Konfigurieren eines RHEL-FCI-Clusters (Failoverclusterinstanz) für SQL Server
Gilt für: ![]() SQL Server – Linux
SQL Server – Linux
Diese Anleitung enthält Anweisungen zum Erstellen eines freigegebenen Datenträgerfailoverclusters mit zwei Knoten für SQL Server unter Red Hat Enterprise Linux. Die Clusteringebene basiert auf einem Hochverfügbarkeits-Add-On für Red Hat Enterprise Linux (RHEL), das auf Pacemaker aufbaut. Die SQL Server-Instanz ist auf einem der beiden Knoten aktiv.
Hinweis
Für den Zugriff auf das Red Hat-Hochverfügbarkeits-Add-On und die Dokumentation ist ein Abonnement erforderlich.
Wie in der folgenden Abbildung zu sehen, wird der Speicher zwei Servern präsentiert. Clusteringkomponenten – Corosync und Pacemaker – koordinieren die Kommunikation und die Ressourcenverwaltung. Ein Server verfügt über die aktive Verbindung mit den Speicherressourcen und SQL Server. Wenn Pacemaker einen Fehler erkennt, sind die Clusteringkomponenten das Verschieben der Ressourcen auf den anderen Knoten verantwortlich.
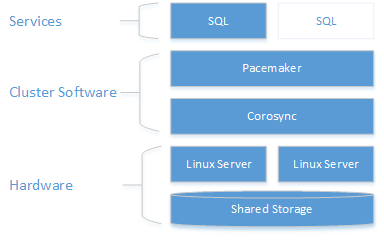
Weitere Informationen zur Clusterkonfiguration, den Optionen für Ressourcen-Agents und der Verwaltung finden Sie in der Referenzdokumentation von RHEL.
Hinweis
An diesem Punkt ist die Integration von SQL Server in Pacemaker nicht so stark gekoppelt wie in WSFC unter Windows. Aus SQL Server kann der Cluster nicht erkannt werden. Die gesamte Orchestrierung erfolgt außerhalb durch Pacemaker. Zudem wird der Dienst als eigenständige Instanz von Pacemaker gesteuert. Außerdem werden z. B. die Cluster dmvs sys.dm_os_cluster_nodes und sys.dm_os_cluster_properties keine Datensätze enthalten.
Wenn Sie eine Verbindungszeichenfolge verwenden möchten, die auf einen Zeichenfolgenservernamen zeigt und nicht die IP-Adresse verwendet, müssen Sie die IP-Adresse, die (wie in den folgenden Abschnitten beschrieben) zum Erstellen der virtuellen IP-Ressource verwendet wird, mit dem ausgewählten Servernamen beim DNS-Server registrieren.
In den folgenden Abschnitten werden die Schritte zum Einrichten einer Failoverclusterlösung erläutert.
Voraussetzungen
Für das folgende End-to-End-Szenario benötigen Sie zwei Computer, um den Cluster mit zwei Knoten und einen weiteren Server zum Konfigurieren des NFS-Servers bereitzustellen. Die folgenden Schritte beschreiben, wie diese Server konfiguriert werden.
Einrichten und Konfigurieren des Betriebssystems auf den einzelnen Clusterknoten
Der erste Schritt besteht darin, das Betriebssystem auf den Clusterknoten zu konfigurieren. Verwenden Sie für diese exemplarische Vorgehensweise RHEL mit einem gültigen Abonnement für das Hochverfügbarkeits-Add-On.
Installieren und Konfigurieren der SQL Server-Instanz auf den einzelnen Clusterknoten
Installieren Sie SQL Server auf beiden Knoten, und richten Sie die Anwendung ein. Ausführliche Anweisungen finden Sie unter Installieren von SQL Server für Linux.
Legen Sie für die Konfiguration einen Knoten als primär und den anderen als sekundär fest. Verwenden Sie diese Begriffe für den weiteren Verlauf dieses Leitfadens.
Beenden und deaktivieren Sie SQL Server auf dem sekundären Knoten.
Im folgenden Beispiel wird SQL Server beendet und deaktiviert:
sudo systemctl stop mssql-server sudo systemctl disable mssql-server
Hinweis
Zum Zeitpunkt der Einrichtung wird ein Serverhauptschlüssel für die SQL Server-Instanz generiert und unter /var/opt/mssql/secrets/machine-key platziert. Unter Linux wird SQL Server immer als lokales Konto mit dem Namen mssql ausgeführt. Da es sich um ein lokales Konto handelt, wird dessen Identität nicht knotenübergreifend freigegeben. Daher müssen Sie den Verschlüsselungsschlüssel vom primären Knoten auf jeden sekundären Knoten kopieren, damit jedes lokale mssql-Konto darauf zugreifen kann, um den Serverhauptschlüssel zu entschlüsseln.
Erstellen Sie auf dem primären Knoten eine SQL Server-Anmeldung für Pacemaker, und erteilen Sie dem Anmeldenamen die Berechtigung zum Ausführen von
sp_server_diagnostics. Pacemaker verwendet dieses Konto, um zu überprüfen, welcher Knoten auf SQL Server ausgeführt wird.sudo systemctl start mssql-serverStellen Sie mithilfe des sa-Kontos eine Verbindung mit der
master-Datenbank von SQL Server her, und führen Sie Folgendes aus:USE [master] GO CREATE LOGIN [<loginName>] with PASSWORD= N'<loginPassword>' ALTER SERVER ROLE [sysadmin] ADD MEMBER [<loginName>]Alternativ können Sie die Berechtigungen detaillierter festlegen. Der Pacemaker-Anmeldename benötigt
VIEW SERVER STATE, um mithilfe vonsp_server_diagnosticsden Integritätsstatus abzufragen, sowiesetupadminundALTER ANY LINKED SERVER, um den Namen der Failoverclusterinstanz mit dem Ressourcennamen zu aktualisieren, indemsp_dropserverundsp_addserverausgeführt werden.Beenden und deaktivieren Sie SQL Server auf dem primären Knoten.
Konfigurieren Sie die Hostdatei für jeden Clusterknoten. Die Hostdatei muss die IP-Adresse und den Namen jedes Clusterknotens enthalten.
Überprüfen Sie die IP-Adresse jedes Knotens. Das folgende Skript zeigt die IP-Adresse des aktuellen Knotens an.
sudo ip addr showLegen Sie den Computernamen auf jedem Knoten fest. Geben Sie jedem Knoten einen eindeutigen Namen, der höchstens 15 Zeichen lang ist. Legen Sie den Computernamen fest, indem Sie diesen zu
/etc/hostshinzufügen. Mithilfe des folgenden Skripts können Sie/etc/hostsmitvibearbeiten.sudo vi /etc/hostsDas folgende Beispiel zeigt
/etc/hostsmit Ergänzungen für zwei Knoten mit den Namensqlfcivm1undsqlfcivm2.127.0.0.1 localhost localhost4 localhost4.localdomain4 ::1 localhost localhost6 localhost6.localdomain6 10.128.18.128 sqlfcivm1 10.128.16.77 sqlfcivm2
Im nächsten Abschnitt konfigurieren Sie den freigegebenen Speicher und verschieben Ihre Datenbankdateien in diesen Speicher.
Konfigurieren von freigegebenem Speicher und Verschieben von Datenbankdateien
Es gibt verschiedene Lösungen für die Bereitstellung von freigegebenem Speicher. Diese exemplarische Vorgehensweise veranschaulicht das Konfigurieren von freigegebenem Speicher mit NFS. Es wird empfohlen, auf die bewährten Methoden zurückzugreifen und Kerberos zum Sichern von NFS zu verwenden (ein Beispiel finden Sie hier: https://www.certdepot.net/rhel7-use-kerberos-control-access-nfs-network-shares/).
Warnung
Wenn Sie NFS nicht sichern, kann jeder Benutzer, der auf Ihr Netzwerk zugreifen und die IP-Adresse eines SQL-Knotens spoofen kann, auf Ihre Datendateien zugreifen. Stellen Sie wie immer sicher, dass Sie ein Gefahrenmodell für Ihr System erstellen, bevor Sie es in der Produktion verwenden. Eine andere Speicheroption ist die Verwendung der SMB-Dateifreigabe.
Konfigurieren von freigegebenem Speicher mit NFS
Wichtig
Das Hosting von Datenbankdateien auf einem NFS-Server mit Version <4 wird in dieser Version nicht unterstützt. Dies schließt die Verwendung von NFS für das Failoverclustering für freigegebene Datenträger sowie für Datenbanken auf nicht gruppierten Instanzen ein. Wir arbeiten daran, in zukünftigen Releases andere Versionen des NFS-Servers zu ermöglichen.
Führen Sie auf dem NFS-Server folgende Schritte aus:
Installieren von
nfs-utilssudo yum -y install nfs-utilsAktivieren und starten Sie
rpcbind.sudo systemctl enable rpcbind && sudo systemctl start rpcbindAktivieren und starten Sie
nfs-server.sudo systemctl enable nfs-server && sudo systemctl start nfs-serverBearbeiten Sie
/etc/exports, um das Verzeichnis zu exportieren, das Sie freigeben möchten. Sie benötigen eine Zeile für jede gewünschte Freigabe. Zum Beispiel:/mnt/nfs 10.8.8.0/24(rw,sync,no_subtree_check,no_root_squash)Exportieren Sie die Freigaben.
sudo exportfs -ravStellen Sie sicher, dass die Pfade freigegeben/exportiert wurden. Führen Sie dazu Folgendes auf dem NFS-Server aus:
sudo showmount -eFügen Sie in SELinux eine Ausnahme hinzu.
sudo setsebool -P nfs_export_all_rw 1Öffnen Sie die Firewall des Servers.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reload
Konfigurieren aller Clusterknoten für die Verbindung mit dem freigegebenen NFS-Speicher
Führen Sie die folgenden Schritte auf allen Clusterknoten durch.
Installieren von
nfs-utilssudo yum -y install nfs-utilsÖffnen Sie die Firewall auf Clients und dem NFS-Server.
sudo firewall-cmd --permanent --add-service=nfs sudo firewall-cmd --permanent --add-service=mountd sudo firewall-cmd --permanent --add-service=rpc-bind sudo firewall-cmd --reloadVergewissern Sie sich, dass die NFS-Freigaben auf Clientcomputern angezeigt werden.
sudo showmount -e <IP OF NFS SERVER>Wiederholen Sie diese Schritte auf allen Clusterknoten.
Weitere Informationen zur Verwendung von NFS finden Sie unter folgenden Quellen:
- NFS servers and firewalld | Stack Exchange (NFS-Server und firewalld | Stack Exchange)
- Mounting an NFS Volume | Linux Network Administrators Guide (Einbinden eines NFS-Volumes | Leitfaden für Linux-Netzwerkadministratoren)
- NFS server configuration | Red Hat Customer Portal (NFS-Serverkonfiguration | Red Hat-Kundenportal)
Einbinden des Datenbankdateiverzeichnisses zum Zeigen auf den freigegebenen Speicher
Speichern Sie die Datenbankdateien nur auf dem primären Knoten an einem temporären Speicherort. Das folgende Skript erstellt ein neues temporäres Verzeichnis, kopiert die Datenbankdateien in das neue Verzeichnis und entfernt die alten Datenbankdateien. Da SQL Server als lokaler Benutzer
mssqlausgeführt wird, müssen Sie sicherstellen, dass der lokale Benutzer nach der Datenübertragung zur eingebundenen Freigabe Lese- und Schreibzugriff auf die Freigabe hat.sudo su mssql mkdir /var/opt/mssql/tmp cp /var/opt/mssql/data/* /var/opt/mssql/tmp rm /var/opt/mssql/data/* exitBearbeiten Sie die Datei
/etc/fstabauf allen Clusterknoten, um den Befehl zum Einbinden einzuschließen.<IP OF NFS SERVER>:<shared_storage_path> <database_files_directory_path> nfs timeo=14,intrDas folgende Skript ist ein Beispiel hierfür.
10.8.8.0:/mnt/nfs /var/opt/mssql/data nfs timeo=14,intr
Hinweis
Wenn Sie wie hier empfohlen eine File System-Ressource (FS) verwenden, muss der Befehl zum Einbinden in „/etc/fstab“ nicht beibehalten werden. Pacemaker übernimmt die Einbindung des Ordners beim Starten der in FS gruppierten Ressource. Mithilfe von Fencing wird sichergestellt, dass FS nie zweimal eingebunden wird.
Führen Sie den Befehl
mount -aaus, damit das System die eingebundenen Pfade aktualisiert.Kopieren Sie die Datenbank und die Protokolldateien, die Sie in
/var/opt/mssql/tmpgespeichert haben, in die neu eingebundene Freigabe/var/opt/mssql/data. Diesen Schritt müssen Sie nur auf dem primären Knoten durchführen. Stellen Sie sicher, dass Sie dem lokalen BenutzermssqlLese- und Schreibberechtigungen erteilen.sudo chown mssql /var/opt/mssql/data sudo chgrp mssql /var/opt/mssql/data sudo su mssql cp /var/opt/mssql/tmp/* /var/opt/mssql/data/ rm /var/opt/mssql/tmp/* exitÜberprüfen Sie, ob SQL Server mit dem neuen Dateipfad erfolgreich gestartet wurde. Führen Sie dies auf jedem Knoten durch. An diesem Punkt sollte SQL Server immer nur auf einem Knoten ausgeführt werden. Sie können SQL Server nicht auf beiden Knoten gleichzeitig ausführen, da diese ansonsten versuchen würden, gleichzeitig auf die Datendateien zuzugreifen (verwenden Sie zur Vermeidung eines versehentlichen Starts von SQL Server auf beiden Knoten eine File System-Clusterressource, um sicherzustellen, dass die Freigabe nicht zweimal von verschiedenen Knoten eingebunden wird). Die folgenden Befehle starten SQL Server, überprüfen den Status und beenden SQL Server dann.
sudo systemctl start mssql-server sudo systemctl status mssql-server sudo systemctl stop mssql-server
An diesem Punkt sind beide Instanzen von SQL Server so konfiguriert, dass sie mit den Datenbankdateien im freigegebenen Speicher ausgeführt werden. Der nächste Schritt besteht darin, SQL Server für Pacemaker zu konfigurieren.
Installieren und Konfigurieren von Pacemaker auf jedem Clusterknoten
Erstellen Sie auf beiden Clusterknoten eine Datei zum Speichern von Benutzername und Kennwort für SQL Server für die Pacemaker-Anmeldung. Der folgende Code erstellt und füllt diese Tabelle:
sudo touch /var/opt/mssql/secrets/passwd echo '<loginName>' | sudo tee -a /var/opt/mssql/secrets/passwd echo '<loginPassword>' | sudo tee -a /var/opt/mssql/secrets/passwd sudo chown root:root /var/opt/mssql/secrets/passwd sudo chmod 600 /var/opt/mssql/secrets/passwdÖffnen Sie auf beiden Clusterknoten die Pacemaker-Firewallports. Führen Sie zum Öffnen dieser Ports mit
firewalldfolgenden Befehl aus:sudo firewall-cmd --permanent --add-service=high-availability sudo firewall-cmd --reloadWenn Sie eine andere Firewall verwenden, in die keine Konfiguration mit Hochverfügbarkeit integriert ist, müssen die folgenden Ports geöffnet werden, damit Pacemaker mit anderen Knoten im Cluster kommunizieren kann:
- TCP: Ports 2224, 3121, 21064
- UDP: Port 5405
Installieren Sie Pacemaker-Pakete auf jedem Knoten.
sudo yum install pacemaker pcs fence-agents-all resource-agentsLegen Sie das Kennwort für den Standardbenutzer fest, der beim Installieren von Pacemaker und Corosync-Paketen erstellt wird. Verwenden Sie auf beiden Knoten dasselbe Kennwort.
sudo passwd haclusterAktivieren und starten Sie den
pcsd-Dienst und Pacemaker. So können Knoten dem Cluster nach dem Neustart erneut beitreten. Führen Sie den folgenden Befehl auf beiden Knoten aus.sudo systemctl enable pcsd sudo systemctl start pcsd sudo systemctl enable pacemakerInstallieren Sie den FCI-Ressourcenagent für SQL Server. Führen Sie die folgenden Befehle auf beiden Knoten aus.
sudo yum install mssql-server-ha
Konfigurieren des Fencing-Agents
Ein STONITH-Gerät stellt einen Fencing-Agent bereit. Ein Beispiel für das Erstellen eines STONITH-Geräts für diesen Cluster in Azure finden Sie unter Einrichten von Pacemaker unter Red Hat Enterprise Linux in Azure. Ändern Sie die Anweisungen für Ihre Umgebung.
Erstellen Sie den Cluster.
Erstellen Sie auf einem der Knoten den Cluster.
sudo pcs cluster auth <nodeName1 nodeName2 ...> -u hacluster sudo pcs cluster setup --name <clusterName> <nodeName1 nodeName2 ...> sudo pcs cluster start --allKonfigurieren Sie die Clusterressourcen für SQL Server-, File System- und virtuelle IP-Ressourcen, und pushen Sie die Konfiguration zum Cluster. Sie benötigen die folgenden Informationen:
- SQL Server-Ressourcenname: Ein Name für die gruppierte SQL Server-Ressource
- Floating IP-Ressourcenname: Ein Name für die virtuelle IP-Adressenressource
- IP-Adresse: Die IP-Adresse, die von Clients zum Herstellen einer Verbindung mit der gruppierten Instanz von SQL Server verwendet wird.
- Ressourcenname des Dateisystems: Ein Name für die Dateisystemressource
- device (Gerät): Der NFS-Freigabepfad
- device (Gerät): Der lokale Pfad, der in die Freigabe eingebunden wird
- fstype: Typ der Dateifreigabe (d. h.
nfs)
Aktualisieren Sie die Werte aus dem folgenden Skript für Ihre Umgebung. Führen Sie es auf einem Knoten aus, um den gruppierten Dienst zu konfigurieren und zu starten.
sudo pcs cluster cib cfg sudo pcs -f cfg resource create <sqlServerResourceName> ocf:mssql:fci sudo pcs -f cfg resource create <floatingIPResourceName> ocf:heartbeat:IPaddr2 ip=<ip Address> sudo pcs -f cfg resource create <fileShareResourceName> Filesystem device=<networkPath> directory=<localPath> fstype=<fileShareType> sudo pcs -f cfg constraint colocation add <virtualIPResourceName> <sqlResourceName> sudo pcs -f cfg constraint colocation add <fileShareResourceName> <sqlResourceName> sudo pcs cluster cib-push cfgDas folgende Skript erstellt beispielsweise eine gruppierte SQL Server-Ressource mit dem Namen
mssqlhasowie eine Floating IP-Ressource mit der IP-Adresse10.0.0.99. Außerdem wird eine File System-Ressource erstellt sowie Einschränkungen hinzugefügt, sodass alle Ressourcen auf demselben Knoten als SQL-Ressource verbunden werden.sudo pcs cluster cib cfg sudo pcs -f cfg resource create mssqlha ocf:mssql:fci sudo pcs -f cfg resource create virtualip ocf:heartbeat:IPaddr2 ip=10.0.0.99 sudo pcs -f cfg resource create fs Filesystem device="10.8.8.0:/mnt/nfs" directory="/var/opt/mssql/data" fstype="nfs" sudo pcs -f cfg constraint colocation add virtualip mssqlha sudo pcs -f cfg constraint colocation add fs mssqlha sudo pcs cluster cib-push cfgNach dem Pushen der Konfiguration wird SQL Server auf einem Knoten gestartet.
Stellen Sie sicher, dass SQL Server gestartet wird.
sudo pcs statusDie folgenden Beispiele zeigen die Ergebnisse, wenn Pacemaker erfolgreich eine gruppierte Instanz von SQL Server gestartet hat.
fs (ocf::heartbeat:Filesystem): Started sqlfcivm1 virtualip (ocf::heartbeat:IPaddr2): Started sqlfcivm1 mssqlha (ocf::mssql:fci): Started sqlfcivm1 PCSD Status: sqlfcivm1: Online sqlfcivm2: Online Daemon Status: corosync: active/disabled pacemaker: active/enabled pcsd: active/enabled
Zugehöriger Inhalt
Feedback
Bald verfügbar: Im Laufe des Jahres 2024 werden wir GitHub-Tickets als Feedbackmechanismus für Inhalte auslaufen lassen und es durch ein neues Feedbacksystem ersetzen. Weitere Informationen finden Sie unter: https://aka.ms/ContentUserFeedback.
Einreichen und Feedback anzeigen für