Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
In diesem Artikel wird erläutert, wie Sie die Modellversion und die Einstellungen im Prompt Builder ändern. Die Modellversion und die Einstellungen können sich auf die Leistung und das Verhalten des generativen KI-Modells auswirken.
Modellauswahl
Sie können das Modell ändern, indem Sie oben im Aufforderungs-Generator " Modell " auswählen. Im Dropdown-Menü können Sie aus den generativen KI-Modellen auswählen, die Antworten auf Ihre benutzerdefinierte Eingabeaufforderung generieren.
Die Verwendung von Eingabeaufforderungen in Power Apps oder Power Automate verbraucht Prompt Builder Credits, während die Verwendung von Eingabeaufforderungen in Copilot Studio Copilot Credits verbraucht. Weitere Informationen finden Sie in Lizenzierungs- und Prompt-Builder-Gutschriften in der AI Builder-Dokumentation.
Überblick
Die folgende Tabelle beschreibt die verschiedenen verfügbaren Modelle.
Modelle haben unterschiedliche Verfügbarkeit in allen Regionen und werden regelmäßig aktualisiert. Weitere Informationen finden Sie in der Verfügbarkeit des Eingabeaufforderungsmodells nach Region und Updates.
Notiz
- GPT-4o mini und GPT-4o werden weiterhin in US-Regierungsregionen verwendet. Diese Modelle befolgen Lizenzregeln und bieten Funktionalitäten, die mit GPT-4.1 Mini und GPT-4.1 vergleichbar sind.
- Anthropische Modelle werden außerhalb Microsoft gehostet und unterliegen anthropischen Ausdrücken und der Datenverarbeitung. Erfahren Sie mehr in Wählen Sie ein externes Modell als primäres KI-Modell.
| GPT-Modell | Lizenzierung | Funktionen | Category |
|---|---|---|---|
| GPT-4.1 mini (Standardmodell) | Basistarif | Trainiert mit Daten bis Juni 2024. Geben Sie bis zu 128.000 Token ein. | Mini |
| GPT-4.1 | Standardtarif | Trainiert mit Daten bis Juni 2024. Kontext erlaubt bis zu 128.000 Token. | Allgemeines |
| GPT-5 Chat | Standardtarif | Trainiert mit Daten bis September 2024. Kontext erlaubt bis zu 128.000 Token. | Allgemeines |
| GPT-5-Begründung | Premiumtarif | Trainiert mit Daten bis September 2024. Kontext erlaubt bis zu 400.000 Token. | Tief |
| GPT-5.2-Argumentation | Premiumtarif | Trainiert mit Daten bis Oktober 2024. Kontext erlaubt bis zu 400.000 Token. | Tief |
| GPT-5.3-Chat | Standardtarif | Verwaltetes Modell. Kontext erlaubt bis zu 128.000 Token. | Allgemeines |
| Claude Sonett 4.6 | Standardtarif | Externes Modell von Anthropic. Der Kontext erlaubt bis zu 200.000 Token. | Allgemeines |
| Claude Opus 4.6 | Premiumtarif | Externes Modell von Anthropic. Der Kontext erlaubt bis zu 200.000 Token. | Tief |
| Grok 4.1 Fast (Non-Reasoning) (siehe den folgenden wichtigen Hinweis) | Standardtarif | Externes Modell aus xAI. | Allgemeines |
Wichtig
Die Sicherheits- und verantwortungsvolle KI-Bewertung von Microsoft ergab, dass Grok-4.1 Fast (Non-Reasoning) weniger gut ausgerichtet ist als andere Modelle. Dies führt zu (i) höheren Risiken, dass das Modell potenziell schädliche Inhalte erzeugt und (ii) niedrigeren Bewertungen bei Sicherheits- und Jailbreak-Benchmarks. Grok-4.1 Fast (Non-Reasoning) kann expliziten Inhalt erzeugen und hat dabei möglicherweise eine höhere Neigung als andere Modelle. Kunden müssen sowohl den Microsoft Enterprise AI Services-Verhaltenskodex als auch die Nutzungsbedingungen von xAI einhalten, einschließlich ihrer Richtlinie zur zulässigen Nutzung. Darüber hinaus kann es Kategorien von Schäden geben, die dieses Modell erzeugen kann, die nicht von den Inhaltssicherheitssystemen von Microsoft abgedeckt werden. Entsprechend wird Grok-4.1 Fast (Non-Reasoning), wie bei allen experimentellen Modellen, für den Produktionseinsatz nicht empfohlen. Kunden sollten Einschränkungen experimenteller und Vorschaumodelle überprüfen und eigene Auswertungen durchführen, bevor sie Grok-4.1 Fast (Non-Reasoning) auswählen.
Lizenzierung
In Agents, Flows oder Apps, verbrauchen Prompts, die Modelle verwenden, Copilot-Gutschriften, unabhängig von der Veröffentlichungsphase des Modells. Erfahren Sie mehr unter Abrechnungsgebühren und -verwaltung.
Wenn Sie AI Builder-Credits haben, nutzt das System diese zuerst, wenn Prompts in Power Apps und Power Automate verwendet werden. Das System verbraucht keine AI Builder Credits, wenn Prompts im Copilot Studio verwendet werden. Weitere Informationen finden Sie in Overview of licensing in der AI Builder-Dokumentation.
Veröffentlichungsphasen
Modelle durchlaufen verschiedene Veröffentlichungsphasen. Sie können neue, hochmoderne experimentelle und Vorschaumodelle ausprobieren oder ein zuverlässiges, gründlich getestetes, allgemein verfügbares Modell wählen.
| Tag | Beschreibung |
|---|---|
| Experimentell | Für Experimente gedacht und nicht für Produktionszwecke. Unterliegt den Vorschaubedingungen und kann Einschränkungen in Bezug auf Verfügbarkeit und Qualität aufweisen. |
| Vorschau | Wird letztlich zu einem allgemein verfügbaren Modell; derzeit jedoch nicht für den Produktionseinsatz empfohlen. Unterliegt den Vorschaubedingungen und kann Einschränkungen in Bezug auf Verfügbarkeit und Qualität aufweisen. |
| Kein Tag | Allgemein verfügbar. Sie können dieses Modell für skalierte und produktive Zwecke verwenden. In den meisten Fällen haben allgemein verfügbare Modelle keine Einschränkungen hinsichtlich Verfügbarkeit und Qualität, bei einigen gibt es jedoch möglicherweise trotzdem noch einige Einschränkungen, z. B. bezüglich der regionalen Verfügbarkeit. Wichtig: Anthropic Claude-Modelle befinden sich in der Prüfungsphase, obwohl sie kein Tag anzeigen. |
| Standard | Das Standardmodell für alle Agents und in der Regel das am besten geeignete allgemein verfügbare Modell. Das Standardmodell wird regelmäßig aktualisiert, sobald neue, leistungsfähigere Modelle allgemein verfügbar sind. Agenten verwenden das Standardmodell auch als Fallback, wenn ein ausgewähltes Modell deaktiviert oder nicht verfügbar ist. |
Experimentelle und Vorschaumodelle könnten Variabilität in Leistung, Antwortqualität, Latenz oder Nachrichtenkonsum zeigen. Sie könnten ein Timeout erfahren oder nicht verfügbar sein. Sie unterliegen den Bedingungen für Vorschauversionen.
Kategorisierung
In der folgenden Tabelle sind die unterschiedlichen Modellkategorien beschrieben.
| Category | Mini | Allgemeines | Tief |
|---|---|---|---|
| Leistung | Gut für die meisten Aufgaben | Überlegenheit bei komplexen Aufgaben | Trainiert für Denkaufgaben |
| Geschwindigkeit | Schnellere Verarbeitung | Kann aufgrund der Komplexität langsamer sein | Langsamer, da es vor der Reaktion nachdenkt |
| Anwendungsfälle | Zusammenfassung, Informationsaufgaben, Bild- und Dokumentenverarbeitung | Bild- und Dokumentverarbeitung, erweiterte Aufgaben zum Erstellen von Inhalten | Datenanalyse und Begründungsaufgaben, Bild- und Dokumentverarbeitung |
Wählen Sie ein Mini-Modell , wenn Sie eine kosteneffiziente Lösung für mäßig komplexe Aufgaben benötigen, begrenzte Rechenressourcen haben oder schnellere Verarbeitung benötigen. Mini-Modelle sind ideal für Projekte mit Budgetbeschränkungen und Anwendungen wie Kundensupport oder effiziente Code-Analyse.
Wählen Sie ein allgemeines Modell, wenn Sie mit hochkomplexen, multimodalen Aufgaben zu tun haben, die überlegene Leistung und detaillierte Analyse erfordern. Es ist die bessere Wahl für Großprojekte, bei denen Genauigkeit und erweiterte Funktionen entscheidend sind. Ein allgemeines Modell ist auch eine gute Wahl, wenn man das Budget und die Rechenressourcen dafür hat. Allgemeine Modelle sind auch für langfristige Projekte vorzuziehen, die im Laufe der Zeit an Komplexität zunehmen könnten.
Deep Models sind für Projekte hervorragend geeignet, die fortgeschrittene Denkfähigkeiten erfordern. Sie eignen sich für Szenarien, die anspruchsvolles Problemlösen und kritisches Denken erfordern. Deep-Modelle eignen sich perfekt für Umgebungen, in denen nuanciertes Reasoning, komplexe Entscheidungsfindung und detaillierte Analysen wichtig sind.
Wählen Sie zwischen den Modellen basierend auf Verfügbarkeit der Region, Funktionalitäten, Anwendungsfällen und Kosten. Erfahren Sie, welche Modelle in Ihrer Region verfügbar sind, und modellieren Sie die Einstellungszeitpläne in der Modellverfügbarkeit nach Region und Updates. Erfahren Sie mehr über die Preise in AI Builder Capability Rate table.
Modelleinstellungen
Du kannst auf das Einstellungsfeld zugreifen, indem du die drei Punkte auswählst (...). >Einstellungen oben im Prompt-Builder. Sie können die folgenden Einstellungen ändern:
- Temperatur: Niedrigere Temperaturen führen zu vorhersagbaren Ergebnissen. Höhere Temperaturen ermöglichen vielfältigere oder kreativere Antworten.
- Datensatz abrufen: Anzahl der Datensätze, die für Ihre Wissensquellen abgerufen wurden.
- Links in die Antwort einfügen: Wenn diese Option ausgewählt ist, enthält die Antwort Linkzitate für die abgerufenen Datensätze.
- Code-Interpreter aktivieren: Wenn ausgewählt, ist der Code-Interpreter aktiviert, um Code zu generieren und auszuführen .
- Inhaltsmoderationsniveau: Das niedrigste Level liefert die meisten Antworten, kann aber schädliche Inhalte enthalten. Das höchste Maß an Inhaltsmoderation wendet einen strengeren Filter an, um schädliche Inhalte zu begrenzen, und liefert weniger Antworten.
Temperatur
Stellen Sie die Temperatur für das generative KI-Modell mit dem Schieberegler ein. Sie liegt zwischen 0 und 1. Dieser Wert leitet das generative KI-Modell darin, wie viel Kreativität (1) im Vergleich zur deterministischen Antwort (0) es liefert.
Notiz
Die Temperatureinstellung ist für das GPT-5-Reasoning-Modell nicht verfügbar. Aus diesem Grund ist der Schieberegler deaktiviert, wenn Sie das GPT-5-Reasoning-Modell auswählen.
Die Temperatur ist ein Parameter, der die Zufälligkeit der vom KI-Modell erzeugten Ausgaben steuert. Eine niedrigere Temperatur führt zu vorhersehbareren und konservativeren Ergebnissen. Im Vergleich dazu ermöglicht eine höhere Temperatur mehr Kreativität und Vielfalt in den Reaktionen. Es ist eine Möglichkeit, das Gleichgewicht zwischen Zufälligkeit und Determinismus in der Modellausgabe zu feinjustieren.
Standardmäßig ist die Temperatur 0, wie in zuvor erstellten Eingabeaufforderungen.
| Temperatur | Funktion | Verwenden in |
|---|---|---|
| 0 | Vorhersehbarere und konservativere Ergebnisse. Die Antworten sind konsistenter. |
Eingabeaufforderungen, die eine hohe Genauigkeit und weniger Variabilität erfordern. |
| 1 | Mehr Kreativität und Vielfalt in den Antworten. Vielfältigere und manchmal innovativere Antworten. |
Prompts, die sofort einsatzbereite neue Inhalte erstellen. |
Die Temperaturanpassung kann die Ausgabe des Modells beeinflussen, garantiert aber kein bestimmtes Ergebnis. Die Antworten der KI sind von Natur aus probabilistisch und können auch bei derselben Temperatureinstellung variieren.
Inhaltsmoderationsniveau
Stellen Sie das Moderationsniveau für den Prompt mit dem Schieberegler ein. Mit einem niedrigeren Maß an Moderation kann dein Prompt mehr Antworten liefern. Allerdings könnte die Zunahme der Antworten beeinflussen, ob schädliche Inhalte (Hass und Fairness, sexuell, Gewalt, Selbstverletzung) im Prompt berücksichtigt werden.
Notiz
Die Einstellung für Inhaltsmoderation ist nur für verwaltete Modelle verfügbar. Aus diesem Grund ist der Schieberegler nicht verfügbar, wenn Sie anthropische oder Azure AI Foundry Modelle auswählen.
Die Moderationsstufen reichen von Niedrig bis Hoch. Die Standardmoderationsstufe für Prompts ist Moderat.
Eine geringere Moderation erhöht das Risiko schädlicher Inhalte in den Antworten deiner Prompts. Eine höhere Moderation senkt dieses Risiko, könnte aber die Anzahl der Antworten verringern.
| Inhaltsmoderationsniveau | Beschreibung | Verwendungsempfehlung |
|---|---|---|
| Gering | Könnte Hass und Fairness, sexuelle, Gewalt- oder Selbstverletzungsinhalte erlauben, die explizite und schwerwiegende schädliche Anweisungen, Handlungen, Schäden oder Missbrauch zeigen. Beinhaltet die Befürwortung, Verherrlichung oder Förderung schwerwiegender schädlicher Handlungen, extremer oder illegaler Formen von Schäden, Radikalisierung oder nicht einvernehmlicher Machtübertragung oder -missbrauch. | Verwendung für Prompts zur Verarbeitung von Daten, die als schädliche Inhalte angesehen werden könnten (zum Beispiel Beschreibungen von Gewalt oder medizinischen Eingriffen). |
| Mäßig | Könnte Hass und Fairness, sexuelle, Gewalt- oder Selbstverletzungsinhalte erlauben, die beleidigende, spöttische, einschüchternde oder erniedrigende Sprache gegenüber bestimmten Identitätsgruppen verwenden. Enthält Darstellungen der Suche nach und der Ausführung von schädlichen Anweisungen, Fantasien, Verherrlichung und Förderung von Schädigung mit mittlerer Intensität. | Standardfilterung. Für die meisten Anwendungen geeignet. |
| Hoch | Könnte Inhalte zu Hass, Sexualität, Gewalt oder Selbstverletzung erlauben, die voreingenommene, wertende oder meinungsstarke Ansichten ausdrücken. Beinhaltet beleidigende Sprachgebrauch, Stereotypisierung, Anwendungsfälle zur Erkundung einer fiktiven Welt (zum Beispiel Gaming, Literatur) und Darstellungen mit niedriger Intensität. | Nutze es, wenn du eine stärkere Filterung brauchst, die restriktiver ist als auf der mittleren Stufe. |
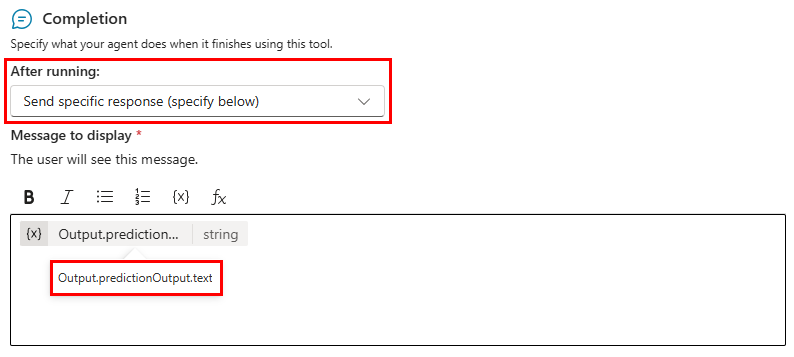
Um die Inhaltsmoderationseinstellung des Agenten beim Verwenden des Prompts in einem Agenten zu überschreiben, stellen Sie im Abschlussbildschirm des Prompt-Tools die Einstellung "Nach dem Ausführen" auf Senden einer spezifischen Antwort (unten angeben). Die anzuzeigende Nachricht sollte die benutzerdefinierte Variable Output.predictionOutput.text enthalten.