthalten.

Einige Anwendungsfälle für die Objekterkennung sind:
- Autonomes Fahren
- Robotik
- Gesichtserkennung
- Arbeitsplatzsicherheit
- Objektzählung
- Aktivitätserkennung
In diesem Beispiel wird eine C# .NET Core-Konsolenanwendung erstellt, die mithilfe eines mit Model Builder erstellten Machine Learning-Modells Stoppschilder in Bildern erkennt. Sie finden den Quellcode für dieses Tutorial im GitHub-Repository dotnet/machinelearning-samples.
Vorbereiten und Verstehen der Daten
Das Stoppschild-Dataset besteht aus 50 Bildern, die von Unsplash heruntergeladen wurden und jeweils mindestens ein Stoppschild enthalten.
Erstellen Sie eines neuen VoTT-Projekts
Laden Sie das Dataset mit 50 Bildern von Stoppschildern herunter, und entpacken Sie es.
Herunterladen von VoTT (Visual Object Tagging-Tool).
Öffnen Sie VoTT, und wählen Sie New Project (Neues Projekt) aus.
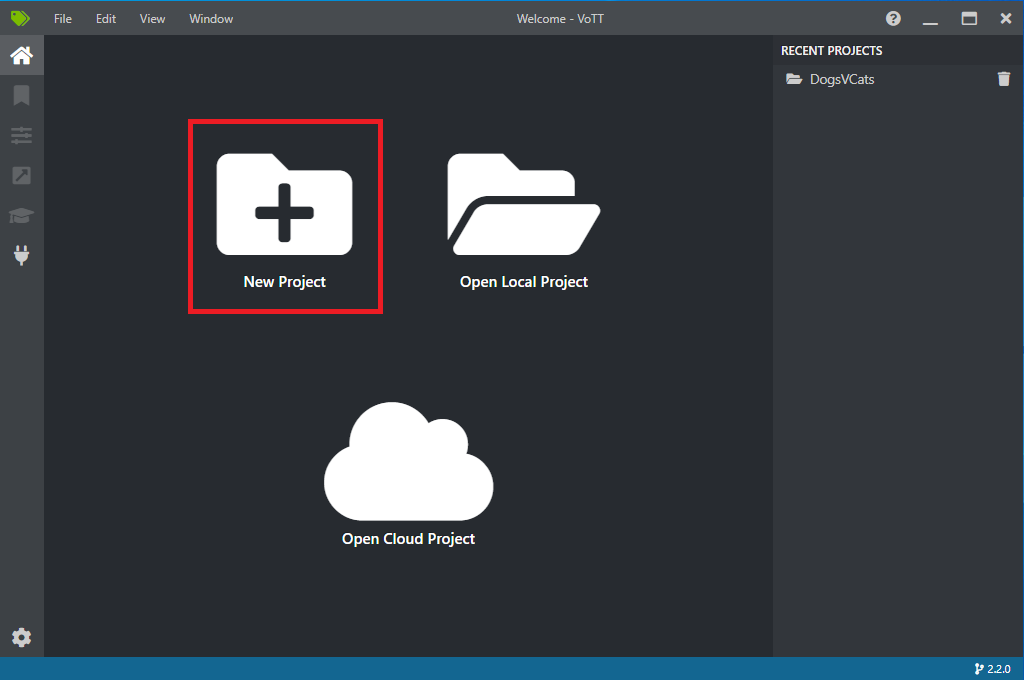
Ändern Sie Display Name (Anzeigenname) unter Project Settings (Projekteinstellungen) in „StopSignObjDetection“.
Ändern Sie Security Token (Sicherheitstoken) in Generate New Security Token (Neues Sicherheitstoken generieren).
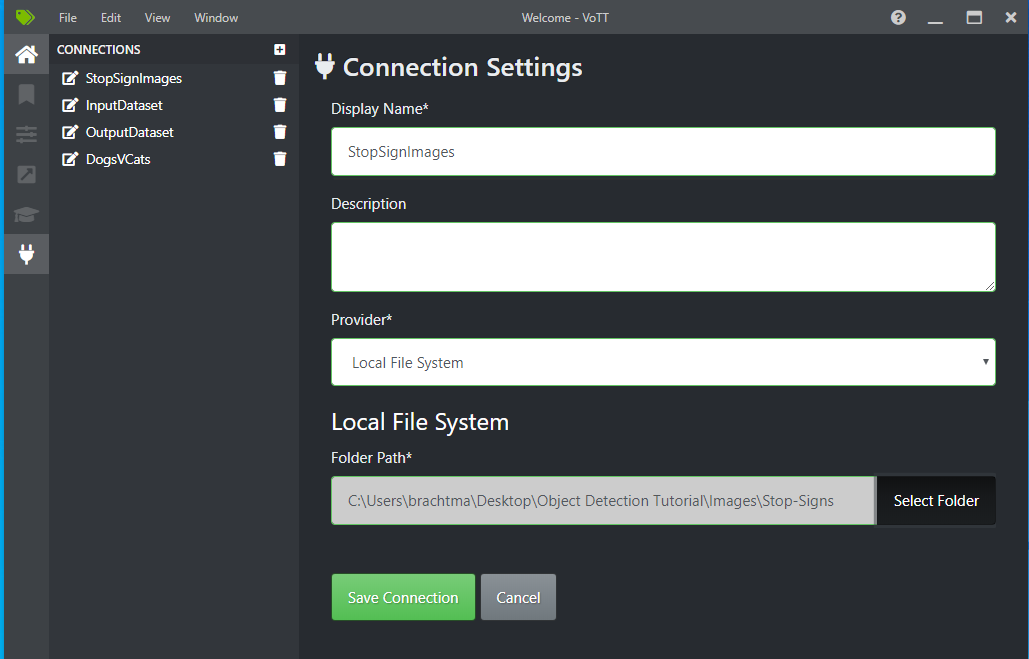
Wählen Sie neben Source Connection (Quellverbindung) die Option Add Connection (Verbindung hinzufügen) aus.
Ändern Sie unter Connection Settings (Verbindungseinstellungen) den Display Name (Anzeigenamen) für die Quellverbindung in „StopSignImages“, und wählen Sie Local File System (Lokales Dateisystem) als Provider (Anbieter) aus. Wählen Sie als Folder Path (Ordnerpfad) den Ordner Stop-Signs aus, der die 50 Trainingsbilder enthält, und wählen Sie dann Save Connection (Verbindung speichern) aus.
Ändern Sie unter Project Settings (Projekteinstellungen) Source Connection (Quellverbindung) in StopSignImages (die soeben erstellte Verbindung).
Ändern Sie auch die Target Connection (Zielverbindung) in StopSignImages. Ihre Projekteinstellungen sollten nun in etwa wie in diesem Screenshot aussehen:
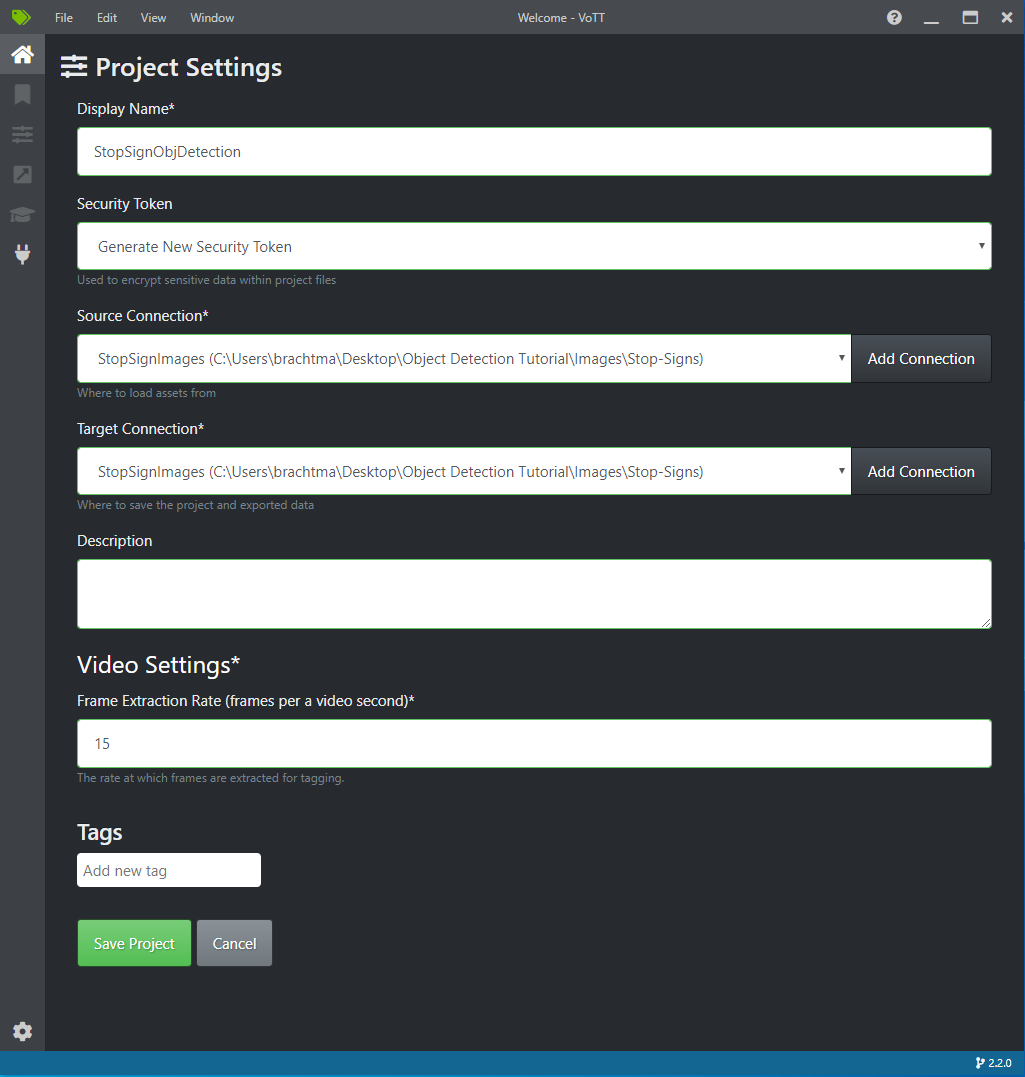
Wählen Sie Save Project (Projekt speichern) aus.
Hinzufügen von Tags und Beschriften der Bilder
Sie sollten nun ein Fenster mit Vorschaubildern aller Trainingsbilder auf der linken Seite, einer Vorschau des ausgewählten Bilds in der Mitte und einer Spalte Tags auf der rechten Seite sehen. Dieser Bildschirm ist der Tag-Editor.
Wählen Sie auf der Tags-Symbolleiste das erste Symbol (Pluszeichen) aus, um ein neues Tag hinzuzufügen.

Nennen Sie das Tag „Stop-Sign“, und drücken Sie die EINGABETASTE.

Klicken und ziehen Sie, um ein Rechteck um jedes Stoppzeichen im Bild zu zeichnen. Wenn Sie mit dem Cursor kein Rechteck zeichnen können, versuchen Sie, das Tool Rechteck zeichnen auf der oberen Symbolleiste auszuwählen, oder verwenden Sie den Tastaturkurzbefehl R.
Nachdem Sie das Rechteck gezeichnet haben, wählen Sie das Tag Stop-Sign aus, das Sie in den vorherigen Schritten erstellt haben, um das Tag dem umgebenden Rechteck hinzuzufügen.
Klicken Sie auf das Vorschaubild, um das nächste Bild im Dataset anzuzeigen, und wiederholen Sie diesen Vorgang.
Führen Sie die Schritte 3 bis 4 für jedes Stoppschild in jedem Bild aus.

Exportieren der VoTT-JSON-Datei
Nachdem Sie alle Trainingsbilder beschriftet haben, können Sie die Datei exportieren, die von Model Builder zum Trainieren verwendet wird.
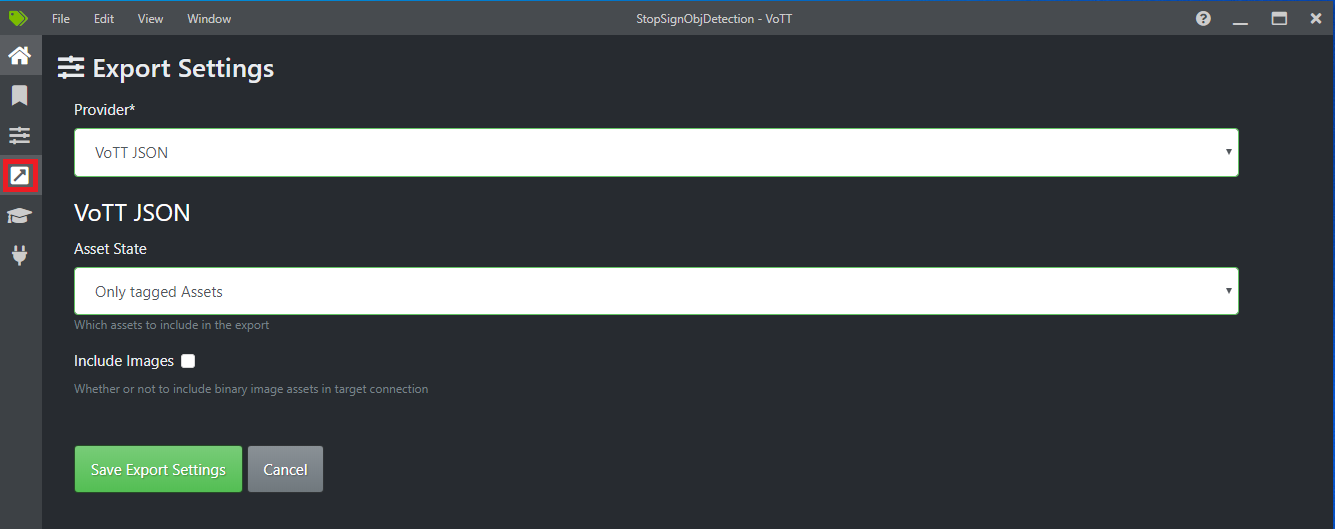
Wählen Sie das vierte Symbol auf der linken Symbolleiste (das Symbol mit dem diagonalen Pfeil in einem Feld) aus, um zu Export Settings (Einstellungen exportieren) zu gelangen.
Belassen Sie den Provider (Anbieter) als VoTT JSON.
Ändern Sie Asset State (Ressourcenstatus) in Only tagged Assets (Nur mit Tags versehene Ressourcen).
Deaktivieren Sie die Option Include Images (Bilder einschließen). Wenn Sie die Bilder einschließen, werden die Trainingsbilder in den generierten Exportordner kopiert. Dies ist nicht erforderlich.
Wählen Sie Save Export Settings (Exporteinstellungen speichern) aus.
Wechseln Sie zurück zum Tag-Editor (das zweite Symbol auf der linken Symbolleiste, das wie ein Band aussieht). Wählen Sie auf der oberen Symbolleiste das Symbol Projekt exportieren (das letzte Symbol, das wie ein Pfeil in einem Rechteck aussieht), oder verwenden Sie den Tastaturkurzbefehl STRG+E.

Dieser Export erstellt einen neuen Ordner namens vott-json-export in Ihrem Ordner Stop-Sign-Images und generiert eine JSON-Datei namens StopSignObjDetection-export in diesem neuen Ordner. Diese JSON-Datei wird in den nächsten Schritten zum Trainieren eines Objekterkennungsmodells in Model Builder verwendet.
Erstellen einer Konsolenanwendung
Erstellen Sie in Visual Studio eine C# .NET Core-Konsolenanwendung namens StopSignDetection.
Erstellen einer mbconfig-Datei
- Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt StopSignDetection, und wählen Sie Hinzufügen>Machine Learning Modell ... aus, um die Benutzeroberfläche des Model Builder zu öffnen.
- Geben Sie dem Model Builder-Projekt im Dialogfeld den Namen StopSignDetection, und klicken Sie auf Hinzufügen.
Auswählen eines Szenarios
Für dieses Beispiel ist das Szenario Objekterkennung. Wählen Sie im Schritt Szenario von Model Builder das Szenario Objekterkennung aus.
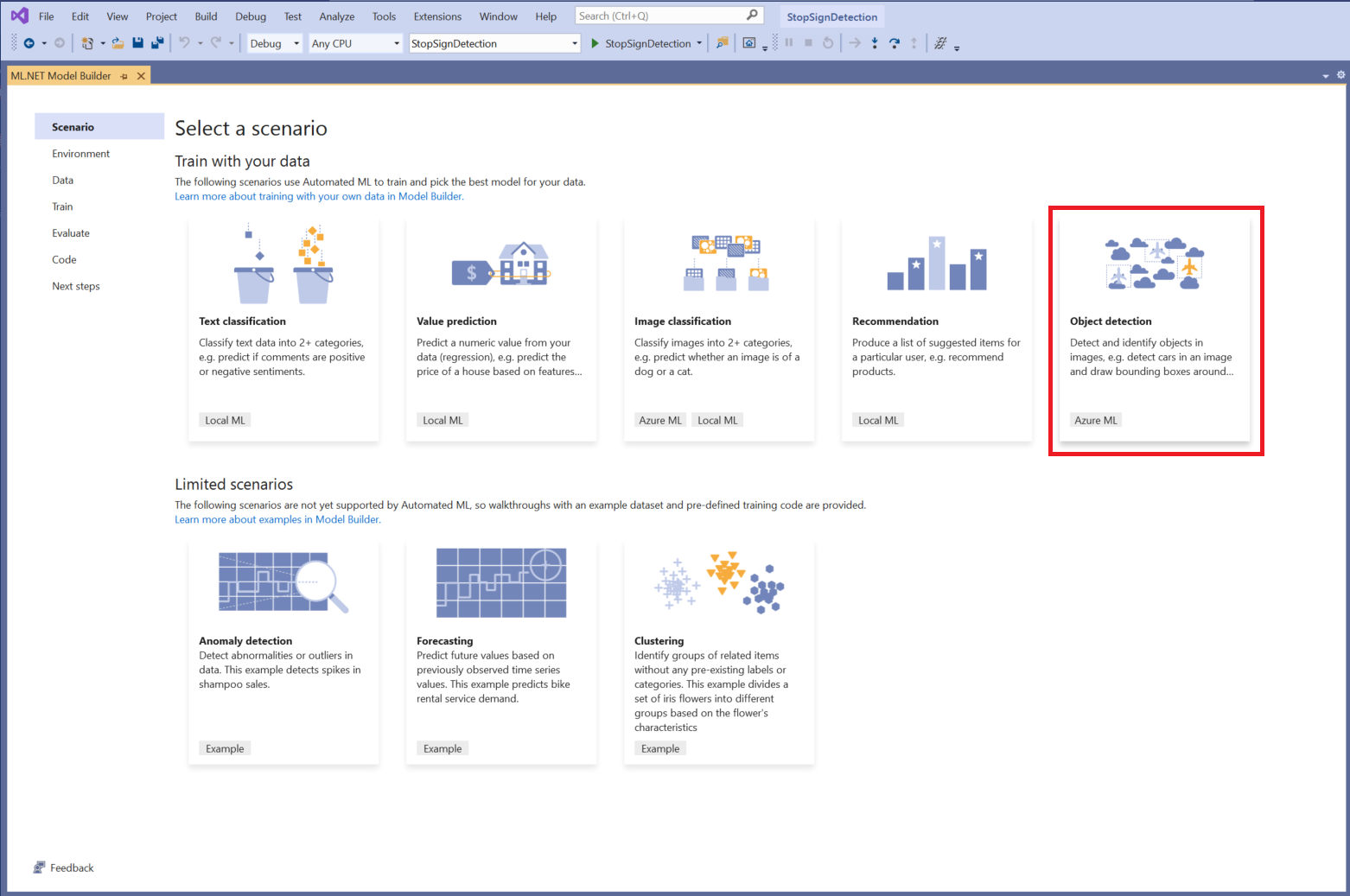
Wenn Objekterkennung in der Liste der Szenarien nicht angezeigt wird, müssen Sie möglicherweise Ihre Version von Model Builder aktualisieren.
Auswählen der Trainingsumgebung
Model Builder unterstützt nur das Trainieren von Objekterkennungsmodellen mit Azure Machine Learning, sodass die Azure-Trainingsumgebung standardmäßig ausgewählt ist.
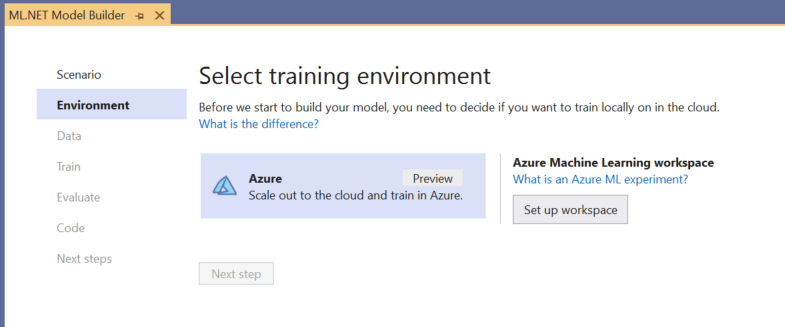
Zum Trainieren eines Modells mit Azure ML müssen Sie ein Azure ML-Experiment über Model Builder erstellen.
Ein Azure ML-Experiment ist eine Ressource, die die Konfiguration und die Ergebnisse für mindestens eine Ausführung des Machine Learning-Trainings kapselt.
Zum Erstellen eines Azure ML-Experiments müssen Sie zuerst Ihre Umgebung in Azure konfigurieren. Ein Experiment benötigt Folgendes für die Ausführung:
- Ein Azure-Abonnement
- Einen Arbeitsbereich: eine Azure ML-Ressource, die einen zentralen Ort für alle Azure ML-Ressourcen und Artefakte bietet, die als Teil eines Trainingslaufs erstellt werden.
- Eine Computeinstanz: Eine Azure Machine Learning-Computeinstanz ist eine cloudbasierte Linux-VM für das Training. Erfahren Sie mehr über die von Model Builder unterstützten Computetypen.
Einrichten eines Azure ML-Arbeitsbereichs
So konfigurieren Sie Ihre Umgebung:
Wählen Sie die Schaltfläche Arbeitsbereich einrichten aus.
Wählen Sie im Dialogfeld Neues Experiment erstellen Ihr Azure-Abonnement aus.
Wählen Sie einen vorhandenen Arbeitsbereich aus, oder erstellen Sie einen neuen Azure ML-Arbeitsbereich.
Wenn Sie einen neuen Arbeitsbereich erstellen, werden die folgenden Ressourcen für Sie bereitgestellt:
- Azure Machine Learning-Arbeitsbereich
- Azure Storage
- Azure Application Insights
- Azure Container Registry
- Azure-Schlüsseltresor
Dies führt dazu, dass dieser Vorgang einige Minuten in Anspruch nehmen kann.
Wählen Sie eine vorhandene Computeinstanz aus, oder erstellen Sie eine neue Azure ML-Computeinstanz. Dieser Vorgang kann einige Minuten in Anspruch nehmen.
Behalten Sie den Standardnamen des Experiments bei, und wählen Sie Erstellen aus.
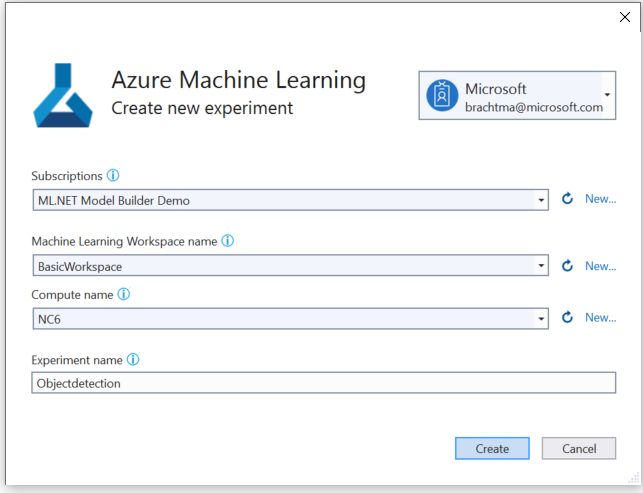
Das erste Experiment wird erstellt, und der Experimentname wird im Arbeitsbereich registriert. Alle nachfolgenden Ausführungen (wenn derselbe Experimentname verwendet wird) werden als Teil desselben Experiments protokolliert. Andernfalls wird ein neues Experiment erstellt.
Wenn Sie mit der Konfiguration zufrieden sind, wählen Sie im Model Builder die Schaltfläche Nächster Schritt aus, um zum Schritt Daten zu gelangen.
Laden der Daten
Im Schritt Daten von Model Builder wählen Sie das Trainingsdataset aus.
Wichtig
Model Builder akzeptiert derzeit nur das von VoTT generierte JSON-Format.
Wählen Sie die Schaltfläche im Abschnitt Eingabe aus, und verwenden Sie den Datei-Explorer, um die Datei
StopSignObjDetection-export.jsonzu suchen, die sich im Verzeichnis Stop-Signs/vott-json-export befinden sollte.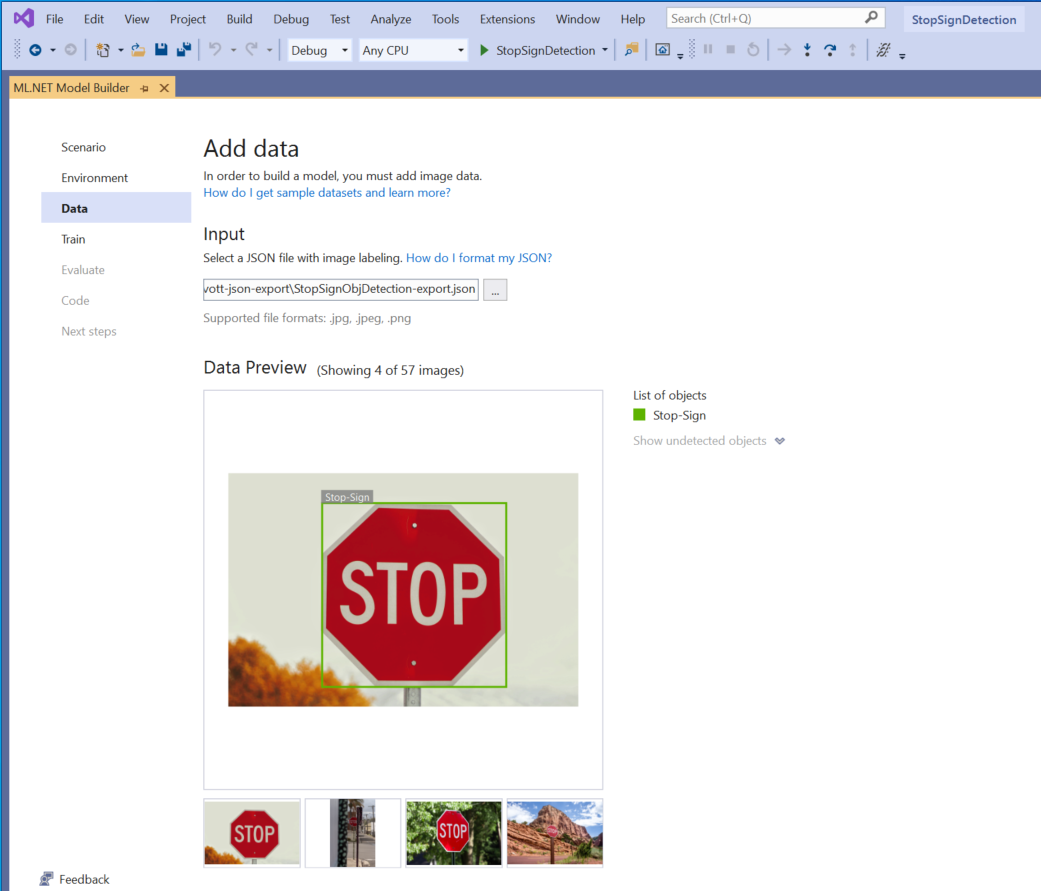
Wenn die Daten in der Datenvorschau richtig aussehen, klicken Sie auf Nächster Schritt, um Schritt Trainieren fortzufahren.
Trainieren des Modells
Der nächste Schritt ist das Trainieren Ihres Modells.
Wählen Sie im Bildschirm Trainieren von Model Builder die Schaltfläche Training starten aus.
An diesem Punkt werden Ihre Daten in Azure Storage hochgeladen, und der Trainingsprozess beginnt in Azure ML.
Der Trainingsprozess nimmt einige Zeit in Anspruch. Diese Zeitspanne kann je nach Computegröße und Datenmenge variieren. Wenn ein Modell zum ersten Mal in Azure trainiert wird, können Sie eine etwas längere Trainingszeit erwarten, da erst Ressourcen bereitgestellt werden müssen. Für dieses Beispiel mit 50 Bildern hat das Training ungefähr 16 Minuten gedauert.
Sie können den Status Ihrer Ausführung im Azure Machine Learning-Portal verfolgen, indem Sie den Link Aktuelle Ausführung im Azure-Portal verfolgen in Visual Studio auswählen.
Wählen Sie nach Abschluss des Trainings die Schaltfläche Nächster Schritt aus, um mit dem Schritt Evaluieren fortzufahren.
Evaluieren des Modells
Im Bildschirm „Evaluieren“ erhalten Sie eine Übersicht über die Ergebnisse aus dem Trainingsprozess, einschließlich der Modellgenauigkeit.
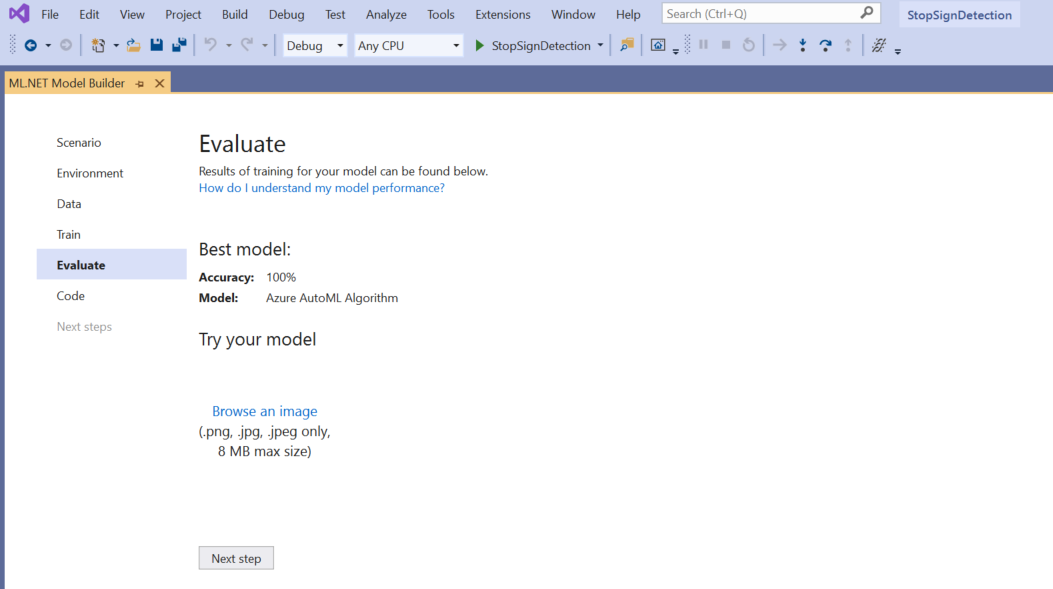
In diesem Fall beträgt die Genauigkeit 100 %, was bedeutet, dass das Modell höchstwahrscheinlich überangepasst ist, weil zu wenig Bilder im Dataset vorhanden sind.
Mit der Funktion Try your model (Modell testen) können Sie schnell überprüfen, ob Ihr Modell wie erwartet funktioniert.
Wählen Sie Browse an image (Bild suchen) aus, und geben Sie ein Testbild an, vorzugsweise eines, das vom Modell nicht als Teil des Trainings verwendet wurde.
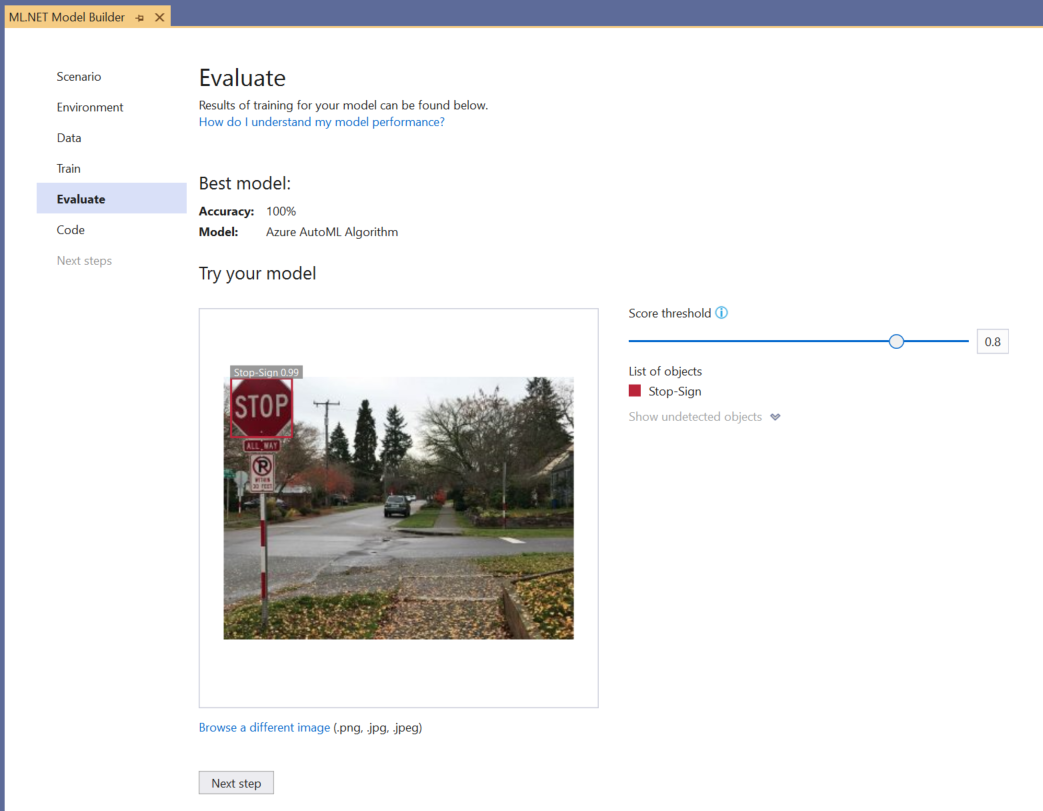
Das in jedem erkannten Begrenzungsrahmen angezeigte Ergebnis gibt die Konfidenz des erkannten Objekts an. Im Screenshot oben zeigt der Score am Begrenzungsrahmen um das Stoppschild beispielsweise an, dass das Modell zu 99 % sicher ist, dass es sich bei dem erkannten Objekt um ein Stoppschild handelt.
Der Scoreschwellenwert, der mit dem Schwellenwertschieberegler vergrößert oder verkleinert werden kann, fügt erkannte Objekte auf der Grundlage ihrer Scores hinzu und entfernt sie. Wenn der Schwellenwert beispielsweise auf 0,51 festgelegt ist, zeigt das Modell nur Objekte mit einem Konfidenzscore von 51 oder höher an. Wenn Sie den Schwellenwert erhöhen, werden weniger erkannte Objekte angezeigt, und wenn Sie den Schwellenwert verringern, werden weitere erkannte Objekte angezeigt.
Wenn Sie mit Ihren Genauigkeitsmetriken nicht zufrieden sind, besteht eine einfache Möglichkeit zum Verbessern der Modellgenauigkeit darin, eine größere Menge an Daten zu verwenden. Wählen Sie andernfalls den Link Nächster Schritt aus, um zum Schritt Consume (Nutzen) in Model Builder zu gelangen.
(Optional) Nutzen des Modells
Dieser Schritt enthält Projektvorlagen, mit denen Sie das Modell nutzen können. Dieser Schritt ist optional, und Sie können die Methode auswählen, die Ihren Anforderungen, das Modell zu bedienen, am besten entspricht.
- Konsolen-App
- Web-API
Konsolen-App
Wenn Sie Ihrer Projektmappe eine Konsolen-App hinzufügen, werden Sie aufgefordert, das Projekt zu benennen.
Nennen Sie das Konsolenprojekt StopSignDetection_Console.
Klicken Sie auf Zu Projektmappe hinzufügen, um das Projekt Ihrer aktuellen Projektmappe hinzuzufügen.
Führen Sie die Anwendung aus.
Die vom Programm generierte Ausgabe sollte wie der folgende Ausschnitt aussehen:
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
Web-API
Wenn Sie Ihrer Projektmappe eine Web-API hinzufügen, werden Sie aufgefordert, das Projekt zu benennen.
Nennen Sie das Web-API-Projekt StopSignDetection_API.
Klicken Sie auf Zu Projektmappe hinzufügen, um das Projekt Ihrer aktuellen Projektmappe hinzuzufügen.
Führen Sie die Anwendung aus.
Öffnen Sie PowerShell, und geben Sie den folgenden Code ein, wobei PORT der Port ist, auf dem Ihre Anwendung lauscht.
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"Bei erfolgreicher Ausführung sollte die Ausgabe dem folgenden Text ähneln.
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}- Die
boxes-Spalte gibt die Begrenzungsfeldkoordinaten des erkannten Objekts an. Die Werte gehören hier jeweils zu den Koordinaten links, oben, rechts und unten. - Die
labelssind der Index der vorhergesagten Bezeichnungen. In diesem Fall ist der Wert 1 ein Stoppzeichen. scoresdefiniert, wie sicher das Modell ist, dass das Begrenzungsfeld zu dieser Bezeichnung gehört.
Hinweis
(Optional) Die Koordinaten des Begrenzungsrahmens werden für eine Breite von 800 Pixel und eine Höhe von 600 Pixeln normalisiert. Damit die Koordinaten des Begrenzungsrahmens für das Bild bei der weiteren Nachbearbeitung skaliert werden, müssen Sie folgende Schritte ausführen:
- Multiplizieren Sie die oberen und unteren Koordinaten mit der ursprünglichen Bildhöhe, und multiplizieren Sie die linken und rechten Koordinaten mit der ursprünglichen Bildbreite.
- Dividieren Sie die oberen und unteren Koordinaten durch 600, und dividieren Sie die linken und rechten Koordinaten durch 800.
Beispielsweise zeigt der folgende Codeausschnitt, wie die
BoundingBox-Koordinaten anhand der ursprünglichen BilddimensionenactualImageHeightundactualImageWidthund einerModelOutputmit Namenpredictionskaliert werden:var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;Ein Bild kann mehrere Begrenzungsrahmen aufweisen, sodass derselbe Prozess auf jeden Begrenzungsrahmen im Bild angewendet werden muss.
- Die
Herzlichen Glückwunsch! Sie haben erfolgreich ein Machine Learning-Modell erstellt, um Stoppschilder in Bildern mithilfe von Model Builder zu erkennen. Sie finden den Quellcode für dieses Tutorial im GitHub-Repository dotnet/machinelearning-samples.
Zusätzliche Ressourcen
Weitere Informationen zu den in diesem Tutorial erwähnten Themen finden Sie in den folgenden Ressourcen:
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.