Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Erfahren Sie, wie Sie ein vortrainiertes ONNX-Modell in ML.NET verwenden, um Objekte in Bildern zu erkennen.
Das Training eines Objekterkennungsmodells erfordert das Festlegen von Millionen von Parametern, eine große Menge bezeichneter Schulungsdaten und eine große Menge an Rechenressourcen (Hunderte von GPU-Stunden). Durch die Verwendung eines vorab trainierten Modells können Sie den Trainingsprozess abkürzen.
In diesem Tutorial erfahren Sie, wie:
- Verstehen des Problems
- Erfahren Sie, was ONNX ist und wie es mit ML.NET zusammenarbeitet.
- Grundlegendes zum Modell
- Wiederverwenden des vortrainierten Modells
- Erkennen von Objekten mit einem geladenen Modell
Voraussetzungen
- Visual Studio 2022 oder höher.
- Microsoft.ML NuGet-Paket
- Microsoft.ML.ImageAnalytics NuGet-Paket
- Microsoft.ML.OnnxTransformer NuGet-Paket
- Vortrainiertes Tiny YOLOv2-Modell
- Netron (optional)
Übersicht über das ONNX-Objekterkennungsbeispiel
In diesem Beispiel wird eine .NET Core-Konsolenanwendung erstellt, die Objekte innerhalb eines Bilds mithilfe eines vordefinierten Deep Learning-ONNX-Modells erkennt. Der Code für dieses Beispiel finden Sie im Repository "dotnet/machinelearning-samples " auf GitHub.
Was ist die Objekterkennung?
Objekterkennung ist ein Computervisionsproblem. Während die Objekterkennung eng mit der Bildklassifizierung verknüpft ist, führt die Objekterkennung die Bildklassifizierung in einer differenzierteren Skalierung durch. Die Objekterkennung sucht und kategorisiert Entitäten innerhalb von Bildern. Objekterkennungsmodelle werden häufig mithilfe von Deep Learning und neuralen Netzwerken trainiert. Weitere Informationen finden Sie unter Deep Learning vs Machine Learning .
Verwenden Sie die Objekterkennung, wenn Bilder mehrere Objekte unterschiedlicher Typen enthalten.

Einige Anwendungsfälle für die Objekterkennung umfassen:
- Autonome Fahrzeuge
- Robotertechnik
- Gesichtserkennung
- Sicherheit am Arbeitsplatz
- Objektzählung
- Aktivitätserkennung
Auswählen eines Deep Learning-Modells
Deep Learning ist eine Teilmenge des maschinellen Lernens. Um Deep Learning-Modelle zu trainieren, sind große Datenmengen erforderlich. Muster in den Daten werden durch eine Reihe von Ebenen dargestellt. Die Beziehungen in den Daten werden als Verbindungen zwischen den Ebenen codiert, die Gewichtungen enthalten. Je höher die Gewichtung, desto stärker die Beziehung. Zusammen werden diese Reihe von Schichten und Verbindungen als künstliche neurale Netzwerke bezeichnet. Je mehr Ebenen in einem Netzwerk, desto tiefer ist es, was es zu einem tiefen neuralen Netzwerk macht.
Es gibt verschiedene Arten von neuronalen Netzwerken, die am häufigsten Multischichtes Perceptron (MLP), Konvolutionales Neuronales Netzwerk (CNN) und Wiederkehrendes Neuronales Netzwerk (RNN). Am einfachsten ist der MLP, der eine Reihe von Eingaben einem Satz von Ausgaben zuordnet. Dieses neurale Netzwerk ist gut, wenn die Daten keine räumliche oder zeitbezogene Komponente aufweisen. Der CNN verwendet konvolutionale Ebenen, um räumliche Informationen zu verarbeiten, die in den Daten enthalten sind. Ein guter Anwendungsfall für CNNs ist die Bildverarbeitung, um das Vorhandensein eines Features in einem Bereich eines Bilds zu erkennen (z. B. gibt es eine Nase in der Mitte eines Bilds?). Schließlich ermöglichen RNNs die Verwendung eines persistenten Speicherzustands als Eingabe. RNNs werden für Zeitreihenanalysen verwendet, bei denen die sequenzielle Anordnung und der Kontext von Ereignissen wichtig sind.
Grundlegendes zum Modell
Objekterkennung ist eine Bildverarbeitungsaufgabe. Daher sind die meisten Deep-Learning-Modelle, die trainiert wurden, um dieses Problem zu lösen, Convolutional Neural Networks (CNNs). Das in diesem Lernprogramm verwendete Modell ist das Tiny YOLOv2-Modell, eine kompaktere Version des YOLOv2-Modells, das im Papier beschrieben wird: "YOLO9000: Better, Faster, Stronger" von Redmon und Farhadi. Tiny YOLOv2 wird auf dem Pascal VOC-Dataset trainiert und besteht aus 15 Schichten, die 20 verschiedene Klassen von Objekten vorhersagen können. Da Tiny YOLOv2 eine komprimierte Version des ursprünglichen YOLOv2-Modells ist, wird ein Kompromiss zwischen Geschwindigkeit und Genauigkeit hergestellt. Die verschiedenen Ebenen, aus denen das Modell besteht, können mithilfe von Tools wie Netron visualisiert werden. Bei der Prüfung des Modells würde eine Zuordnung der Verbindungen zwischen allen Ebenen erzielt, aus denen das neurale Netzwerk besteht, wobei jede Ebene den Namen der Ebene zusammen mit den Dimensionen der jeweiligen Eingabe/Ausgabe enthalten würde. Die Zum Beschreiben der Eingaben und Ausgaben des Modells verwendeten Datenstrukturen werden als Tensoren bezeichnet. Tensoren können als Container betrachtet werden, die Daten in N-Dimensionen speichern. Im Fall von Tiny YOLOv2 ist image der Name der Eingabeschicht und erwartet einen Tensor von Dimensionen 3 x 416 x 416. Der Name der Ausgabeebene ist grid und generiert einen Ausgabe-Tensor von Dimensionen 125 x 13 x 13.

Das YOLO-Modell verwendet ein Bild 3(RGB) x 416px x 416px. Das Modell verwendet diese Eingabe und übergibt sie über die verschiedenen Ebenen, um eine Ausgabe zu erzeugen. Die Ausgabe teilt das Eingabebild in ein 13 x 13 Raster auf, wobei jede Zelle im Raster aus 125 Werten besteht.
Was ist ein ONNX-Modell?
Der Open Neural Network Exchange (ONNX) ist ein Open Source-Format für KI-Modelle. ONNX unterstützt die Interoperabilität zwischen Frameworks. Dies bedeutet, dass Sie ein Modell in einem der vielen gängigen Machine Learning Frameworks wie PyTorch trainieren, es in das ONNX-Format konvertieren und das ONNX-Modell in einem anderen Framework wie ML.NET verwenden können. Weitere Informationen finden Sie auf der ONNX-Website.

Das vortrainierte Tiny YOLOv2-Modell wird im ONNX-Format gespeichert, eine serialisierte Darstellung der Schichten und gelernten Muster dieser Schichten. In ML.NET wird die Interoperabilität mit ONNX mit den ImageAnalyticsOnnxTransformer NuGet-Paketen erreicht. Das ImageAnalytics Paket enthält eine Reihe von Transformationen, die ein Bild aufnehmen und in numerische Werte codieren können, die als Eingabe in eine Vorhersage- oder Schulungspipeline verwendet werden können. Das OnnxTransformer Paket nutzt die ONNX-Runtime zum Laden eines ONNX-Modells und verwendet es, um Vorhersagen basierend auf der bereitgestellten Eingabe zu erstellen.
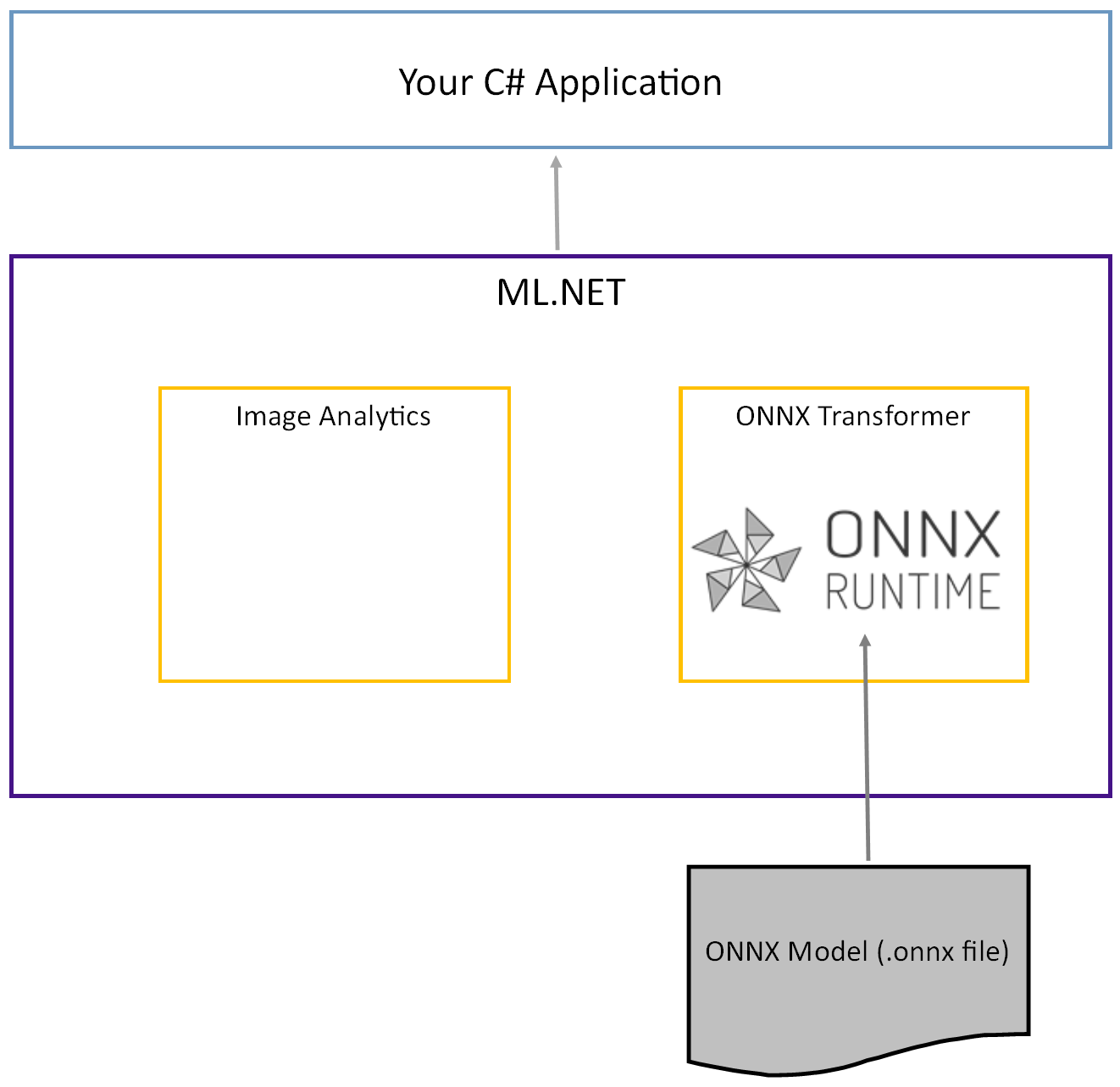
Einrichten des .NET-Konsolenprojekts
Nachdem Sie nun ein allgemeines Verständnis darüber haben, was ONNX ist und wie Tiny YOLOv2 funktioniert, ist es an der Zeit, die Anwendung zu erstellen.
Erstellen einer Konsolenanwendung
Erstellen Sie eine C# -Konsolenanwendung namens "ObjectDetection". Klicken Sie auf die Schaltfläche Weiter .
Wählen Sie .NET 8 als zu verwendende Framework aus. Klicken Sie auf die Schaltfläche " Erstellen ".
Installieren Sie das Microsoft.ML NuGet-Paket:
Hinweis
In diesem Beispiel wird die neueste stabile Version der erwähnten NuGet-Pakete verwendet, sofern nichts anderes angegeben ist.
- Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf Ihr Projekt, und wählen Sie "NuGet-Pakete verwalten" aus.
- Wählen Sie "nuget.org" als Paketquelle aus, wählen Sie die Registerkarte "Durchsuchen" aus, suchen Sie nach Microsoft.ML.
- Wählen Sie die Schaltfläche Installieren aus.
- Wählen Sie im Dialogfeld "Vorschauänderungen" die Schaltfläche "OK" und dann im Dialogfeld "Lizenzakzeptanz" die Schaltfläche "Ich stimme zu", wenn Sie den Lizenzbedingungen für die aufgeführten Pakete zustimmen.
- Wiederholen Sie diese Schritte für Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer und Microsoft.ML.OnnxRuntime.
Bereiten Sie Ihre Daten und das vortrainierte Modell vor.
Laden Sie die Zip-Datei des Projektressourcenverzeichnisses herunter, und entpacken Sie sie.
Kopieren Sie das
assetsVerzeichnis in Ihr ObjectDetection-Projektverzeichnis . Dieses Verzeichnis und seine Unterverzeichnisse enthalten die Bilddateien (mit Ausnahme des Tiny YOLOv2-Modells, das Sie im nächsten Schritt herunterladen und hinzufügen werden), die für dieses Lernprogramm erforderlich sind.Laden Sie das Tiny YOLOv2-Modell aus dem ONNX Model Zoo herunter.
Kopieren Sie die
model.onnxDatei in Ihr ObjectDetection-Projektverzeichnisassets\Modelund benennen Sie sie inTinyYolo2_model.onnxum. Dieses Verzeichnis enthält das für dieses Lernprogramm erforderliche Modell.Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf die dateien im Objektverzeichnis und unterverzeichnisse, und wählen Sie "Eigenschaften" aus. Ändern Sie unter Erweitert den Wert von In Ausgabeordner kopieren in Kopieren, wenn neuer.
Erstellen von Klassen und Definieren von Pfaden
Öffnen Sie die Program.cs Datei, und fügen Sie oben in der Datei die folgenden zusätzlichen using Direktiven hinzu:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Definieren Sie als Nächstes die Pfade der verschiedenen Ressourcen.
Erstellen Sie zunächst die
GetAbsolutePathMethode unten in der datei Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Erstellen Sie dann unter den
usingDirektiven Felder, um den Speicherort Ihrer Objekte zu speichern.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Fügen Sie Ihrem Projekt ein neues Verzeichnis hinzu, um Ihre Eingabedaten und Vorhersageklassen zu speichern.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und wählen Sie dann "Neuen Ordner>" aus. Wenn der neue Ordner im Projektmappen-Explorer angezeigt wird, nennen Sie ihn "DataStructures".
Erstellen Sie Ihre Eingabedatenklasse im neu erstellten DataStructures-Verzeichnis .
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Verzeichnis "DataStructures", und wählen Sie dann "> hinzufügen" aus.
Wählen Sie im Dialogfeld " Neues Element hinzufügen " " Klasse " aus, und ändern Sie das Feld "Name " in ImageNetData.cs. Klicken Sie anschließend auf Hinzufügen.
Die ImageNetData.cs Datei wird im Code-Editor geöffnet. Fügen Sie oben
usingdie folgende Direktive hinzu:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Entfernen Sie die vorhandene Klassendefinition, und fügen Sie der
ImageNetDataden folgenden Code für die Klasse hinzu:public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataist die Eingabebilddatenklasse und weist die folgenden String Felder auf:-
ImagePathenthält den Pfad, in dem das Bild gespeichert ist. -
Labelenthält den Namen der Datei.
Enthält darüber hinaus eine Methode
ImageNetData,ReadFromFilemit der mehrere im angegebenen Pfad gespeicherteimageFolderBilddateien geladen und als Auflistung vonImageNetDataObjekten zurückgegeben werden.-
Erstellen Sie Ihre Vorhersageklasse im DataStructures-Verzeichnis .
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Verzeichnis "DataStructures", und wählen Sie dann "> hinzufügen" aus.
Wählen Sie im Dialogfeld " Neues Element hinzufügen " " Klasse " aus, und ändern Sie das Feld "Name " in ImageNetPrediction.cs. Klicken Sie anschließend auf Hinzufügen.
Die ImageNetPrediction.cs Datei wird im Code-Editor geöffnet. Fügen Sie oben
usingdie folgende Direktive hinzu:using Microsoft.ML.Data;Entfernen Sie die vorhandene Klassendefinition, und fügen Sie der
ImageNetPredictionden folgenden Code für die Klasse hinzu:public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictionist die Vorhersagedatenklasse und weist das folgendefloat[]Feld auf:-
PredictedLabelsenthält die Dimensionen, die Objektheitsbewertung und die Klassenwahrscheinlichkeiten für jede der in einem Bild erkannten Begrenzungsrahmen.
-
Initialisieren der Variablen
Die MLContext-Klasse ist ein Ausgangspunkt für alle ML.NET-Vorgänge, und das Initialisieren von mlContext erstellt eine neue ML.NET-Umgebung, die für die Modell-Erstellungs-Workflow-Objekte freigegeben werden kann. Es ist konzeptionell ähnlich wie DBContext im Entity Framework.
Initialisieren Sie die mlContext Variable mit einer neuen Instanz, indem MLContext Sie die folgende Zeile unterhalb des outputFolder Felds hinzufügen.
MLContext mlContext = new MLContext();
Einen Parser zum Nachverarbeiten von Modellausgaben erstellen
Das Modell segmentiert ein Bild in ein 13 x 13 Raster, wobei jede Rasterzelle ist 32px x 32px. Jede Rasterzelle enthält 5 potenzielle Objekt-Begrenzungsfelder. Ein Begrenzungsrahmen hat 25 Elemente.

-
xdie x-Position des Mittelpunkts der Begrenzungsbox relativ zu der Gitternetzzelle, mit der sie verbunden ist. -
ydie y-Position des Mittelpunkts des Begrenzungsrahmens relativ zur Rasterzelle, der er zugeordnet ist. -
wdie Breite des Begrenzungsrahmens. -
hdie Höhe des Begrenzungsrahmens. -
oder Konfidenzwert, der angibt, dass ein Objekt innerhalb des Begrenzungsrahmens existiert, auch bekannt als Objektheitswert. -
p1-p20Klassenwahrscheinlichkeiten für jede der 20 Klassen, die vom Modell vorhergesagt werden.
Insgesamt bilden die 25 Elemente, die die 5 Begrenzungsrahmen beschreiben, die 125 Elemente, die in jeder Rasterzelle enthalten sind.
Die durch das vortrainierte ONNX-Modell generierte Ausgabe ist ein Float-Array der Länge 21125, das die Elemente eines Tensors mit Dimensionen 125 x 13 x 13darstellt. Um die vom Modell generierten Vorhersagen in einen Tensor umzuwandeln, sind einige Nachbearbeitungsarbeiten erforderlich. Erstellen Sie dazu eine Reihe von Klassen, um die Ausgabe zu analysieren.
Fügen Sie Ihrem Projekt ein neues Verzeichnis hinzu, um eine Sammlung von Parserklassen zu organisieren.
- Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und wählen Sie dann "Neuen Ordner>" aus. Wenn der neue Ordner im Projektmappen-Explorer angezeigt wird, nennen Sie ihn "YoloParser".
Erstellen Sie Begrenzungsrahmen und Dimensionen
Die Datenausgabe des Modells enthält Koordinaten und Dimensionen der Begrenzungsrahmen von Objekten innerhalb des Bildes. Erstellen Sie eine Basisklasse für Dimensionen.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Verzeichnis "YoloParser", und wählen Sie dann "Neues Element> aus.
Wählen Sie im Dialogfeld " Neues Element hinzufügen " " Klasse " aus, und ändern Sie das Feld "Name " in DimensionsBase.cs. Klicken Sie anschließend auf Hinzufügen.
Die DimensionsBase.cs Datei wird im Code-Editor geöffnet. Entfernen Sie alle
usingDirektiven und vorhandene Klassendefinitionen.Fügen Sie der
DimensionsBaseden folgenden Code für die Klasse hinzu:public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBasehat die folgendenfloatEigenschaften:-
Xenthält die Position des Objekts entlang der X-Achse. -
Yenthält die Position des Objekts entlang der Y-Achse. -
Heightenthält die Höhe des Objekts. -
Widthenthält die Breite des Objekts.
-
Erstellen Sie eine Klasse für Ihre Begrenzungsrahmen.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Verzeichnis "YoloParser", und wählen Sie dann "Neues Element> aus.
Wählen Sie im Dialogfeld " Neues Element hinzufügen " " Klasse " aus, und ändern Sie das Feld "Name " in YoloBoundingBox.cs. Klicken Sie anschließend auf Hinzufügen.
Die YoloBoundingBox.cs Datei wird im Code-Editor geöffnet. Fügen Sie die folgende
usingDirektive oben in YoloBoundingBox.cs hinzu:using System.Drawing;Fügen Sie direkt oberhalb der vorhandenen Klassendefinition eine neue Klassendefinition
BoundingBoxDimensionshinzu, die von derDimensionsBaseKlasse erbt, um die Dimensionen des jeweiligen begrenzenden Rechtecks zu enthalten.public class BoundingBoxDimensions : DimensionsBase { }Entfernen Sie die vorhandene
YoloBoundingBoxKlassendefinition, und fügen Sie derYoloBoundingBoxden folgenden Code für die Klasse hinzu:public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxhat die folgenden Eigenschaften:-
Dimensionsenthält Abmessungen des Begrenzungsrahmens. -
Labelenthält die Klasse des Objekts, das innerhalb des Begrenzungsrahmens erkannt wurde. -
Confidenceenthält die Zuversicht der Klasse. -
Rectenthält die Rechteckdarstellung der Abmessungen des Begrenzungsrahmens. -
BoxColorenthält die Farbe, die der jeweiligen Klasse zugeordnet ist, die zum Zeichnen auf dem Bild verwendet wird.
-
Erstellen des Parsers
Nachdem die Klassen für Dimensionen und Begrenzungsrahmen erstellt wurden, ist es an der Zeit, den Parser zu erstellen.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Verzeichnis "YoloParser", und wählen Sie dann "Neues Element> aus.
Wählen Sie im Dialogfeld " Neues Element hinzufügen " " Klasse " aus, und ändern Sie das Feld "Name " in YoloOutputParser.cs. Klicken Sie anschließend auf Hinzufügen.
Die YoloOutputParser.cs Datei wird im Code-Editor geöffnet. Fügen Sie oben
usingdie folgenden Direktiven hinzu:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;Fügen Sie innerhalb der vorhandenen
YoloOutputParserKlassendefinition eine geschachtelte Klasse hinzu, die die Abmessungen jeder Zelle im Bild enthält. Fügen Sie den folgenden Code für dieCellDimensionsKlasse hinzu, die von derDimensionsBaseKlasse am Anfang derYoloOutputParserKlassendefinition erbt.class CellDimensions : DimensionsBase { }Fügen Sie innerhalb der
YoloOutputParserKlassendefinition die folgenden Konstanten und Felder hinzu.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNTist die Anzahl der Zeilen im Raster, in die das Bild unterteilt ist. -
COL_COUNTist die Anzahl der Spalten im Raster, in die das Bild unterteilt ist. -
CHANNEL_COUNTist die Gesamtanzahl der Werte, die in einer Zelle des Rasters enthalten sind. -
BOXES_PER_CELList die Anzahl der begrenzenden Boxen in einer Zelle. -
BOX_INFO_FEATURE_COUNTist die Anzahl der Features, die in einem Feld enthalten sind (x,y,Höhe,Breite,Konfidenz). -
CLASS_COUNTist die Anzahl der Klassenvorhersagen, die in jedem umgebenden Feld enthalten sind. -
CELL_WIDTHist die Breite einer Zelle im Bildraster. -
CELL_HEIGHTist die Höhe einer Zelle im Bildraster. -
channelStrideist die Startposition der aktuellen Zelle im Raster.
Wenn das Modell eine Vorhersage macht, auch als Scoring (Bewertung) bezeichnet, teilt es das
416px x 416pxEingabebild in ein Raster von Zellen der Größe13 x 13. Jede Zelle enthält folgendes:32px x 32pxInnerhalb jeder Zelle gibt es fünf Begrenzungsrahmen, die jeweils fünf Merkmale enthalten (x, y, Breite, Höhe, Konfidenz). Darüber hinaus enthält jedes Begrenzungsfeld die Wahrscheinlichkeit jedes der Klassen, die in diesem Fall 20 beträgt. Daher enthält jede Zelle 125 Informationen (5 Merkmale + 20 Klassenwahrscheinlichkeiten).-
Erstellen Sie eine Liste der Verankerungen unterhalb channelStride für alle fünf Begrenzungsrahmen.
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Anker sind vordefinierte Höhen- und Breitenverhältnisse von Begrenzungsrahmen. Die meisten von einem Modell erkannten Objekte oder Klassen weisen ähnliche Verhältnisse auf. Dies ist nützlich, wenn es darum geht, Begrenzungsrahmen zu erstellen. Anstatt die umgebenden Felder vorherzusagen, wird der Offset aus den vordefinierten Dimensionen berechnet, wodurch die Berechnung reduziert wird, die erforderlich ist, um das umgebende Feld vorherzusagen. In der Regel werden diese Ankerverhältnisse basierend auf dem verwendeten Dataset berechnet. Da das Dataset bekannt ist und die Werte vorkompiliert wurden, können die Anker hartcodiert werden.
Definieren Sie als Nächstes die Bezeichnungen oder Klassen, die vom Modell vorhergesagt werden. Dieses Modell prognostiziert 20 Klassen, bei denen es sich um eine Teilmenge der Gesamtzahl der klassen handelt, die vom ursprünglichen YOLOv2-Modell vorhergesagt wurden.
Fügen Sie Ihre Liste der Labels unter die anchors hinzu.
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Jeder Klasse sind Farben zugeordnet. Weisen Sie Ihre Klassenfarben unter Ihren labels:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Erstellen von Hilfsfunktionen
Es gibt eine Reihe von Schritten, die in der Nachbearbeitungsphase involviert sind. Dazu können mehrere Hilfsmethoden eingesetzt werden.
Die Hilfsmethoden, die vom Parser verwendet werden, sind:
-
Sigmoidwendet die Sigmoidfunktion an, die eine Zahl zwischen 0 und 1 ausgibt. -
Softmaxnormalisiert einen Eingabevektor in eine Wahrscheinlichkeitsverteilung. -
GetOffsetordnet Elemente in der eindimensionalen Modellausgabe der entsprechenden Position in einem125 x 13 x 13Tensor zu. -
ExtractBoundingBoxesextrahiert die Abmessungen des Begrenzungsrahmens mithilfe der MethodeGetOffsetaus der Modellausgabe. -
GetConfidenceextrahiert den Konfidenzwert, der angibt, wie sicher das Modell ist, dass es ein Objekt erkannt hat, und verwendet dieSigmoidFunktion, um sie in einen Prozentsatz umzuwandeln. -
MapBoundingBoxToCellverwendet die Bounding-Box-Abmessungen und ordnet sie ihrer jeweiligen Zelle innerhalb des Bildes zu. -
ExtractClassesextrahiert die Klassenvorhersagen für den Begrenzungsrahmen aus der Modellausgabe mithilfe der MethodeGetOffsetund wandelt sie mithilfe der MethodeSoftmaxin eine Wahrscheinlichkeitsverteilung um. -
GetTopResultwählt die Klasse aus der Liste der vorhergesagten Klassen mit der höchsten Wahrscheinlichkeit aus. -
IntersectionOverUnionFilter, die begrenzungsgebundene Felder mit niedrigeren Wahrscheinlichkeiten überlappen.
Fügen Sie den Code für alle Hilfsmethoden unterhalb der Liste der classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Nachdem Sie alle Hilfsmethoden definiert haben, ist es an der Zeit, sie zum Verarbeiten der Modellausgabe zu verwenden.
Erstellen Sie unter der IntersectionOverUnion Methode die ParseOutputs Methode, um die vom Modell generierte Ausgabe zu verarbeiten.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Erstellen Sie eine Liste, um die Begrenzungsrahmen zu speichern, und definieren Sie Variablen in der ParseOutputs Methode.
var boxes = new List<YoloBoundingBox>();
Jedes Bild wird in ein Zellenraster 13 x 13 unterteilt. Jede Zelle enthält fünf begrenzende Boxen. Fügen Sie unterhalb der boxes Variablen Code hinzu, um alle Felder in den einzelnen Zellen zu verarbeiten.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
Berechnen Sie innerhalb der innersten Schleife die Startposition des aktuellen Felds innerhalb der eindimensionalen Modellausgabe.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Verwenden Sie die ExtractBoundingBoxDimensions Methode direkt darunter, um die Abmessungen des aktuellen Begrenzungsrahmens abzurufen.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Verwenden Sie dann die GetConfidence-Methode, um die Konfidenz für den aktuellen Umgrenzungsrahmen abzurufen.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Verwenden Sie anschließend die MapBoundingBoxToCell Methode, um das aktuelle umgebende Feld der aktuellen Zelle zuzuordnen, die verarbeitet wird.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Überprüfen Sie vor der weiteren Verarbeitung, ob Ihr Konfidenzwert größer als der angegebene Schwellenwert ist. Falls nicht zutreffend, verarbeiten Sie die nächste Begrenzungsbox.
if (confidence < threshold)
continue;
Andernfalls fahren Sie mit der Verarbeitung der Ausgabe fort. Der nächste Schritt besteht darin, die Wahrscheinlichkeitsverteilung der vorhergesagten Klassen für den aktuellen begrenzenden Rahmen mit der Methode ExtractClasses abzurufen.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Verwenden Sie dann die GetTopResult Methode, um den Wert und den Index der Klasse mit der höchsten Wahrscheinlichkeit für das aktuelle Feld abzurufen und deren Bewertung zu berechnen.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Verwenden Sie die topScore Funktion, um erneut nur die begrenzungsgebundenen Felder beizubehalten, die sich über dem angegebenen Schwellenwert befinden.
if (topScore < threshold)
continue;
Wenn die aktuelle Bounding-Box den Schwellenwert überschreitet, erstellen Sie ein neues BoundingBox Objekt und fügen Sie es der boxes Liste hinzu.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Nachdem alle Zellen im Bild verarbeitet wurden, geben Sie die boxes Liste zurück. Fügen Sie die folgende Rückgabe-Anweisung unterhalb der äußersten For-Loop-Anweisung in der ParseOutputs Methode hinzu.
return boxes;
Überlappende Boxen filtern
Da nun alle hochsicheren Begrenzungsfelder aus der Modellausgabe extrahiert wurden, muss zusätzliche Filterung durchgeführt werden, um überlappende Bilder zu entfernen. Fügen Sie eine Methode hinzu, die unter der FilterBoundingBoxes Methode aufgerufen wirdParseOutputs:
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
Beginnen Sie innerhalb der FilterBoundingBoxes Methode, indem Sie ein Array erstellen, das der Größe von erkannten Feldern entspricht, und markieren Sie alle Steckplätze als aktiv oder für die Verarbeitung bereit.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Sortieren Sie dann die Liste mit Ihren Begrenzungsrahmen in absteigender Reihenfolge basierend auf den Vertrauenswerten.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Erstellen Sie danach eine Liste, um die gefilterten Ergebnisse zu enthalten.
var results = new List<YoloBoundingBox>();
Beginnen Sie mit der Verarbeitung jedes Begrenzungsrahmens, indem Sie jeden der Begrenzungsrahmen durchlaufen.
for (int i = 0; i < boxes.Count; i++)
{
}
Überprüfen Sie innerhalb dieser for-Schleife, ob die aktuelle Bounding-Box verarbeitet werden kann.
if (isActiveBoxes[i])
{
}
Wenn ja, fügen Sie den Begrenzungsrahmen zur Liste der Ergebnisse hinzu. Wenn die Ergebnisse den angegebenen Grenzwert der zu extrahierenden Felder überschreiten, brechen Sie die Schleife aus. Fügen Sie den folgenden Code innerhalb der If-Anweisung hinzu.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
Sehen Sie sich andernfalls die angrenzenden Begrenzungsfelder an. Fügen Sie den folgenden Code unterhalb des Kontrollkästchenlimits hinzu.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Verwenden Sie wie das erste Feld, wenn das angrenzende Feld aktiv ist oder verarbeitet werden kann, die IntersectionOverUnion Methode, um zu überprüfen, ob das erste Kontrollkästchen und das zweite Feld den angegebenen Schwellenwert überschreiten. Fügen Sie dem innersten For-Loop den folgenden Code hinzu.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
Außerhalb der innersten For-Loop-Funktion, die benachbarte Begrenzungsfelder überprüft, sehen Sie, ob es noch zu verarbeitende Begrenzungsfelder gibt. Wenn nicht, brechen Sie die äußere For-Loop-Schleife auf.
if (activeCount <= 0)
break;
Geben Sie schließlich außerhalb der ersten for-Schleife der FilterBoundingBoxes Methode die Ergebnisse zurück.
return results;
Sehr gut! Jetzt ist es an der Zeit, diesen Code zusammen mit dem Modell für die Bewertung zu verwenden.
Verwenden des Modells für die Bewertung
Genau wie bei der Nachbearbeitung gibt es einige Schritte in den Bewertungsschritten. Fügen Sie dazu eine Klasse hinzu, die die Bewertungslogik zu Ihrem Projekt enthält.
Klicken Sie im Projektmappen-Explorer mit der rechten Maustaste auf das Projekt, und wählen Sie dann "> hinzufügen" aus.
Wählen Sie im Dialogfeld " Neues Element hinzufügen " " Klasse " aus, und ändern Sie das Feld "Name " in OnnxModelScorer.cs. Klicken Sie anschließend auf Hinzufügen.
Die OnnxModelScorer.cs Datei wird im Code-Editor geöffnet. Fügen Sie oben
usingdie folgenden Direktiven hinzu:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;Fügen Sie innerhalb der
OnnxModelScorerKlassendefinition die folgenden Variablen hinzu.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Erstellen Sie direkt darunter einen Konstruktor für die
OnnxModelScorerKlasse, der die zuvor definierten Variablen initialisiert.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Nachdem Sie den Konstruktor erstellt haben, definieren Sie einige Strukturen, die Variablen enthalten, die sich auf die Bild- und Modelleinstellungen beziehen. Erstellen Sie eine Struktur namens
ImageNetSettings, um die als Eingabe für das Modell erwartete Höhe und Breite zu enthalten.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Erstellen Sie danach eine weitere Struktur mit dem Namen
TinyYoloModelSettings, die die Namen der Eingabe- und Ausgabeebenen des Modells enthält. Um den Namen der Eingabe- und Ausgabeebenen des Modells zu visualisieren, können Sie ein Tool wie Netron verwenden.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Erstellen Sie als Nächstes die erste Gruppe von Methoden, die für die Bewertung verwendet werden. Erstellen Sie die
LoadModelMethode innerhalb derOnnxModelScorerKlasse.private ITransformer LoadModel(string modelLocation) { }Fügen Sie innerhalb der
LoadModelMethode den folgenden Code für die Protokollierung hinzu.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET Pipelines müssen das Datenschema kennen, das beim Aufrufen der
FitMethode ausgeführt werden soll. In diesem Fall wird ein Prozess verwendet, der der Schulung ähnelt. Da jedoch keine tatsächliche Schulung stattfindet, ist es akzeptabel, eine leereIDataViewzu verwenden. Erstellen Sie eine neueIDataViewfür die Pipeline von einer leeren Liste.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Definieren Sie im Folgenden die Pipeline. Die Pipeline wird aus vier Transformationen bestehen.
-
LoadImageslädt das Bild als Bitmap. -
ResizeImagesVerkleinern des Bilds auf die angegebene Größe (in diesem Fall416 x 416). -
ExtractPixelsändert die Pixeldarstellung des Bilds von einer Bitmap in einen numerischen Vektor. -
ApplyOnnxModellädt das ONNX-Modell und verwendet es, um die bereitgestellten Daten auszuwerten.
Definieren Sie Ihre Pipeline in der Methode unterhalb der
LoadModeldataVariablen.var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));Jetzt ist es an der Zeit, das Modell für die Bewertung zu instanziieren. Rufen Sie die
FitMethode für die Pipeline auf, und geben Sie sie zur weiteren Verarbeitung zurück.var model = pipeline.Fit(data); return model;-
Nachdem das Modell geladen wurde, kann es dann verwendet werden, um Vorhersagen zu erstellen. Um diesen Prozess zu erleichtern, erstellen Sie eine Methode, die unter der PredictDataUsingModel Methode aufgerufen wirdLoadModel.
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
Fügen Sie in der PredictDataUsingModelDatei den folgenden Code für die Protokollierung hinzu.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Verwenden Sie dann die Transform Methode, um die Daten zu scoren.
IDataView scoredData = model.Transform(testData);
Extrahieren Sie die vorhergesagten Wahrscheinlichkeiten, und geben Sie sie für die zusätzliche Verarbeitung zurück.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Nachdem beide Schritte eingerichtet wurden, kombinieren Sie sie in einer einzigen Methode. Fügen Sie unterhalb der PredictDataUsingModel Methode eine neue Methode mit dem Namen Scorehinzu.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Fast da! Jetzt ist es an der Zeit, alles zu verwenden.
Erkennen von Objekten
Nachdem das Setup abgeschlossen ist, ist es an der Zeit, einige Objekte zu erkennen.
Ausgabe des Bewertungs- und Analysemodells
Fügen Sie unterhalb der Erstellung der mlContext Variablen eine try-catch-Anweisung hinzu.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
Beginnen Sie innerhalb des try Blocks mit der Implementierung der Objekterkennungslogik. Laden Sie zunächst die Daten in eine IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Erstellen Sie dann eine Instanz von OnnxModelScorer und verwenden Sie sie, um die geladenen Daten zu notieren.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
Jetzt ist es an der Zeit für den Schritt nach der Verarbeitung. Erstellen Sie eine Instanz, YoloOutputParser und verwenden Sie sie, um die Modellausgabe zu verarbeiten.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Sobald die Modellausgabe verarbeitet wurde, ist es an der Zeit, die Begrenzungsrahmen auf den Bildern zu zeichnen.
Visualisieren von Vorhersagen
Nachdem das Modell die Bilder bewertet hat und die Ergebnisse verarbeitet wurden, müssen die Begrenzungsrahmen auf dem Bild gezeichnet werden. Fügen Sie dazu eine Methode hinzu, die unterhalb der DrawBoundingBox Methode innerhalb von GetAbsolutePath aufgerufen wird.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Laden Sie zunächst das Bild, und rufen Sie die Abmessungen für Höhe und Breite in der DrawBoundingBox Methode ab.
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Erstellen Sie dann eine For-Each-Schleife, um über jedes der Begrenzungsfelder zu iterieren, die vom Modell erkannt wurden.
foreach (var box in filteredBoundingBoxes)
{
}
Rufen Sie innerhalb der for-each-Schleife die Abmessungen des begrenzenden Rahmens ab.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Da die Abmessungen des Begrenzungsrahmens der Modelleingabe 416 x 416 entsprechen, skalieren Sie die Abmessungen des Begrenzungsrahmens entsprechend der tatsächlichen Größe des Bildes.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Definieren Sie eine Vorlage für Text, der über jedem Begrenzungsrahmen erscheint. Der Text enthält die Objektklasse innerhalb des jeweiligen Begrenzungsrahmens sowie die Konfidenz.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Um auf das Bild zu zeichnen, konvertieren Sie es in ein Graphics Objekt.
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
using Optimieren Sie im Codeblock die Objekteinstellungen der GrafikGraphics.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Legen Sie darunter die Schriftart- und Farboptionen für den Text und das umgebende Feld fest.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Erstellen und füllen Sie ein Rechteck über dem begrenzenden Rahmen, damit er den Text mithilfe der FillRectangle Methode enthält. Dadurch wird der Kontrast des Textes erhöht und die Lesbarkeit verbessert.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Zeichnen Sie dann den Text und das begrenzende Rechteck auf dem Bild mithilfe der DrawString und DrawRectangle Methoden.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
Fügen Sie außerhalb der for-each-Schleife Code hinzu, um die Bilder in der outputFolderSchleife zu speichern.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Fügen Sie für zusätzliches Feedback, dass die Anwendung zur Laufzeit Vorhersagen wie erwartet vornimmt, eine Methode hinzu, die unter der Methode in der LogDetectedObjectsDrawBoundingBox aufgerufen wird, um die erkannten Objekte in der Konsole auszugeben.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Da Sie nun über Hilfsmethoden verfügen, um visuelles Feedback aus den Vorhersagen zu erstellen, fügen Sie eine Schleife hinzu, um über jedes bewertete Bild zu iterieren.
for (var i = 0; i < images.Count(); i++)
{
}
Rufen Sie innerhalb der Forschleife den Namen der Bilddatei und die damit verbundenen Begrenzungsrahmen ab.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Verwenden Sie unterhalb davon die DrawBoundingBox Methode, um die begrenzenden Boxen auf dem Bild zu zeichnen.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Verwenden Sie schließlich die LogDetectedObjects Methode, um Vorhersagen an die Konsole auszugeben.
LogDetectedObjects(imageFileName, detectedObjects);
Fügen Sie nach der try-catch-Anweisung zusätzliche Logik hinzu, um anzugeben, dass der Prozess abgeschlossen ist.
Console.WriteLine("========= End of Process..Hit any Key ========");
Das ist alles!
Ergebnisse
Führen Sie nach den vorherigen Schritten die Konsolen-App (STRG+F5) aus. Ihre Ergebnisse sollten mit der folgenden Ausgabe vergleichbar sein. Möglicherweise werden Warnungen oder die Verarbeitung von Nachrichten angezeigt, aber diese Nachrichten wurden aus den folgenden Ergebnissen aus Gründen der Übersichtlichkeit entfernt.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Um die Bilder mit Begrenzungsrahmen anzuzeigen, navigieren Sie zum Verzeichnis assets/images/output/. Nachfolgend finden Sie ein Beispiel aus einem der verarbeiteten Bilder.

Glückwunsch! Sie haben nun erfolgreich ein Machine Learning-Modell für die Objekterkennung erstellt, indem Sie ein vortrainiertes Modell in ML.NET wiederverwenden ONNX .
Den Quellcode für dieses Lernprogramm finden Sie im Repository "dotnet/machinelearning-samples" .
In diesem Tutorial haben Sie Folgendes gelernt:
- Verstehen des Problems
- Erfahren Sie, was ONNX ist und wie es mit ML.NET zusammenarbeitet.
- Grundlegendes zum Modell
- Wiederverwenden des vortrainierten Modells
- Erkennen von Objekten mit einem geladenen Modell
Sehen Sie sich das GitHub-Repository für Machine Learning-Beispiele an, um ein erweitertes Beispiel zur Objekterkennung zu erkunden.
Zusammenarbeit auf GitHub
Die Quelle für diesen Inhalt finden Sie auf GitHub, wo Sie auch Issues und Pull Requests erstellen und überprüfen können. Weitere Informationen finden Sie in unserem Leitfaden für Mitwirkende.